在線對照實驗中的元分析:公正地看待這種科學方法的力量和局限性
已發表: 2022-09-28
元分析在 A/B 測試和其他在線實驗中有多有用?
它有助於利用過去的學習來改進你的假設生成嗎? 或者元分析只是一個懶惰的藉口,簡單地依賴“經過驗證的模式”,而不是基於特定情況的數據通過經驗在您的業務中進行創新?
這是一個熱議的話題。 有些人讚成,有些人強烈反對。 但是,您如何才能從這兩種觀點中受益,並為您的實驗計劃帶來切實的價值呢?
這就是這篇文章的內容。 在裡面,你會
- 了解什麼是元分析
- 查看實際中的元分析示例
- 發現為什麼必須謹慎(和尊重)對待元分析作為一個概念,以及
- 了解實驗團隊如何以正確的方式進行元分析
還有一個好處:您還會看到兩位著名的轉化率優化專家從相反的角度討論這個問題。
讓我們開始吧。
- 什麼是元分析?
- 在線對照實驗中的元分析示例
- 有興趣進行自己的 A/B 測試元分析嗎?
- 元分析——是或否
- 元分析——謹慎行事?
- 不妥協測試嚴謹性和追求創新
- 元分析——給實驗飛輪上油?
- 元分析——謹慎行事?
- 如果您選擇進行(和使用)元分析——請記住以下幾點
- 分析中包含的實驗質量差
- 異質性
- 發表偏倚
什麼是元分析?
元分析使用統計數據通過分析多個實驗結果做出決定。 它來自科學界,研究人員將針對同一問題的醫學研究結果匯總在一起,並使用統計分析來判斷效果是否真的存在以及它的重要性。
在在線控制實驗中,我們有 A/B 測試、多變量測試和拆分測試來製定決策和尋找實現業務目標的最佳方法,我們藉用元分析來利用我們已經從之前學到的東西測試以通知未來的測試。
讓我們看看不同的例子。
在線對照實驗中的元分析示例
以下是 A/B 測試中元分析的 3 個示例,它是如何使用的,以及在每項工作中發現了什麼:
- Alex P. Miller 和 Kartik Hosanagar對電子商務 A/B 測試策略的實證元分析
這份 A/B 測試元分析於 2020 年 3 月發布。分析師專門研究了電子商務行業的測試,他們從 SaaS A/B 測試平台收集了數據。 它包括 2,732 次 A/B 測試,由 252 家美國電子商務公司在 3 年內跨 7 個行業進行。
他們分析了這些測試,以提供對測試如何在電子商務轉換漏斗的各個階段進行定位的可靠分析。
他們發現的是:
- 與其他實驗類型相比,價格促銷測試和類別頁面上的測試與最大的影響大小相關聯。
- 消費者對不同促銷的反應取決於這些促銷在電子商務網站中的位置。
- 雖然有關產品價格的促銷在轉化渠道的早期最有效,但與運輸相關的促銷在轉化渠道的後期(在產品頁面和結帳上)最有效。
讓我們看另一個例子,以及研究人員發現了什麼……
- 什麼在電子商務中有效——Will Browne 和 Mike Swarbrick Jones 對 6,700 個實驗的薈萃分析
