
使用 Python 和站點地圖來審核內容策略
已發表: 2020-10-08使用 Python 庫代表 SEO 可以做什麼的興趣不再是秘密。 但是,大多數沒有編程經驗的人在導入和使用大量庫或推送時遇到困難,其結果超出了任何普通爬蟲或SEO工具所能做的。
這就是為什麼專門為 SEO、SEM、SMO、SERP 檢查和內容分析創建的 Python 庫對每個人都有用的原因。
在本文中,我們將了解一些可以使用由 Elias Dabbas 創建和開發的用於 SEO 的 Adverttools Python 庫完成的事情,我認為這些事情在 SEO、PPC 和編碼能力方面具有巨大潛力在很短的時間內。 此外,我們將以教育和自適應的方式使用自定義 Python 腳本和其他 Python 庫。
由於 Elias Dabbas 的 sitemap_to_df 函數有助於下載和分析 XML 站點地圖(站點地圖是 XML 格式的文檔,用於向搜索引擎報告可抓取和可索引的 URL),我們將研究從站點地圖中可以學到什麼。
本文將向您展示如何編寫自定義 Python 代碼以根據不同的結構分析不同的網站,如何根據 SEO 解釋數據,以及在內容配置文件、URL 和網站結構方面如何像搜索引擎一樣思考.
基於站點地圖分析網站的內容規模和策略
站點地圖是網站的一個組件,可以捕獲許多不同類型的數據,例如網站發佈內容的頻率、內容類別、發布日期、作者信息、內容主題……
在正常情況下,您可以使用 scrapy 抓取站點地圖,使用 Pandas 將其轉換為 DataFrame,並根據需要使用許多不同的輔助庫對其進行解釋。
但在本文中,我們將只使用 Advertools 和一些 Pandas 庫方法和屬性。 一些庫將被激活以可視化我們獲得的數據。
讓我們直接進入並選擇一個網站以使用其站點地圖來總結一些重要的 SEO 見解。
使用 Advertools 從站點地圖中提取和創建數據框
在 Advertools 中,您只需一行代碼即可發現、瀏覽和組合網站的所有站點地圖。
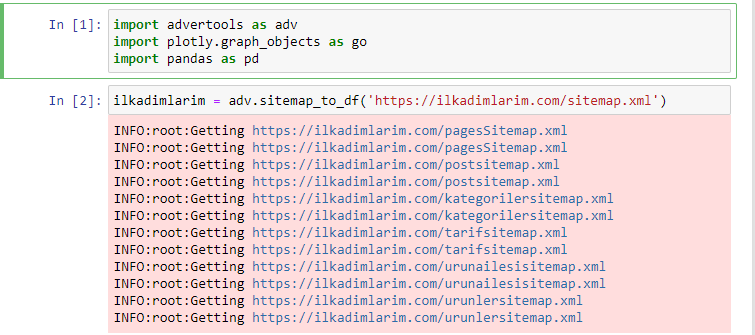
我喜歡使用 Jupyter Notebook 而不是常規的代碼編輯器或 IDE。
在第一個單元格中,我們導入了用於收集和組織數據的 Pandas 和 Advertools,以及用於可視化數據的 Plotly.graph_objects。
adv.sitemap_to_df('sitemap address')命令簡單地收集所有站點地圖並將它們統一為一個 DataFrame。
如果您使用 Pandas 和 Advertools 執行相同操作,您可以發現哪個 URL 在哪個站點地圖中可用。
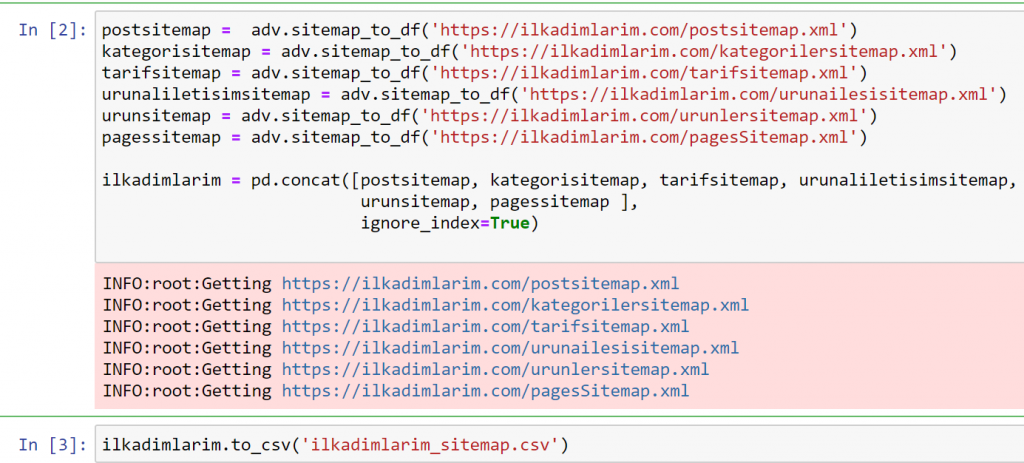
在上面的示例中,我們分別提取了相同的站點地圖,然後將它們與pd.concat命令組合併將結果傳輸到 CSV。 前面的示例使用了站點地圖索引文件,在這種情況下,該函數將檢索所有其他站點地圖。 因此,如果您對網站的特定部分感興趣,您可以像我們在這裡所做的那樣選擇特定的站點地圖。
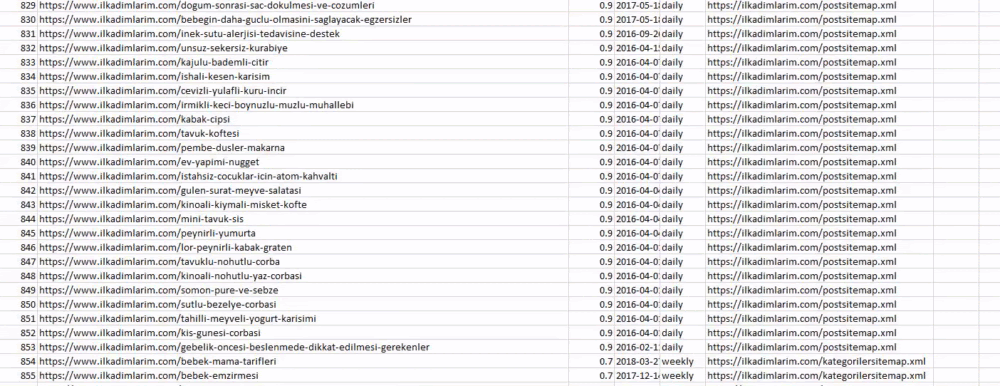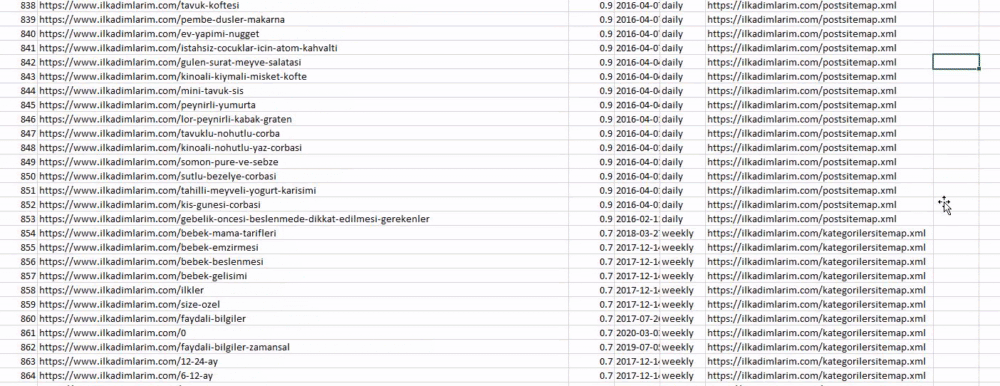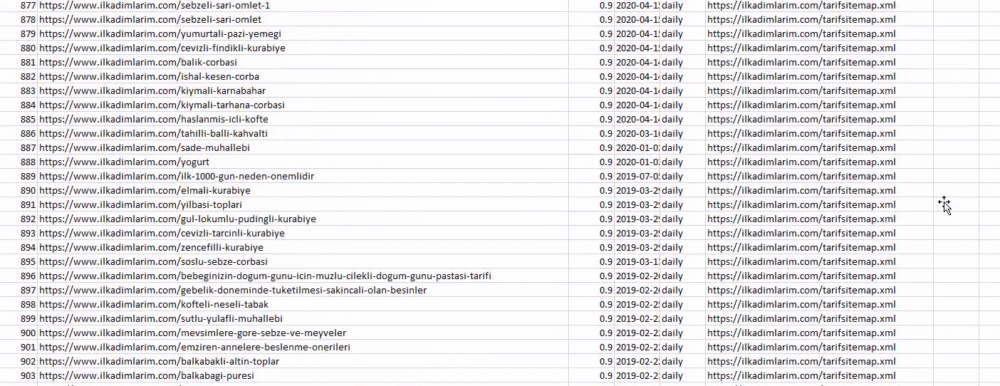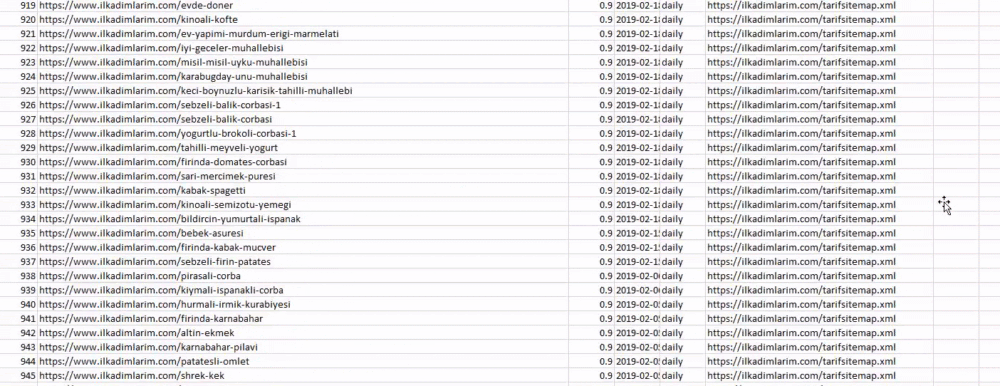
您可以在上方看到具有不同站點地圖名稱的列。 ignore_index=True 部分用於對不同 DataFrame 的索引號進行整齊排序,如果您已將多個索引號合併在一起。
抓取數據³
 學到更多
學到更多使用 Python 清理和準備用於內容分析的站點地圖數據框
要通過站點地圖了解網站的內容配置文件,我們需要準備它以查看我們使用 Advertools 獲得的 DataFrame。
