
理解人工智慧:我們如何教授電腦自然語言
已發表: 2023-11-28自 1950 年代以來,「人工智慧」一詞就一直與電腦相關,但直到去年,大多數人可能仍認為人工智慧仍然更科幻,而不是技術現實。
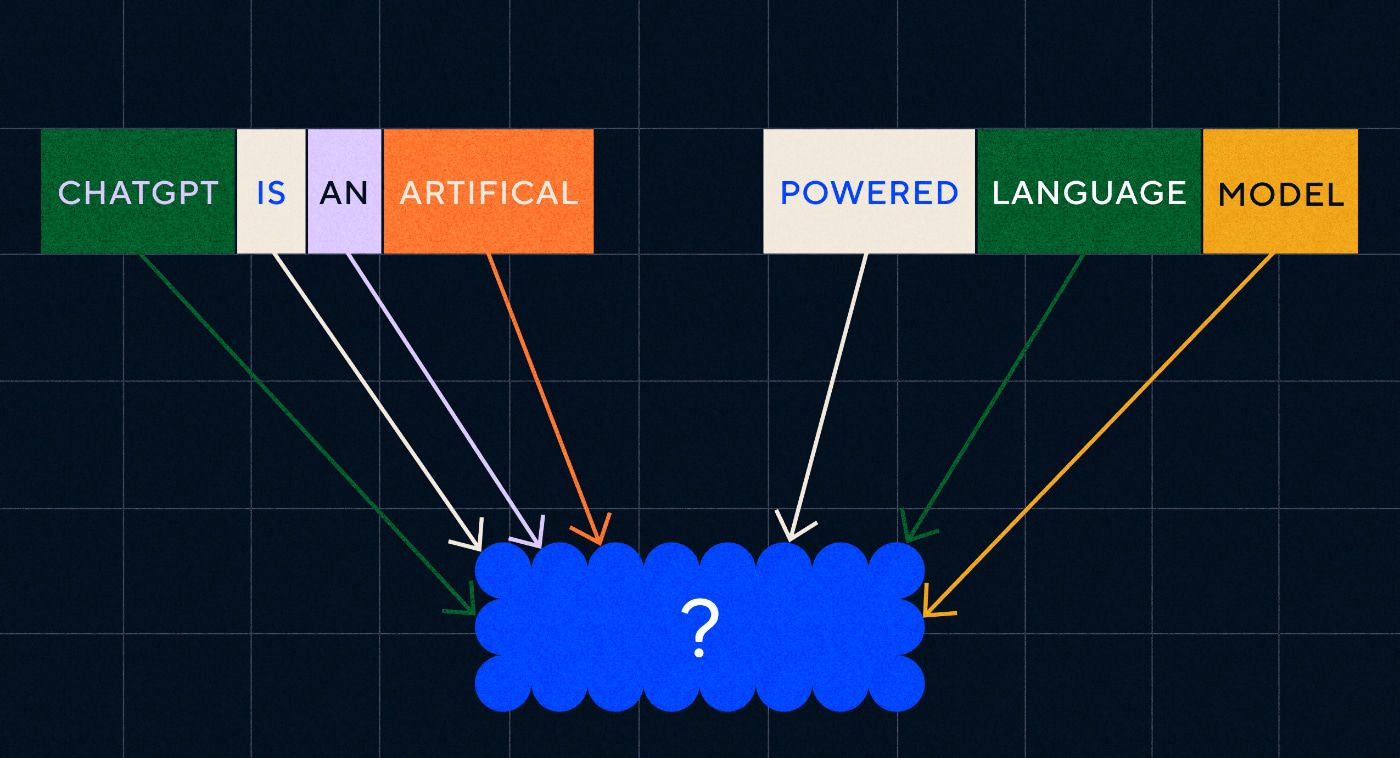
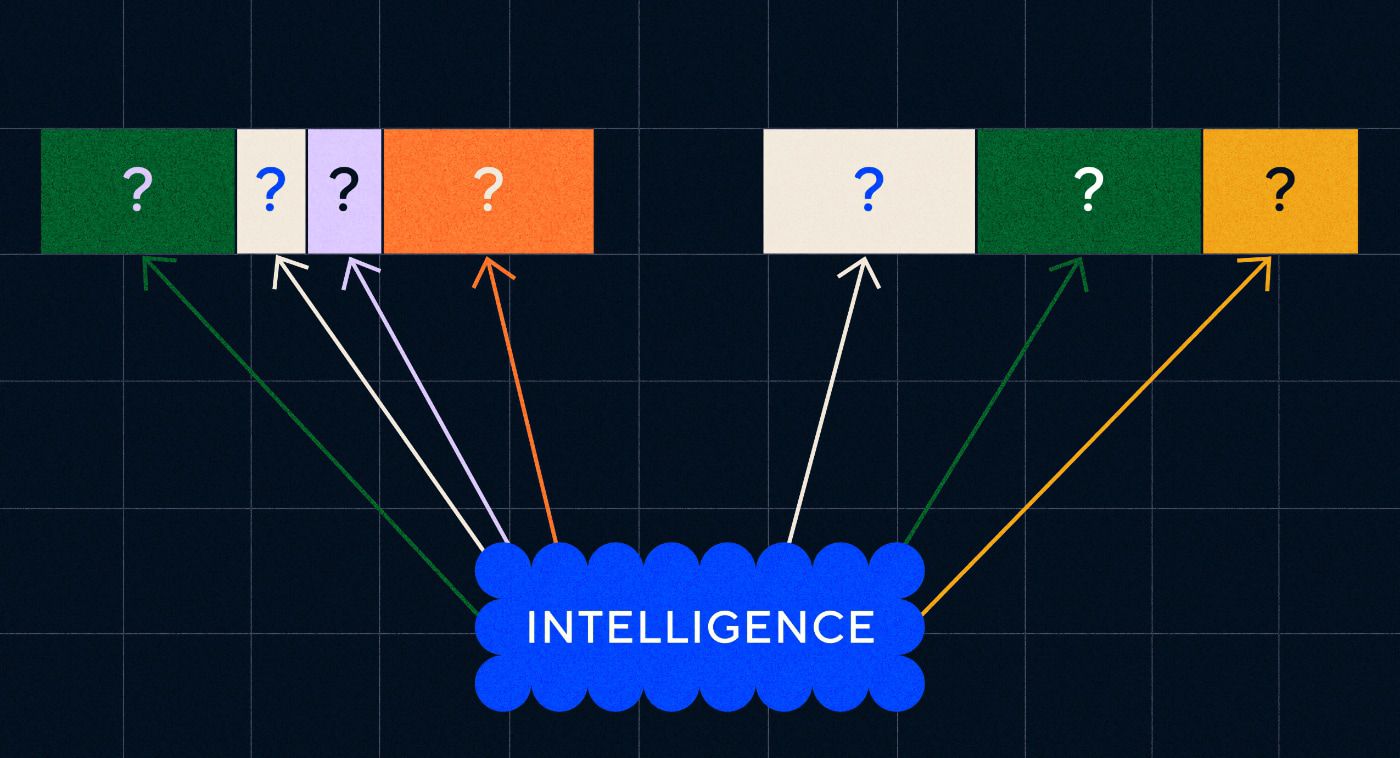
OpenAI 的 ChatGPT 於 2022 年 11 月問世,突然改變了人們對機器學習能力的看法 - 但 ChatGPT 到底是什麼讓世界刮目相看並意識到人工智慧已經大有作為?
簡而言之,語言——ChatGPT 之所以讓人感覺如此顯著的飛躍,是因為它在自然語言方面表現得非常流利,這是聊天機器人從未有過的。
這標誌著「自然語言處理」(NLP)的顯著新階段,即電腦解釋自然語言並輸出令人信服的回應的能力。 ChatGPT 建立在「大型語言模型」(LLM)之上,這是一種使用深度學習的神經網絡,在海量資料集上進行訓練,可以處理和生成內容。
“電腦程式是如何實現如此流暢的語言的?”
但我們是怎麼到這裡的呢? 電腦程式如何實現如此流暢的語言? 怎麼聽起來如此人性化?
ChatGPT 並不是憑空產生的——它建立在近幾十年來無數不同的創新和發現的基礎上。 ChatGPT 的一系列突破都是電腦科學的里程碑,但可以將它們視為模仿人類習得語言的階段。
我們如何學習語言?
