
構建有效的 Robots.txt 的關鍵
已發表: 2020-02-18機器人程序,也稱為爬蟲或蜘蛛,是使用鏈接作為道路自動從一個網站“旅行”到另一個網站的程序。 儘管他們總是表現出一定的好奇心,robot.txt 文件可以是非常有效的工具。 谷歌和必應等搜索引擎使用機器人來抓取網絡內容。 robots.txt 文件為不同的漫遊器提供指導,說明它們不應在您的網站上抓取哪些頁面。 您還可以從 robots.txt 鏈接到您的 XML 站點地圖,以便機器人擁有它應該抓取的每個頁面的地圖。
為什麼 robots.txt 有用?
在搜索引擎機器人的情況下,robots.txt 限制了機器人需要抓取和索引的頁面數量。 如果您想避免 Google 抓取管理頁面,您可以在 robots.txt 中阻止它們,以嘗試將頁面保留在 Google 服務器之外。
除了防止頁面被索引外,robots.txt 還非常適合優化抓取預算。 抓取預算是 Google 確定將在您的網站上抓取的頁面數。 通常權限多、頁面多的網站比頁面少、權限低的網站的爬取預算要大。 由於我們不知道為我們的網站分配了多少抓取預算,因此我們希望通過允許 Googlebot 訪問最重要的網頁而不是抓取我們不想被編入索引的網頁來充分利用這段時間。
關於 robots.txt,您需要了解的一個非常重要的細節是,雖然 Google 不會抓取被 robots.txt 阻止的頁面,但如果該頁面是從其他網站鏈接的,它們仍然可以被編入索引。 要正確防止您的頁面被編入索引並出現在 Google 搜索結果中,您需要對服務器上的文件進行密碼保護,使用 noindex 元標記或響應標頭,或完全刪除頁面(響應 404 或 410)。 有關抓取和控制索引的更多信息,您可以閱讀 OnCrawl 的 robots.txt 指南。