我們將使用 Pandas 庫中的一些基本命令來塑造我們的數據:
ilkadimlarim = pd.read_csv('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop(列 = '未命名:0')
ilkadimlarim['lastmod'] = pd.to_datetime(ilkadimlarim['lastmod'])
ilkadimlarim = ilkadimlarim.set_index('lastmod')
“Ilkadimlarim”在土耳其語中的意思是“我的第一步”,你可以想像,它是嬰兒、懷孕和母親的網站。
我們對這些行執行了三個操作。
- 未命名:我們從 DataFrame 中刪除了一個名為 0 的空列。 此外,如果您將“index = False”與pd.to_csv()函數一起使用,您將不會在開頭看到此“未命名 0”列。
- 我們將 Last Modification 列中的數據轉換為 Date Time。
- 我們將“lastmod”列帶到了索引位置。
您可以在下面看到 DataFrame 的最終版本。
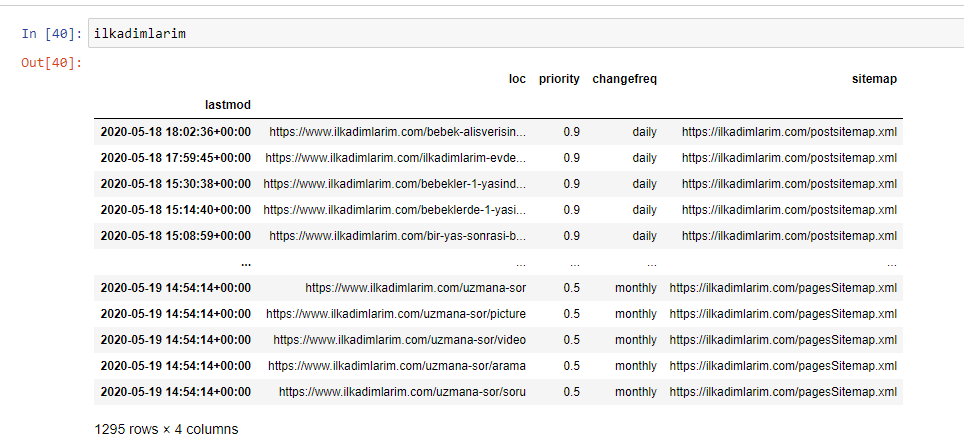
我們知道 Google 不會使用站點地圖中的優先級和更改頻率信息。 他們稱之為“一袋噪音”。 但是,如果您重視您的網站對其他搜索引擎的性能,您可能會發現檢查它們也很有用。 就個人而言,我不太關心這些數據,但我仍然不需要將其從 DataFrame 中刪除。
我們還需要一個代碼行來對另一列中的站點地圖進行分類。
ilkadimlarim['sitemap_cat'] = ilkadimlarim['sitemap'].str.split('/').str[3]
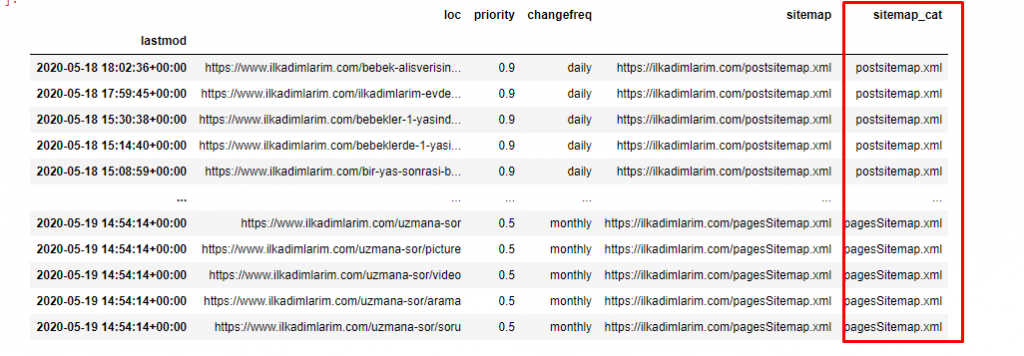
在 Pandas 中,您可以向 DataFrame 添加新的列或行,或者您可以輕鬆地更新它們。 我們使用DataFrame['new_columns']代碼片段創建了一個新列。 DataFrame['column_name'].str允許我們通過更改列中的數據類型來執行不同的操作。 我們將.split('/')相關列中的字符串數據除以/字符,放到一個列表中。 使用.str [number] ,我們通過選擇該列表中的特定元素來創建新列的內容。
根據站點地圖計數和種類進行內容配置文件分析
根據站點地圖的類型將站點地圖放在不同的列中後,我們可以檢查每個站點地圖中的內容百分比。 因此,我們也可以推斷網站的哪個部分更重要。
ilkadimlarim['sitemap_cat'].value_counts(normalize = True) * 100
- DataFrame['column_name']正在選擇我們要進行處理的列。
- value_counts()計算列中值的頻率。
- normalize=True採用十進制值的比率。
- 我們通過使用 *100 使十進制數字更大,使其更易於閱讀。
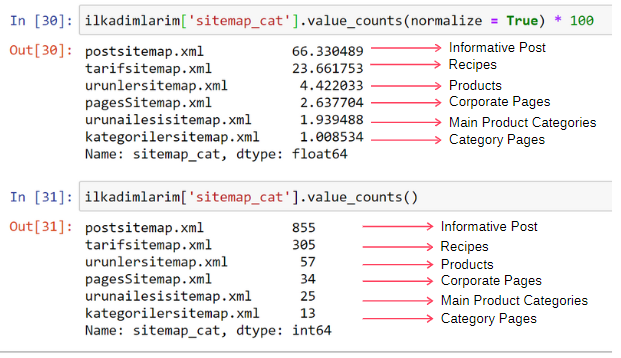
我們看到 65% 的內容在 Post Sitemap 中,23% 在 Recipe Sitemap 中。 產品站點地圖只有 2% 的內容。
這表明我們有一個網站,必須為廣大受眾創建信息內容來推銷自己的產品。 讓我們檢查一下我們的論點是否正確。
在繼續之前,我們需要使用以下代碼將 ilkadimlarim['sitemap_cat'] 列的名稱更改為 'URL_Count':
ilkadimlarim.rename(columns={'sitemap_cat' : 'URL_Count'}, inplace=True)
- rename() 函數可用於修改列或索引的名稱以連接數據及其更深層次的含義。
- 由於'inplace=True'屬性,我們已將列名更改為永久。
