
什麼是語義網,它是如何工作的?
已發表: 2018-02-14
快速導航
- 介紹
- 語義網是如何工作的?
- 1.語義網有助於信息檢索
- 2.語義網回答複雜問題
- 3.它執行自動摘要
- 4. 共享數據:語義網示例
- 關於語義網的最終想法
介紹
我們如何使用互聯網?
我們將其用於信息檢索、回答問題、廣告和發現。
雖然人類能夠看到實體、信息和數據之間的關係,但計算機沒有這種天生的能力。
如果網絡要為互聯網用戶提供相關結果,則迫切需要計算機能夠識別這些關係。
這就是語義網(也稱為 web 3.0)的用武之地。
準備好一個語義網絡演示文稿,它將定義語義網絡,就像它沒什麼大不了的,並幫助您了解這一切是什麼?
去吧!
語義網是如何工作的?
想知道什麼是語義網?
然後閱讀並了解語義網的一些優勢!
1.語義網有助於信息檢索
大數據和語義網。

語義網和信息系統之間有什麼關係?
語義網和大數據如何協同工作?
簡單的!
語義網將數據和信息存儲在知識圖中。
例如,“Barack Obama”被存儲為與“Michelle Obama”和“Malia”相關。
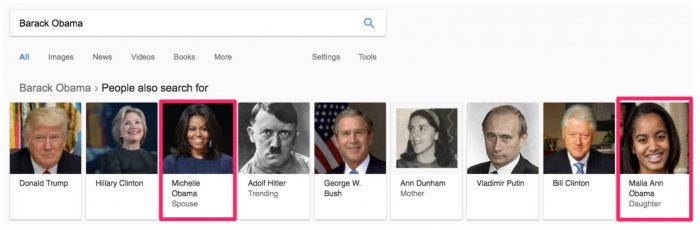
當您搜索“巴拉克奧巴馬的妻子”時,搜索結果應該返回“米歇爾奧巴馬”。
兩人的關係是“夫妻”。
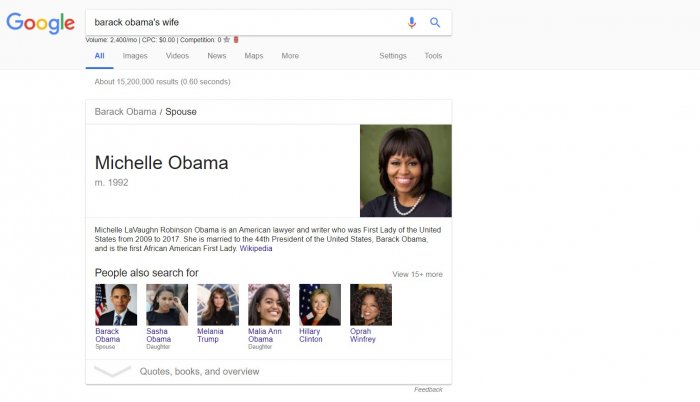
這個唯一標識符有助於創建兩個實體之間的關係。
語義網的這一方面將有助於提高搜索查詢的特異性以及檢索到的信息,以便提供更準確的搜索結果。
在當前網絡時代,計算機執行我們所謂的“例行處理”。
《科學美國人》上的 Tim Berners-Lee 爵士解釋說:
“當今大多數網絡內容都是為人類閱讀而設計的,而不是讓計算機程序進行有意義的操作。 計算機可以熟練地解析網頁以進行佈局和常規處理,這裡是標題,那裡是到另一個頁面的鏈接,但一般來說,計算機沒有可靠的方法來處理語義。”
這意味著——要檢索有關“奧巴馬家族”的信息——計算機必須爬取多個網頁。
語義網允許在創建過程中將此數據編碼到網絡中。
因此,檢索將更快、更準確。
2.語義網回答複雜問題
任何語義網定義都必須始終處理本體的含義。
這些對於理解網絡語義、語義網絡的應用以及語義網絡的含義至關重要。
你問什麼是語義網絡本體?

本體是語義網的基本組成部分。
這些是定義術語之間關係的文件。
本體有助於將數據和信息分類為類別或分類法。
讓我們給你一個語義網絡的例子,讓你得到一個清晰的畫面。
例如,可以將包含郵政編碼的信息歸類為位置。
如果郵政編碼也被歸類為位置會發生什麼?
我們最終可能會將郵政編碼與郵政編碼混淆。
對於不同的代碼,我們需要有兩種不同的本體。
本體將使計算機更容易將網頁上的信息與指導推理的相關知識圖和規則聯繫起來。
一個很好的例子是關於藝術家的信息。
您很容易找到指向藝術家傳記的鏈接,該鏈接指向他們的淨資產。
一台計算機需要相當先進,才能“猜測”出這條信息可以在傳記信息中找到。
語義網將使此類複雜問題的處理變得更加容易,並使得響應迅速傳遞。
本體之間的關係將表明藝術家確實有淨資產,因此計算機將檢查具有淨資產的本體並檢索特定藝術家的信息。
當前的網絡根據父子關係對分類中的信息進行分類。

