
XML 站點地圖:優化的關鍵建議
已發表: 2021-03-26您網站上的 Sitemap.xml 可以作為您希望 Google bot 索引的頁面的良好導航。 即使您沒有良好的內部鏈接,它也可以幫助您更快地找到主頁。
在本文中,我們將針對 XML 站點地圖的優化提出各種建議,以及這樣做的好處。
功能和優勢
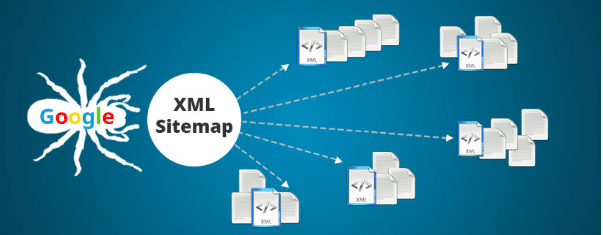
讓機器人更容易工作,並允許獲取您網站上不容易找到的頁面和鏈接的“報告”。
一些 SEO 的好處如下:
- 更快的索引 - 搜索引擎會更快地找到新頁面,因此在搜索結果中索引和顯示網站的過程會更快。 這裡的特殊之處在於它還可以幫助您進行去索引(更多信息在這裡);
- 更好地索引內部頁面——搜索引擎可以找到在抓取網站時沒有找到的頁面。 但這並不一定意味著它們都會被索引。
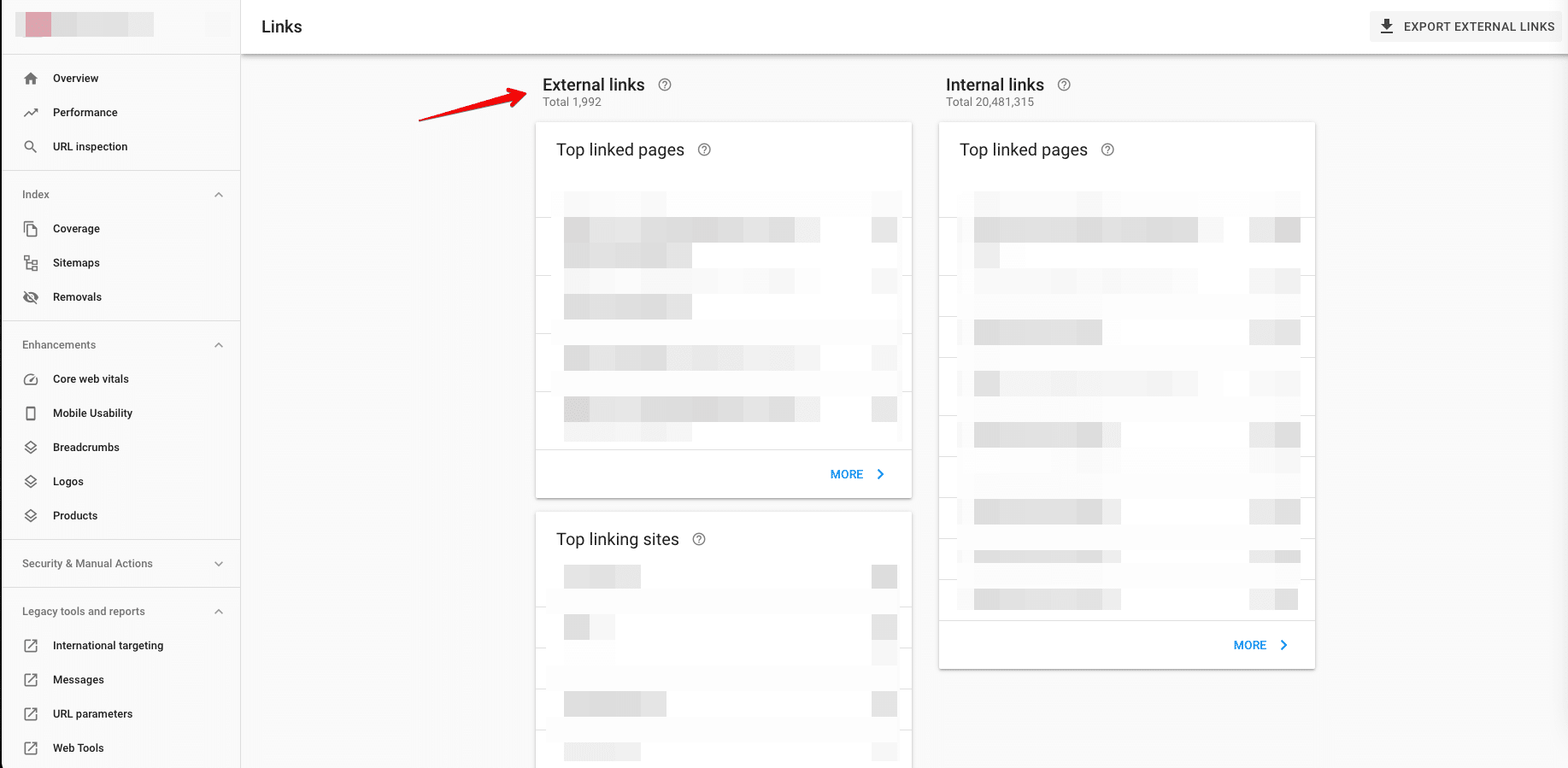
- 監控索引頁面。 結合 Google Search Console,您可以找出哪些 URL 包含在 Google 索引的 XML Sitemap 中。
XML 站點地圖重要嗎?
對於以下站點很重要:
- 沒有良好的結構或沒有良好的內部鏈接分佈;
- 有很多頁面——XML 站點地圖幫助搜索引擎找到新的或更新的頁面;
- 不要有很多入站鏈接——這將是查找頁面的好方法。
要求和格式
Google 支持多種站點地圖格式。 所有格式和標準都可以在這個地址找到:https://www.sitemaps.org/index.html。
所有格式都將站點地圖限制為 50MB(未壓縮)和 50,000 個地址。 如果您有更大的文件或更多地址,則需要創建一個包含所有地圖的索引文件(在下面的文章中描述)。
主要建議如下:
- 文件必須使用 UTF-8 編碼;
- 它必須以一個打開的標籤開始,並以一個關閉的標籤結束,例如……。 ;
- 在標籤中指定標準協議;
- 每個 URL 條目的主標記;
- 在標籤中指定以協議(https或http)開頭的URL,必須參與主標籤才能保存。
XML 站點地圖的其他可選屬性
