
使用 Wikipedia 和 Google Language API 破解主題圖
已發表: 2019-08-27過去十年中我最喜歡的幻燈片之一是 Mark Johnstone 在 2014 年完成的,當時他還在 Distilled 工作。 該套牌被稱為“如何製作更好的內容創意”,幾年來我一直將其用作我的聖經,同時組建團隊來進行內容推廣的艱苦工作。
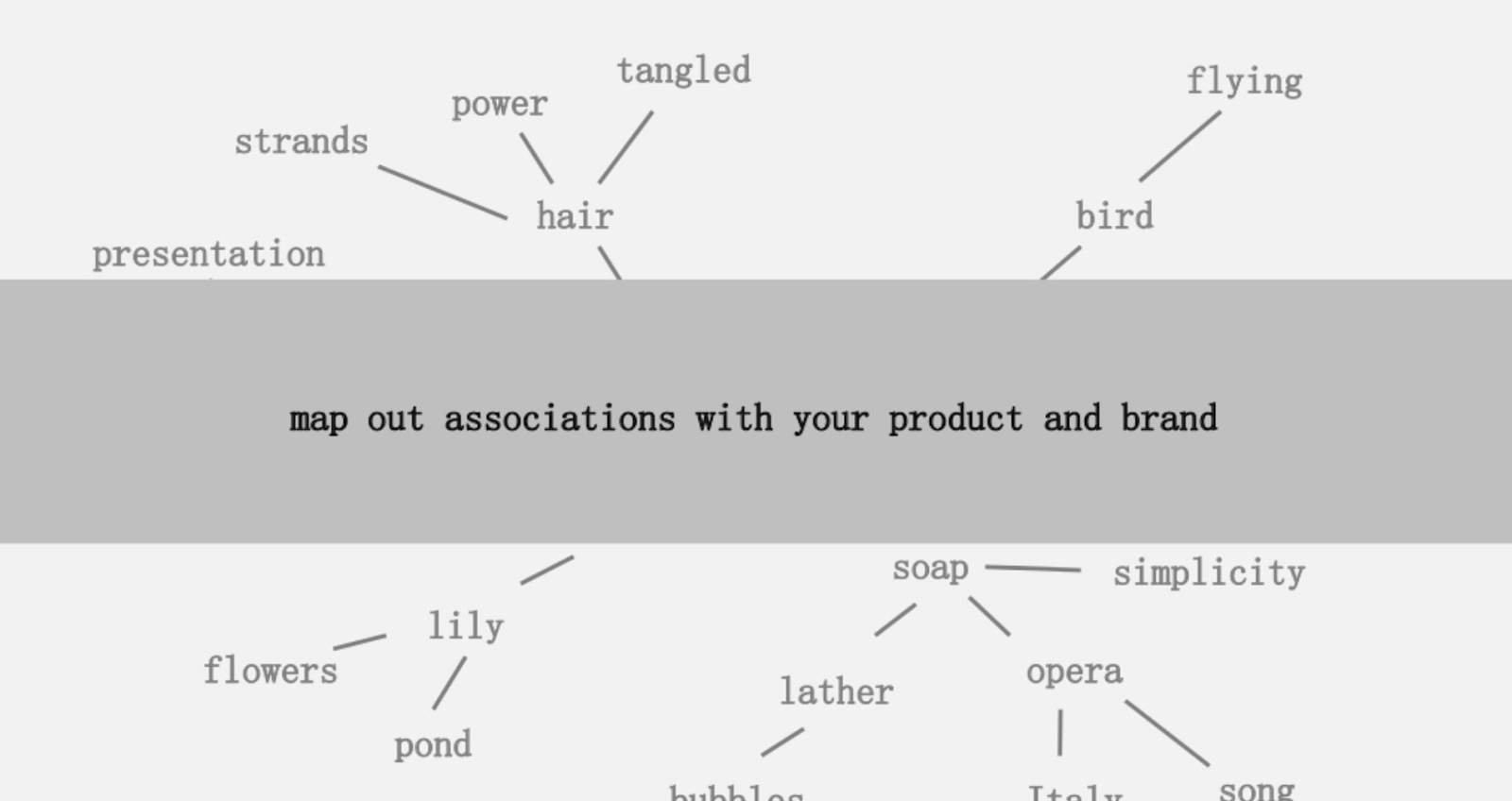
提供的想法之一是創建與您的產品或品牌相關聯的單詞的視覺映射,以便您可以退後一步,尋找將關聯組合成有趣的方法。 目標是產生想法,他將其定義為“以增加價值的方式將以前未連接的元素組合在一起”。
在本文中,我們採用一種更左腦的方法,通過使用 Python、Google 的語言 API 以及 Wikipedia 來探索種子主題中存在的實體關聯。 目標是沿著主題圖對實體關係進行高級視圖。 這篇文章不適合普通讀者。 熟悉 Python 並至少具有基本編碼能力的讀者會發現它更有啟發性。
理念
按照 Mark Johnstone 的映射想法,我認為讓 Google 和 Wikipedia 從種子主題或網頁開始定義主題結構會很有趣。 目標是在樹狀圖中以可視方式構建與主要主題的關係映射,可以查看該圖以尋找聯繫並可能產生內容創意。 下圖代表了最初的設計理念。
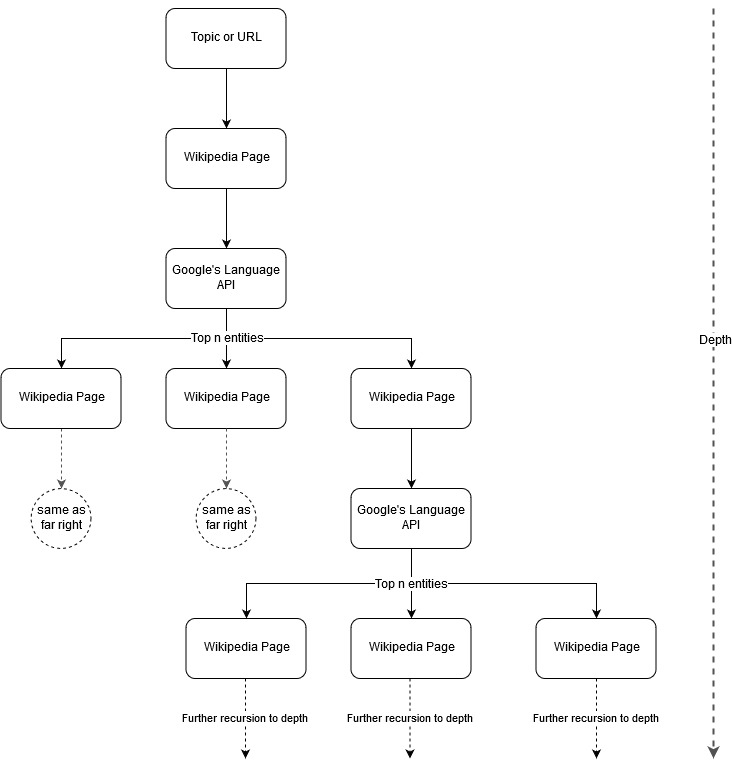