- 您還可以使用ilkadimlarim.rename(str.capitalize, axis='columns', inplace=True)更改列和索引的字母樣式。 這僅將 Ilkadimlarim 中每列的首字母大寫。

現在,我們可以繼續了。
要在單個幀中查看此信息,您可以使用以下代碼:
(ilkadimlarim['sitemap_cat']
.value_counts()
.to_frame()
.assign(percentage=lambda df: df['sitemap_cat'].div(df['sitemap_cat'].sum()))
.style.format(dict(sitemap_cat='{:,}', percent='{:.1%}')))
- to_frame()用於將 value_counts() 在選定列中測量的值框起來。
- assign()用於向框架添加某些值。
- lambda指的是 Python 中的匿名函數。
- 在這裡,Lambda 函數和站點地圖類型通過 Pandas div()方法除以站點地圖總數。
- style()確定如何寫入指定的最終值。
- 在這裡,我們使用format()方法設置句點後寫入的位數。
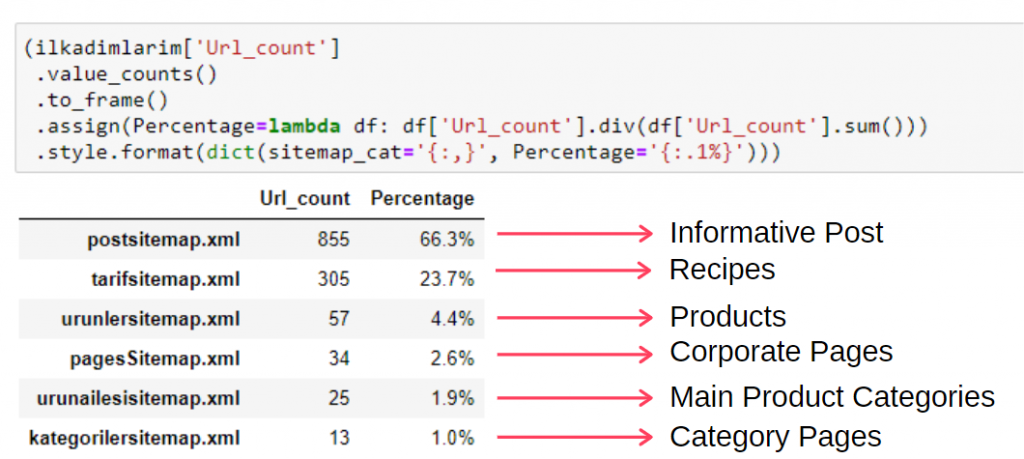
因此,我們看到了內容營銷對這個網站的重要性。 我們還可以通過兩行代碼查看他們每年的文章發布趨勢,以更深入地檢查他們的情況。
通過站點地圖和 Python 按年檢查和可視化內容髮布趨勢
我們根據站點地圖類別對被審查網站的內容和意圖進行了匹配,但我們還沒有進行基於時間的分類。 我們將使用resample()方法來完成此操作。
post_per_month = ilkadimlarim.resample('A')['loc'].count()
post_per_month.to_frame()
Resample 是 Pandas 庫中的一種方法。 resample('A') 檢查年度數據幀的數據系列。 對於幾週,您可以使用“W”,對於幾個月,您可以使用“M”。
Loc在這裡象徵著索引; count 表示您要計算數據示例的總和。
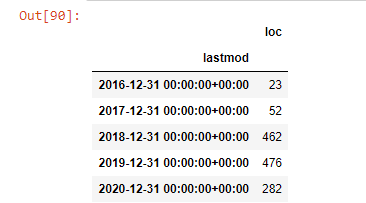
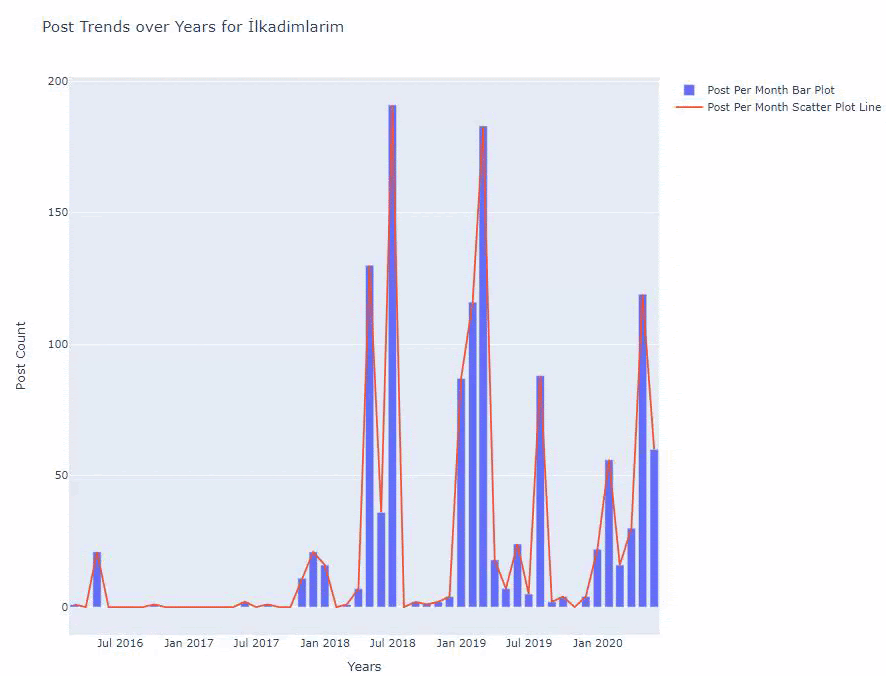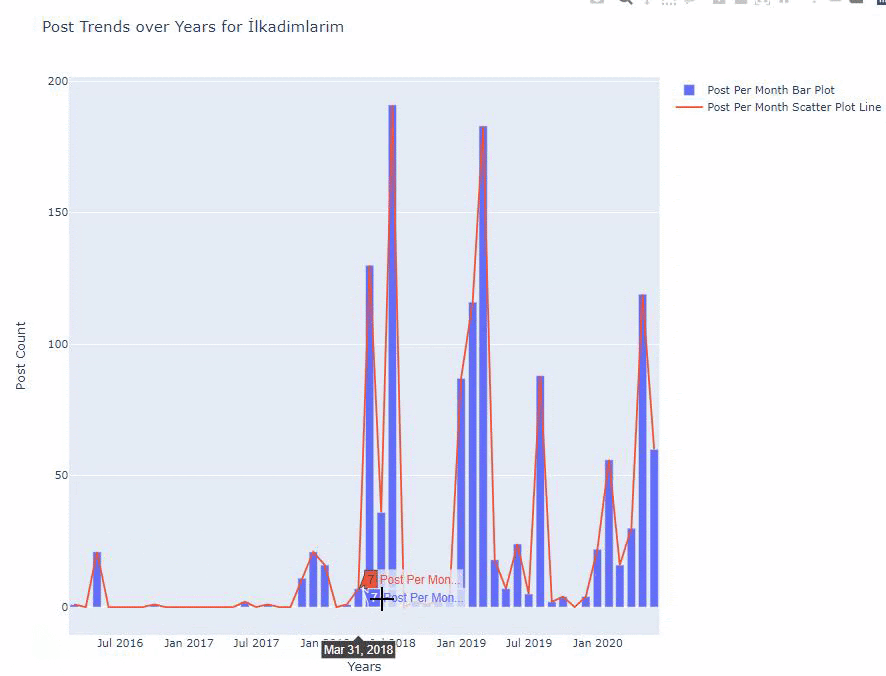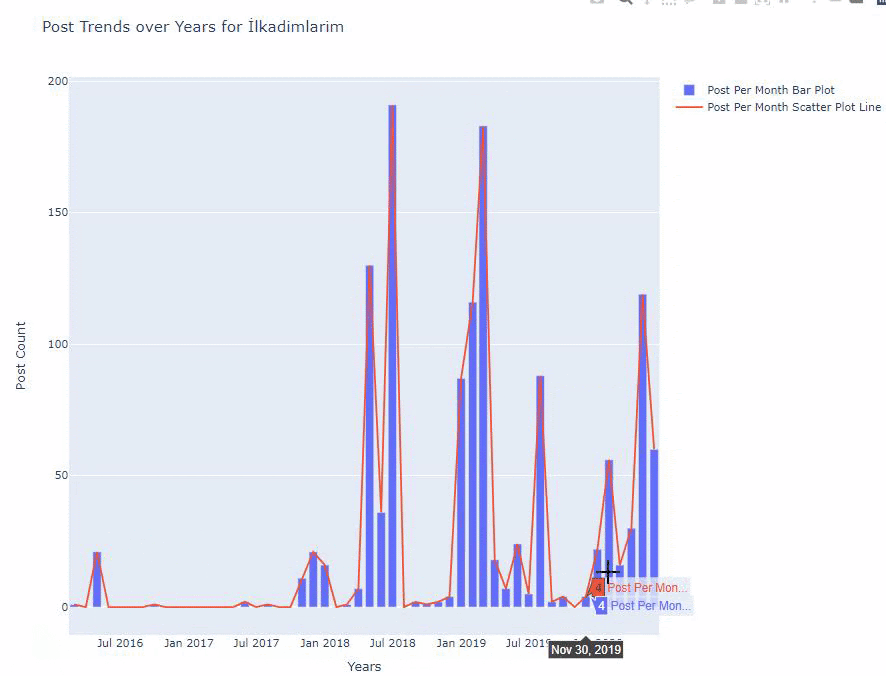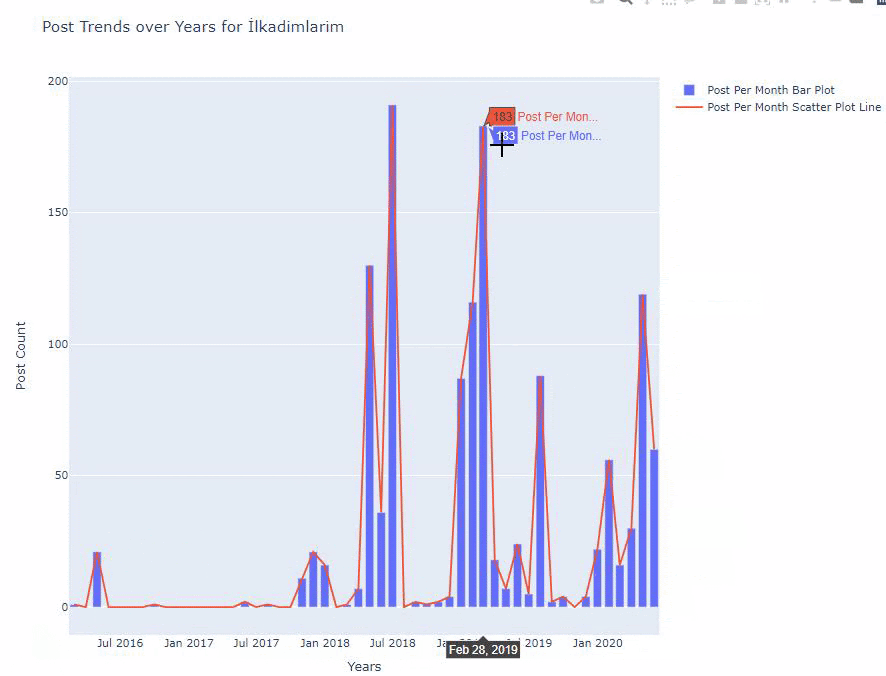
我們看到他們在 2016 年開始發表文章,但他們的主要發表趨勢在 2017 年之後有所增加。我們也可以藉助 Plotly Graph Objects 將其放入圖形中。
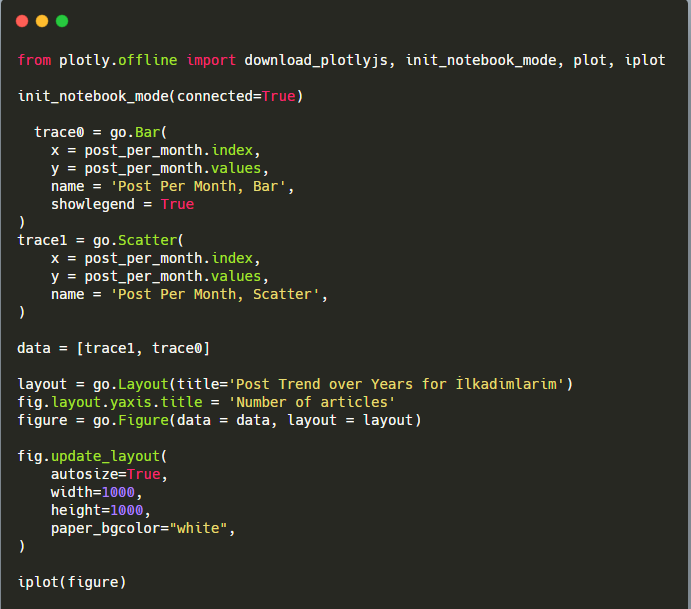
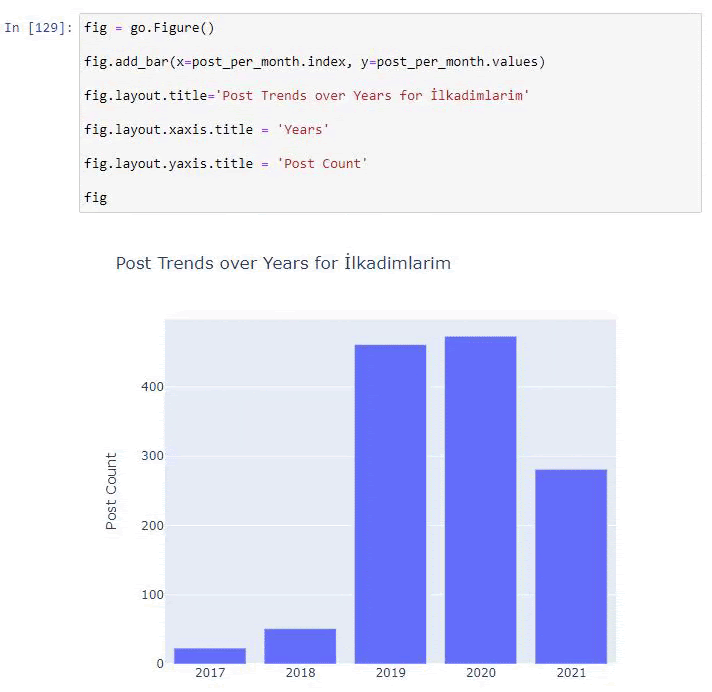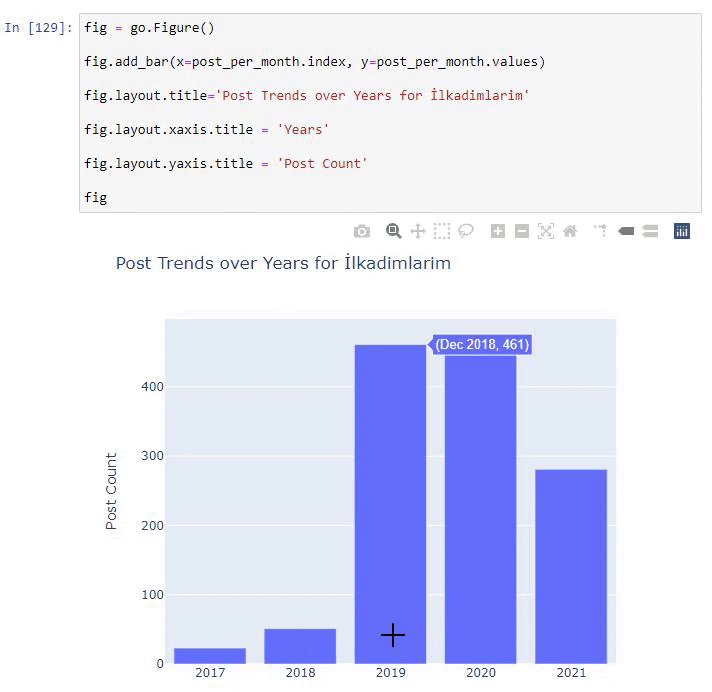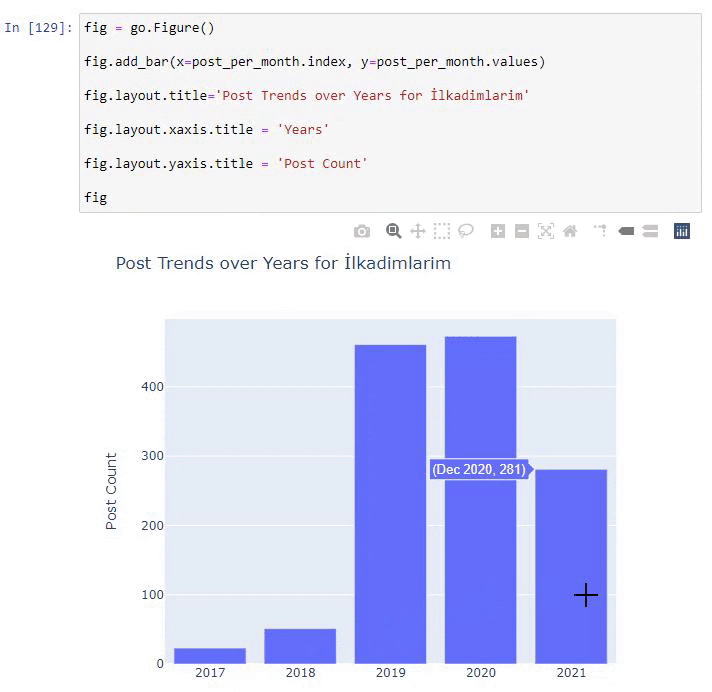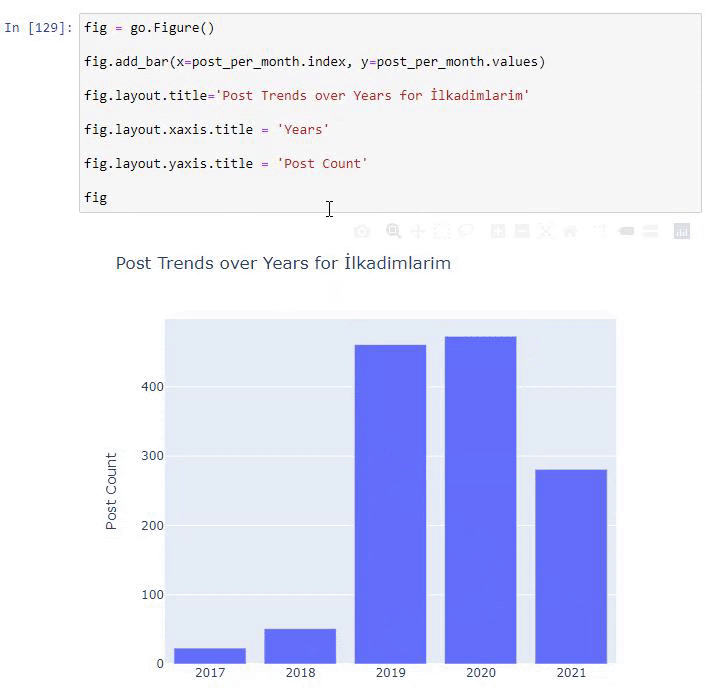
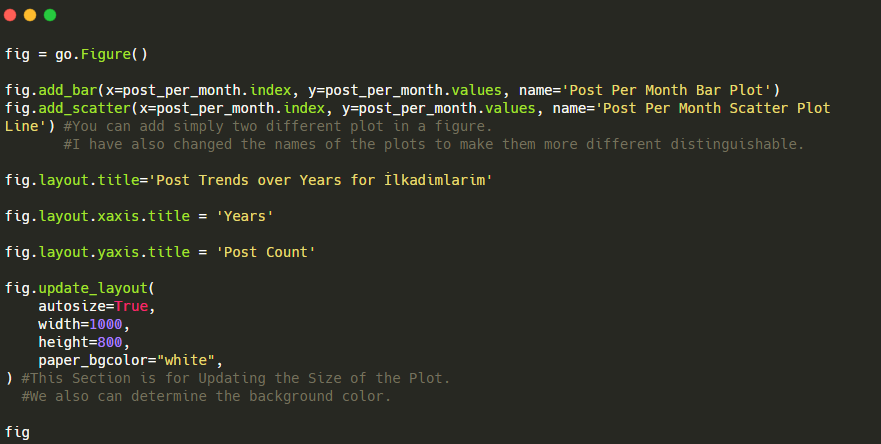
此 Plotly Bar Plot 代碼片段的說明:
- fig = go.Figure()用於創建圖形。
- fig.add_bar()用於在圖中添加條形圖。 我們還確定括號內的 X 軸和 Y 軸。
- Fig.layout用於為圖形和軸創建一個通用標題。
- 在最後一行,我們使用 fig 命令調用我們創建的繪圖,它等於go.Figure()
下面,您將按月找到相同的數據,包括散點圖和條形圖:
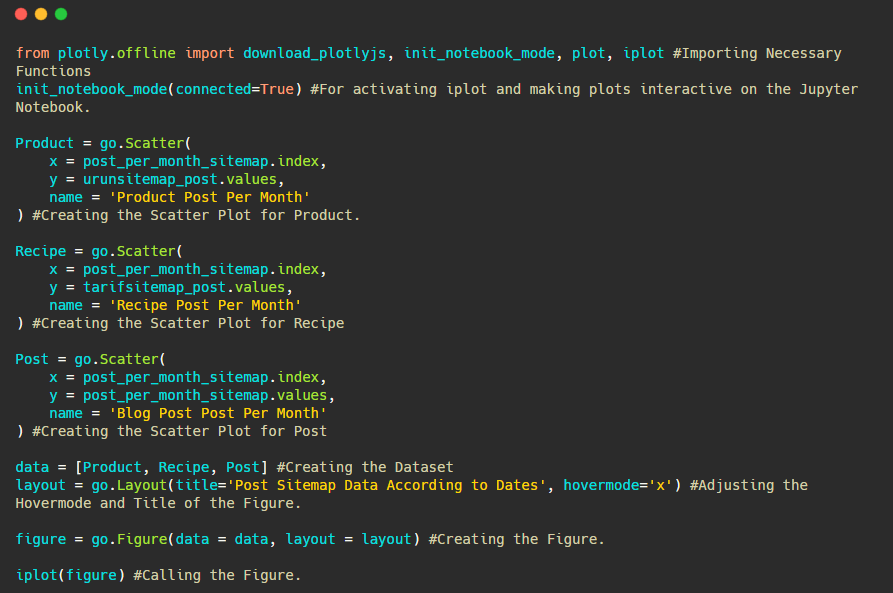