Google 不會在其網站上使用該屬性。 所有其他屬性都可用,但這取決於它們是否會被反映。 因此,請記住,Google 不會非常重視這些標籤。 他們是:
- – 表示最後一次文件更改的日期。 必須是 W3C 日期時間格式;
- – 頁面可能更新的頻率。 此值提供有關搜索引擎的一般信息。 有效值可以是始終、每小時、每天、每週、每月、每年、從不。
應該記住,這個標籤的值更多地被認為是一個提示而不是一個命令。 機器人看到這些信息並將其考慮在內,但最終會自行決定是否使用它,這取決於許多其他因素。
- – 將 URL 優先於您網站上的其他 URL。 有效值範圍為 0.0。 到 1.0。
在這裡,應該記住,這個優先級是相對的,不是機器人的強制性條件,或者至少還沒有被接受。 但是,如果您決定嘗試一下,請使用以下指南:
- 0 – 0.3:過時的新聞,不再有效但在歷史上有用的信息;
- 4 – 0.7:博客文章、頁麵類別、常見問題;
- 8 – 1.0:主頁、產品頁面、所有內容優化良好的頁面。
以下示例顯示了一個站點地圖,其中僅包含一個 URL,並使用了所有以斜體書寫的可選標籤。
https://netpeak.bg
2018-09-15
每月
0.8
識別重要頁面
添加高質量頁面和優化良好的頁面。 整體質量對於更好的排名非常重要。 這是谷歌的一個重要因素,它可以讓你在競爭中獲得優先權。
我們不想訪問低質量的頁面,谷歌機器人也不想。 如果您將其引導至數千個對用戶無用且未得到很好優化的頁面,則這只會對您造成傷害。 什麼是高質量頁面? 簡而言之,這些頁面是:
- 有足夠的獨特內容;
- 通過提示採取行動(評論、評論等)快速吸引用戶;
- 包括圖片、視頻等;
- 不違反 Google 政策;
為索引打開的頁面
爬取預算一般代表單位時間(天、週、月等)爬取的頁面數。 因此,不建議不必要地浪費它。
不應將包含“Noindex”元標記的頁面添加到站點地圖中。 遵循邏輯順序對一切都很重要。
有必要進行自動檢查,並且不包括為索引而關閉的地址。
建議遵循以下說明:
- 如果頁面 https://example.com/category/product 有元標記“noindex”,則不應包含在站點的 XML 映射中;