本質上,我們為工具提供了一個主題或 URL,並讓 Google 的語言 API 為每個實體頁面選擇前 n 個(在我們的示例中為 3 個)實體(包括 Wikipedia URL),然後我們遞歸地為每個找到的實體構建一個網絡圖達到最大深度。
使用工具的背景
谷歌語言 API
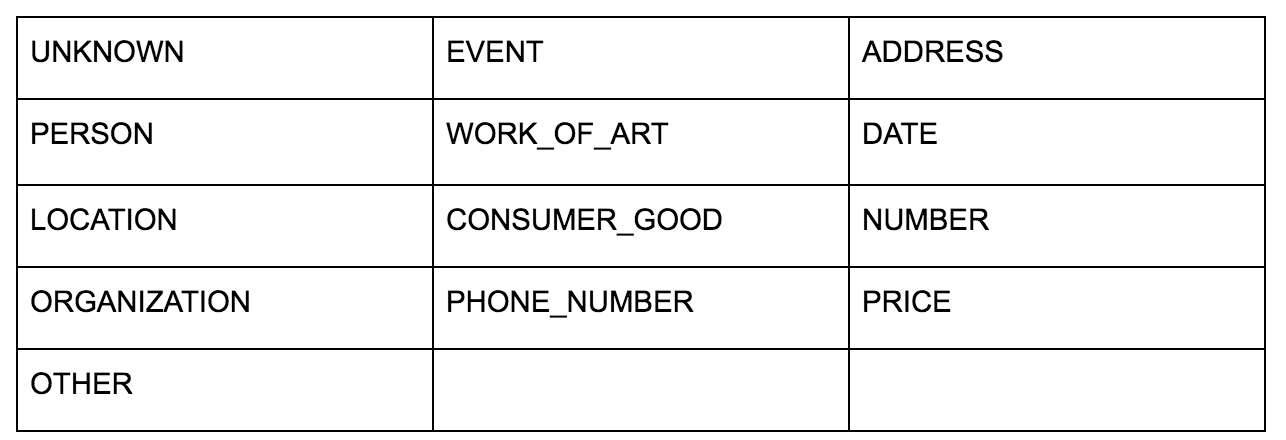
Google 的語言 API 允許您將純文本或 HTML 傳遞給它,它會神奇地返回與內容相關的所有各種實體。 API 做的遠不止這些,但是對於這個分析,我們將只關注這部分。 以下是它返回的實體類型列表:
長期以來,實體識別一直是自然語言處理 (NLP) 的基本部分,該任務的正確術語是命名實體識別 (NER)。 NER 是一項艱鉅的任務,因為許多單詞根據使用的上下文具有不同的含義,因此 NLP 工具或 API 必須了解術語周圍的完整上下文,才能正確地將它們識別為特定實體。
如果您想在完成本文之前了解一些上下文,我在 opensource.com 上的一篇文章中給出了這個 API 的非常詳細的概述,特別是實體。
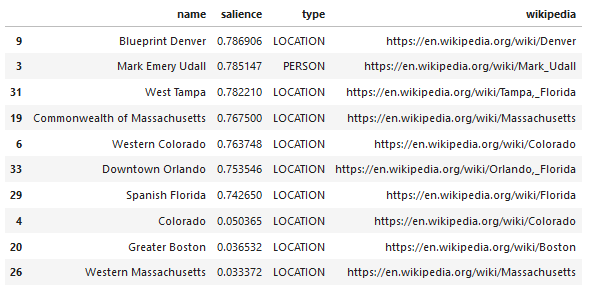
Google 語言 API 的一個有趣功能是,除了查找相關實體之外,它還標記它們與整個文檔(顯著性)的相關程度,並且對於某些人來說,它提供了代表實體的相關 Wikipedia(知識圖)文章。
