
什麼是詞向量以及結構化標記如何增強它們
已發表: 2021-07-28你如何定義詞向量? 在這篇文章中,我將向您介紹詞向量的概念。 我們將討論不同類型的詞嵌入,更重要的是,詞向量是如何工作的。 然後,我們將能夠看到詞向量對 SEO 的影響,這將引導我們了解結構化數據的 Schema.org 標記如何幫助您利用 SEO 中的詞向量。
如果您想了解有關這些主題的更多信息,請繼續閱讀這篇文章。
讓我們潛入水中。
什麼是詞向量?
詞向量(也稱為詞嵌入)是一種詞表示,它允許具有相似含義的詞具有相等的表示。
簡單來說:詞向量是特定詞的向量表示。
根據維基百科:
它是自然語言處理 (NLP) 中用於表示用於文本分析的單詞的一種技術,通常作為一個實值向量,對單詞的含義進行編碼,以便在向量空間中接近的單詞可能具有相似的含義。
下面的例子將幫助我們更好地理解這一點:
看看這些類似的句子:
祝你有美好的一天。 祝你有美好的一天。
它們幾乎沒有不同的含義。 如果我們構建一個詳盡的詞彙表(我們稱之為 V),它將有 V = {Have, a, good, great, day} 組合所有單詞。 我們可以對這個詞進行如下編碼。
一個詞的向量表示可以是一個one-hot 編碼向量,其中 1 表示詞存在的位置,0 表示其餘部分
有 = [1,0,0,0,0]
a=[0,1,0,0,0]
好=[0,0,1,0,0]
偉大的=[0,0,0,1,0]
天=[0,0,0,0,1]
假設我們的詞彙表只有五個詞:King、Queen、Man、Women 和 Child。 我們可以將單詞編碼為:
國王 = [1,0,0,0,0]
皇后 = [0,1,0,0,0]
人 = [0,0,1,00]
女人 = [0,0,0,1,0]
孩子 = [0,0,0,0,1]
詞嵌入的類型(詞向量)
Word Embedding 就是這樣一種技術,其中向量表示文本。 以下是一些比較流行的詞嵌入類型:
- 基於頻率的嵌入
- 基於預測的嵌入
我們不會在這裡深入探討基於頻率的嵌入和基於預測的嵌入,但您可能會發現以下指南有助於理解兩者:
對詞嵌入的直觀理解以及用於從文本創建特徵的詞袋 (BOW) 和 TF-IDF 快速介紹
WORD2Vec簡介
雖然基於頻率的嵌入已經流行起來,但在理解單詞的上下文方面仍然存在空白,並且在單詞表示方面受到限制。
基於預測的嵌入 (WORD2Vec) 由 Google 的 Tomas Mikolov 領導的一組研究人員於 2013 年創建、獲得專利並被引入 NLP 社區。
根據維基百科,word2vec 算法使用神經網絡模型從大量文本語料庫(大型結構化文本集)中學習單詞關聯。
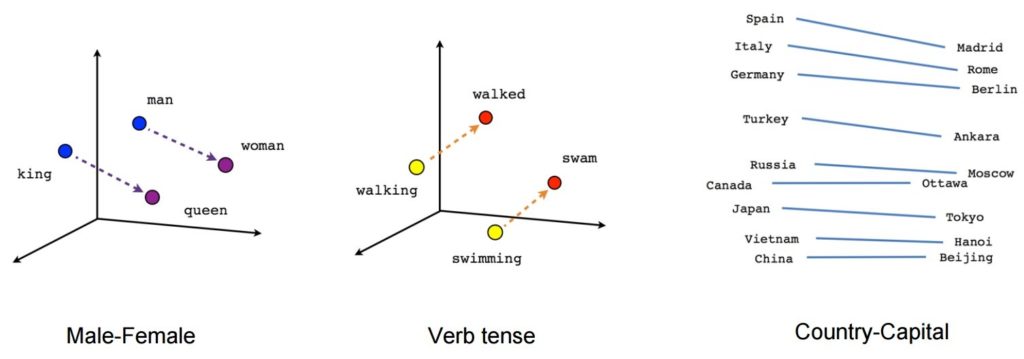
一旦經過訓練,這樣的模型就可以檢測同義詞或為部分句子建議額外的詞。 例如,使用 Word2Vec,您可以輕鬆創建這樣的結果:國王 - 男人 + 女人 = 女王,這被認為是一個近乎神奇的結果。
 圖片來源:張量流
圖片來源:張量流
- [king] – [man] + [woman] ~= [queen] (另一種思考方式是 [king] – [queen] 只編碼 [monarch] 的性別部分)
