
什麼是潛在語義索引,它是如何工作的?
已發表: 2020-04-02潛在語義索引 (LSI) 長期以來一直是搜索營銷人員爭論的焦點。 谷歌“潛在語義索引”一詞,你會同時遇到擁護者和懷疑者。 在搜索引擎營銷的背景下考慮 LSI 的好處沒有明確的共識。 如果您對這個概念不熟悉,本文將總結關於 LSI 的爭論,希望您能了解它對您的 SEO 策略意味著什麼。
什麼是潛在語義索引?
LSI 是自然語言處理 (NLP) 中的一個過程。 NLP 是語言學和信息工程的一個子集,重點關注機器如何解釋人類語言。 這項研究的一個關鍵部分是分佈語義。 該模型幫助我們理解和分類大型數據集中具有相似上下文含義的單詞。
LSI 開發於 1980 年代,使用一種數學方法,使信息檢索更加準確。 該方法通過識別單詞之間隱藏的上下文關係來工作。 它可以幫助您像這樣分解它:
- 潛在的→隱藏的
- 語義→詞之間的關係
- 索引→信息檢索
潛在語義索引如何工作?
LSI 使用奇異值分解 (SVD) 的部分應用來工作。 SVD 是一種數學運算,可將矩陣簡化為其組成部分,以便進行簡單有效的計算。
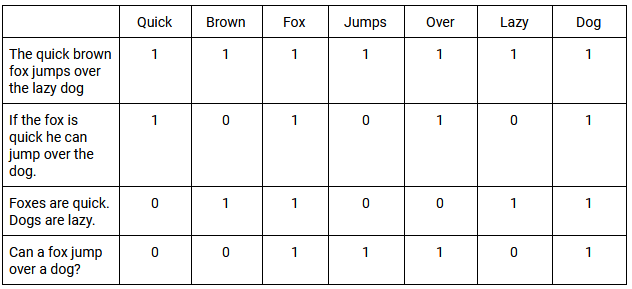
在分析一串單詞時,LSI 會刪除連詞、代詞和常用動詞,也稱為停用詞。 這隔離了構成短語主要“內容”的單詞。 這是一個簡單的示例,說明這可能看起來如何:
![]()
然後將這些詞放置在術語文檔矩陣(TDM) 中。 TDM 是一個 2D 網格,它列出了每個特定單詞(或術語)在數據集中的文檔中出現的頻率。
然後將加權函數應用於 TDM。 一個簡單的例子是對所有包含值為 1 的單詞和所有不包含值為 0 的單詞的文檔進行分類。當單詞在這些文檔中以相同的一般頻率出現時,稱為co-occurrence 。 您將在下面找到 TDM 的基本示例,以及它如何評估跨多個短語的共現:
使用 SVD 可以讓我們估計所有文檔中的單詞使用模式。 LSI 生成的 SVD 向量比分析單個術語更準確地預測含義。 最終,LSI 可以使用單詞之間的關係來更好地理解它們在特定上下文中的意義或含義。
[案例研究] 通過頁面 SEO 推動新市場的增長
 閱讀案例研究
閱讀案例研究潛在語義索引是如何參與 SEO 的?
在其成長期,谷歌發現搜索引擎會根據特定關鍵詞的出現頻率對網站進行排名。 但是,這並不能保證最相關的搜索結果。 相反,谷歌開始對他們認為值得信賴的信息仲裁者的網站進行排名。
隨著時間的推移,谷歌的算法會更準確地過濾掉低質量和不相關的網站。 因此,營銷人員必須了解搜索背後的含義,而不是依賴於所使用的確切詞。 這就是為什麼 Roger Montti 在一篇關於過時的 SEO 理念的文章中將 LSI 描述為“搜索引擎的訓練輪”,並補充說 LSI“與搜索引擎如何對當今的網站進行排名幾乎沒有相關性”。
搜索查詢的含義與其背後的意圖密切相關。 Google 維護著一份名為“搜索質量評估員指南”的文檔。 在這些指南中,他們為用戶意圖引入了四個有用的類別:

- 知道查詢- 這代表尋找有關某個主題的信息。 對此的一個變體是“知道簡單”查詢,當用戶在搜索時考慮到特定的答案。
- 做查詢——這反映了參與特定活動的願望,例如在線購買或下載。 所有這些查詢都可以通過“交互”的感覺來定義。
- 網站查詢- 這是用戶正在尋找特定網站或頁面的時候。 這些搜索表明對特定網站或品牌的先前認識。
- 親自訪問查詢——用戶正在搜索物理位置,例如實體店或餐廳。
LSI 背後的理論——在一個短語中定義一個詞的上下文含義——為谷歌提供了競爭優勢。 然而,“LSI 關鍵字”突然成為 SEO 成功的黃金門票的想法開始傳播開來。
“LSI 關鍵字”真的存在嗎?