以下是 API 返回的示例輸出(按顯著性排序):
爬蟲開發者
 學到更多
學到更多Python
Python 是一種在數據科學領域變得流行的軟件語言,因為它擁有龐大且不斷增長的庫集,可以輕鬆地攝取、清理、操作和分析大型數據集。 它還受益於一個名為 Jupyter notebooks 的協作環境,它允許用戶輕鬆地測試和註釋他們的代碼。
在本次審查中,我們將使用一些關鍵庫,這將使我們能夠使用 Google 的 NLP 數據做一些有趣的事情。
- Pandas:想像一下能夠編寫 Microsoft Excel 腳本來讀取、保存、解析或重新排列電子表格,您就會了解 Pandas 的功能。 熊貓很棒。 (關聯)
- Networkx: Networkx 是一種工具,用於構建定義節點之間關係的節點和邊圖。 它還具有對繪製圖形的內置支持,因此它們易於可視化。 (關聯)
- Pywikibot: Pywikibot 是一個庫,允許您與 Wikipedia 交互以搜索、編輯、查找關係等,其中包含每個 Wikipedia 站點的所有內容。 (關聯)
過程
我們在這里共享一個 Google Colab 筆記本,可用於跟進。 (特別感謝 Tyler Reardon 對文章和本筆記本進行了全面檢查。)
配置
筆記本中的前幾個單元處理安裝一些庫,使這些庫可用於 Python,並分別為 Google 的語言 API 和 Pywikibot 提供憑據和配置文件。 以下是我們需要安裝以確保該工具可以運行的所有庫:
- 熊貓
- 要求
- httplib2
- 谷歌云語言
- pywikibot
- 網絡x
- 驗證者
- BS4
注意:能夠運行此筆記本最困難的部分是從 Google 獲取憑據以訪問其 API。 對於那些沒有這方面經驗的人,這需要一個小時左右才能弄清楚。 我們在筆記本頂部鏈接了獲取服務帳戶憑據的說明以幫助您。 以下是我們如何包含我們的示例。
致勝的功能
在“為 Google NLP 定義一些函數”指示的單元格中,我們開發了 8 個函數來處理查詢語言 API、與 Wikipedia 交互、提取網頁文本以及構建和繪製圖形等事務。 函數本質上是小的代碼單元,它們接收一些設置數據,做一些工作,並產生一些東西。 所有的函數都被註釋以告訴他們接受的變量,以及他們產生的東西。
測試 API
以下兩個單元格獲取一個 URL,從 URL 中提取文本,然後從 Google 的 Language API 中提取實體。 一個只提取具有 Wikipedia URL 的實體,另一個提取該頁面中的所有實體。

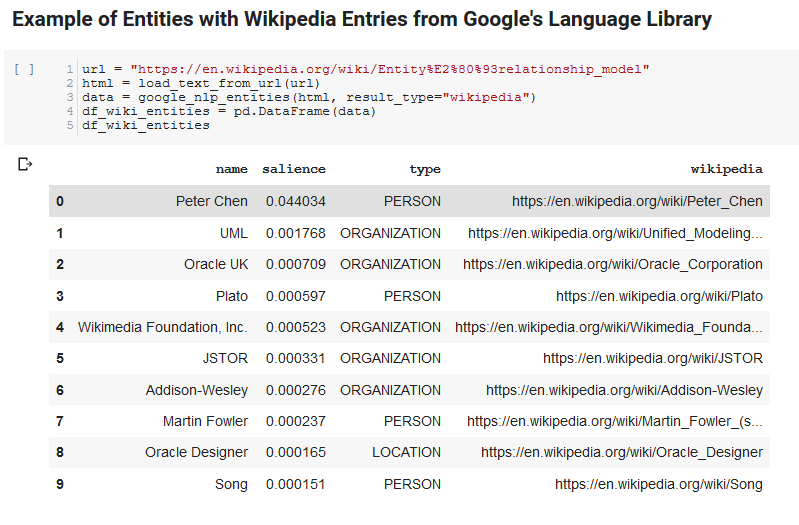
這是重要的第一步,只是為了使內容提取部分正確並了解語言 API 如何工作和返回數據。
網絡x
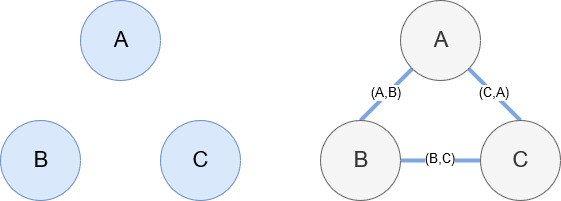