- [walking] – [swimming] + [swam] ~= [walked](或 [swam] – [swimming] 只是編碼動詞的“過去時”)
- [馬德里] – [西班牙] + [法國] ~= [巴黎](或 [馬德里] – [西班牙] ~= [巴黎] – [法國] 大概大致是“首都”)
資料來源:Brainslab Digital
我知道這有點技術性,但 Stitch Fix 整理了一篇關於語義關係和詞向量的精彩文章。
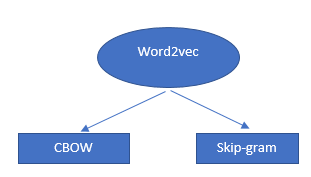
Word2Vec 算法不是一個單一的算法,而是兩種技術的組合,它使用一些人工智能方法來連接人類理解和機器理解。 這種技術對於“解決”許多“NLP”問題至關重要。
這兩種技術是:
- – CBOW(連續詞袋)或 CBOW 模型
- – 跳過語法模型。
兩者都是淺層神經網絡,可為單詞提供概率,並且已被證明在單詞比較和單詞類比等任務中很有幫助。
詞向量和 word2vecs 的工作原理
Word Vector 是 Google 開發的 AI 模型,它可以幫助我們解決非常複雜的 NLP 任務。
“詞向量模型有一個你應該知道的核心目標:
它是一種算法,可以幫助谷歌檢測單詞之間的語義關係。”
每個單詞都被編碼在一個向量中(以多維表示的數字)以匹配出現在相似上下文中的單詞向量。 因此,為文本形成了一個密集向量。
這些向量模型基於思想和語言的等價性、相似性或相關性將語義相似的短語映射到附近的點
[案例研究] 通過頁面 SEO 推動新市場的增長
 閱讀案例研究
閱讀案例研究Word2Vec- 它是如何工作的?
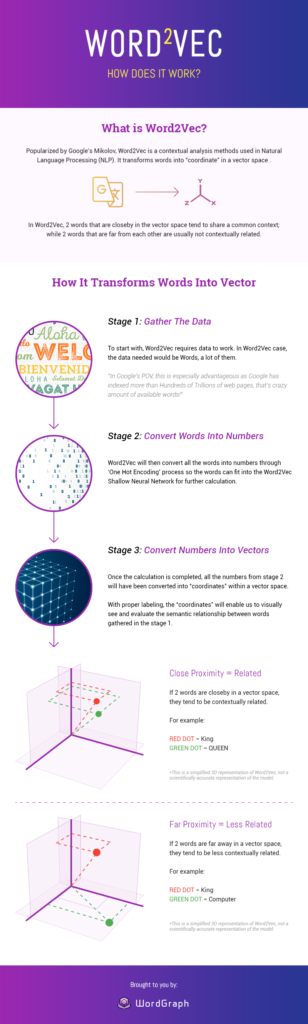
圖片來源:Seopressor
Word2Vec 的優缺點
我們已經看到 Word2vec 是一種非常有效的生成分佈相似度的技術。 我在這裡列出了它的一些其他優點:
- 理解 Word2vec 的概念並不難。 Word2Vec 並不復雜,以至於您不知道幕後發生了什麼。
- Word2Vec 的架構非常強大且易於使用。 與其他技術相比,它的訓練速度很快。
- 訓練在這裡幾乎是完全自動化的,因此不再需要人工標記的數據。
- 該技術適用於小型和大型數據集。 因此,它是一個易於縮放的模型。
- 如果您了解這些概念,則可以輕鬆複製整個概念和算法。
- 它非常好地捕獲了語義相似性。
- 準確且計算效率高
- 由於這種方法是無監督的,因此在工作量方面非常節省時間。
Word2Vec 的挑戰
Word2vec 概念非常有效,但您可能會發現有幾點有點挑戰性。 以下是一些最常見的挑戰。
- 在為您的數據集開發 word2vec 模型時,調試可能是一項重大挑戰,因為 word2vec 模型易於開發但難以調試。
- 它不處理歧義。 因此,對於具有多種含義的單詞,Embedding 將反映這些含義在向量空間中的平均值。
- 無法處理未知或 OOV 詞:word2vec 的最大問題是無法處理未知或詞彙外 (OOV) 詞。
詞向量:搜索引擎優化的遊戲規則改變者?