許多著名的出版物仍然是 LSI 關鍵字的堅定擁護者。 然而,一些消息來源,例如穀歌的網站管理員趨勢分析師約翰穆勒,表示它們是一個神話。 這些消息來源開始提出以下幾點:
- LSI 是在萬維網之前開發的,並不打算應用於如此龐大的動態數據集。
- 1989 年授予貝爾通信研究公司的美國潛在語義索引專利將在 2008 年到期。因此,根據 Bill Slawski 的說法,谷歌使用 LSI 類似於“使用智能電報設備連接到移動網絡。
- Google 使用 RankBrain,這是一種機器學習方法,可將大量文本轉換為“向量”——幫助計算機理解書面語言的數學實體。 與 LSI 不同,RankBrain 將網絡作為一個不斷擴展的數據集來容納,使其可供 Google 使用。
最終,LSI 揭示了營銷人員應該堅持的一個真理:探索一個詞的獨特上下文有助於我們更好地理解用戶意圖,而不是塞進內容中的關鍵字。 然而,這並不一定證實了谷歌基於 LSI 的排名。 因此,可以肯定地說 LSI 在 SEO 中作為一種哲學而不是一門精確的科學起作用嗎?
讓我們回到 Roger Montti 關於 LSI 作為“搜索引擎的訓練輪”的名言。 一旦你學會騎自行車,你往往會取下輔助輪。 我們可以假設在 2020 年,谷歌不再使用輔助輪嗎?
我們可以考慮谷歌最近的算法更新。 2019 年 10 月,搜索副總裁 Pandu Nayak 宣布,谷歌已開始使用名為 BERT(變形金剛的雙向編碼器表示)的人工智能係統。 影響超過 10% 的搜索查詢,這是近年來 Google 最大的更新之一。
在分析搜索查詢時,BERT 會考慮與該特定短語中的所有單詞相關的單個單詞。 這種分析是雙向的,因為它考慮了特定單詞之前或之後的所有單詞。 刪除單個單詞可能會極大地影響 BERT 如何理解短語的獨特上下文。
這與 LSI 形成鮮明對比,後者在分析中省略了任何停用詞。 下面的示例顯示了刪除停用詞如何改變我們對短語的理解:
![]()
儘管是停用詞,但“查找”是搜索的關鍵,我們將其定義為“親自訪問”查詢。
那麼營銷人員應該怎麼做呢?
最初,LSI 被認為能夠幫助 Google 將內容與相關查詢進行匹配。 然而,市場上圍繞 LSI 使用的爭論似乎還沒有得出一個單一的結論。 儘管如此,營銷人員仍然可以採取許多措施來確保他們的工作保持戰略相關性。
首先,應優化文章、網絡副本和付費活動以包含同義詞和變體。 這解釋了意圖相似的人使用語言的方式不同。
營銷人員必須繼續以權威和清晰的方式寫作。 如果他們希望他們的內容解決特定問題,這是絕對必須的。 這個問題可能是缺乏信息或需要某種產品或服務。 一旦營銷人員這樣做,就表明他們真正了解用戶意圖。
最後,他們還應該經常使用結構化數據。 無論是網站、食譜還是常見問題解答,結構化數據都為 Google 提供了上下文,以了解它正在抓取的內容。