
[網絡研討會文摘] Orbit 中的 SEO:重複內容的新視角
已發表: 2019-11-20網絡研討會關於重複內容的新觀點是 SEO in Orbit 系列的最後一集,於 2019 年 6 月 24 日播出。在這一集中,與 OnCrawl 大使 Omi Sido 和 Alexis Sanders 一起探討重複內容的問題。 他們解決的問題如下:排名因素和不斷發展的搜索技術如何影響我們處理重複內容的方式? 並且:網絡上類似內容的未來會怎樣?
Orbit 中的 SEO 是第一個將 SEO 送入太空的網絡研討會系列。 在整個系列中,我們與一些最優秀的 SEO 專家討論了技術 SEO 的現在和未來,並於 2019 年 6 月 27 日將他們的重要技巧發送到了太空。
在這裡觀看重播:
介紹亞歷克西斯·桑德斯
Alexis Sanders 在 Merkle 擔任技術 SEO 客戶經理。 SEO 技術團隊確保該機構的技術建議在所有垂直領域的準確性、可行性和可擴展性。 她是 Moz 博客的撰稿人,也是 TechnicalSEO.expert 挑戰和 SEO in the Lab 播客的創建者。
本期節目由近江西多主持。 Omi 是一位經驗豐富的國際演說家,並以其幽默感和提供可操作見解的能力而聞名於業界,觀眾可以立即開始使用。 從為一些世界上最大的電信和旅遊公司提供 SEO 諮詢到在 HostelWorld 和 Daily Mail 管理內部 SEO,Omi 喜歡深入研究複雜的數據並尋找亮點。 目前,Omi 是 Canon Europe 的高級技術 SEO 和 OnCrawl 大使。
什麼是重複內容?
Omi 提供了以下重複內容的定義:
與相同(或不同)網站上不同 URL 上的內容相似或幾乎相似的重複內容。
重複內容處罰的神話
沒有重複的內容懲罰。
這是一個性能問題。 我們不希望機器人查看兩個特定的 URL,並認為它們是兩個不同的內容,可以彼此相鄰排列。
Alexis 將機器人對您網站的理解與 Joey 在《我討厭你的 10 件事》中的圖片進行了比較:機器人不可能找到兩個版本之間的實質性差異。

您希望避免在搜索引擎排名情況下有兩個完全相同的事物必須相互競爭。 相反,您希望擁有可以在搜索引擎中排名和執行的單一、整合的體驗。
用戶和機器人看到的區別
用戶可能會看到一個令人信服的 URL,但機器人可能仍會看到多個看起來基本相同的版本。
– 對超大型網站的抓取預算的影響
對於非常大的網站(例如 Zillow 或 Walmart),不同頁面的抓取預算可能會有所不同。
正如 Alexis 在 2018 年一篇基於 Frederic Dubut 在 SMX East 的演講的文章中所討論的那樣,預算設置在不同的級別——在子域級別,在不同的服務器級別。 搜索引擎,無論是 Google 還是 Bing,都希望成為禮貌的爬蟲; 他們不想降低實際用戶的性能。 每當他們感覺到性能發生變化時,他們就會退縮。 這可能發生在不同的級別,而不僅僅是站點級別。
如果您有一個龐大的網站,您希望確保提供與您的用戶相關的最統一的體驗。
重複內容是內容還是技術問題?