Browne 和 Jones 使用來自零售和旅遊行業的 6,700 個大型電子商務實驗的數據,研究了 29 種不同類型的變化的影響,並估計了它們對收入的累積影響。 它於 2017 年 6 月發布。
正如論文標題所暗示的那樣,目標是通過運行大型元分析來探索電子商務中的有效方法。 這就是他們如何得出這個強有力的總結:與基於行為心理學的變化相比,網站外觀的變化對收入的影響可以忽略不計。
每位訪問者的收入 (RPV) 指標用於衡量這種影響。 因此,在他們的結果中,實驗的 +10% 提升意味著 RPV 在該實驗中上升了 10%。
以下是分析中的其他一些發現:
- 表現最好的(按類別)是:
- 稀缺性(股票指標,例如,“僅剩 3 個”):+2.9%
- 社交證明(告知用戶他人的行為):+2.3%
- 緊迫性(倒計時):+1.5%
- 放棄恢復(向用戶發送消息讓他們留在網站上):+1.1%
- 產品推薦(追加銷售、交叉銷售等):+0.4%
- 但是對 UI 的外觀更改(如下所示)無效:
- 顏色(改變網頁元素的顏色):+0.0%
- 按鈕(修改網站按鈕):-0.2%
- 號召性用語(更改文本):-0.3%
- 90% 的實驗對收入的影響不到 1.2%,無論是正面的還是負面的
- 幾乎沒有證據表明 A/B 測試會導致案例研究中常見的兩位數收入增長。
現在等待。 在你把這些薈萃分析結果當成福音之前,你需要知道在線實驗的薈萃分析是有局限性的。 我們稍後再談。
- Georgi Georgiev對 GoodUI.org 上 115 個 A/B 測試的元分析
2018 年 6 月,在線實驗專家、《在線 A/B 測試中的統計方法》作者 Georgi Georgiev 在 GoodUI.org 上分析了 115 個公開可用的 A/B 測試。
GoodUI.org 發布了一系列實驗結果,包括新發現的 UI 模式以及 Amazon、Netflix 和 Google 等實驗驅動的公司從他們的測試中學到了什麼。
Georgi 的目標是整理和分析這些數據,以揭示測試的平均結果,並在設計和執行 A/B 測試的元分析時提供關於更好的統計實踐的想法。
他首先修剪初始數據集並進行一些統計調整。 其中包括刪除:
- 被派去體驗控制的用戶數量與被派去體驗挑戰者的用戶數量之間不平衡的測試,以及
- 妥協的測試(通過他們不切實際的低統計能力發現)。
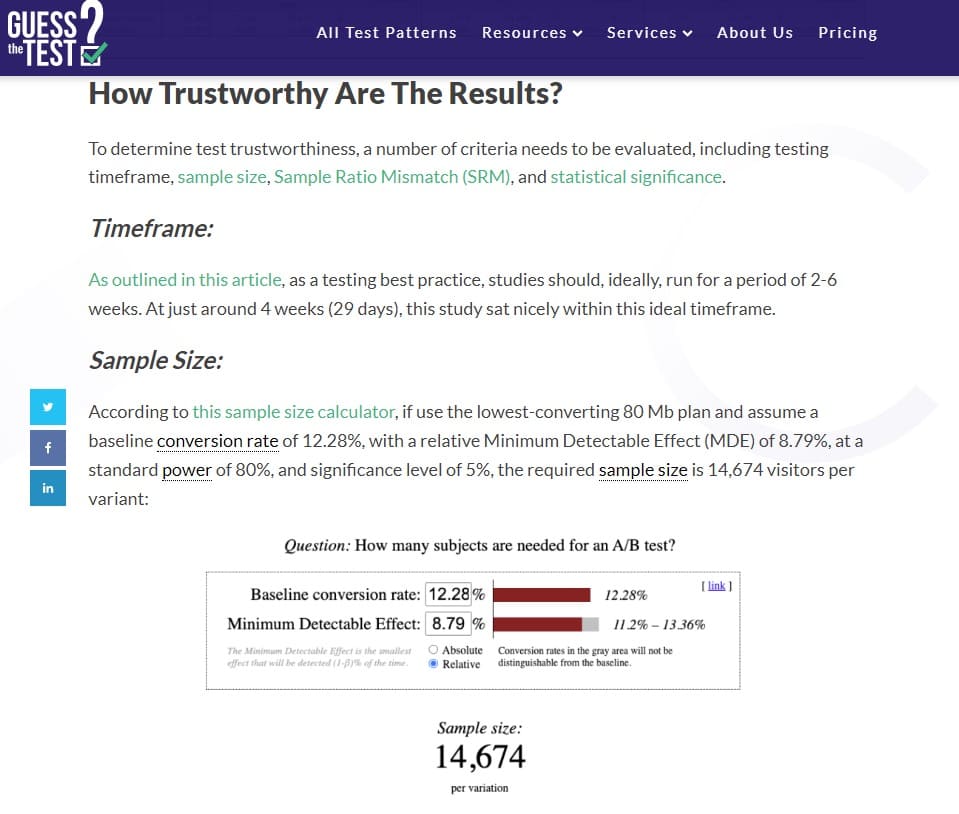
他分析了剩餘的 85 次測試,發現平均提升百分比為 3.77%,中位數提升為 3.92%。 查看下面的分佈,您會看到 58% 的測試(這是大多數)在 -3% 和 +10% 之間觀察到效果(提升 %)。
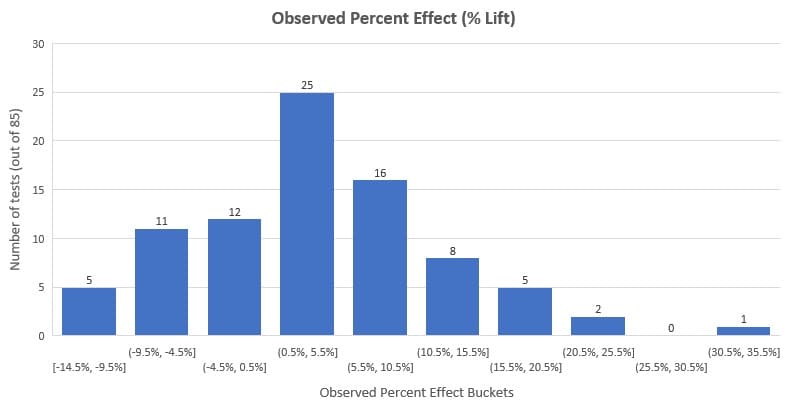