以下是創建此圖的代碼:
我們使用fig.add_scatter()添加了第二個繪圖,並且我們還使用 name 屬性更改了名稱。 fig.update_layout()用於更改繪圖的大小和背景顏色。
您還可以更改懸停模式、條形之間的距離等。 我認為只分享代碼就足夠了,因為在這裡單獨解釋每個代碼可能會導致我們偏離主題。
我們還可以根據以下類別比較競爭對手的內容髮布趨勢:
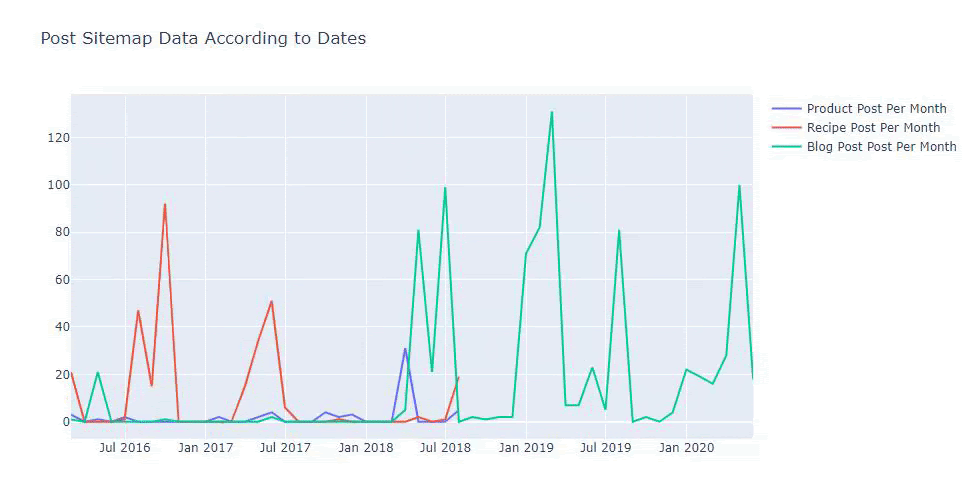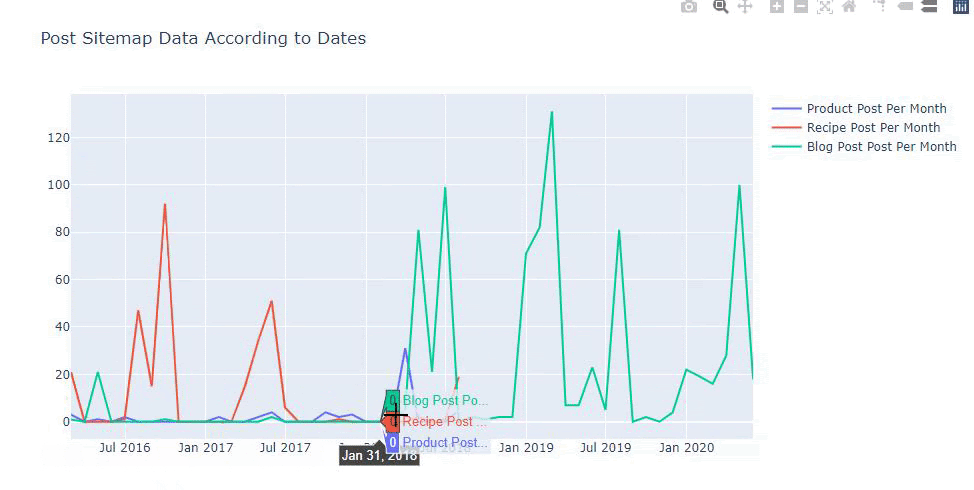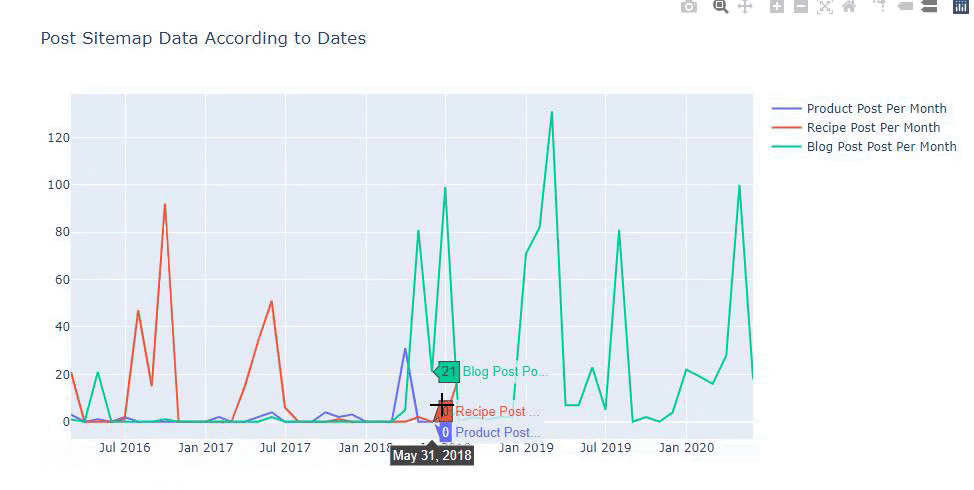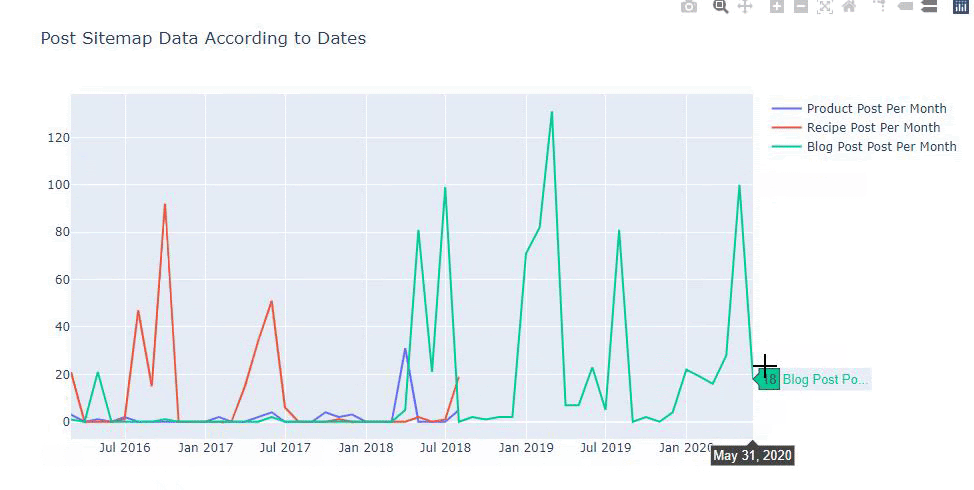
此圖表是使用第二種方法創建的,您可能會看到沒有區別,但其中一個非常簡單。
為了繪製三個獨立站點地圖發佈內容的頻率和趨勢,我們必須將間隔最長的站點地圖放在 X 軸上。 因此,我們可以比較我們正在檢查的網站針對不同搜索意圖發布每種不同類型內容的頻率。
當您檢查下面的相關代碼時,您會發現它與上面的並沒有太大區別。
要創建具有多個 Y 軸的散點圖,您可以使用以下代碼。
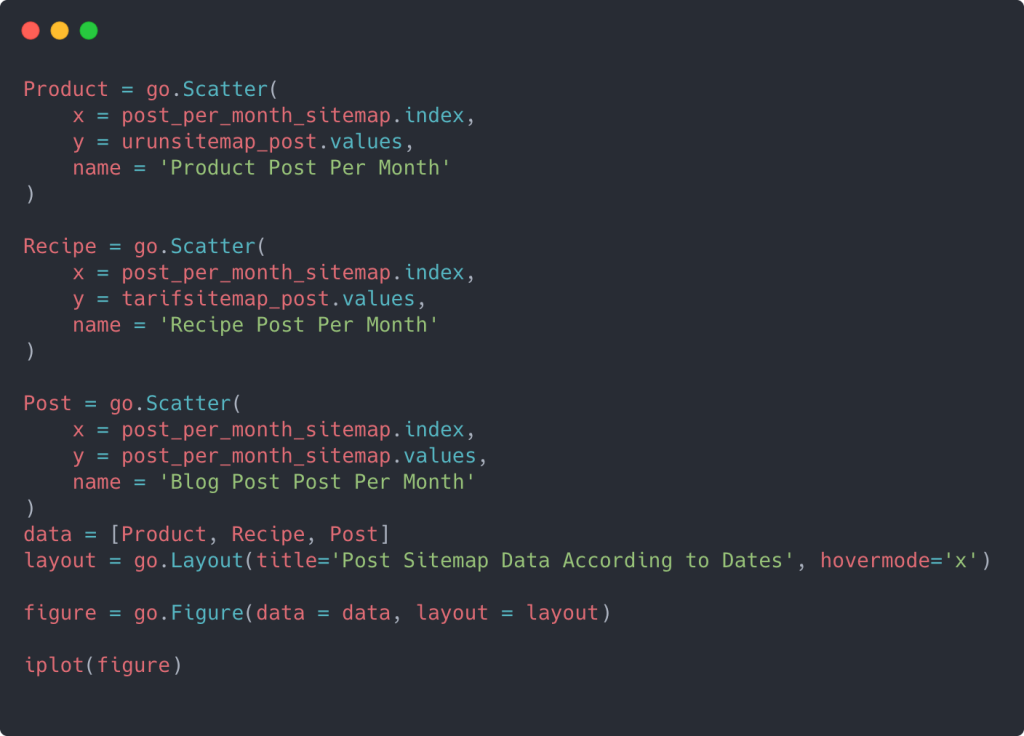
還有其他方法,例如統一不同的站點地圖並為列使用 for 循環以在散點圖中使用多個 Y 軸,但對於如此小的站點,我們不需要這樣做。 在大多數情況下,在擁有數百個站點地圖的網站上使用這種方法會更合乎邏輯。
此外,由於網站很小,圖形可能看起來很淺,但正如您稍後將在具有數百萬個 URL 的網站的文章中看到的那樣,這些圖形是比較不同網站以及比較不同類別的網站的好方法同一個網站。
使用站點地圖和 Python 檢查和可視化內容類別、意圖和發布趨勢
在本節中,我們將檢查他們是否在特定知識領域編寫了大量內容以推銷少量產品,我們在文章開頭說過。 多虧了這一點,我們可能會看到他們是否與其他品牌建立了內容合作夥伴關係。
為了顯示在站點地圖上還可以找到什麼,我們將繼續進行更多的挖掘。 我們還可以從站點地圖的“loc”部分獲取一些信息,例如其他信息。
Ilkadimlarim 的 URL 中沒有類別細分。 如果一個網站的 URL 中有一個類別細分,我們可以了解更多關於內容分發的信息。 如果沒有,我們可以通過編寫額外的代碼來訪問相同的數據,但不確定性較低。
在這一點上,您可以想像,對於抓取數十億網站以了解您的網站的搜索引擎來說,URL 故障的成本會降低多少。
a = ilkadimlarim['loc'].str.contains(“bebek|hamile|haftalik”)
貝貝克:寶貝
哈米爾:懷孕
Haftalik:每週或“懷孕幾週”
baby_post_count = ilkadimlarim[a].resample('M')['loc'].count()
baby_post_count.to_frame()
這裡的str()方法再次允許我們設置選擇某些操作的列。
使用contains()方法,我們確定數據以檢查它是否包含在轉換為字符串的數據中。
這裡,“|” 術語之間的意思是“或” 。
然後我們將我們過濾的數據分配給一個變量,並使用我們之前使用的resample()方法。
另一方面,計數方法測量使用了哪些數據以及使用了多少次。
使用 count() 獲得的結果再次包含在to_frame()中。
此外, str.contains()默認採用 Regex 值,這意味著您可以用更少的代碼創建更複雜的過濾條件。
換句話說,此時,我們將包含單詞“baby”、“weekly”、“pregnant”的 URL 分配給ilkadimlarim中的變量,然後我們將 URL 的發布日期放在我們過濾器的適當條件中在一個框架中創建。