如前所述,Networkx 是一個很棒的庫,使用起來相當直觀。 本質上,您必須告訴它您的節點是什麼以及節點是如何連接的。 例如,在下圖中,我們給 Networkx 三個節點(A、B、C)。 然後我們告訴 Networkx 它們是由定義節點之間關係的邊 (A,B)、(B,C)、(C,A) 連接的。 對於我們的使用,具有 Wikipedia URL 的實體將是節點,而邊緣由在當前實體頁面上找到的新實體定義。 因此,如果我們正在查看實體 A 的 Wikipedia 頁面,並且在該頁面上發現了實體 B,那麼這就是實體 A 和實體 B 之間的邊緣。
把它們放在一起
筆記本的下一部分稱為Wikipedia Topic Branching by URL。 這就是魔法發生的地方。 我們之前已經定義了一個特殊的函數(recurse_entities),它通過谷歌語言 API 定義的新實體在 Wikipedia 上的頁面中遞歸。 我們還添加了一個非常難以理解的函數 (hierarchy_pos),它是從 Stack Overflow 中提取出來的,它很好地呈現了具有許多節點的樹狀圖。 在下面的單元格中,我們將輸入定義為“搜索引擎優化”,並指定深度為 3(這是它遞歸跟踪的頁面數)和限制為 3(這是它每頁拉出多少個實體)。
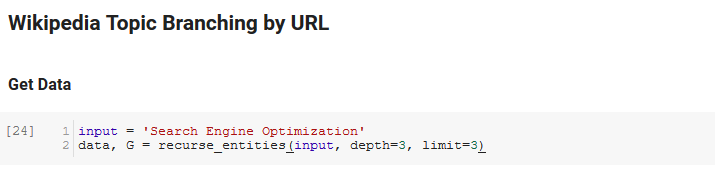