需要注意的是,這代表了這個數據集,而不是所有已經完成的 A/B 測試。 另外,我們必須考慮發表偏倚(我們稍後將討論的薈萃分析的缺點之一)。
但是,此元分析有助於轉化率優化人員和其他優化利益相關者了解 A/B 測試中的外部基準。
有興趣進行自己的 A/B 測試元分析嗎?
您可以訪問 Georgi 使用的相同數據集。 它在 GoodUI.org 上公開可用——這是一個針對不同核心問題進行的跨平台、行業和不同核心問題的 A/B 測試的提煉結果存儲庫。
還有其他類似的 A/B 測試結果集合(您甚至可以通過從眾多 A/B 測試示例和案例研究中提取數據來創建自己的結果),但 GoodUI 是獨一無二的。 如果您正在瀏覽和收集案例研究,您將獲得有關測試的其他統計信息,否則這些信息很難獲得。
還有幾件事使 GoodUI 與眾不同:
- 它不會根據實驗結果進行區分。 它包括獲勝、不確定、平坦和否定測試,以對抗 Meta 分析中的發表偏倚,這是一個真正的問題,正如 John Copas 和 Jian Qing Shi 在“Meta 分析、漏斗圖和敏感性分析”中所述。
發表偏倚是對發表小型研究的偏好,如果它們的結果比具有負面或不確定結果的研究“顯著”。 如果不做出不可測試的假設,您就無法糾正這一點。
- GoodUI 更進一步。 元分析結果通常隱藏在研究論文中。 他們幾乎沒有進入實際應用的道路,特別是對於不是非常成熟的實驗團隊。
借助 GoodUI 模式,好奇的優化器可以深入研究觀察到的百分比變化、統計顯著性計算和置信區間。 他們還可以使用 GoodUI 對結果強弱程度的評估,可能值為“不顯著”、“可能”、“顯著”和“強”,針對每個轉換模式在兩個方向上進行。 你可以說它使來自 A/B 測試元分析的見解“民主化”。
- 但是,這裡有一個問題。 實驗者可能不知道困擾薈萃分析的問題——異質性和發表偏倚——加上薈萃分析結果取決於薈萃分析本身的質量這一事實,可能會轉向盲目複製模式的領域。
相反,他們應該進行自己的研究並進行 A/B 測試。 不這樣做最近(正確地)引起了 CRO 領域的關注。
GuessTheTest 是另一個 A/B 測試案例研究資源,您可以深入研究類似 GoodUI 等測試的詳細信息。
免責聲明:我們撰寫此博客的目的不是為了批評或讚揚元分析和轉換模式。 正如 CRO 領域的專家所討論的那樣,我們只是要介紹利弊。 我們的想法是將薈萃分析作為一種工具呈現,以便您可以自行決定使用它。
元分析——是或否
聰明的頭腦會尋找模式。 這就是您下次遇到類似問題時縮短從問題到解決方案的路徑的方法。
這些模式會引導您在創紀錄的時間內找到答案。 這就是為什麼我們傾向於相信我們可以把我們從實驗中學到的東西,聚合它們,並推斷出一個模式。
但這對實驗團隊來說是否可取?