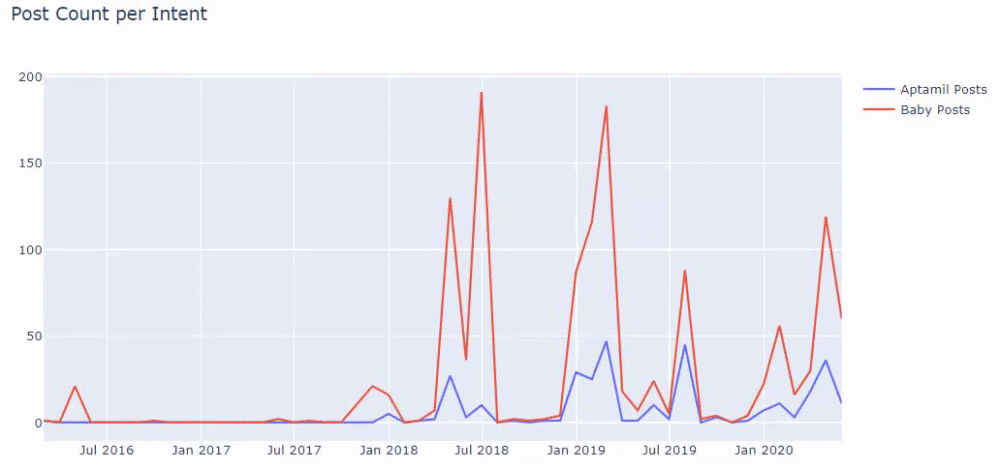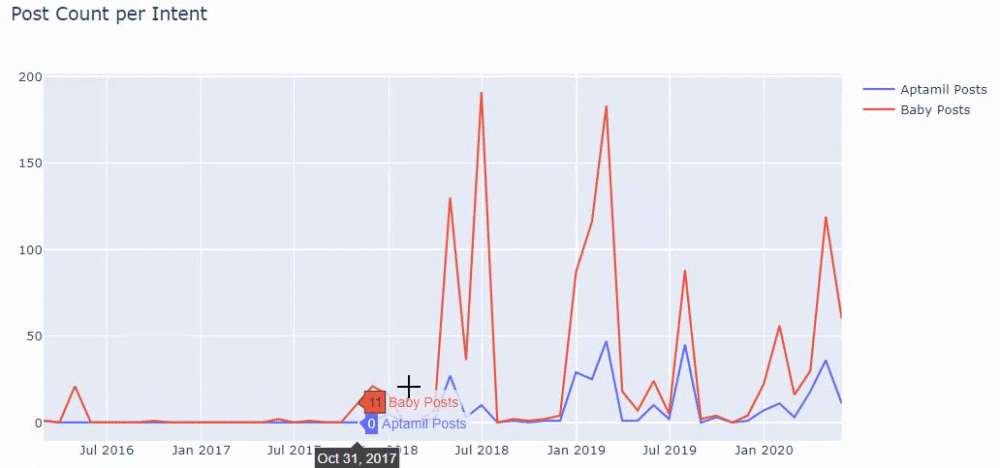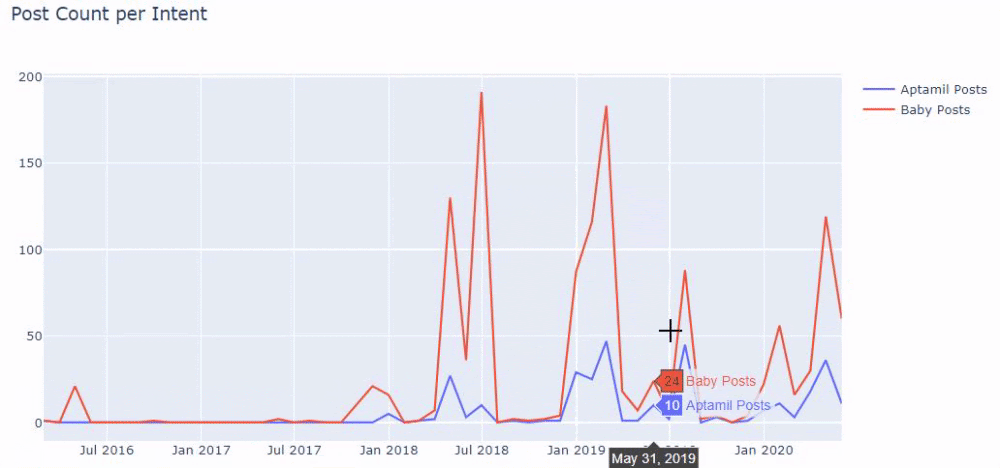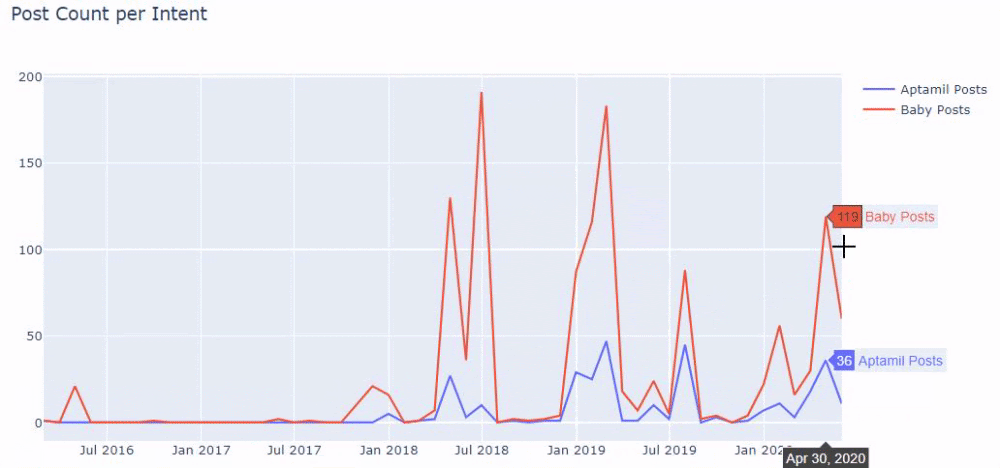
然後我們對包含單詞“aptamil”的 URL 執行相同的操作。 Aptamil 是 Ilkadimlarim 推出的嬰兒營養產品的名稱。 因此,我們也可以關注信息性和商業性內容的播放密度。
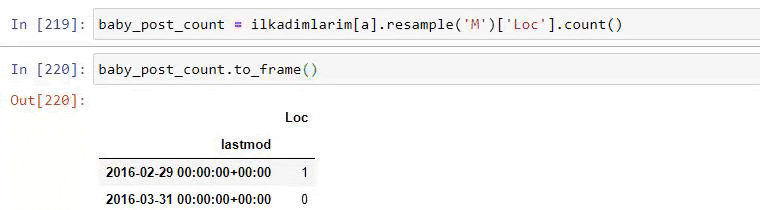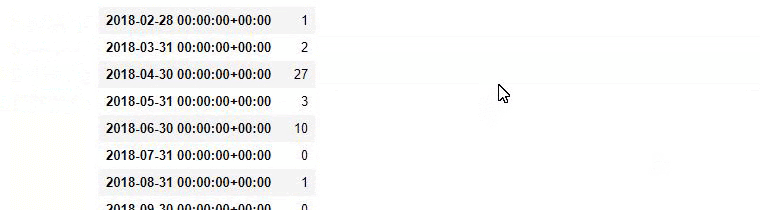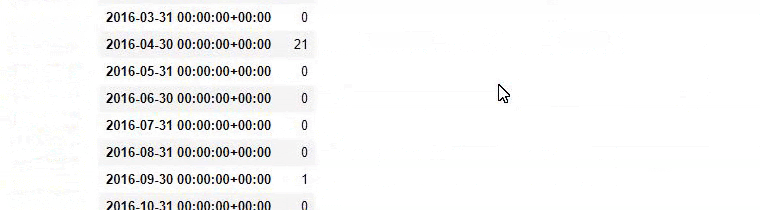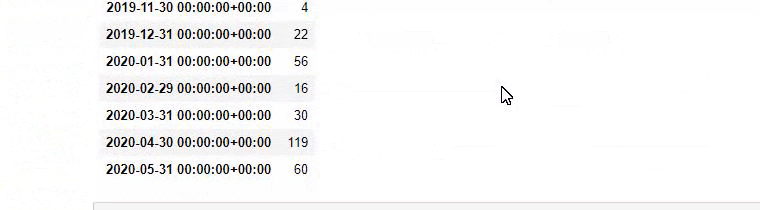
您可能會看到這兩個不同的內容組多年來針對不同的搜索意圖發布了時間表,其中來自 URL 的信息更加確定和準確。
生成此圖表的代碼未共享,因為它與用於上一張圖表的代碼相同
在 Google 搜索運營商的幫助下,當我想要在 Ilkadimlarim.com 的錨文本中使用 Aptamil 一詞的頁面時,我得到了 38 個結果。 這些頁面中有很多是信息豐富的,它們鏈接商業內容。

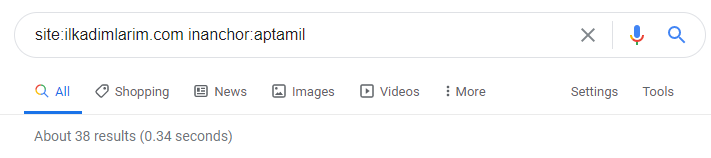
我們的論點已經得到證實。
“我的第一步”使用數百篇關於母性、嬰兒護理和懷孕的信息內容來吸引目標受眾。 “Ilkadimlarim”從該內容鏈接包含 Aptamil 產品的頁面,並將用戶引導到那裡。
通過使用 Python 的站點地圖比較內容分析和分析內容策略
現在,如果您願意,讓我們對同一行業的公司做同樣的事情,並進行比較,以了解該行業的總體情況以及這兩個品牌之間的戰略差異。
作為第二個例子,我選擇了 Prima.com.tr,它是幫寶適,但在土耳其使用品牌名稱 Prima。 由於 Prima 有一個單一的站點地圖,我們將無法按站點地圖進行分類,但至少它們的 URL 有不同的中斷。 所以我們很幸運:我們將不得不編寫更少的代碼。
想像一下,當您製作一個難以理解的網站時,Google 必須為您運行的算法成本要高出多少! 這可以幫助您更清楚地了解爬網成本計算,即使只是相對於 URL 結構也是如此。
為了不進一步增加文章的體積,我們沒有放置與我們已經做過的類似的過程的代碼。
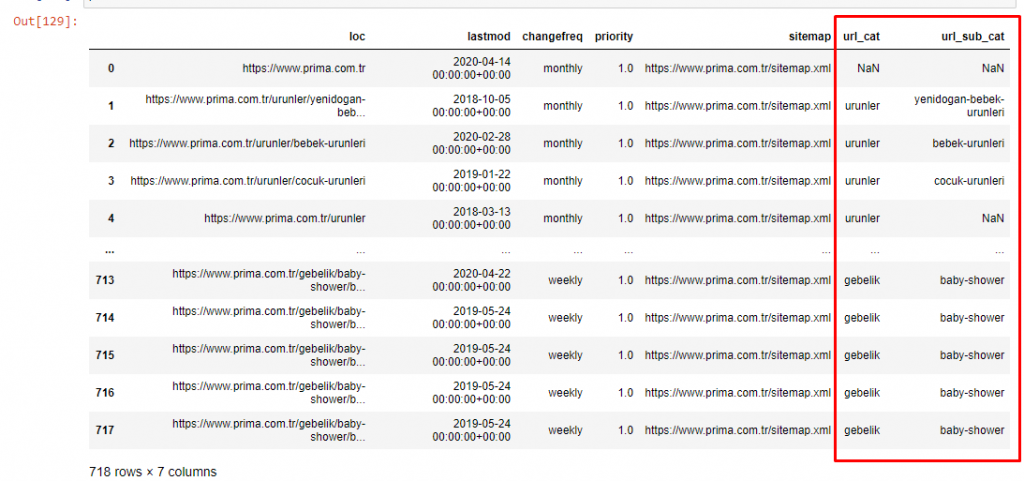
現在,我們可以通過 URL 類別和 URL 子類別檢查它們的內容類別分佈。 我們看到他們擁有過多的公司網頁。 這些公司網頁位於“prima-hakkinda”(“關於 Prima”)部分。 但是當我用 Python 檢查它們時,我發現它們已經將他們的產品和公司網頁統一在一個類別中。 你可以在下面看到他們的內容分佈:

我們可以對以下子類別做同樣的事情。
有趣的是,Prima 使用“gebelik”(土耳其語中的懷孕),它是“hamilelik”(阿拉伯語中的懷孕)的變體,兩者都表示懷孕期。

現在我們看到對其內容進行更深入的分類。 9.2%的內容是關於健康懷孕,7.3%是關於嬰兒的成長過程,8.3%的內容是關於可以和嬰兒一起做的活動,0.7%是關於嬰兒的睡眠順序。 甚至還有 3.9% 的出牙、1.9% 的嬰兒安全和 1.4% 的向家人透露懷孕等話題。 如您所見,您可以通過 URL 及其分佈百分比了解一個行業。
這不是完美的分類,但至少我們可以看到競爭對手的心態和內容營銷趨勢,以及他們網站的內容分類。 現在讓我們按月檢查發佈內容的頻率。
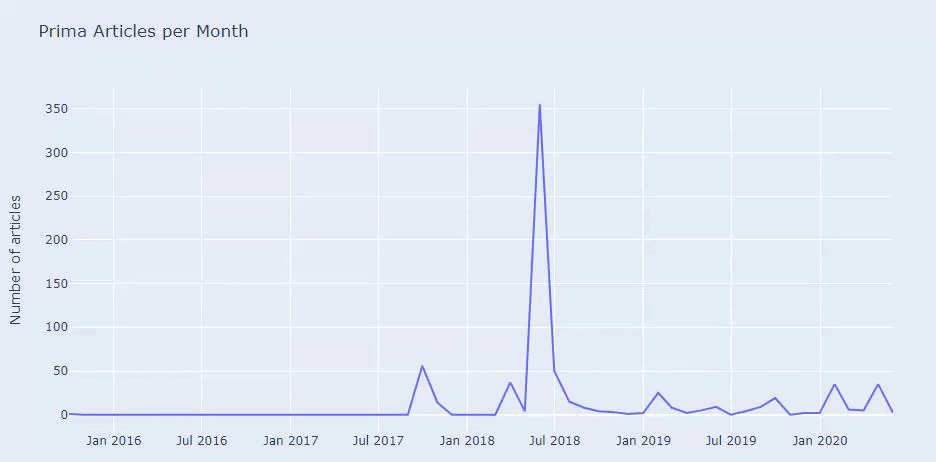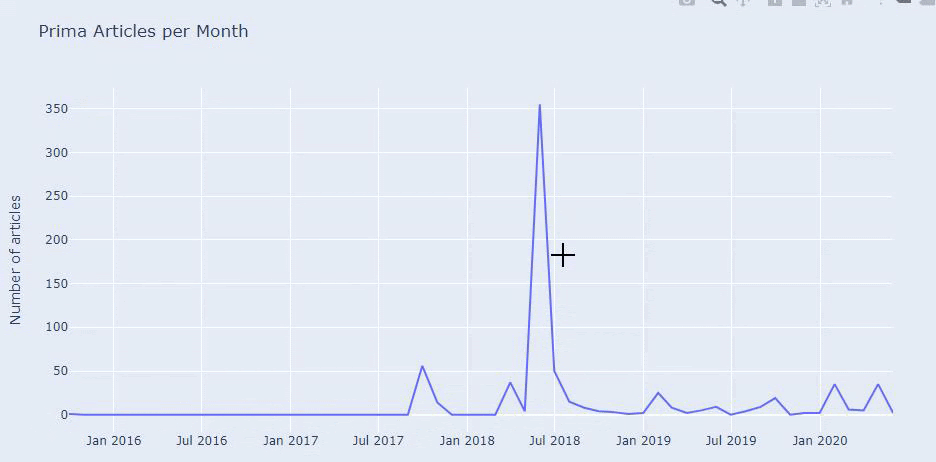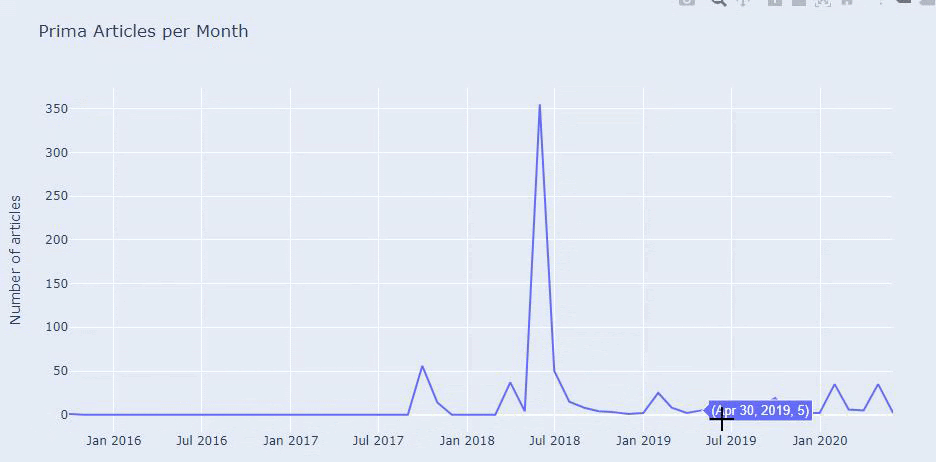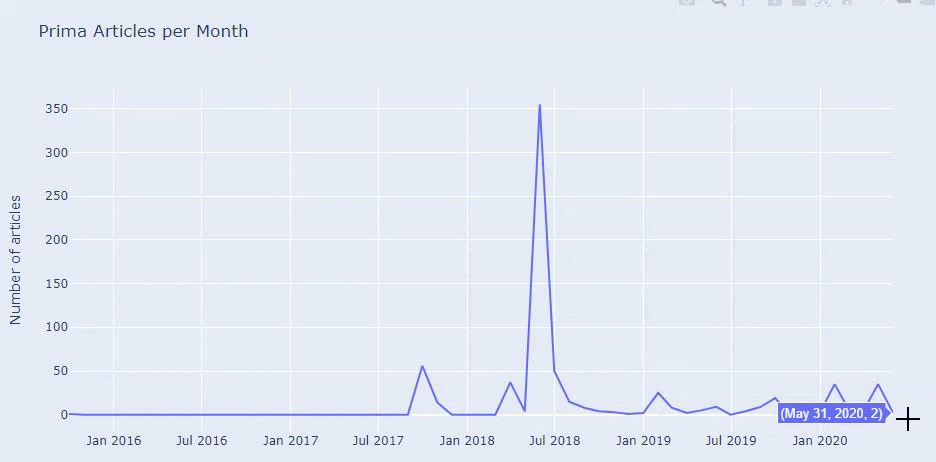