為了理解人工智慧是如何達到這個階段的,有必要考慮語言學習本身的本質——我們從單字開始,然後開始將它們組合成更長的序列,直到我們能夠交流複雜的概念、想法和指令。
例如,兒童語言習得的一些常見階段是:
- 全語階段:9-18 個月期間,孩子學會使用單字來描述他們的基本需求或願望。 使用單字進行溝通意味著強調清晰度而不是概念完整性。 如果孩子餓了,他們不會說“我想要一些食物”或“我餓了”,而是簡單地說“食物”或“牛奶”。
- 兩個單字階段:在 18-24 個月大的時候,孩子開始使用簡單的兩個單字分組來增強他們的溝通技巧。 現在,他們可以用「更多食物」或「閱讀」等表達方式來表達自己的感受和需求。
- 電報階段:24-30 個月期間,兒童開始將多個單字串在一起形成更複雜的片語和句子。 使用的單字數量仍然很少,但正確的單字順序和更多的複雜性開始出現。 孩子開始學習基本的句子結構,例如「我想給媽媽看」。
- 多單字階段:30個月後,孩子開始過渡到多單字階段。 在這個階段,孩子開始使用語法更正確、複雜和多從句的句子。 這是語言習得的最後階段,孩子們最終會用複雜的句子進行交流,例如「如果下雨,我想留在家裡玩遊戲」。
語言習得的第一個關鍵階段之一是以非常簡單的方式開始使用單字的能力。 因此,人工智慧研究人員需要克服的第一個障礙是如何訓練模型來學習簡單的單字關聯。
模型 1 – 使用 Word2Vec 學習單字(論文 1 和論文 2)
Word2Vec 是嘗試以這種方式學習單字關聯的早期神經網路模型之一,由 Tomaš Mikolov 和 Google 的一組研究人員開發。 2013年發表了兩篇論文(可見這個領域發展得有多快。)
這些模型是透過學習將常用的單字關聯起來來訓練的。 這種方法建立在約翰·R·弗斯 (John R. Firth) 等早期語言學先驅的直覺之上,他指出意義可以從單詞聯想中得出:“你應該通過單詞的陪伴來認識它。”
這個想法是,具有相似語義的單字往往更頻繁地一起出現。 「貓」和「狗」這兩個詞通常比它們與「蘋果」或「電腦」等詞一起出現的頻率更高。 換句話說,「貓」這個字與「狗」這個字應該比「貓」與「蘋果」或「電腦」更相似。
Word2Vec 的有趣之處在於它是如何訓練來學習這些單字關聯的:
- 猜測目標單字:模型被給予固定數量的單字作為輸入,但目標單字缺失,並且它必須猜測缺失的目標單字。 這稱為連續詞袋(CBOW)。
- 猜測周圍的單字:模型被給予一個單詞,然後負責猜測周圍的單字。 這稱為 Skip-Gram,與 CBOW 的方法相反,我們預測周圍的單字。