許多 SEO 專家認為 Word Vector 會影響網站在搜索引擎結果中的排名。
在過去五年中,谷歌推出了兩項算法更新,明確關注內容質量和語言全面性。

讓我們退後一步,談談更新:
蜂鳥
2013年,蜂鳥賦予搜索引擎語義分析能力。 通過在他們的算法中利用和結合語義理論,他們開闢了一條通往搜索世界的新道路。
谷歌蜂鳥是自 2010 年咖啡因以來搜索引擎的最大變化。它的名字來源於“精確和快速”。
根據 Search Engine Land 的說法,Hummingbird 更加關注查詢中的每個單詞,確保考慮到整個查詢,而不僅僅是特定的單詞。
Hummingbird 的主要目標是通過了解查詢的上下文而不是返回特定關鍵字的結果來提供更好的結果。
“谷歌蜂鳥於 2013 年 9 月發布。”
RankBrain
2015 年,谷歌宣布了 RankBrain,這是一種結合人工智能 (AI) 的戰略。
RankBrain 是一種算法,可幫助 Google 將復雜的搜索查詢分解為更簡單的查詢。 RankBrain 將搜索查詢從“人類”語言轉換為 Google 可以輕鬆理解的語言。
谷歌於 2015 年 10 月 26 日在彭博社發表的一篇文章中確認了 RankBrain 的使用。
BERT
2019 年 10 月 21 日,BERT 開始在 Google 的搜索系統中推出
BERT 代表 Transformers 的雙向編碼器表示,這是一種基於神經網絡的技術,被 Google 用於自然語言處理 (NLP) 的預訓練。
簡而言之,BERT 幫助計算機更像人類理解語言,這是谷歌引入 RankBrain 以來搜索領域最大的變化。
它不是 RankBrain 的替代品,而是一種用於理解內容和查詢的附加方法。
谷歌在其排名系統中使用 BERT 作為補充。 RankBrain 算法對於某些查詢仍然存在,並將繼續存在。 但是當谷歌認為 BERT 可以更好地理解查詢時,他們會使用它。
有關 BERT 的更多信息,請查看 Barry Schwartz 的這篇文章,以及 Dawn Anderson 的深入研究。
使用詞向量對您的網站進行排名
我假設您已經創建並發布了獨特的內容,即使經過一遍又一遍的潤色,它也不會提高您的排名或流量。
你想知道為什麼這會發生在你身上嗎?
可能是因為您沒有包含 Word Vector:Google 的 AI 模型。
- 第一步是為您的利基識別前 10 個 SERP 排名的詞向量。
- 了解您的競爭對手使用的關鍵字以及您可能忽略的關鍵字。
通過應用利用先進的自然語言處理技術和機器學習框架的 Word2Vec,您將能夠詳細查看所有內容。
但如果您了解機器學習和 NLP 技術,這些都是可能的,但我們可以使用以下工具在內容中應用詞向量:
WordGraph,世界上第一個詞向量工具
該人工智能工具是使用用於自然語言處理的神經網絡創建的,並使用機器學習進行訓練。
WordGraph 基於人工智能分析您的內容並幫助您提高其與排名前 10 位網站的相關性。
它建議與您的主要關鍵字在數學和上下文相關的關鍵字。
就我個人而言,我將它與 BIQ 配對,這是一個強大的 SEO 工具,可以很好地與 WordGraph 配合使用。
將您的內容添加到 Biq 內置的內容智能工具。 它將向您顯示頁面上的 SEO 提示的完整列表,如果您想排名最高,您可以添加這些提示。
您可以在此示例中了解內容智能的工作原理。 這些列表將幫助您掌握頁面 SEO 並使用可行的方法進行排名!