我們看到他們在 2018 年 7 月發表了 355 篇文章,根據 Sitemap,他們的內容從那時起就沒有刷新過。 我們還可以根據多年來的類別比較他們的內容髮布趨勢。 如您所見,它們的內容主要位於四個不同的類別中,並且大多數都在同一個月內發布。
在繼續之前,我必須說站點地圖數據可能並不總是正確的。 例如,所有 URL 的 Lastmod 數據可能已更新,因為它們在該日期更新了所有站點地圖。 為了解決這個問題,我們還可以使用 Wayback Machine 檢查他們是否沒有更改過他們的內容。
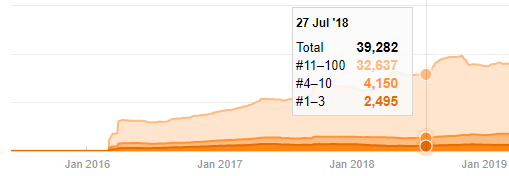
即使看起來可疑,這些數據也可能是真實的。 土耳其的許多公司傾向於先下大量訂單並發佈內容。 當我檢查他們的關鍵字計數時,我看到了這段時間的跳躍。 因此,如果您正在執行比較內容配置文件和策略分析,您還應該考慮這些問題。
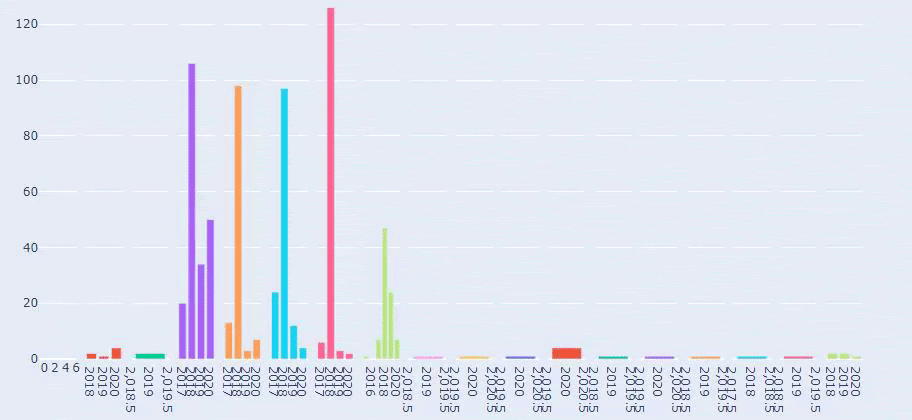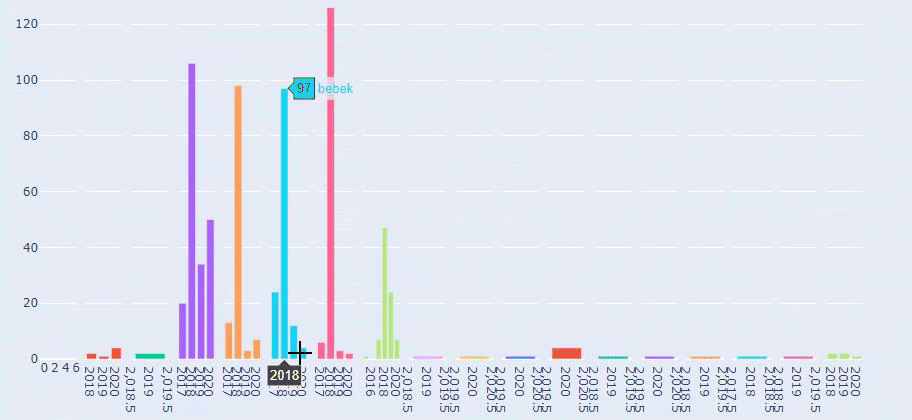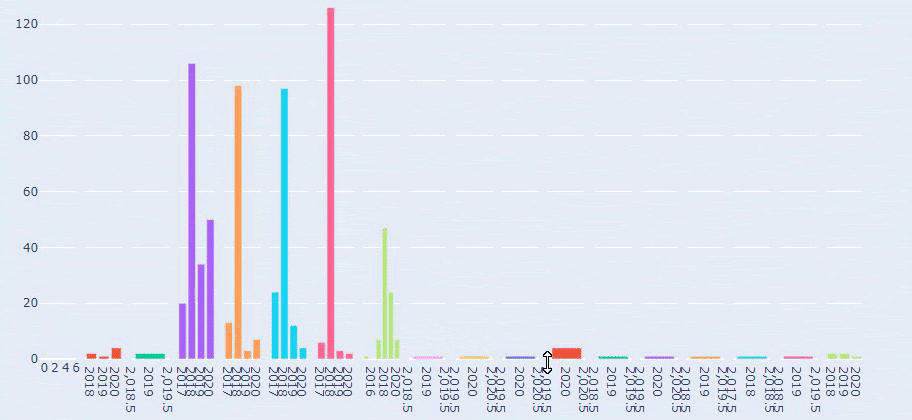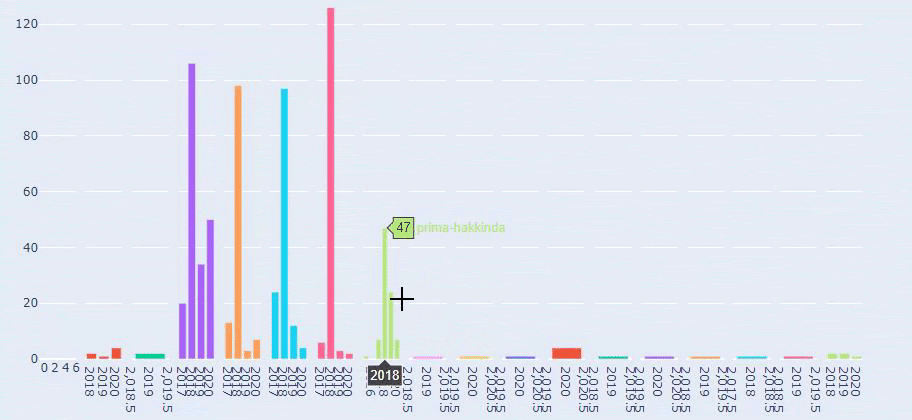
這是 Prima.com.tr 多年來每個類別的內容髮布趨勢之間的比較
現在,我們可以比較兩個不同網站的內容類別及其發布趨勢。
當我們查看 Prima 發表關於嬰兒成長、懷孕和母親的文章的頻率時,我們發現與 Ilkadimlarim 的相似之處:
- 大多數文章都是在某個時間發表的。
- 他們已經很長時間沒有更新了。
- 與信息內容頁面的數量相比,產品和頁面的數量非常少。
- 最近,他們剛剛在他們的網站上添加了新產品。
我們可以將這四個特徵視為行業的默認思維方式,我們可以利用這些弱點來支持我們的活動。 畢竟,質量需要新鮮度(正如穀歌研究員 Amit Singhal 所說)。
在這一點上,我們也看到業界對 Googlebot 的行為並不熟悉。 與其一天上傳250條內容,一年不做任何改動,不如定期添加新內容,定期更新舊內容。 因此,您可以保持內容的質量,Googlebot 可以更輕鬆地了解您的網站,並且您的抓取需求頻率值將高於您的競爭對手。
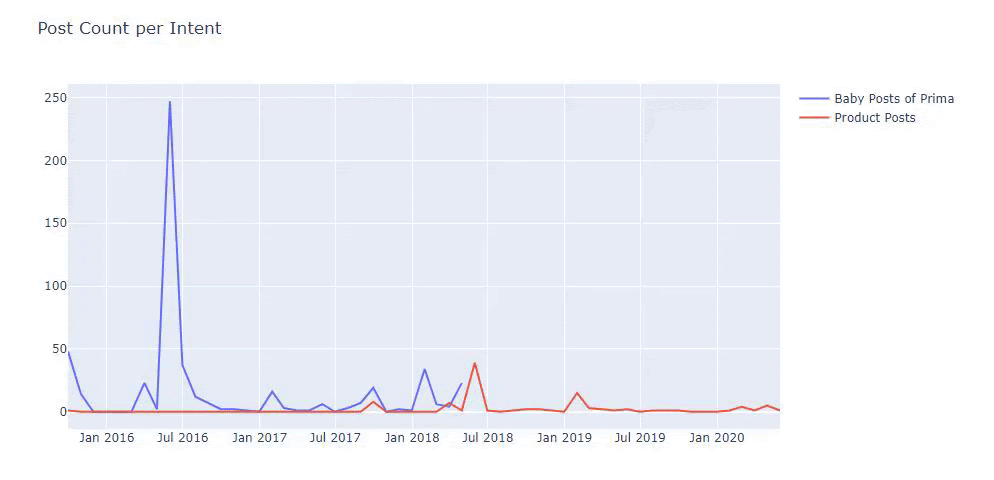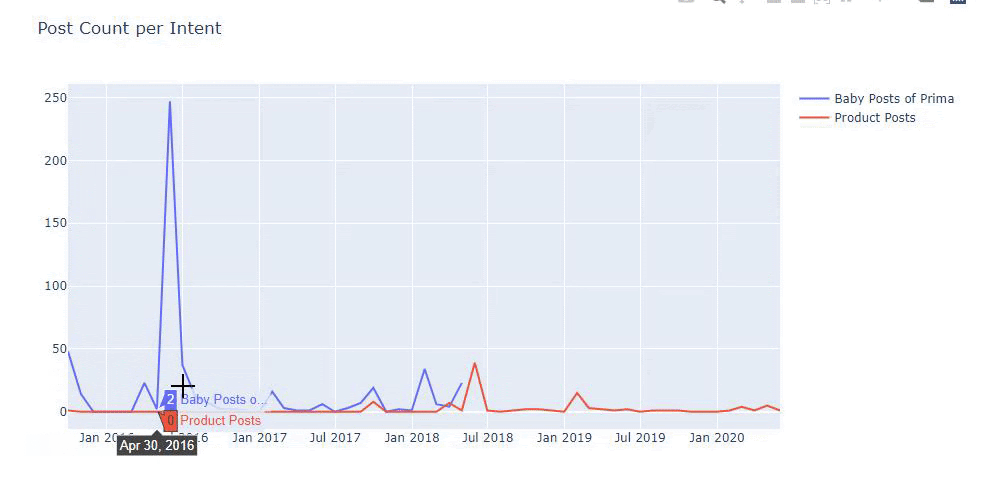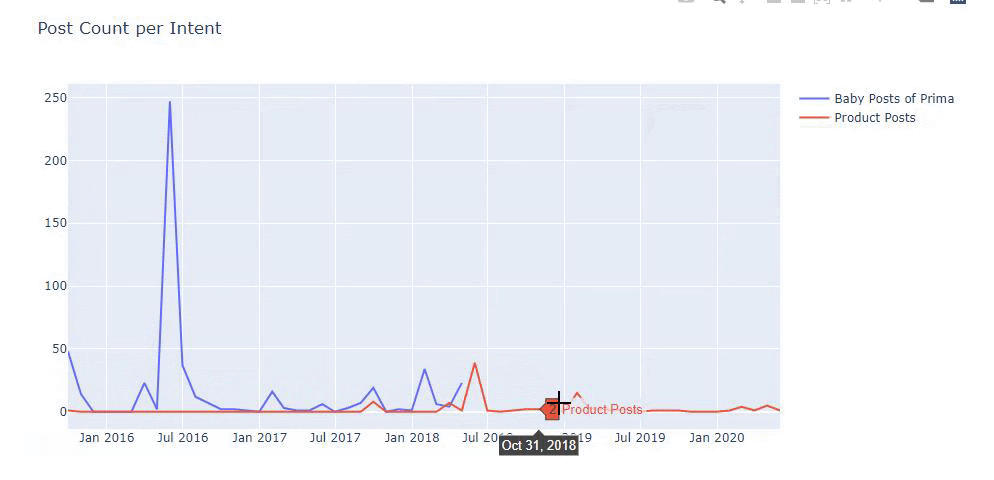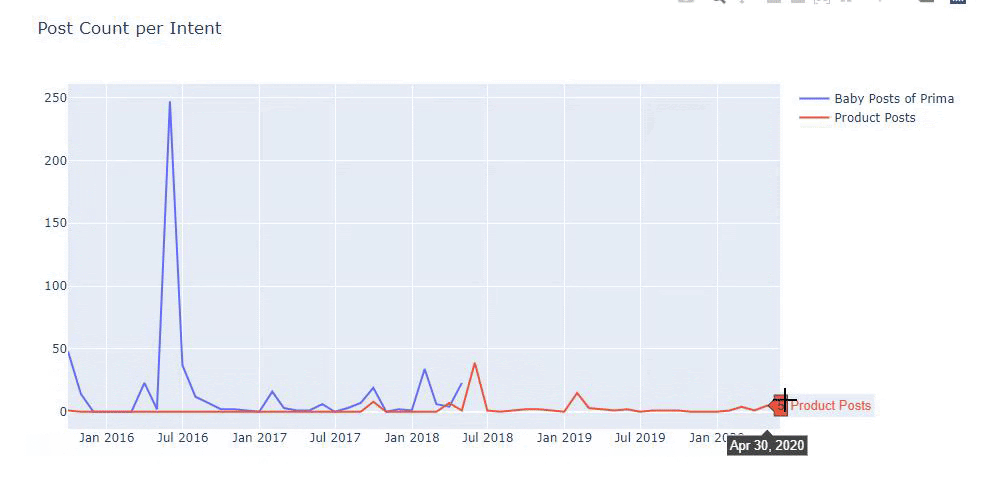
我使用以前的方法來區分產品頁面和信息內容頁面,並分析 URL 中最常用的詞。 這裡的寶貝帖子意味著這些是內容豐富的內容。
如您所見,他們在一天之內添加了 247 個內容。 此外,他們在一年多的時間裡沒有發布或更新信息性內容,只是偶爾添加一些新的產品頁面。
現在讓我們用兩個不同的圖表來比較他們的出版趨勢。 我使用下面的代碼來創建這個圖:
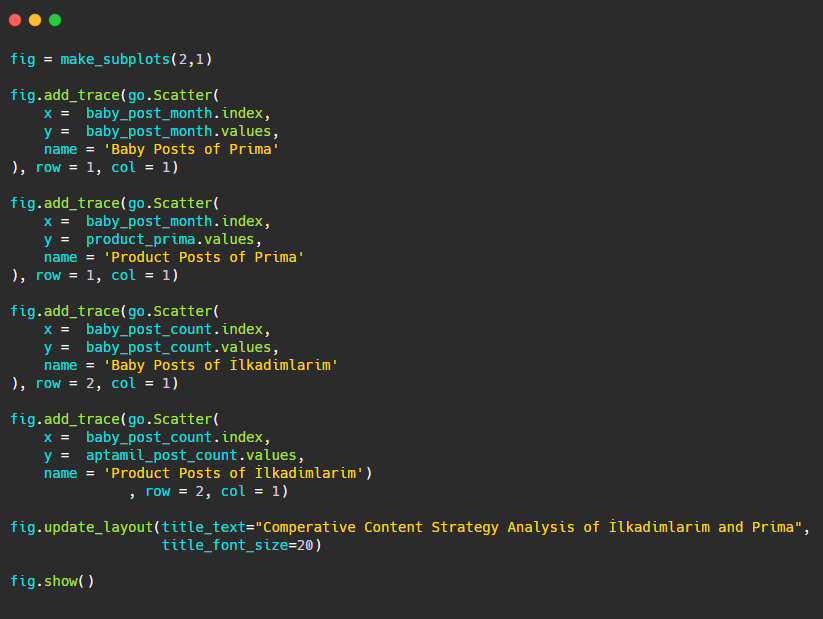
由於此圖形與以前的圖形不同,因此我想向您展示代碼。 在這裡,兩個單獨的圖放置在同一個圖中。 為此,使用來自plotly.subplots import make_subplots 的命令調用了 make_subplots 方法。
它是使用make_subplots (2,1)創建為兩行一列的圖形。
因此, col 和 row 寫在跡線的末尾,並指定了它們的位置。 這是一個任何熟悉 CSS 中網格系統的人都可以輕鬆識別的系統。
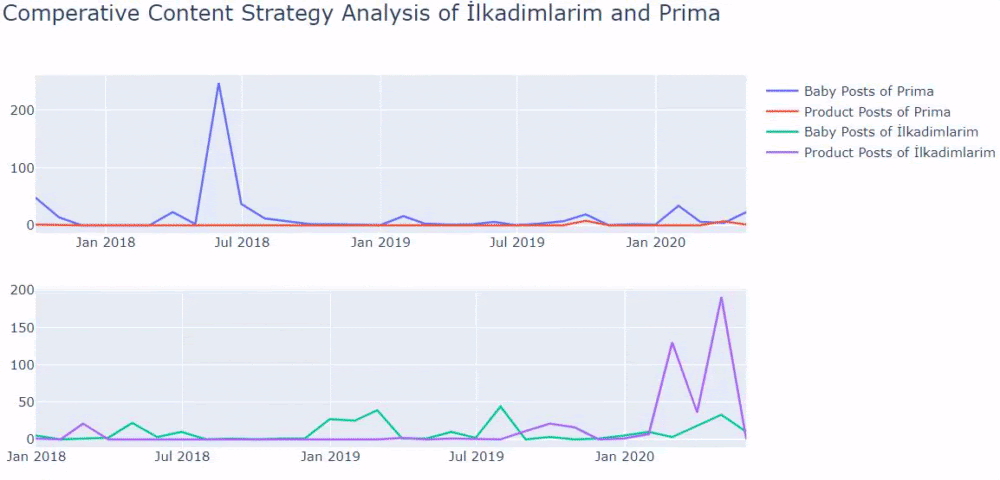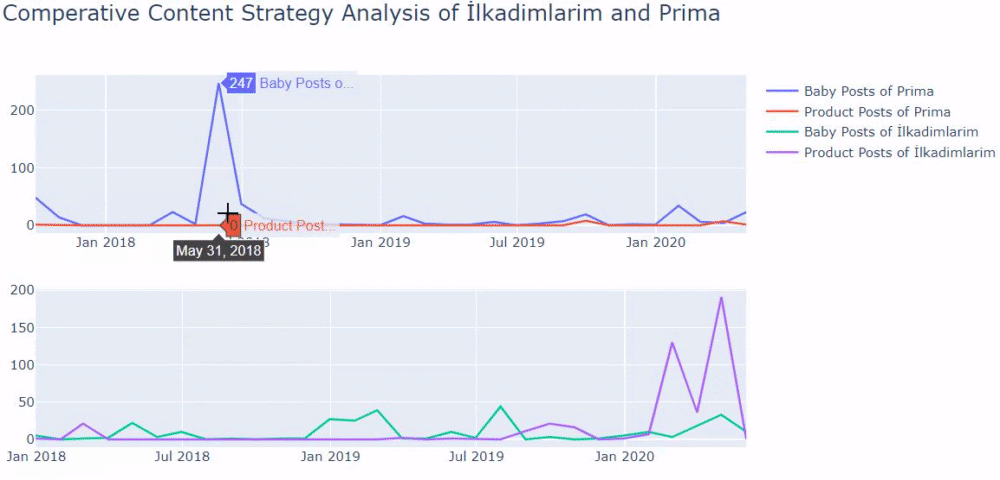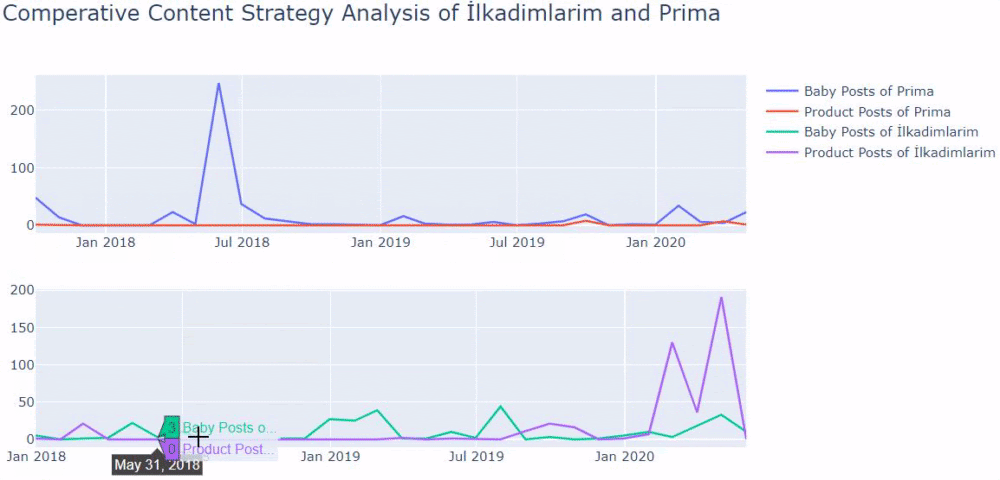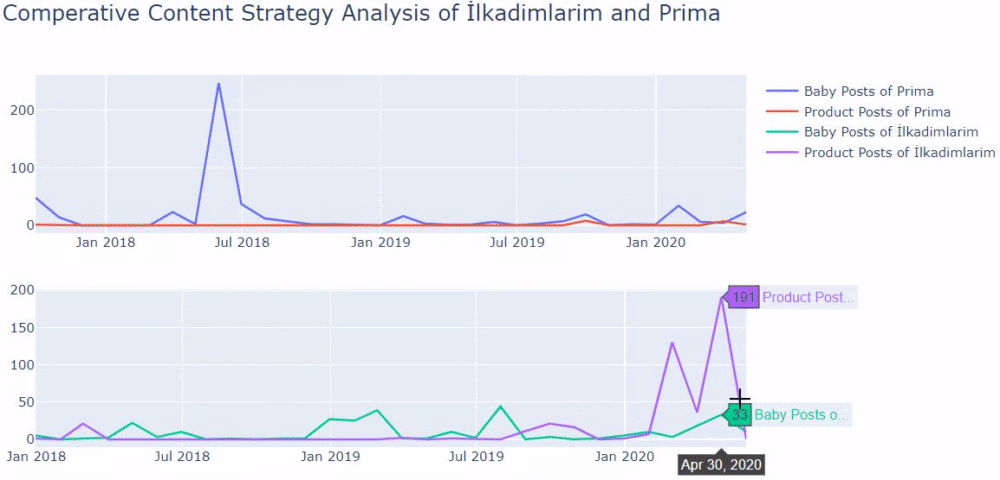