這種存儲數據的方式還定義了實體之間的關係。
分類法和本體之間的唯一區別是前者俱有非常嚴格的結構,在獲取信息和交付結果時變得有限制。
後者呢?
它具有非常靈活的結構,實際上允許在實體之間識別非常複雜的關係。
通過這種方式,可以相對輕鬆地回答複雜的問題。
準備好了解語義網的其他一些優勢了嗎?
那麼,做一些語義網絡講義吧!
閱讀!
3.它執行自動摘要
借助語義網,可以根據從內容中提取的事實來總結搜索結果。
一個很好的例子是基於位置。

使這成為可能的語義網概念稱為“代理”。
這些是從各種來源收集內容、對其進行處理並與其他程序交換的程序。

這種協同作用將有助於創造證據。
這些證明是用一種統一的語言編寫的,該語言指定了上面討論的本體中的規則。
例如,如果您正在尋找您在活動中遇到的人,並且您可能只記得他們的名字、職業和城市,您可以通過在線服務找到他們。
您想確認您是否能夠找到合適的人。
使用語義網,您的計算機可以要求提供返回結果的證明。
將有一個推理引擎來驗證您是否找到了您正在尋找的人。
也可以顯示相關網頁以供進一步證明。
數字簽名還將有助於驗證信息是否來自受信任的來源。
簽名是加密的數據塊。
他們會有所幫助,尤其是在處理敏感的個人信息(如財務)方面。
如果您在電子郵件中收到對帳單,數字簽名和代理將是確保它確實來自您的銀行的好方法。
代理商將能夠通過向價值鏈添加信息來證明。
語義網允許代理交換本體。
這樣,它們就有了一個共同的參考點。
他們甚至能夠在新本體的幫助下創建更多解決方案。
以下是 Tim Berners-Lee 爵士關於語義網的科學美國人研究論文中關於如何簡化語義網的精彩總結:
“語義網將為網頁的有意義的內容帶來結構,創造一個環境,讓在頁面之間漫遊的軟件代理可以輕鬆地為用戶執行複雜的任務。 這樣一個訪問診所網頁的代理人不僅會知道該頁面有諸如“治療、藥物、物理、治療”之類的關鍵字(就像今天可能編碼的那樣),而且還會知道 Hartman 博士每週一、週三在這家診所工作和星期五,並且腳本採用 yyyy-mm-dd 格式的日期範圍並返回約會時間。 它會“知道”這一切,而不需要像 2001 年的 Hal 或星球大戰的 C-3PO 那樣規模的人工智能。 相反,當診所的辦公室經理(從未使用 Comp Sci 101)使用現成的軟件編寫語義網頁以及物理治療協會網站上列出的資源時,這些語義被編碼到網頁中。 ”
4. 共享數據:語義網示例
共享數據的概念與前一點討論的證明密切相關。
當我們談論在語義網絡技術中共享數據時,最接近的概念是社交媒體平台。
需要在個人資料中填寫個人信息,例如您的姓名、出生日期、職業,甚至位置。
為了使語義網發揮作用,需要廣泛共享數據。
更好的是:
它需要以機器可讀的方式共享。
在我們目前的情況下——當涉及到語義網和大數據時——沒有足夠的來自個人和組織的數據。
如果有足夠的數據,人類將永遠不需要搜索數據頁面並確定什麼是相關的,什麼是不相關的。
Web 3.0 允許我們以機器可讀的方式互連數據。
這樣,計算機只會獲取信息並將其提供給您。

隨著 web 3.0 的不斷發展,個人和組織在共享數據時將更加自信。
一旦有足夠的數據,提供結果和打樣將變得更容易和更直接。
但是,重要的是要注意收集的數據需要結構化。
隨著語義網的發展,公司和組織需要構建他們現在可以訪問的數據。
然後他們需要創建知識圖譜。
隨著越來越多的公司這樣做,web 3.0 將成為現實。
關於語義網的最終想法
喜歡這個語義網絡教程嗎?
享受這個機會,終於能夠理解語義網技術可以做什麼?
驚人的!
語義網將創造一個更美好的世界,在盡可能短的時間內將信息直接提供給用戶。
對於工作的本體論者來說,語義網的力量是無限的。
怎麼會這樣?
由於信息將存儲在本體中,因此很容易檢索它。
為什麼?
因為實體之間的關係定義明確且易於追溯。
我們必須開始利用我們可以訪問的數據並以結構化的方式存儲它。
當 web 3.0 最終啟動時,我們無疑將遙遙領先。