這些方法的一個優點是,您不需要任何標記數據來訓練模型 - 標記數據,例如將文本描述為“積極”或“消極”來教授情緒分析,畢竟是一項緩慢而費力的工作。
Word2Vec 最令人驚訝的事情之一是它透過相對簡單的訓練方法捕捉了複雜的語義關係。 Word2Vec 輸出表示輸入單字的向量。 透過對這些向量進行數學運算,作者能夠證明詞向量不僅捕獲語法上相似的元素,而且還捕獲複雜的語義關係。
這些關係與詞語的使用方式有關。 作者提到的例子是「King」和「Queen」以及「Man」和「Woman」等字眼之間的關係。
雖然這是向前邁出的一步,但 Word2Vec 也有限制。 它的每個單字只有一個定義——例如,我們都知道「bank」可能有不同的含義,這取決於你是打算持有一個還是從其中釣魚。 Word2Vec 不在乎,它只是對「銀行」一詞有一個定義,並且會在所有上下文中使用它。
最重要的是,Word2Vec 無法處理指令甚至句子。 它只能將一個單字作為輸入,並輸出一個「單字嵌入」或向量表示,這是它為該單字學習的。 為了建立在這個單字的基礎上,研究人員需要找到一種方法將兩個或多個單字按順序串在一起。 我們可以將其想像為類似語言習得的兩個單字階段。
模型 2 – 使用 RNN 和文字序列學習單字序列
一旦孩子開始掌握單字的用法,他們就會嘗試將單字組合在一起來表達更複雜的想法和感受。 同樣,NLP 發展的下一步是發展處理單字序列的能力。 處理文字序列的問題是它們沒有固定的長度。 句子的長度可以從幾個單字到很長的一段不等。 並非所有序列對於整體意義和上下文都很重要。 但我們需要能夠處理整個序列,以了解哪些部分最相關。
這就是循環神經網路(RNN)出現的地方。
RNN 於 20 世紀 90 年代開發,其工作原理是在循環中處理其輸入,其中先前步驟的輸出在迭代序列中的每個步驟時透過網路進行。
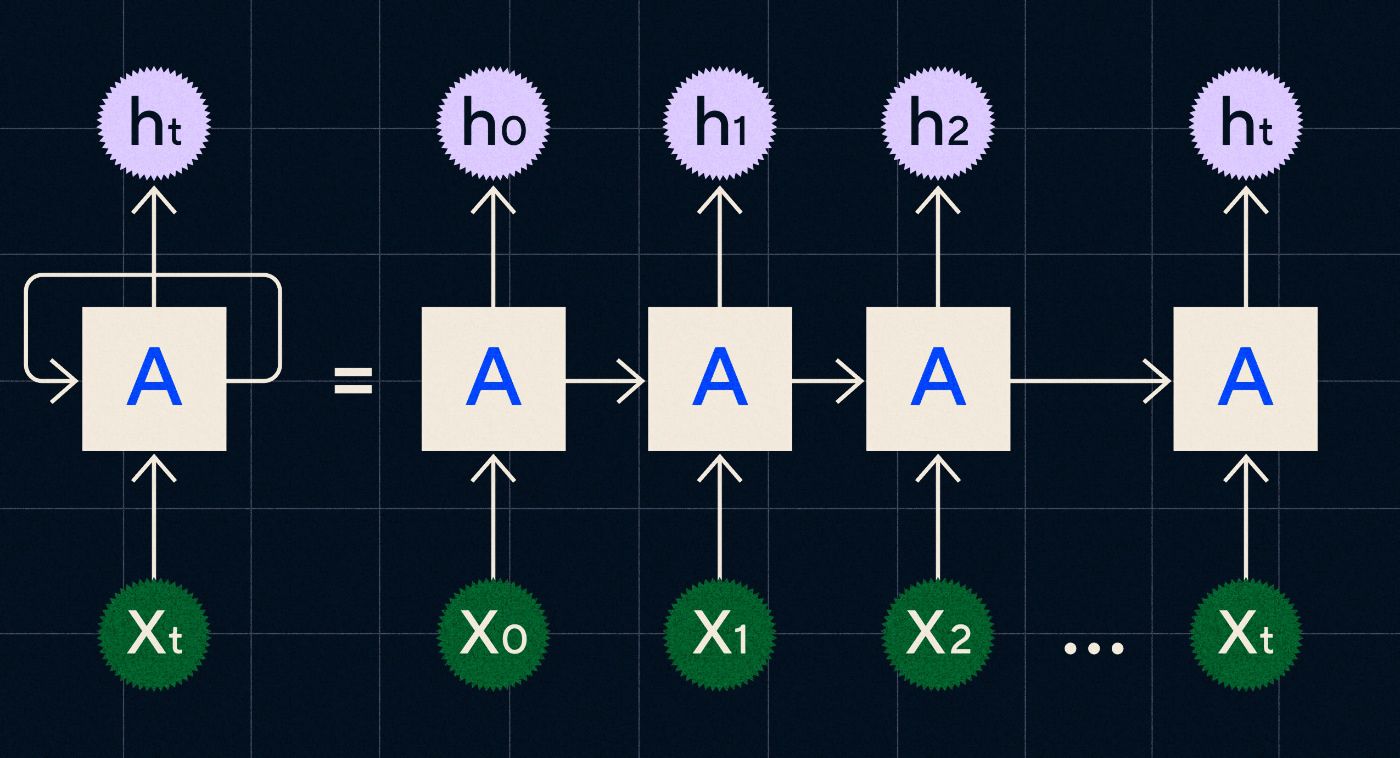
資料來源:Christopher Olah 關於 RNN 的部落格文章
上圖顯示如何將 RNN 描繪為一系列神經網路 (A),其中上一個步驟的輸出 (h0、h1、h2…ht) 被帶入下一步。 在每個步驟中,網路也會處理新的輸入(X0、X1、X2 … Xt)。
RNN(特別是長短期記憶網絡,即 LSTM,Sepp Hochreiter 和 Jurgen Schmidhuber 在 1997 年引入的一種特殊類型的 RNN)使我們能夠創建可以執行更複雜任務(例如翻譯)的神經網路架構。