為“搜索引擎優化”一詞運行它,我們可以看到該工具採用的以下路徑,從維基百科的搜索引擎優化頁面(0 級)開始,遞歸地跟踪頁面直到指定的最大深度(3)。

然後我們獲取所有找到的實體並將它們添加到 Pandas DataFrame 中,這使得保存為 CSV 變得非常容易。 我們按顯著性(即實體對找到它的頁面的重要性)對這些數據進行排序,但這個分數在這種情況下有點誤導,因為它沒有告訴您實體與原始術語的相關程度(“搜索引擎優化”)。 我們將把進一步的工作留給讀者。

最後,我們繪製該工具構建的圖形以顯示所有實體的連通性。 在下面的單元格中,您可以傳遞給函數的參數是:( G :由 recurse_entities 函數預先構建的圖形, w:繪圖的寬度, h:繪圖的高度, c:圓形的百分比繪圖和文件名:保存到圖像文件夾的 PNG 文件。)

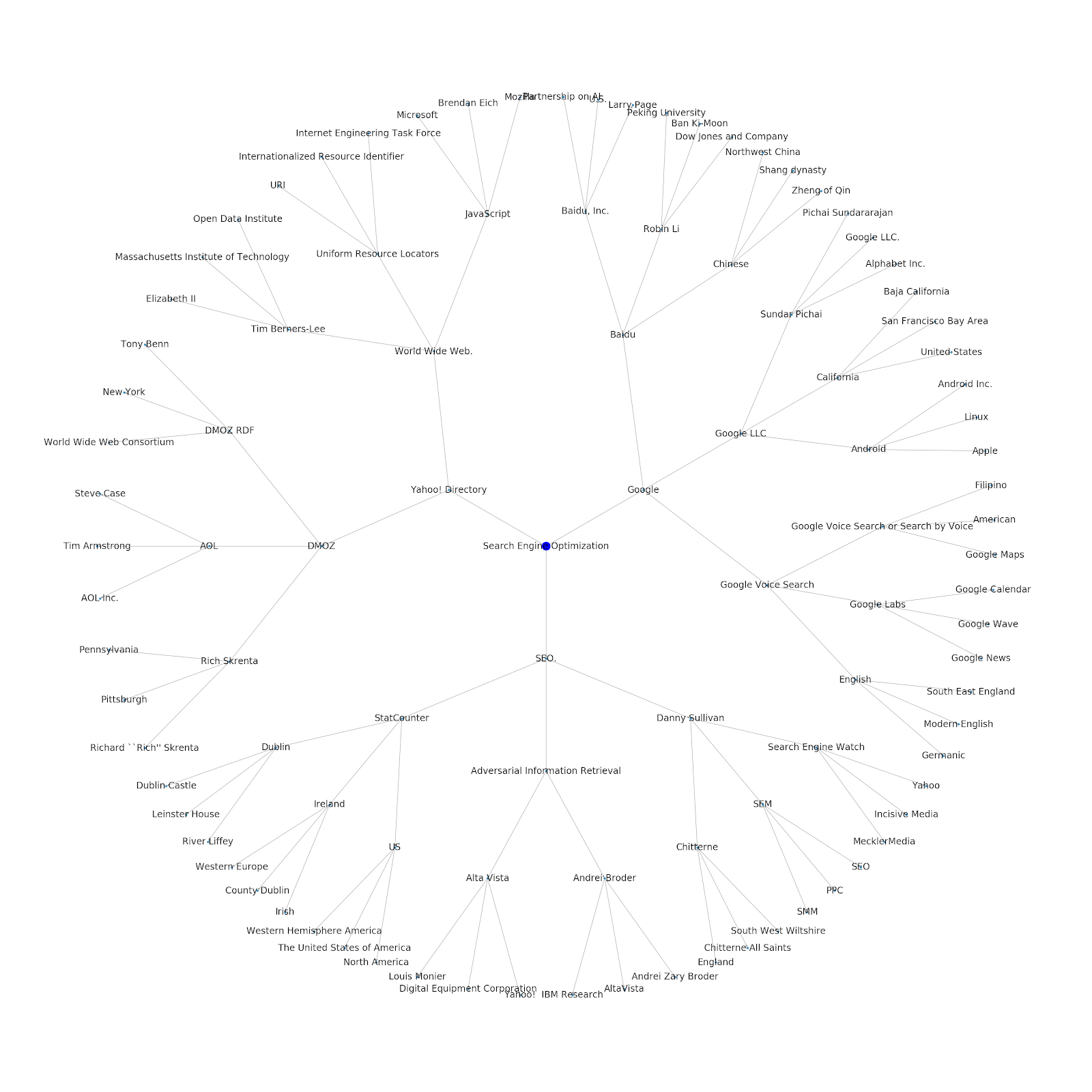
我們添加了為其提供種子主題或種子 URL 的功能。 在這種情況下,我們查看與 Google 的索引問題繼續但這篇不同的文章相關的實體
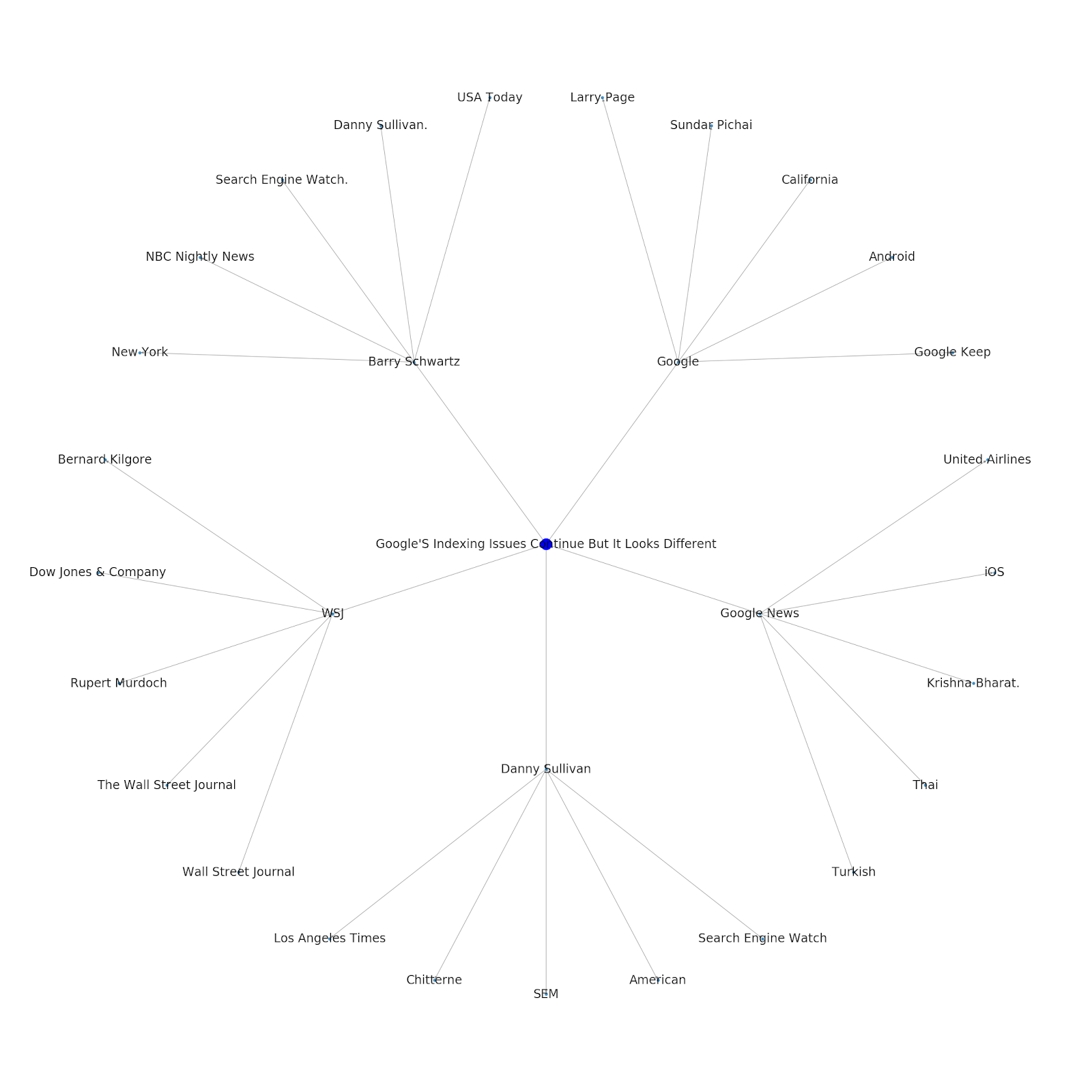
這是 Python 的 Google/Wikipedia 實體圖。
這意味著什麼
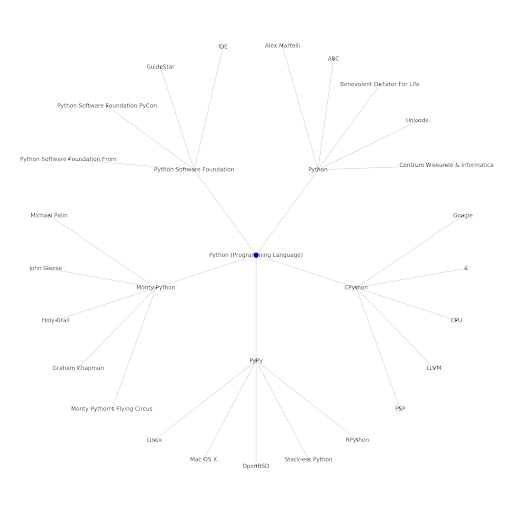