在線對照實驗中支持和反對薈萃分析的論據是什麼? 你能找到一個兩全其美的中間立場嗎?
我們詢問了實驗領域中兩個最有發言權的聲音,他們對元分析的看法(恭敬地)不同。
Jonny Longden 和 Jakub Linowski 是您可以信賴的聲音。


元分析——謹慎行事?
在上面的討論中,Jonny 指出了在在線測試中使用元分析數據的兩個潛在問題,這需要 CRO 從業者謹慎行事。

- 問題 #1:使用結果而不進行測試
“如果它適用於那家公司,它也應該適用於我們”。 這可能會被證明是錯誤的想法,因為圍繞測試的細微差別無法體現在您正在審查的結果片段中。
幾個測試可能會證明一個簡單的解決方案,但這只是它可能比其他解決方案稍微好一點的可能性,而不是它可以在您的網站上運行的明確答案。
- 問題 #2:你不能這麼容易地對測試進行分類
正如 #1 中提到的,這些結果並未顯示測試背後的完整、細緻入微的故事。 您看不到為什麼要運行測試,它們來自哪裡,網站上存在哪些先前的問題等。
例如,您只看到這是對產品頁面上的號召性用語的測試。 但是元分析數據庫會將它們分類為特定的模式,即使它們並沒有完全落入這些模式中。
這對您、A/B 測試元分析數據庫用戶或 CRO 研究人員來說意味著什麼?
這並不意味著薈萃分析是禁區,但你應該小心使用它。 你應該採取什麼樣的謹慎態度?
不妥協測試嚴謹性和追求創新
回想一下,薈萃分析是醫學界的一種統計概念,在該概念中,實驗受到嚴格控制,以確保發現的可重複性。
圍繞觀察的環境和其他因素在多個實驗中重複出現,但這與在線實驗不同。 無論這些差異如何,在線實驗的元分析都會將他們的數據匯總在一起。
一個網站與另一個網站完全不同,因為它有非常不同的受眾和非常不同的事情發生。 即使看起來比較相似,即使是同一種產品,但在千千萬萬種方式中,它仍然是完全不同的,所以你無法控制它。
喬尼·朗登
除其他限制外,這會影響我們所謂的真正薈萃分析的質量。
因此,如果您不確定測試和薈萃分析的統計活力水平,您只能非常謹慎地使用,正如 Shiva Manjunath 建議的那樣。
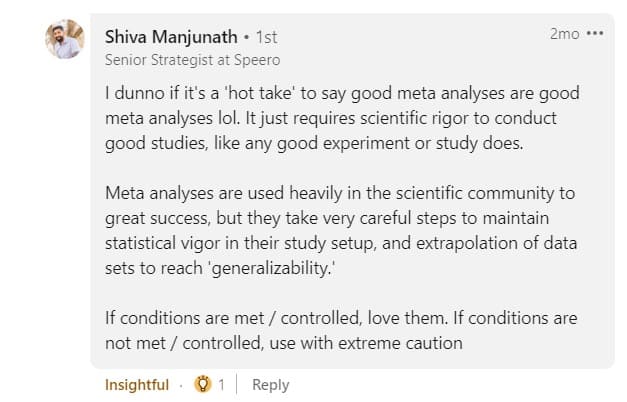
元分析的目標不應該是複制競爭對手。 從利用元分析到直接複製的跳躍推動了可信度的界限。 “複製”背後的意圖是有細微差別的,所以這不是一個非黑即白的情況。
上面對黛博拉帖子的評論是多種多樣的。 複製到一定程度是可以的,但過度複製是危險的:
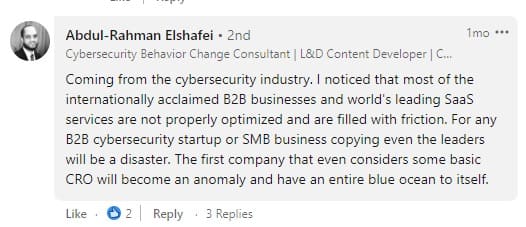
正如 Jakub 所同意的那樣,我們必須對複制保持謹慎,尤其是在驗證我們通過實驗觀察到的模式時。