如何增強詞向量:使用結構化數據標記
Schema 標記或結構化數據是一種使用 schema.org 詞彙創建的代碼(以 JSON、Java-Script Object Notation 編寫),可幫助搜索引擎抓取、組織和顯示您的內容。
如何添加結構化數據
通過在 html 中添加內聯腳本,可以輕鬆地將結構化數據添加到您的網站
下面的示例顯示瞭如何以最簡單的格式定義組織的結構化數據。
為了生成模式標記,我使用了這個模式標記生成器 (JSON-LD)。
這是 https://www.telecloudvoip.com/ 的架構標記的實時示例。 檢查源代碼並蒐索 JSON。
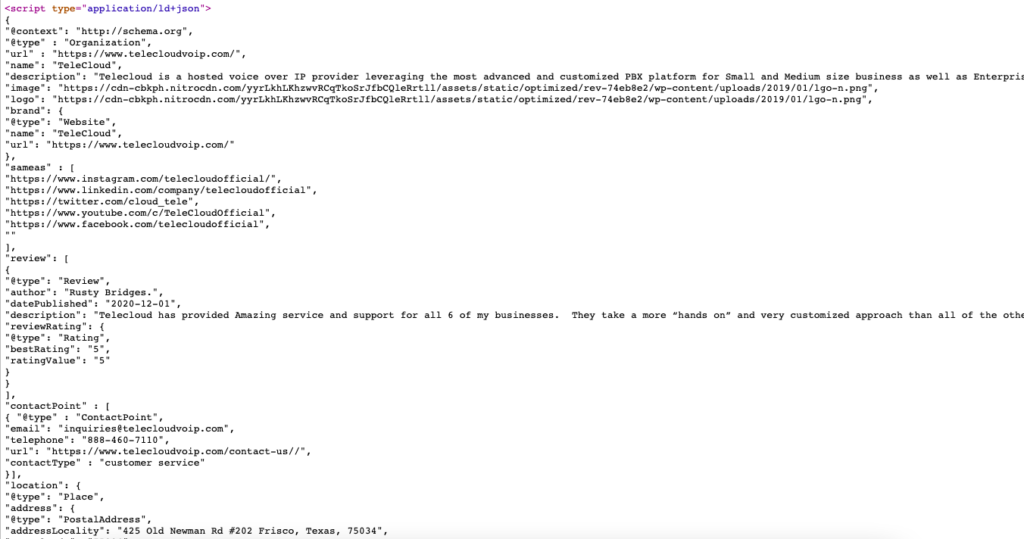
創建架構標記代碼後,使用 Google 的富結果測試來查看頁面是否支持富結果。
您還可以使用 Semrush Site Audit 工具來探索每個 URL 的結構化數據項,並確定哪些頁面有資格出現在 Rich Results 中。 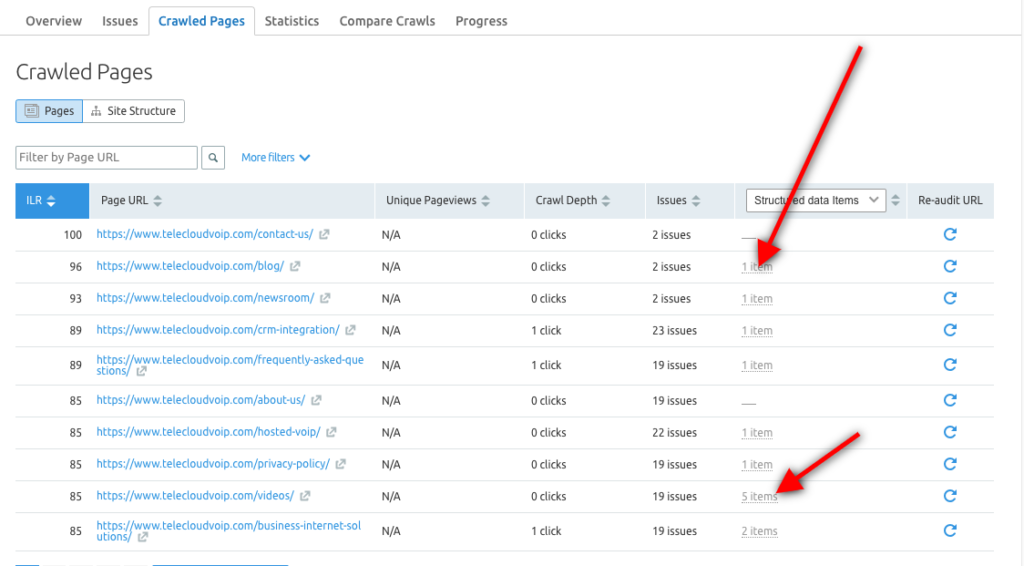
為什麼結構化數據對 SEO 很重要?