2014年,Google的Ilya Sutskever(OpenAI聯合創始人)、Oriol Vinyals和Quoc V Le發表了一篇論文,描述了序列到序列(Seq2Seq)模型。 本文展示如何訓練神經網路來取得輸入文字並傳回該文字的翻譯。 您可以將其視為生成神經網路的早期範例,您給它一個提示,它會傳回一個回應。 然而,任務是固定的,所以如果它接受了翻譯訓練,你就不能「提示」它做任何其他事情。
請記住,先前的模型 Word2Vec 只能處理單字。 因此,如果你向它傳遞一個像「牙醫拔掉我的牙齒」這樣的句子,它只會為每個單字產生一個向量,就好像它們不相關一樣。
然而,順序和上下文對於翻譯等任務很重要。 您不能只翻譯單字,您需要解析單字序列,然後輸出結果。 這就是 RNN 使 Seq2Seq 模型能夠以這種方式處理單字的地方。
Seq2Seq 模型的關鍵是神經網路設計,它使用兩個背對背的 RNN。 一個是編碼器,它將文字輸入轉換為嵌入,另一個是解碼器,它將編碼器輸出的嵌入作為輸入:
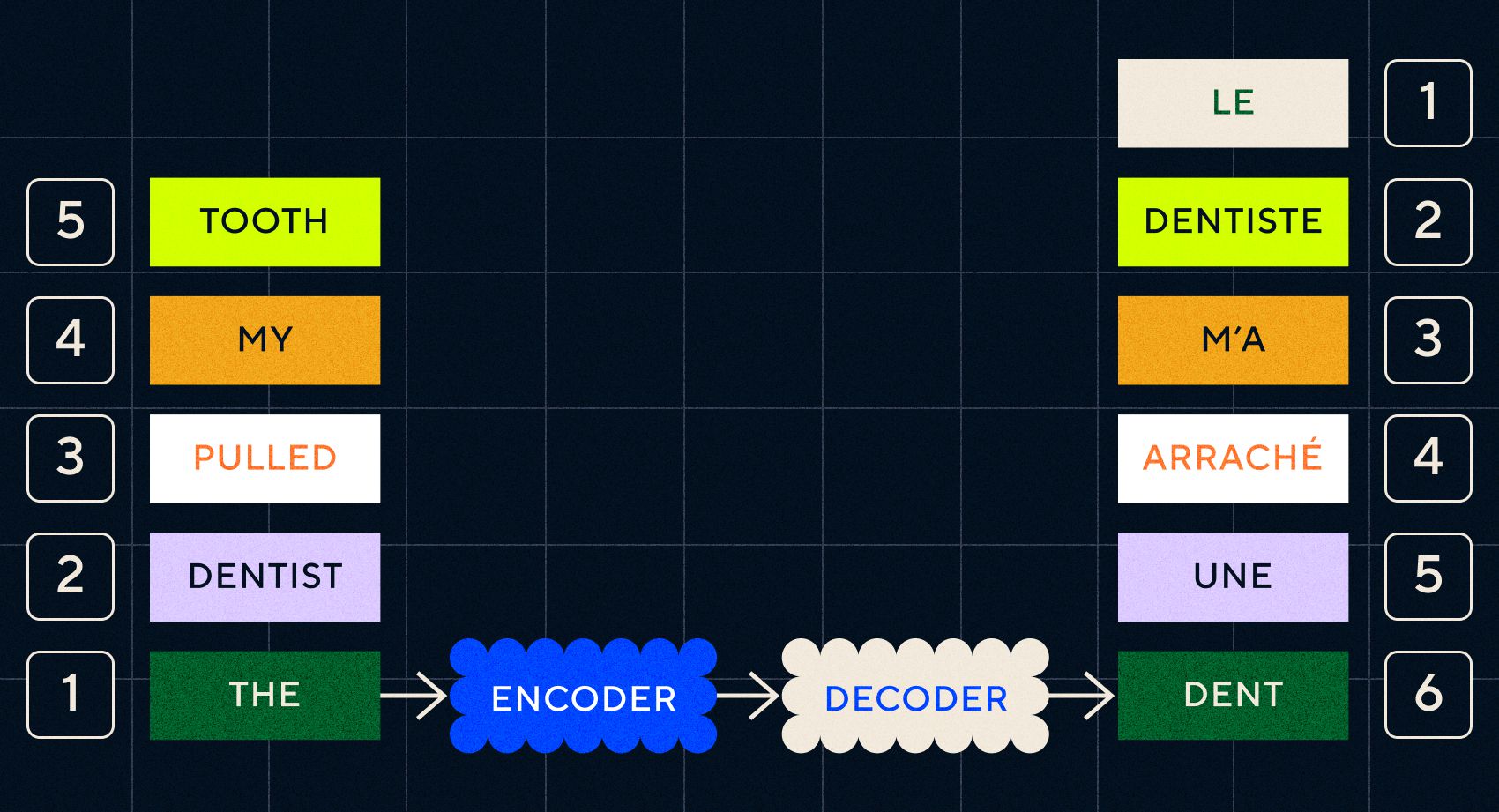
一旦編碼器處理完每個步驟中的輸入,它就會開始將輸出傳遞給解碼器,解碼器將嵌入轉換為翻譯後的文字。
我們可以看到,隨著這些模型的演變,它們開始以某種簡單的形式類似於我們今天在 ChatGPT 中看到的模型。 然而,我們也可以看到相較之下這些模型有多有限。 就像我們自己的語言發展一樣,要真正提高語言能力,我們需要確切地知道要注意什麼,以便創建更複雜的短語和句子。
模型 3 – 透過注意力學習並使用 Transformer 進行擴展
我們之前註意到,電報階段是孩子們開始用兩個或更多單字創建短句的階段。 這個語言習得階段的一個關鍵方面是孩子開始學習如何建構正確的句子。
RNN 和 Seq2Seq 模型可幫助語言模型處理多個單字序列,但它們可以處理的句子長度仍然有限。 隨著句子長度的增加,我們需要注意句子中的大部分內容。
例如,採用以下句子「房間裡氣氛太緊張,你可以用刀割它」。 那裡發生了很多事情。 要知道我們在這裡並不是真的用刀切割某物,我們需要在句子前面將「切割」與「張力」聯繫起來。
隨著句子長度的增加,要知道哪些單字指的是哪個單字以推斷正確的意思變得更加困難。 這就是 RNN 開始遇到限制的地方,我們需要一個新模型來進入語言習得的下一個階段。
「想像一下,當一段對話變得越來越長時,試著用固定的字數來總結它。 每走一步,你都會開始失去越來越多的信息”