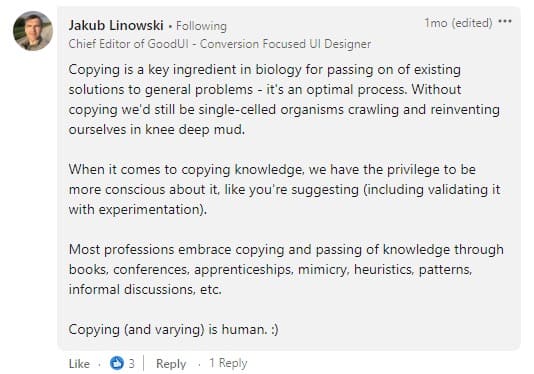
但是,我們應該警惕的是將實驗商品化。 也就是說,使用薈萃分析的模式和見解作為最佳實踐來代替實驗研究,而不是讚美特定情況的數據必須說明的內容。
因此,首先要了解您想要解決的問題,並確定最有可能成功的干預措施。 這就是對遺留實驗數據的元分析最能支持獨特優化策略的地方。
元分析——給實驗飛輪上油?
實驗飛輪有一種回收動力的方式。 當你第一次做實驗時,你需要很大的慣性才能讓事物運轉起來。
實驗飛輪的想法是利用這種勢頭來運行更多測試並再次循環,變得越來越好,運行越來越多的測試。
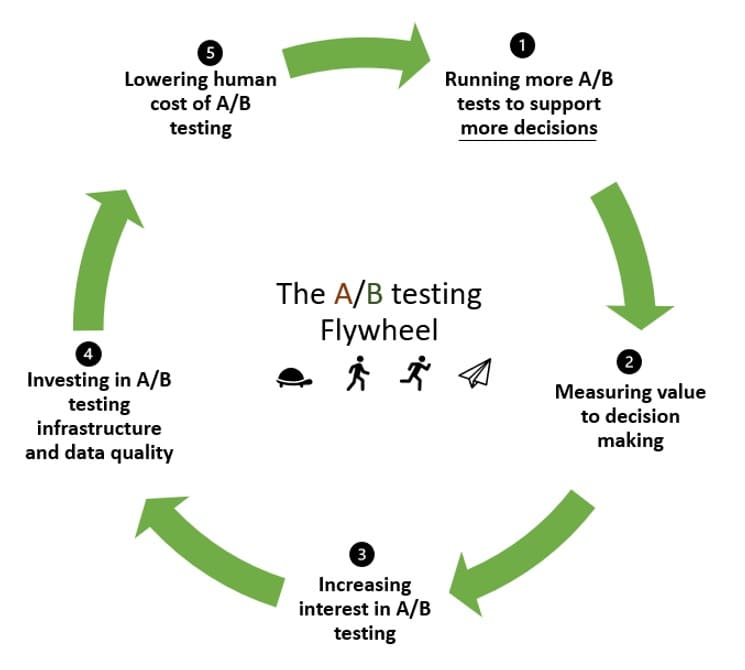
這就是元分析可以提供幫助的地方。 在飛輪中:
- 您運行測試以希望驗證您的假設(並可能在此過程中拒絕一些假設)。
- 衡量他們為決策增加的價值。
- 鼓勵對 A/B 測試產生更多興趣和支持。
- 投資於 A/B 測試基礎設施並提高數據質量。
- 降低 A/B 測試的人力成本,使下一步比上一輪更輕鬆。
但作為一個數據驅動的組織,當您認識到 A/B 測試的力量時,您不會止步於此。 相反,您希望在初始實驗投資的基礎上驗證或拒絕更多假設。
如果沒有最初的洞察力或知識開始,那麼讓您的飛輪運轉的慣性將太大。 分享這些知識(使 A/B 測試數據大眾化)可以通過降低知識壁壘來激發並幫助其他人採用實驗方法。
這將我們帶到了元分析如何為實驗飛輪提供潤滑脂的第 1 點:
- 元分析可能會縮短假設想法的時間。
您可以從之前的測試中獲取您所學到的知識、見解和所有內容,從而輕鬆地生成新假設。 這增加了您運行的測試數量,並且是加速 A/B 測試飛輪的絕佳方式。
我們花更少的時間重做已經建立的模式,而花更多的時間根據我們在之前的實驗中學到的知識開闢新的路徑。
- Meta 分析可以通過過去的數據獲得更好的預測率。
過去實驗驅動的學習可以讓實驗飛輪旋轉得更快的另一種方法是結合現有數據來提供新的假設。
這可能會改善 A/B 測試中觀察到的影響如何溢出到未來。
部署 A/B 測試並不能保證看到您想要的結果,因為 95% 顯著性測試的錯誤發現率 (FDR) 介於 18% 和 25% 之間。 在得出這一結論的測試中,只有 70% 具有足夠的功效。
錯誤發現率是實際無效的顯著 A/B 測試結果的一部分。 不要被誤認為是誤報或 I 類錯誤。
- 最後,薈萃分析可能是一種建立對本質上不確定的測試結果的信心的方法。