儘管“重複內容”中有“內容”一詞,但它在一定程度上是一個技術問題。
– 重複來源 – [07:50]
有很多因素會導致重複。 即使是部分列表似乎也可以永遠持續下去:
- 重複頁面
- 臨時站點
- HTTP 與 HTTPS URL
- 不同的子域
- 不同的案例
- 不同的文件擴展名
- 尾部斜線
- 索引頁
- 網址參數
- 刻面
- 排序
- 適合打印的版本
- 門口頁
- 存貨
- 聯合內容
- 公關發布
- 重新發佈內容
- 抄襲內容
- 本地化內容
- 稀薄的內容
- 僅圖像
- 內部網站搜索
- 單獨的移動站點
- 非唯一內容
- …
– 技術 SEO 和內容之間的問題分佈
事實上,這些重複內容的來源可以分為技術和開發來源以及基於內容的來源,有些則屬於兩者之間的重疊區域。
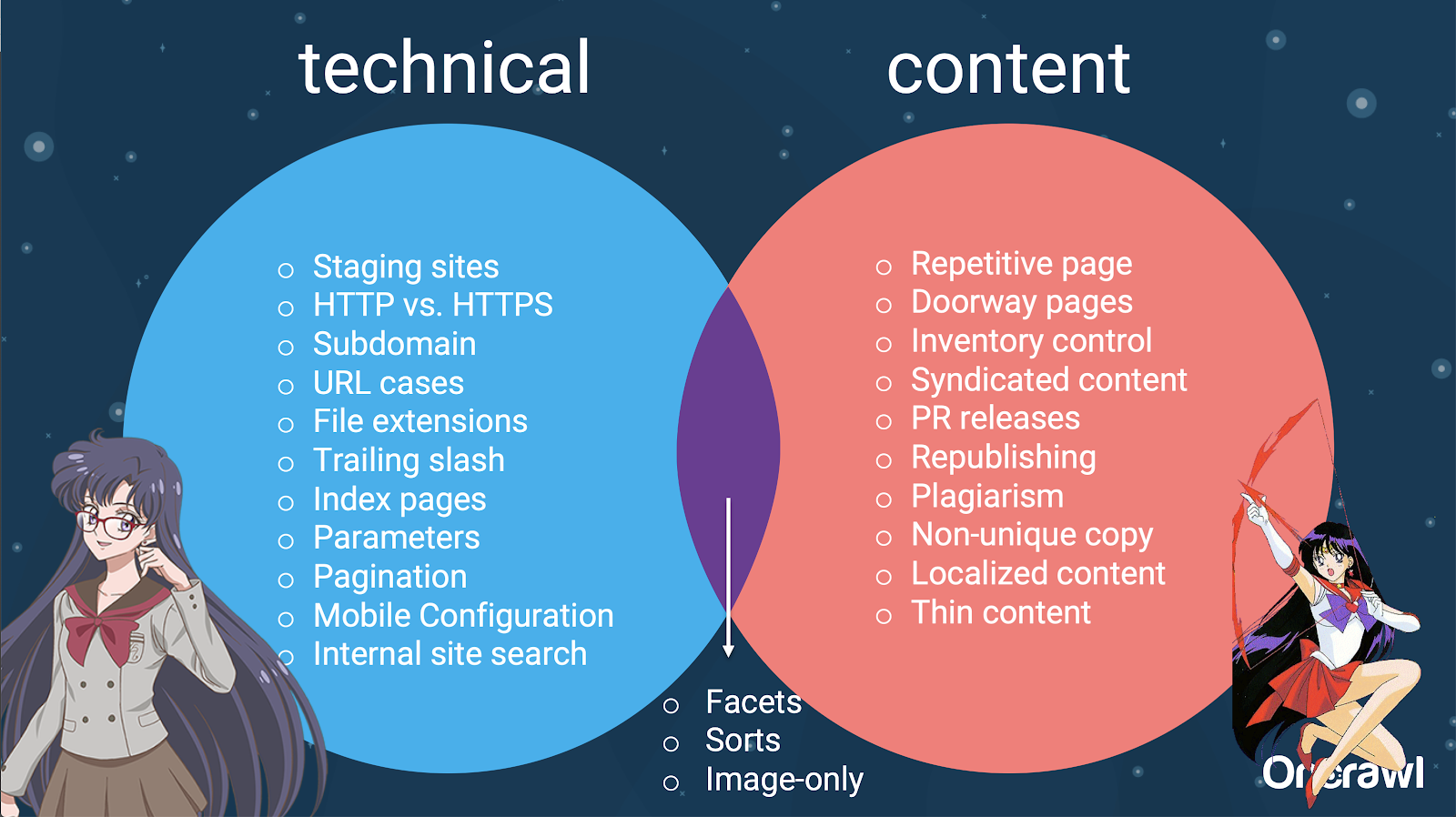
這使得重複內容成為一個跨團隊的問題,這也是它如此有趣的部分原因。
如何查找重複的內容
大多數重複的內容是無意的。 對於 Omi,這表明內容和技術團隊之間有共同的責任來查找和修復重複的內容。
– Omi 最喜歡的工具:Grammarly
Grammarly 是 Omi 最喜歡的查找重複內容的工具,它甚至不是 SEO 工具。 他使用抄襲檢查器。 他要求內容髮布者檢查是否已經在其他任何地方發布了新內容。
- 無意重複內容的數量
無意重複內容的問題是工程師非常熟悉的問題。 在一本名為 Introduction to Information Retrieval (2008) 的書中,這本書顯然已經過時了,他們估計當時大約 40% 的網絡是重複的。

– 優先處理重複內容的策略
要處理重複的內容,您應該:
- 從了解您的用戶旅程開始,這將幫助您了解每條內容的適合位置。 這可能很難做到,尤其是在 20 年前製作網站的時候,當時我們不知道它們會變得多大,也不知道它們會如何擴展。 了解您的用戶在他們旅程中的任何給定點的位置將幫助您在接下來的一些步驟中確定優先級。
- 您需要一個有效的層次結構,以便為每種類型的內容提供一個位置。 在處理重複內容的步驟中,了解您的信息架構非常重要。
- 優先考慮影響性能的重複內容。 上面的部分來源列表太長了,你不能一次真正地攻擊。
- 處理 100% 重複
- 信號重複內容
- 就如何處理重複做出戰略選擇:整合、創建、刪除、優化
- 處理被盜內容

– 工具:在 OnCrawl 中使用分段
Alexis 非常喜歡在 OnCrawl 中對您的網站進行細分的能力,這使您可以深入研究對您有意義的事情。
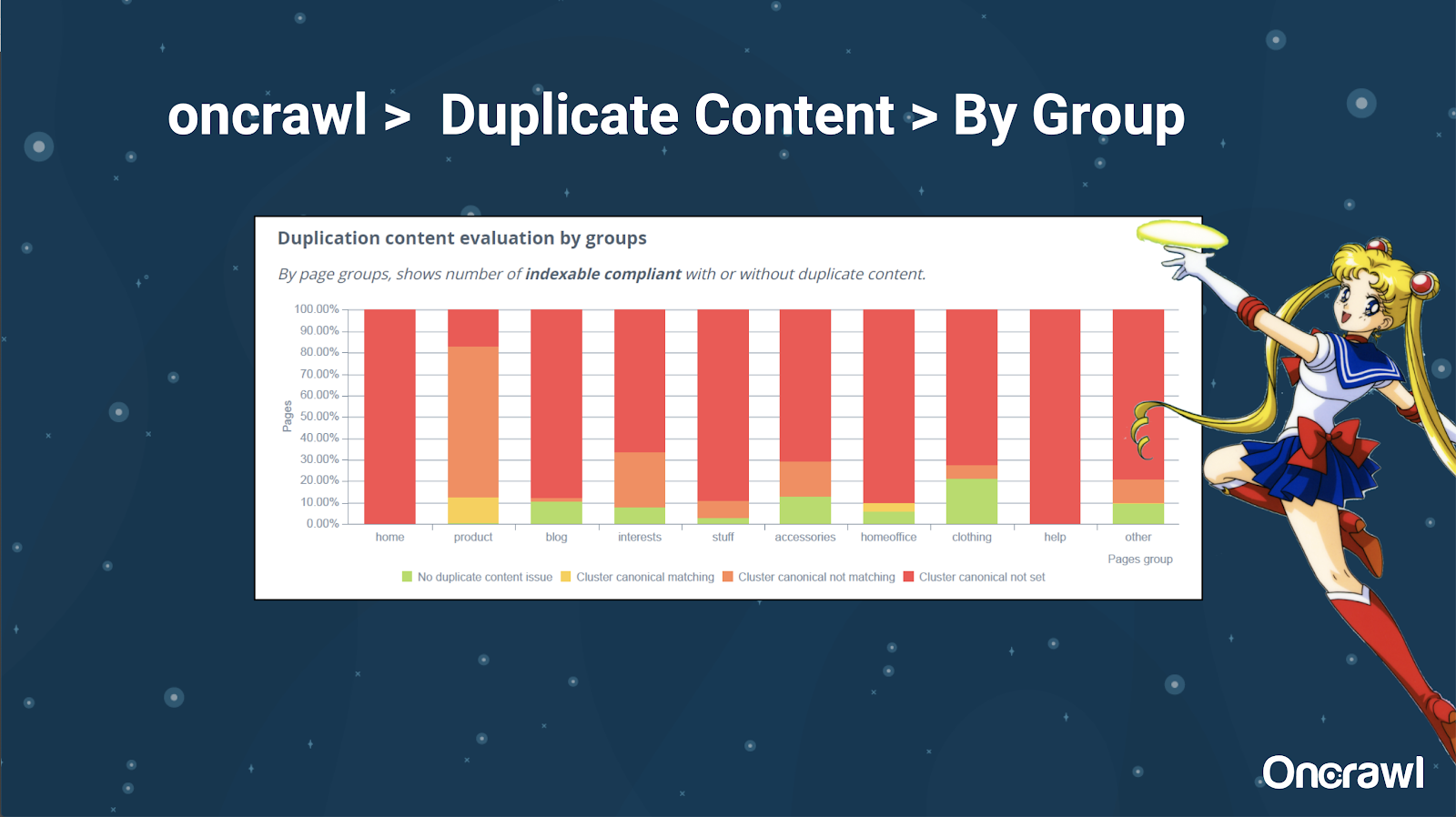
不同類型的頁面有不同的重複量; 這允許查看問題最多的部分。 在上面的示例中,該站點需要大量關注。
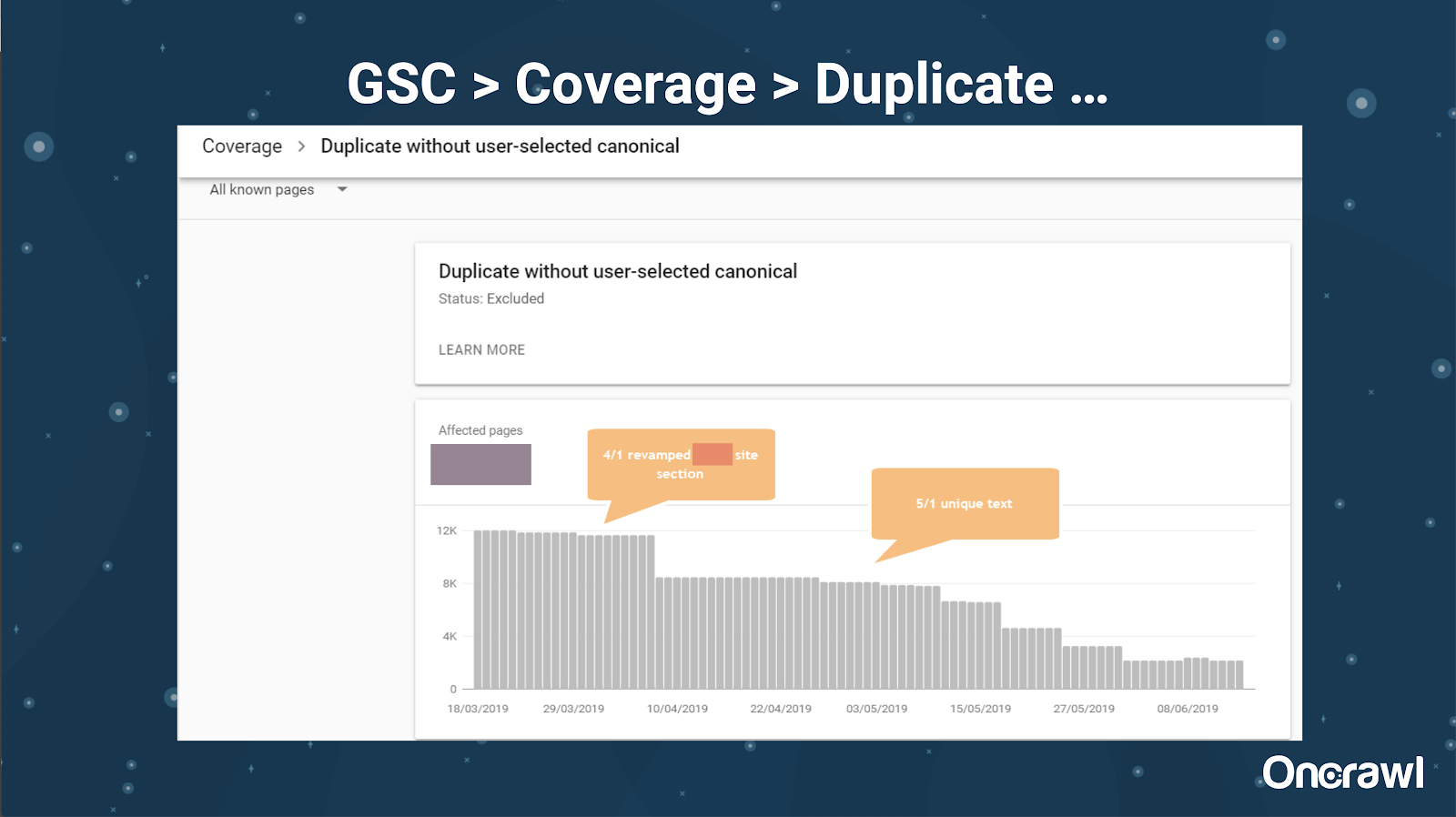
– 工具:谷歌搜索和 GSC
您還可以使用搜索引擎本身檢查重複的內容。 在 Google 中,您可以:
- 使用直接引號
- 使用站點:搜索
- 使用額外的運算符,如 inurl:、intitle: 或 filetype:

Google Search Console 還添加了重複內容報告,這對於從他們的角度識別 Google 認為是重複內容的內容非常有用。
– 工具:抄襲工具
和 Omi 一樣,Alexis 也使用不同的抄襲工具:
網文
諾普拉格
紙評者
語法
複製景觀

您要確保您的內容不僅是原創的,而且從機器人的角度來看,它不會被認為是從其他來源獲取的。
這些還可以幫助您在文章中找到可能與 Internet 上其他地方的內容相似的片段。