2017 年,Google的一組研究人員發表了一篇論文,提出了一種技術,可以讓模型更好地專注於一段文本中的重要上下文。
他們開發的是一種讓語言模型在處理文字輸入序列時更輕鬆地找到所需上下文的方法。 他們將這種方法稱為“變壓器架構”,它代表了迄今為止自然語言處理領域的最大飛躍。
這種查找機制使模型更容易識別先前的哪些單字為目前正在處理的單字提供了更多上下文。 RNN 嘗試透過傳遞每個步驟已處理過的所有單字的聚合狀態來提供上下文。 想像一下,當對話變得越來越長時,試著用固定的字數限制來總結對話。 每走一步,你就會開始失去越來越多的資訊。 相反,轉換器根據單字(或標記,不是整個單字而是單字的一部分)對當前單字在上下文中的重要性進行加權。 這使得處理越來越長的單字序列變得更加容易,而不會出現 RNN 中出現的瓶頸。 這種新的注意力機制還允許並行處理文本,而不是像 RNN 那樣順序處理。

因此,想像這樣的句子:「動物沒有過馬路,因為它太累了」。 對於 RNN,它需要在每一步表示所有先前的單字。 隨著「it」和「animal」之間的單字數量增加,RNN 辨識正確的上下文變得更加困難。
借助 Transformer 架構,模型現在能夠找到最有可能指涉「it」的單字。 下圖顯示了 Transformer 模型在嘗試處理句子時如何能夠專注於文字的「動物」部分。
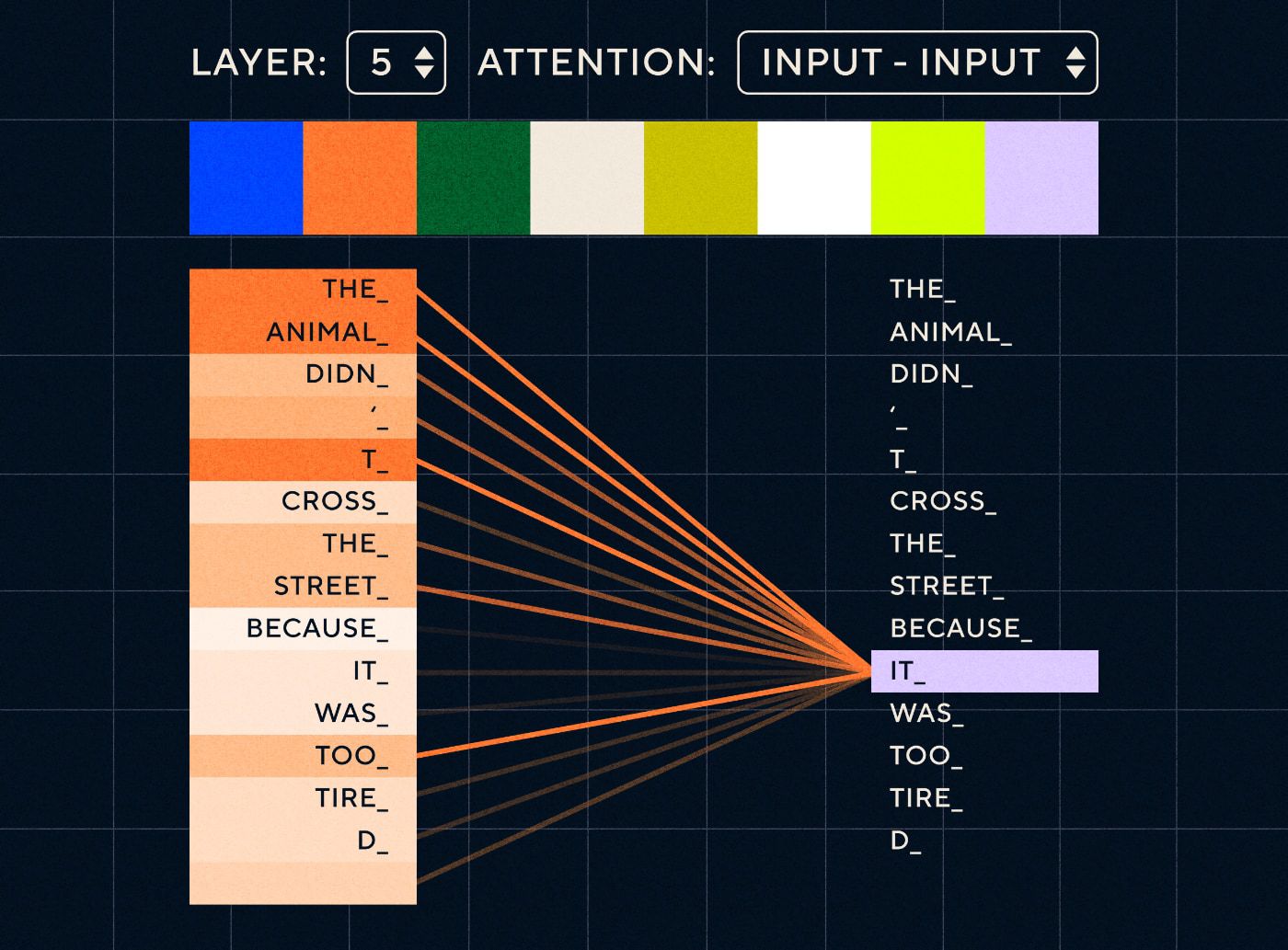
來源:《變形金剛圖解》
上圖顯示了網路第 5 層的注意力。 在每一層,模型都在建立對句子的理解,並「關注」輸入的特定部分,它認為該部分與當時正在處理的步驟更相關,即它更關注「動物」作為這一層中的「它」。 來源:圖解變壓器
把它想像成一個資料庫,它可以檢索得分最高的單詞,該單字最有可能與“it”相關。
隨著這種發展,語言模型不再局限於解析短文本序列。 相反,您可以使用更長的文字序列作為輸入。 我們知道,透過「參與式對話」讓孩子接觸更多單字有助於改善他們的語言發展。
同樣,透過新的注意力機制,語言模型能夠解析更多、更多樣化類型的文字訓練資料。 這包括維基百科文章、線上論壇、Twitter 以及您可以解析的任何其他文字資料。 與童年發展一樣,接觸所有這些單字及其在不同上下文中的使用有助於語言模型發展新的、更複雜的語言能力。
正是在這個階段,我們開始看到一場規模競賽,人們向這些模型投入越來越多的數據,看看他們能學到什麼。 這些數據不需要由人類標記——研究人員只需在互聯網上抓取數據並將其輸入模型,看看它學到了什麼。