置信水平可幫助您相信您的測試結果並非純屬偶然。 如果您沒有足夠的信息,您可能傾向於將該測試標記為“不確定”,但不要那麼著急。
為什麼? 從統計上講,您可以累積無關緊要的 p 值以獲得顯著的結果。 請參閱下面的帖子:
薈萃分析有兩個主要好處:1)它提高了效果估計的準確性,2)它增加了研究結果的普遍性。
資料來源:好的、壞的和醜陋的:Madelon van Wely 的薈萃分析
鑑於元分析調整和糾正了效應大小和顯著性水平,人們可以像使用任何其他實驗一樣使用這種更高的標準結果,包括:
1)為自己的實驗進行功效計算/樣本量估計(使用真實數據而不是主觀猜測)
2)做出exploit-experiment決定。 如果有人覺得需要額外的信心,他們可能會決定自己進行額外的實驗。 如果有人發現薈萃分析的證據足夠有力,他們可能會更早地採取行動,而無需進行額外的實驗。
雅庫布·林諾夫斯基
元分析可以通過各種方式幫助您的實驗計劃獲得更多動力,重要的是要記住它存在一些眾所周知的限制。
如果您選擇進行(和使用)元分析——請記住以下幾點
是的,通過元分析方法結合實驗結果可以提高統計精度,但這並不能消除初始數據集的基本問題,例如……
分析中包含的實驗質量差
如果元分析中包含的實驗設置不當並且包含統計錯誤,那麼無論元分析員多麼準確,他們都會得到無效的結果。
也許在 A/B 測試中樣本量分配不均,能力或樣本量不足,或者有偷窺的證據——不管是什麼情況,這些結果都是有缺陷的。
您可以做的繞過此限制的方法是仔細選擇您的測試結果。 從您的數據集中消除有問題的結果。 您還可以重新計算您選擇包含的測試的統計顯著性和置信區間,並在薈萃分析中使用新值。
異質性
這是組合最初不應該放在同一個桶中的測試結果。 例如,當用於進行測試的方法不同時(貝葉斯與頻率統計分析、A/B 測試平台特定的差異等)。
這是薈萃分析的一個常見局限性,分析師有意或無意地忽略了研究之間的關鍵差異。
您可以查看原始定量數據來對抗異質性。 這比僅結合測試結果的摘要要好。 這意味著重新計算每個 A/B 測試的結果,假設您可以訪問數據。
發表偏倚
也稱為“文件抽屜問題”,這是元分析中最臭名昭著的問題。 在對公開可用的數據進行薈萃分析時,您僅限於匯集那些使其發表的結果。
那些沒有成功的呢? 出版物通常偏愛具有統計學意義且具有顯著治療效果的結果。 當薈萃分析中未顯示此數據時,結果僅描述已發布的內容。
您可以通過漏斗圖和相應的統計數據發現發表偏倚。
那麼,您在哪裡可以找到沒有進入案例研究或 A/B 測試元分析數據庫的 A/B 測試? 無論結果如何,A/B 測試平台都處於提供測試數據的最佳位置。 這就是本文中的示例 1 和示例 2 的優勢所在。