亞歷克西斯喜歡我們擁有這些工具的方式,這些工具使我們能夠“同情搜索引擎機器人”,因為我們都不是機器人。 當工具向我們發出內容過於相似的信號時,即使我們知道存在差異,這也是一個好兆頭,有一些東西需要挖掘。
– 工具:關鍵字密度工具
Alexis 使用的關鍵字密度工具的兩個示例是:
標記人群
搜索引擎優化書
取決於網站類型的問題
解決重複內容實際上取決於您發布的內容類型和您面臨的問題類型。 例如,博客不會像電子商務網站那樣面臨重複內容的情況。
難忘的案例
Alexis 分享了她最近發現令人難忘的重複內容問題的客戶案例。
- 大型網站:添加獨特內容後的結果
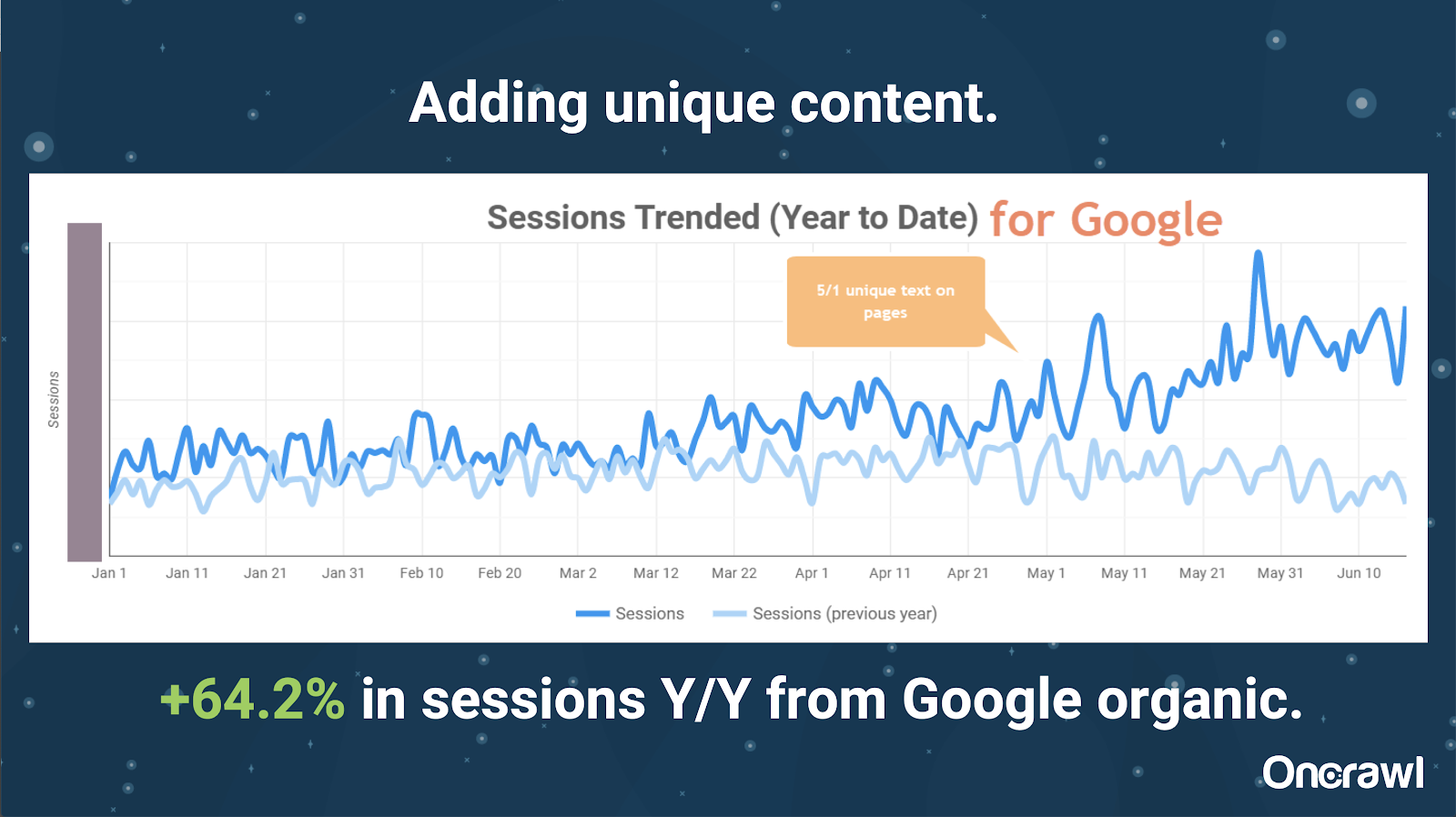
這個網站非常大,並且遇到了抓取預算問題。 它有 8600 萬頁尚未編入索引,其中只有大約 1% 的頁面已編入索引。
這是一個房地產網站,很多內容並不是特別獨特,而且他們的很多頁面都非常非常相似。 Alexis 最終將內容添加到頁面以添加特定於位置的信息以區分頁面。 令人驚訝的是,它產生結果的速度如此之快。 (這只是谷歌的有機數據。)
對於亞歷克西斯來說,這是一個非常通用的案例研究。 儘管我們今天談論 EAT 和類似的事情,這表明只要搜索引擎認為內容是獨特且有價值的,那仍然會得到回報。

在這個網站上,一個偶然的規範標籤問題導致大約 250 個頁面被發送到錯誤的協議。
這是規範標籤指示錯誤的主要頁面的一種情況,將 HTTP 頁面推送到 HTTPS 頁面的位置。
過去 18 個月的變化
亞歷克西斯在本次網絡研討會前大約 18 個月寫了一篇非常完整的文章,重複內容和戰略解決方案。 SEO 變化迅速,您需要不斷更新和重新評估您的知識。