「像 BERT 這樣的模型打破了所有可用的自然語言處理記錄。 事實上,用於這些任務的測試資料集對於這些變壓器模型來說太簡單了”
出於幾個原因,BERT(來自 Transformers 的雙向編碼器表示)模型值得特別提及。 它是最早利用作為 Transformer 架構核心的注意力特徵的模型之一。 首先,BERT 是雙向的,因為它可以查看目前輸入左側和右側的文字。 這與只能從左到右順序處理文字的 RNN 不同。 其次,BERT也使用了一種名為「掩蔽」的新訓練技術,在某種程度上,透過「隱藏」或「掩蔽」隨機標記迫使模型學習不同輸入的含義,以確保模型無法「作弊」和在每次迭代中關注單一標記。 最後,BERT 可以進行微調以執行不同的 NLP 任務。 它不必從頭開始接受這些任務的訓練。
結果是驚人的。 像 BERT 這樣的模型打破了所有可用的自然語言處理記錄。 事實上,用於這些任務的測試資料集對於這些變壓器模型來說太簡單了。
現在我們有能力訓練大型語言模型,作為新的自然語言處理任務的基礎模型。 以前人們大多從頭開始訓練模型。 但現在像 BERT 和早期的 GPT 模型這樣的預訓練模型已經非常好了,你自己做就沒有意義了。 事實上,這些模型非常好,人們發現它們可以用相對較少的示例執行新任務 - 它們被描述為“少樣本學習者”,類似於大多數人不需要太多示例來掌握新概念。
這是這些模型及其語言能力發展的一個巨大轉折點。 現在我們只需要更好地製作說明。
模型 4 – 使用 InstructGPT 學習指令
兒童在語言習得的最後階段(多詞階段)學到的東西之一是使用功能詞連接句子中攜帶訊息的元素的能力。 功能詞告訴我們句子中不同單字之間的關係。 如果我們想要建立指令,那麼語言模型將需要能夠建立包含捕捉複雜關係的實詞和虛詞的句子。 例如,以下指令的功能詞以粗體突出顯示:
- “我想讓你寫一封信…”
- “告訴我你對上述文字的看法”
但在我們嘗試訓練語言模型遵循指令之前,我們需要確切了解它們已經了解的指令內容。
OpenAI 的 GPT-3 於 2020 年發布。這讓我們得以一睹這些模型的能力,但我們仍然需要了解如何解鎖這些模型的底層功能。 我們如何與這些模型互動以使它們執行不同的任務?
例如,GPT-3 表明,增加模型大小和訓練資料可以實現作者所說的「元學習」——這就是語言模型開發廣泛的語言能力的地方,其中許多能力是意想不到的,並且可以使用這些能力理解給定任務的技能。
「模型是否能夠理解指令中的意圖並執行任務,而不僅僅是簡單地預測下一個單字?”