- 當通過 robots.txt 關閉頁面以進行索引時,它不應包含在 XML 映射中:
不允許:/類別/產品
無索引:/類別/產品
- 如果通過 HTTP 標頭中的 X-Robots-Tag 關閉頁面以進行索引,則它也不應該包含在站點的 XML 映射中:
HTTP/1.1 200 正常
日期:格林威治標準時間 2010 年 5 月 25 日星期二 21:42:43
(……)
X-Robots-標籤:noindex
(……)
頁面的規範版本
通過具有相似內容的多個 URL 訪問單個頁面將被 Google 視為重複。
您必須使用“link rel canonical”屬性來指示機器人哪個是“主”頁面,應該對哪個頁面進行爬網和索引。

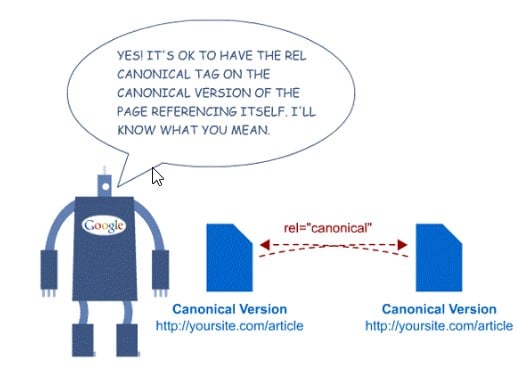
例如,如果頁面 https://example.com/category/product-1 對 https://example.com/product 具有規範,則 http://example.com/category/product-1 不應參與XML 站點地圖。
您應該執行自動檢查,因為流程的自動化肯定會給您帶來更少的麻煩並節省您進行手動檢查的時間。
返回 200 OK 的頁面
包括返回 200 OK 響應的地址。 進行自動檢查並且不包括返回 200 OK 以外的響應的地址(例如 404、301 等)非常重要。
例如,如果頁面 https://example.com/product 返回的響應不是 200 OK,則它不應參與站點地圖。

您可以使用以下工具進行檢查:https://soft.galinov.com/ 進行檢查。
來自分頁的頁面
不必在 sitemap.xml 中絕對包含所有頁面。 如果描述正確,該機器人足夠聰明,可以從相關類別的第一頁導航。 建議執行以下操作:
- 僅包括類別的主頁;
- 用 rel = next / rel = prev 標記頁面,以便機器人可以看到它們之間的連接;
- 分頁的每一頁都應該有自己的規範指南,而不是主頁,因為如果反過來,這意味著你告訴機器人“我有 5,000 個產品和 20 個頁面並不重要,他們和第一個一樣。”