對於 Alexis,文章中提到的大部分內容在今天仍然適用,但 rel=next/prev 除外。 不過,她希望它在未來五到十年內不再適用。
開發人員處理的技術問題:過於手動
許多與開發人員處理的重複內容相關的問題都過於手動。 Alexis 認為它們應該由 CMS 和 Adobe 來處理。 例如,您不必手動完成並確保所有規範都已設置且連貫。
– 自動化/通知機會
在重複內容的技術問題領域,自動化有很多機會。 舉個例子:我們應該能夠在任何鏈接應該轉到 HTTPS 時立即檢測到是否有任何鏈接轉到 HTTP,並糾正它們。
– 站點年齡和遺留基礎設施是一個障礙
一些後端系統太舊,無法支持某些更改和自動化。 將舊的 CMS 遷移到新的 CMS 非常困難。 Omi 給出了將佳能網站遷移到新的定制 CMS 的示例。 這不僅昂貴,而且花了他們 12 個月的時間。
Rel prev/next 和來自 Google 的通信
有時來自谷歌的溝通有點令人困惑。 Omi 舉了一個例子,在應用 rel=prev/next 時,他的客戶在 2018 年看到了性能的顯著提升,儘管谷歌在 2019 年宣布這些標籤已經多年沒有使用了。
– 缺乏一刀切的解決方案
SEO 的困難在於,一個人在他們的網站上觀察到的事情不一定與另一個 SEO 在他們自己的網站上看到的一樣。 沒有一刀切的 SEO。
谷歌發布與所有 SEO 相關的公告的能力應該被認為是一項重大成就,甚至他們的一些聲明也是一個失誤,比如 rel=next/prev 的情況。
希望重複內容管理的未來
亞歷克西斯對未來的希望:
- 較少基於技術的重複內容(作為 CMS 明智的做法)。
- 更多的自動化(單元測試和外部測試)。 例如,像 OnCrawl 這樣的工具可能會定期抓取您的網站,並在發現某些錯誤時立即通知您。