如果您有同一行業的客戶,您可以使用這些數據來創建內容策略,查看競爭對手的弱點以及他們在 SERP 上的查詢/登陸頁面網絡。 此外,您可以了解應該在同一知識領域或針對同一用戶意圖發布多少內容。
在總結我們可以從站點地圖中學到的內容作為內容策略分析的一部分之前,我們可以檢查最後一個來自另一個行業的 URL 計數更高的網站。
使用 Python 和站點地圖對貨幣上的新聞 Web 實體進行內容策略分析
在本節中,我們將使用 Seaborn 的熱圖以及一些更高級的框架和數據提取方法。

Elias Dabbas 在數據科學和 SEO 方面有一個有趣且非常有用的 Kaggle 存檔。 本月,他為土耳其新聞網站開設了一個新的 Kaggle 數據集部分,供我編寫必要的代碼並通過站點地圖使用 Advertools 執行內容策略分析。
在我開始在 Kaggle 上使用這些技術之前,我想展示一些示例,說明如果我們在本文中在更大的 Web 實體上使用相同的技術會發生什麼。
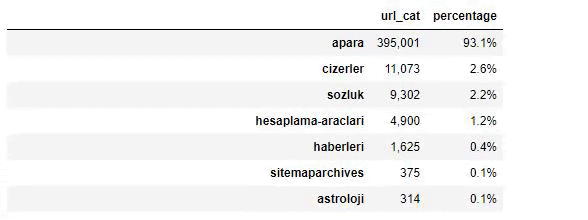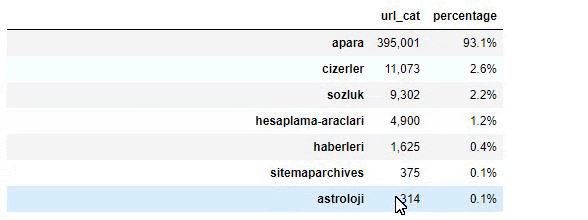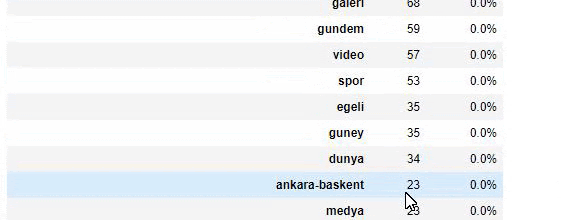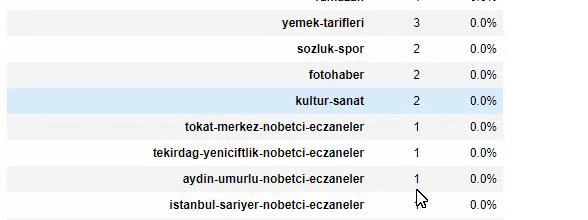
當我們分析沙巴報的內容時,我們發現其內容的很大一部分(81%)屬於一個名為“apara”的類別。 此外,它們還有一些占星術、計算、字典、天氣和世界新聞的大類別。 (Para 在土耳其語中是錢的意思)
對於沙巴報紙,我們也可以使用僅使用 Adverttools 收集的站點地圖來分析內容,但由於所討論的報紙非常大,我不喜歡它,因為站點地圖數量眾多且包含相同 URL 的不同站點地圖的內容類別。
您還可以在下面看到使用 Advertools 的過多站點地圖。
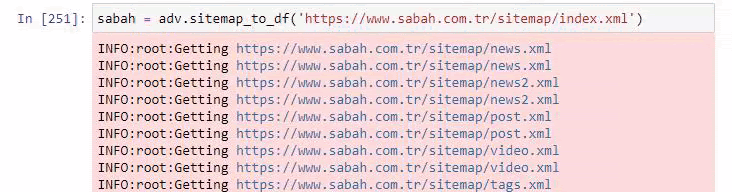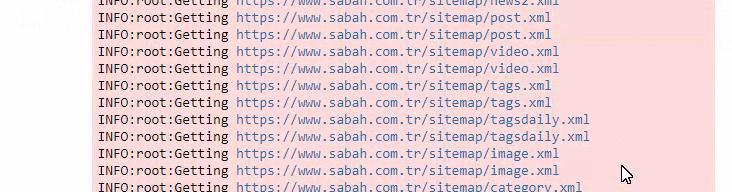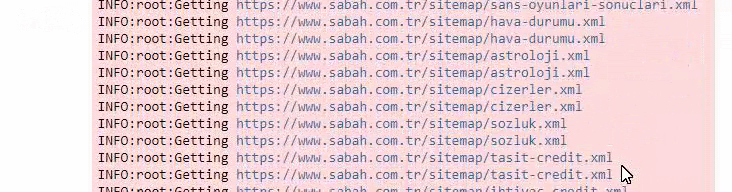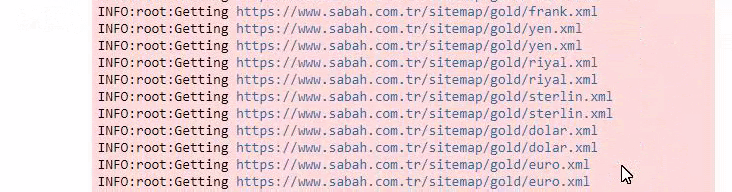
我們可能會看到他們對相同的 URL 類別有不同的站點地圖,例如黃金、信用、貨幣、標籤、祈禱時間和藥房工作時間等……
簡而言之,我們可以通過關注 URL 的子類別來實現這些細節。 而不是通過變量統一不同的站點地圖。 所以,我用 Advertools 的 sitemap_to_df() 方法統一了所有的站點地圖,就像文章開頭一樣。
我們還可以使用 Elias Dabbas 創建的另一組函數來創建更好的數據框。 如果您檢查 dataset_utilites 函數,您可以看到一些示例。 下面的代碼通過樣式化給出了指定 URL 正則表達式的總數和百分比以及累積總和。
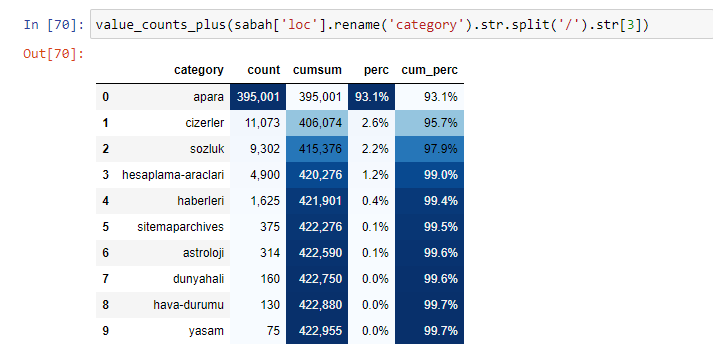
如果我們對 Sabah Newspaper 的子 URL 細分做同樣的事情,我們將得到以下結果。
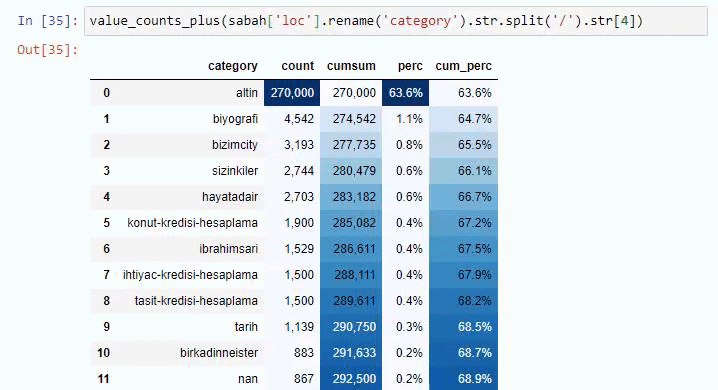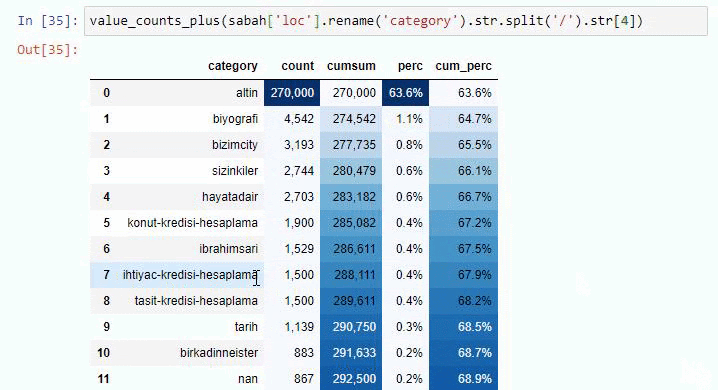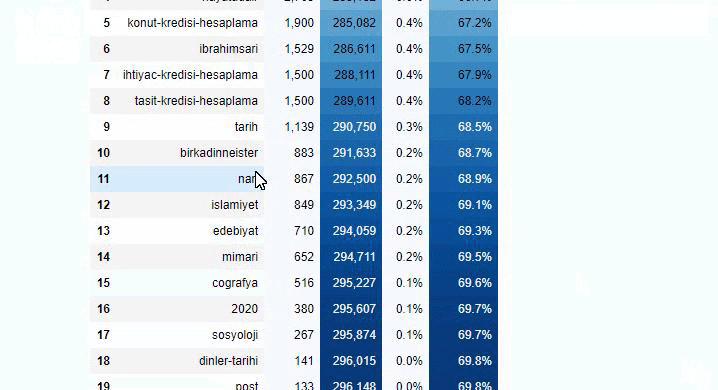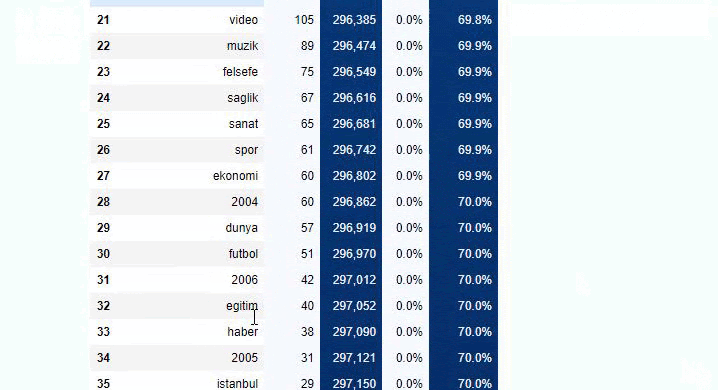
您可以通過更改下面的行來增加相關函數將輸出的行數。 此外,如果您檢查函數的內容,您會發現它與我們之前使用的類似。
在細分中,我們看到了不同的細分,例如“宗教歷史”、“傳記”、“城市名稱”、“足球”、“Bizimcity(漫畫)”、“抵押貸款”。 最大的細分是“黃金”類別。
那麼,一份報紙怎麼會有 295,000 個黃金價格的 URL 呢?