從 SEO 的角度來看,了解 Internet 的主題層很有趣,因為它迫使您考慮事物的連接方式,而不僅僅是單個查詢。 由於谷歌正在使用這一層將個人用戶的親和力與主題相匹配,正如他們在谷歌發現重新引入中提到的那樣,它可能成為以數據為中心的 SEO 的更重要的工作流程。 在上面的“Python”圖中,可以推斷出用戶對與種子主題相關的主題的熟悉程度可能是他們對種子主題的專業水平的合理衡量標準。
下面的示例顯示了兩個用戶,其中綠色突出顯示了他們對相關主題的歷史興趣或親和力。 左邊的用戶,了解 IDE 是什麼,了解 PyPy 和 CPython 的含義,將比知道它是一種語言的人更有經驗的 Python 用戶,但僅此而已。 對於每個用戶,這很容易轉化為每個主題的數字分數。

結論
我今天的目標是分享一個非常標準的過程,我使用 Jupyter Notebooks 測試和審查各種工具或 API 的有效性。 探索主題圖非常有趣,我們希望您發現共享的工具可以為您提供開始自己探索所需的良好開端。 使用這些工具,您可以構建探索許多關係級別的主題圖,僅限於 Google 語言 API 的配額範圍(每天 800,000 個)。 (更新:定價基於發送到 API 的 1,000 個 unicode 字符的單位,最多可免費使用 5k 個單位。由於 Wikipedia 文章可能會很長,因此您需要注意自己的花費。向 John Murch 致敬,指出這一點。)如果您對筆記本進行了增強或發現了有趣的案例,希望您能告訴我。 你可以在 Twitter 上的@jroakes 找到我。