- 為作者和內容管理者自動檢測高相似度頁面和頁麵類型。 這將使目前在 Grammarly 等工具中手動完成的一些驗證自動化:當有人嘗試發佈時,CMS 應該說“這有點相似——你確定要發布這個嗎?” 查看單個網站以及跨網站比較具有很多價值。
- 谷歌繼續改進他們現有的系統和檢測。
- 也許是一個警報系統來升級 Google 未使用正確規範的問題。 能夠提醒谷歌注意這個問題並解決它會很有用。
我們需要更好的工具,更好的內部工具,但希望隨著谷歌開發他們的系統,他們會添加一些元素來幫助我們。
亞歷克西斯最喜歡的技術技巧
Alexis 有幾個最喜歡的技術技巧:
- EC2 遠程計算機實例。 這是訪問真實計算機以進行非常大的爬網或需要大量計算能力的任何事情的一種非常好的方法。 設置好後速度非常快。 只要確保在完成後終止它,因為它確實需要花錢。
- 檢查移動優先測試工具。 谷歌已經提到這是他們正在查看的最準確的圖片。 它著眼於 DOM。
- 將用戶代理切換到 Googlebot。 這將使您了解 Googlebot 真正看到的內容。
- 使用 TechnicalSEO.com 的 robots.txt 工具。 這是 Merkle 的工具之一,但 Alexis 真的很喜歡它,因為 robots.txt 有時會讓人很困惑。
- 使用日誌分析器。
- 用 Love 的 htaccess 檢查器製作。
- 使用 Google Data Studio 報告更改(將表格與更新同步,按相關更新過濾每個頁面)。
技術 SEO 難點:robots.txt
Robots.txt 真的很混亂。
這是一個過時的文件,看起來應該能夠支持 RegEx,但事實並非如此。
它對禁止和允許規則有不同的優先規則,這可能會讓人感到困惑。
不同的機器人可以忽略不同的事情,即使他們不應該這樣做。