例如,頁面 https://example.com/category/page-2 不應參與地圖。 在這裡你可以找到谷歌的官方意見,以及他們的建議:
最小化文件大小
2016 年,Google 和 Bing 將文件大小從 10MB 增加到 50MB,但保持站點地圖盡可能小仍然是一個好習慣。

當然,這沒什麼好擔心的,但是如果您的站點地圖包含超過 50,000 個 URL 或大小超過 50MB,則應該將其分解為更多的 XML 地圖。 在這種情況下,應在單獨的站點地圖索引文件中描述對所有 XML 地圖的引用。
什麼是 XML 站點地圖索引文件
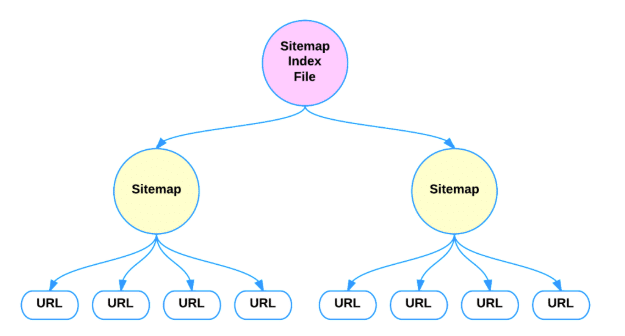
您可以提交多個 Sitemap 文件,但每個文件必須符合上述規則。 如果需要,您可以根據需要使用 gzip 壓縮文件以減小其大小。
索引文件的 XML 格式與正常的站點地圖格式非常相似。 它必須包含:
- 打開和關閉標籤為 ;
- 每個站點地圖的條目,其主要 XML 屬性為;
- 標記到主要屬性。
還包括推薦的屬性。
注意:站點地圖索引文件只能列出同一站點上的地圖。 例如:
https://example.com/sitemap_index.xml 可能包含位於 https://example.com 的地圖,但不包含位於 https://www.saitprimer.com 或 https://www.example.com 的地圖
與所有其他文件一樣,索引文件必須使用 UTF-8 編碼。
以下示例顯示了列出兩個地圖的站點地圖索引:
http://www.example.com/sitemap1.xml.gz
2018-10-01T18:23:17+00:00
http://www.example.com/sitemap2.xml.gz
2017-01-01
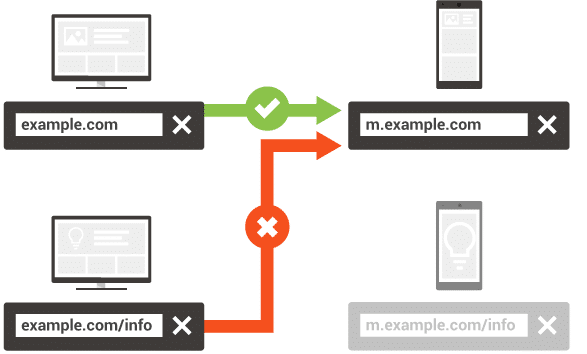
手機版說明
我們需要幫助 Google bot 找到我們的內容並了解桌面和移動頁面之間的聯繫。 在 XML 站點地圖中,必須為桌面版頁面添加 rel = “alternate” 屬性,如下所示:
xmlns:xhtml=”http://www.w3.org/1999/xhtml”>
http://www.example.com/page-1/
<xhtml:鏈接
相對=“替代”
媒體=“僅屏幕和(最大寬度:640px)”
href="http://m.example.com/page-1" />
請記住,每個桌面頁面需要對應一個移動版本的頁面。 例如,不建議通過 rel = “alternate” 將多個桌面頁面鏈接到移動版本的一個頁面,反之亦然。
您還必須檢查重定向。 重要的是桌面頁面對應移動版本中的相同內容,而不是重定向到另一個。 附加信息在這裡。
機器人如何找到您的 XML 站點地圖
當您完成該過程的所有自動化並將其上傳到您的服務器(或通過插件生成)後,您需要留下一個線索,機器人可以在哪裡找到它。
最好的方法是在您的 robots.txt 文件中包含指向它的鏈接。 這也稱為 Sitemap Discovery,它是 Google、Bing 和 Yahoo 早在 2007 年推出的,旨在幫助他們的機器人找到 XML Sitemaps。
您所要做的就是包含地圖或索引文件的完整路徑。

地址的正確音譯
Google 官方文檔(構建並提交站點地圖)強調所有數據值(包括 URL)必須僅包含 ASCII 字符。 它不能包含控制代碼或特殊字符,例如 * 或 {}。
如果您網站的 URL 包含這些字符,當您嘗試添加它時會收到錯誤消息。
將您的地圖提交給 Google
您可以通過 Google Search Console 將您的站點地圖提交給 Google。
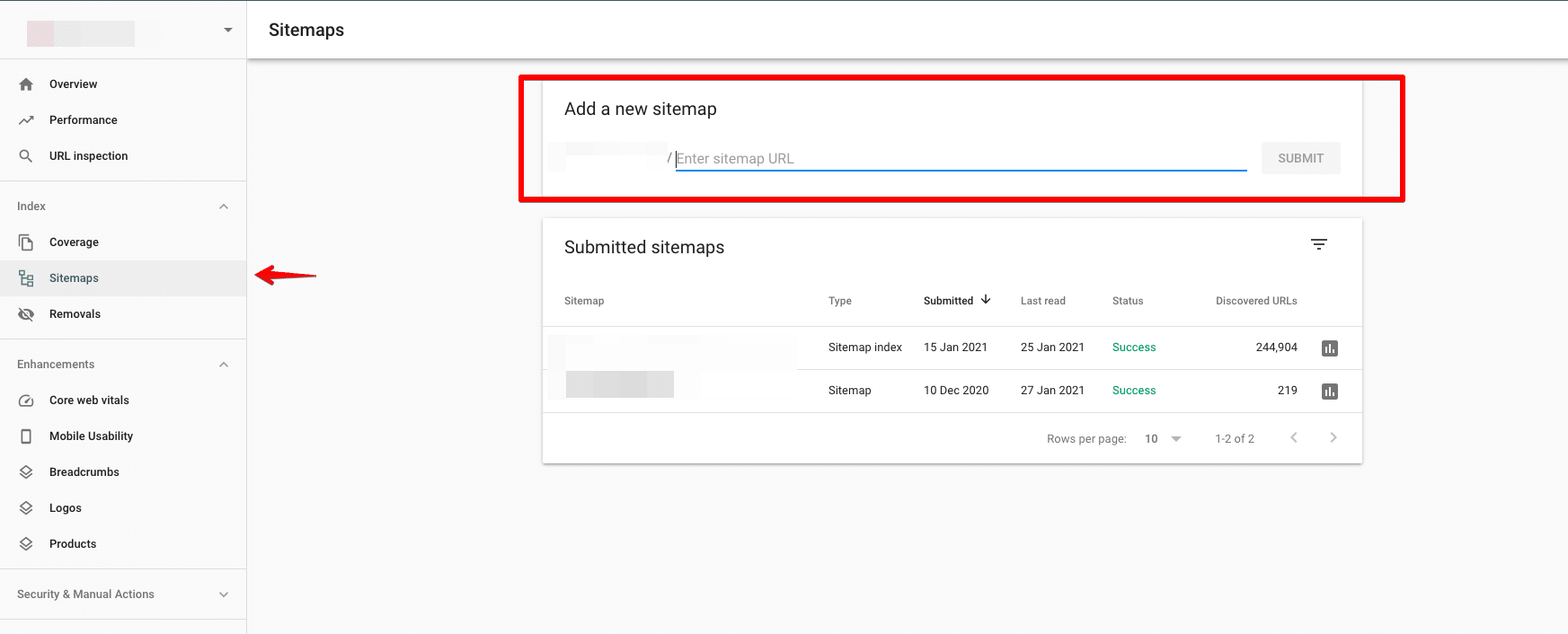
提交前檢查是否有任何錯誤。 清除可能阻礙索引關鍵目標網頁的任何錯誤非常重要。
理想情況下,索引頁數應等於提交的頁數。
結論
- 保持一致——如果頁面被 robots.txt 或“noindex”阻止,最好不要出現在您的 XML 映射中。
- 自動化您的流程 - 上述所有建議都應可用於自動化,因為這將節省您的時間,幫助抓取預算保持優化,並為您省去很多麻煩。
- 如果您有一個非常大的網站,請使用具有不同地圖的索引文件,這將節省您的服務器時間並涵蓋您網站上的所有重要頁面。