首先,我將沙巴報紙的第一個 URL 細分中包含“apara”的所有 URL 放入一個變量中。
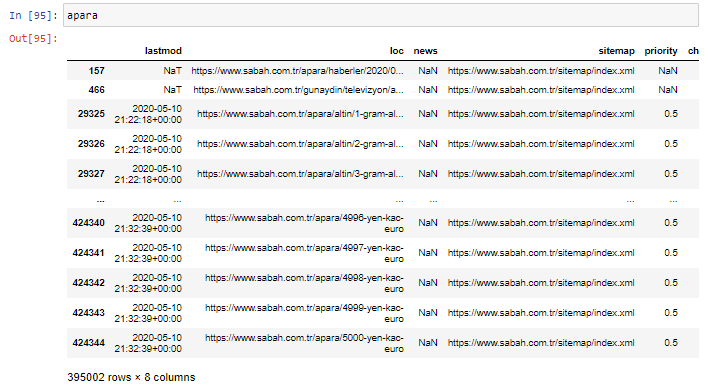
apara = sabah[sabah['loc'].str.contains('apara')]
結果如下:
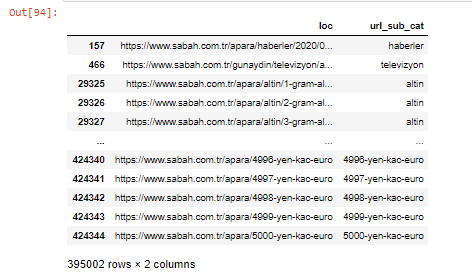
我們還可以使用 .filter() 方法過濾列:
現在,我們可以在 DataFrame 的底部看到為什麼 Sabah Newspaper 有過多的 Apara URL,因為他們為每筆貨幣計算(例如 5000 歐元、4999 歐元、4998 歐元等等)打開了不同的網頁……
但是,在得出任何結論之前,我們需要確定,因為這些 URL 中有超過 250,000 個屬於“altin (gold)”類別。
apara.filter(['loc', 'url_sub_cat' ]).tail(60) 將顯示這個數據框的最後 60 行:

我們可以對 Apara 組中的黃金 URL 細分執行相同的操作。
金 = apara[apara['loc'].str.contains('altin')]
gold.filter(['loc','url_sub_cat']).tail(85)
gold.filter(['loc','url_sub_cat']).head(85)
至此,我們看到《沙巴報》已經打開了 5000 個不同的頁面,將每種貨幣兌換成美元、歐元、黃金和 TL(土耳其里拉)。 1 到 5000 之間的每個貨幣單位都有一個單獨的計算頁面。您可以在下面看到黃金組的前 85 行和後 85 行的示例。 每克黃金價格都打開了一個單獨的頁面。


我們毫不懷疑這些頁面是不必要的,有很多重複的內容,而且過大,但沙巴報紙是這樣一個品牌強大的網站,谷歌幾乎在每個查詢中都繼續顯示它,排名靠前。
在這一點上,我們也可以看到,對於一個具有高權限的舊新聞網站,Crawl Cost Tolerance 是很高的。
但是,這並不能解釋為什麼黃金類別的 URL 比其他類別多。
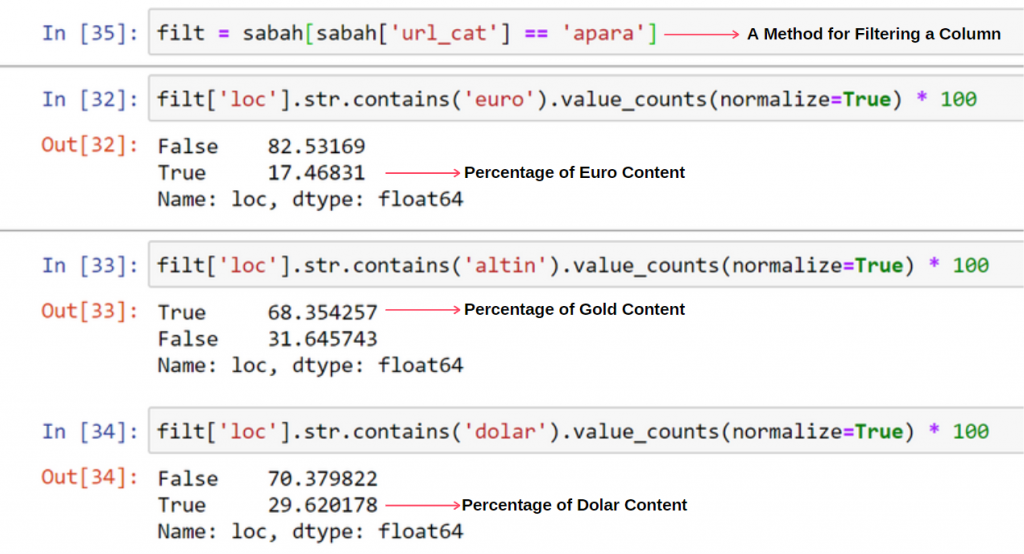
我沒有看到重疊值加起來超過 100% 有什麼奇怪的地方。
除非我錯過了什麼?
正如您會注意到的,當我們將所有真值相加時,我們得到 115.16% 的結果。 原因如下。
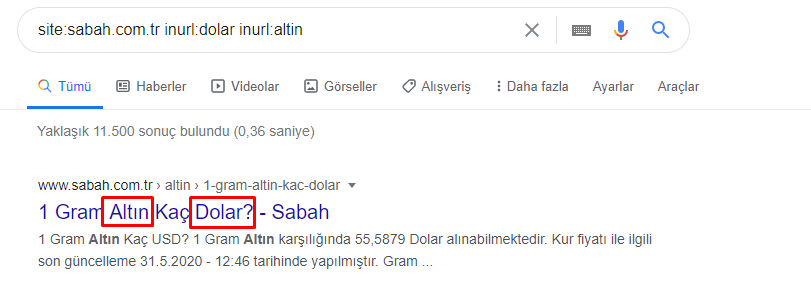
就連主隊也有這樣的交集。 我們也可以分析這些交叉點,但它可能是另一篇文章的主題。
我們看到 Apara URL 組中 68% 的內容與 GOLD 相關。
為了更好地理解這種情況,我們需要做的第一件事是掃描黃金折射中的 URL。
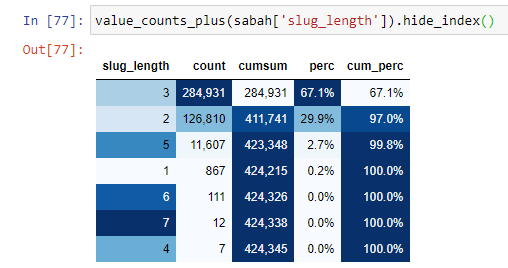
當我們根據自根部分以來的“/”數量對 URL 進行分類時,我們看到最多 3 個中斷的 URL 的數量很高。 當我們分析這些 URL 時,我們看到 3 個 slug_length URL 中有 270.000 個屬於 Gold 類別。
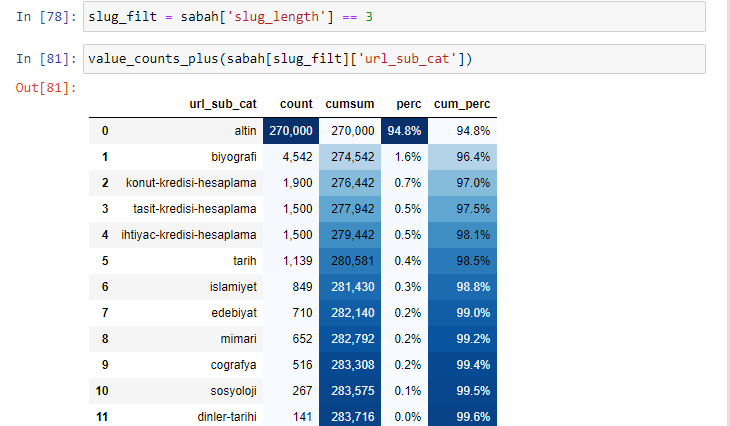
Morning_filt = Morning ['slug_length'] == 3 表示你只從某個數據幀的某一列的 int 數據類型的數據組中獲取等於 3 的那些。 然後,基於這些信息,我們將適合條件的 URL 用計數、總和和聚合率與累積總和框起來。
當我們提取黃金 URL 中最常用的詞時,我們會遇到代表“full”、“republic”、“quarter”、“gram”、“half”、“ancestor”的詞。 Ata 和共和國黃金類型是土耳其獨有的。 其中一位代表土耳其主權,另一位是共和國的創始人凱末爾·阿塔圖爾克。 這就是他們的查詢搜索量很高的原因。
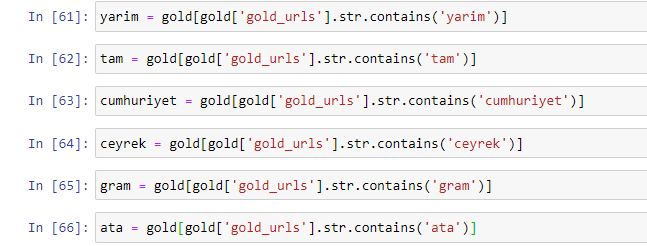
首先,我們刪除了 URL 中的常用詞,並將它們分配給單獨的變量。 接下來,我們將在 Gold DataFrame 中使用這些變量來創建特定於其類型的列。
通過變量創建新列後,我們必須將它們與布爾值一起過濾。
如您所見,我們能夠將所有黃金 URL 分類為 270,000 行和 6 列。 黃金專用頁面數量眾多的主要原因是美元或歐元沒有單獨的類型,而黃金有單獨的類型。 同時,由於傳統上對土耳其人民的信任,黃金與不同貨幣之間的跨頁多樣性高於其他貨幣。
在我看來,所有類型的金頁都應該平均分配,對吧?
我們可以使用 Seaborn 的 Heatmap 功能輕鬆測試這一點。
將 seaborn 導入為 sns
將 matplotlib.pyplot 導入為 plt
plt.figure(figsize=(10,8))
sns.heatmap(a,yticklabels=False,cbar=False,cmap=”viridis”)
plt.show()
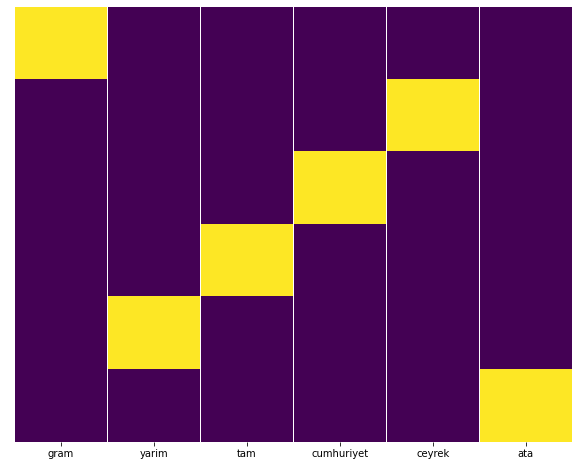
在熱圖上,每列中的真值都被簡單地標記了。 可以看出,每一個的大小都是相互對稱的,在地圖上排列整齊。
因此,我們對 Sabah.com.tr 報紙關於貨幣和貨幣計算的內容政策採取了廣泛的視角。
將來,我將根據 Elias Dabbas 推出的 Sitemaps Kaggle 編寫土耳其新聞網站及其內容策略,但在本文中,我們已經充分討論了使用站點地圖可以在大型和小型網站上發現什麼.
結論和要點
我想我們已經看到了理解一個網站是多麼容易,這要歸功於流暢和語義化的 URL 結構。 我們還應該記住正確的 URL 結構對 Google 的價值。
未來,我們會看到很多 SEO 越來越熟悉數據科學、數據可視化、前端編程等等……我認為這個過程是一個不可避免的變化的開始:SEO 和開發人員之間的差距將完全縮小幾年內。
使用 Python,您可以更進一步地進行這種分析:可以從了解新聞網站的政治觀點、誰寫什麼、多久寫一次以及懷著什麼樣的心情來獲取數據。 我不想在這裡討論這些,因為這些過程更多地是關於純數據科學而不是 SEO(這篇文章已經很長了)。
但是,如果您有興趣,可以通過站點地圖和 Python 執行許多其他類型的審核,例如檢查站點地圖中 URL 的狀態代碼。
我期待著嘗試和分享您可以使用 Python 和 Advertools 完成的其他 SEO 任務。