你對什麼是正確的假設並不總是正確的。

問答
– HSTS:是否需要拆分協議?
如果您有 HSTS,則必須擁有所有 HTTPS 才能獲得重複內容。
– 翻譯內容是否重複內容?
通常,當您使用 hreflang 時,您是在使用它來消除同一語言中的本地化版本之間的歧義,例如美國和愛爾蘭英語頁面。 Alexis 不會考慮這種重複的內容,但她肯定會建議您確保正確設置 hreflang 標記,以表明這是相同的體驗,並針對不同的受眾進行了優化。
– 您可以使用規範標籤而不是 301 重定向來進行 HTTP/HTTPS 遷移嗎?
檢查 SERP 中實際發生的情況會很有用。 亞歷克西斯的直覺是說這沒關係,但這取決於谷歌的實際行為。 理想情況下,如果這些是完全相同的頁面,您會希望使用 301,但她曾看到規範標籤過去適用於這種類型的遷移。 事實上,她甚至親眼目睹了這種意外發生。
以 Omi 的經驗,他強烈建議使用 301s 來避免問題:如果您正在遷移網站,您不妨正確遷移它以避免當前和未來的錯誤。
– 重複頁面標題的影響
假設您有一個在不同位置非常相似的標題,但內容卻大不相同。 雖然這對亞歷克西斯來說不是重複的內容,但她認為搜索引擎將其視為“整體”類型的東西,標題是可以用來識別可能存在問題的區域的東西。
這是您可能想要使用 [site: + intitle: ] 搜索的地方。
但是,僅僅因為您有相同的標題標籤,它不會導致重複的內容問題。
即使在分頁或其他非常相似的頁面上,您仍然應該瞄準獨特的標題和元描述。 這不是由於重複的內容,而是與優化您在 SERP 中呈現頁面的方式有關。
最重要的提示
“重複內容既是技術挑戰,也是內容營銷挑戰。”
Orbit 中的 SEO 進入太空
如果您錯過了 6 月 27 日的太空之旅,請點擊此處了解我們發送到太空的所有提示。