結構化數據對於 SEO 很重要,因為它可以幫助 Google 了解您的網站和頁面的內容,從而對您的內容進行更準確的排名。
結構化數據通過提供更多信息和準確性來改進 SERP(搜索引擎結果頁面),從而改善了 Search Bot 的體驗和用戶體驗。
要查看對 Google 搜索的影響,請轉到 Search Console 並在性能 > 搜索結果 > 搜索外觀下,您可以查看所有富媒體搜索結果類型的細分,例如“視頻”和“常見問題解答”,並查看它們帶來的自然展示次數和點擊次數為您的內容。
以下是結構化數據的一些優點:
- 結構化數據支持語義搜索
- 它還支持您的 E-AT(專業知識、權威性和信任)
- 擁有結構化數據還可以提高轉化率,因為更多的人會看到您的列表,這增加了他們向您購買的可能性。
- 使用結構化數據,搜索引擎能夠更好地了解您的品牌、網站和內容。
- 搜索引擎將更容易區分聯繫頁面、產品描述、食譜頁面、活動頁面和客戶評論。
- 在結構化數據的幫助下,Google 構建了一個更好、更準確的關於您的品牌的知識圖譜和知識面板。
- 這些改進可以帶來更多的自然印象和自然點擊。
Google 目前使用結構化數據來增強搜索結果。 當人們使用關鍵字搜索您的網頁時,結構化數據可以幫助您獲得更好的結果。 如果我們添加 Schema 標記,搜索引擎會更多地註意到您的內容。
您可以在許多不同的項目上實現模式標記。 下面列出了可以應用模式的幾個領域:
- 文章
- 博客文章
- 新聞文章
- 活動
- 產品
- 視頻
- 服務
- 評論
- 綜合評分
- 餐廳
- 本地企業
這是您可以使用模式標記的項目的完整列表。
具有實體嵌入的結構化數據
術語“實體”是指任何類型的對象、概念或主體的表示。 實體可以是人、電影、書籍、想法、地點、公司或事件。
雖然機器無法真正理解單詞,但通過實體嵌入,它們能夠輕鬆理解國王 - 王后 = 丈夫 - 妻子之間的關係
實體嵌入比 one-hot 編碼表現更好
谷歌使用詞向量算法來發現詞之間的語義關係,當與結構化數據結合時,我們最終得到了一個語義增強的網絡。
通過使用結構化數據,您正在為更加語義化的網絡做出貢獻。 這是一個增強的網絡,我們在其中以機器可讀的格式描述數據。
您網站上的結構化語義數據有助於搜索引擎將您的內容與正確的受眾相匹配。 NLP、機器學習和深度學習的使用有助於縮小人們搜索的內容與可用標題之間的差距。
最後的想法
當您現在了解詞向量的概念及其重要性時,您可以通過利用詞向量、實體嵌入和結構化語義數據使您的有機搜索策略更加有效和高效。
為了獲得最高的排名、流量和轉化,您必須使用詞向量、實體嵌入和結構化語義數據向 Google 證明您網頁上的內容是準確、精確和值得信賴的。