請記住,GPT-3 和早期的語言模型並不是為了培養這些技能而設計的——它們主要被訓練來預測文本序列中的下一個單字。 但是,透過 RNN、Seq2Seq 和注意力網絡的進步,這些模型能夠處理更長序列中的更多文本,並更好地關注相關上下文。
您可以將 GPT-3 視為一項測試,看看我們能走多遠。 我們可以製作多大的模型以及可以提供多少文本? 然後,完成此操作後,我們可以使用輸入文字作為指令,而不是僅僅向模型提供一些輸入文字來完成。 該模型是否能夠理解指令中的意圖並執行任務,而不僅僅是簡單地預測下一個單字? 在某種程度上,這就像試圖了解這些模型已經達到了語言習得的哪個階段。
我們現在將其描述為“提示”,但在 2020 年,即論文發表時,這是一個非常新的概念。
幻覺和對齊
正如我們現在所知,GPT-3 的問題在於它不能很好地遵循輸入文字中的指令。 GPT-3可以遵循指令,但很容易失去注意力,只能理解簡單的指令,並且容易胡編亂造。 換句話說,這些模型與我們的意圖並不「一致」。 所以現在的問題不在於提升模型的語言能力,而是他們遵循指令的能力。
值得注意的是,GPT-3 從未真正接受過指令訓練。 沒有人告訴它指令是什麼,或者它與其他文本有何不同,或者它應該如何遵循指令。 在某種程度上,它透過像其他文字序列一樣「完成」提示來「欺騙」它遵循指令。 因此,OpenAI 需要訓練一個能夠像人類一樣更好地遵循指令的模型。 他們在 2022 年初發表的一篇題為「訓練語言模型以遵循人類反饋指令」的論文中做到了這一點。同年晚些時候,InstructGPT 將被證明是 ChatGPT 的前身。
該論文中概述的步驟也用於訓練 ChatGPT。 指導訓練遵循 3 個主要步驟:
- 步驟 1 – 微調 GPT-3:由於 GPT-3 似乎在少樣本學習方面表現得很好,因此我們的想法是,如果在高品質的教學範例上對其進行微調會更好。 目標是更容易將指令中的意圖與產生的反應保持一致。 為了做到這一點,OpenAI 讓人類貼標者對使用 GPT-3 的人提交的一些提示做出回應。 作者希望透過使用真實的指令來捕捉使用者試圖讓 GPT-3 執行的任務的真實「分佈」。這些指令用於微調 GPT-3,以幫助其提高即時回應能力。
- 步驟 2 – 讓人們對新的和改進的 GPT-3 進行排名:為了評估經過微調的新指令 GPT-3,貼標籤者現在在沒有預定義響應的情況下對不同提示下的模型性能進行評級。 此排名與重要的一致性因素相關,例如有幫助、誠實、無毒、有偏見或有害。 因此,給模型一個任務,並根據這些指標評估其性能。 然後,使用此排名練習的輸出來訓練一個單獨的模型,以預測貼標者可能會喜歡哪些輸出。 此模型稱為獎勵模型(RM)。
- 步驟 3 – 使用 RM 訓練更多範例:最後,RM 用於訓練新的指令模型,以更好地產生符合人類偏好的回應。
要完全理解人類回饋強化學習 (RLHF)、獎勵模型、策略更新等方面的情況是很棘手的。
一種簡單的思考方式是,它只是一種使人類能夠產生如何遵循指令的更好範例的方法。 例如,想像一下您將如何嘗試教孩子說謝謝:
- 家長:「當有人給你X時,你說謝謝」。 這是第 1 步,提示和適當回應的範例資料集
- 家長:「現在,你對 Y 說什麼?」。 這是第 2 步,我們要求孩子做出回應,然後家長對此進行評分。 “是的,那很棒。”
- 最後,在隨後的遭遇中,父母會根據未來類似場景中反應的好或壞例子來獎勵孩子。 這是第 3 步,即發生強化行為。
就 OpenAI 而言,它所做的只是解鎖 GPT-3 等模型中已經存在的功能,“但僅通過即時工程很難獲得”,正如論文所述。
換句話說,ChatGPT 並不是真正學習「新」功能,而只是學習更好的語言「介面」來利用它們。
語言的魔力
ChatGPT 感覺像是一次神奇的飛躍,但它實際上是數十年來艱苦技術進步的結果。
透過回顧近十年來人工智慧和自然語言處理領域的一些重大發展,我們可以看到ChatGPT是如何「站在巨人的肩膀上」的。 早期的模型首先學會辨識單字的意思。 然後後續模型將這些單字組合在一起,我們可以訓練它們執行翻譯等任務。 一旦他們能夠處理句子,我們就開發了一些技術,使這些語言模型能夠處理越來越多的文本,並培養將這些學習應用到新的和不可預見的任務的能力。 然後,透過 ChatGPT,我們最終開發了透過以自然語言格式指定指令來更好地與這些模型互動的能力。
“由於語言是我們思想的載體,那麼教授電腦語言的全部力量會帶來獨立的人工智慧嗎?”
然而,NLP 的發展確實揭示了我們通常忽視的更深層的魔力——語言本身的魔力以及我們作為人類如何獲得它的魔力。
關於兒童最初如何學習語言仍然存在許多懸而未決的問題和爭議。 還有一個問題是所有語言是否都有一個共同的底層結構。 人類是進化到使用語言的還是相反?
奇怪的是,隨著 ChatGPT 及其後代改善其語言發展,這些模型可能有助於回答其中一些重要問題。
最後,由於語言是我們思想的載體,教授電腦語言的全部力量會導致獨立的人工智慧嗎? 和生活中一樣,還有很多東西要學習。