[案例研究] 管理 Google 的機器人抓取
 閱讀案例研究
閱讀案例研究正確的 Robots.txt 語法
robots.txt 語法有時會有點棘手,因為不同的爬蟲對語法的解釋不同。 此外,一些信譽不佳的爬蟲將 robots.txt 指令視為建議,而不是他們需要遵循的明確規則。 如果您的網站上有機密信息,除了使用 robots.txt 阻止爬蟲外,使用密碼保護也很重要
下面我列出了在處理 robots.txt 時需要牢記的一些事項:
- robots.txt 文件需要位於域下而不是子目錄下。 爬蟲不會檢查子目錄中的 robots.txt 文件。
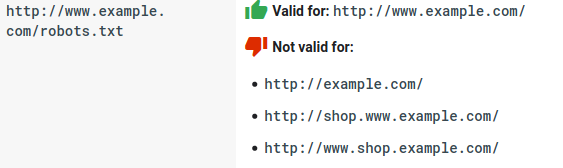
- 每個子域都需要自己的 robots.txt 文件:
- Robots.txt 區分大小寫:
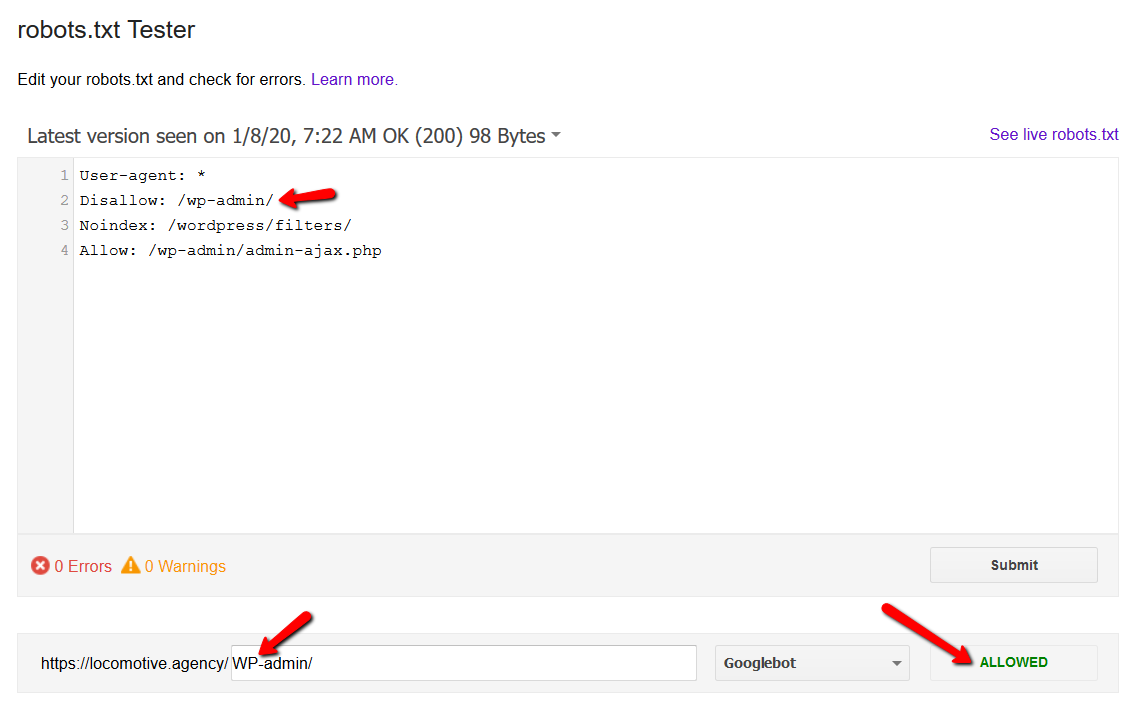
- noindex 指令:當您在 robots.txt 中使用 noindex 時,它的工作方式與 disallow 相同。 Google 將停止抓取該頁面,但會將其保留在其索引中。 @jroakes 和我創建了一個測試,我們在文章 /wordpress/filters/ 上使用了 Noindex 指令,並在 Google 中提交了頁面。 您可以在下面的屏幕截圖中看到它顯示 URL 已被阻止:
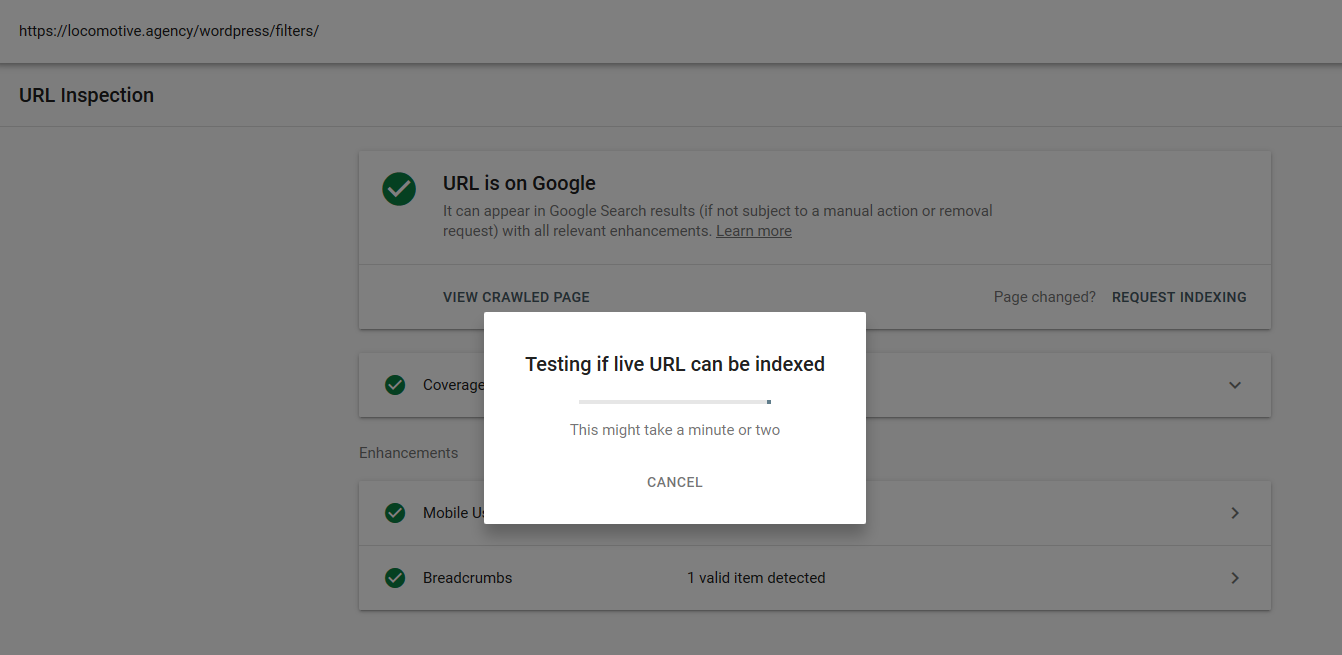
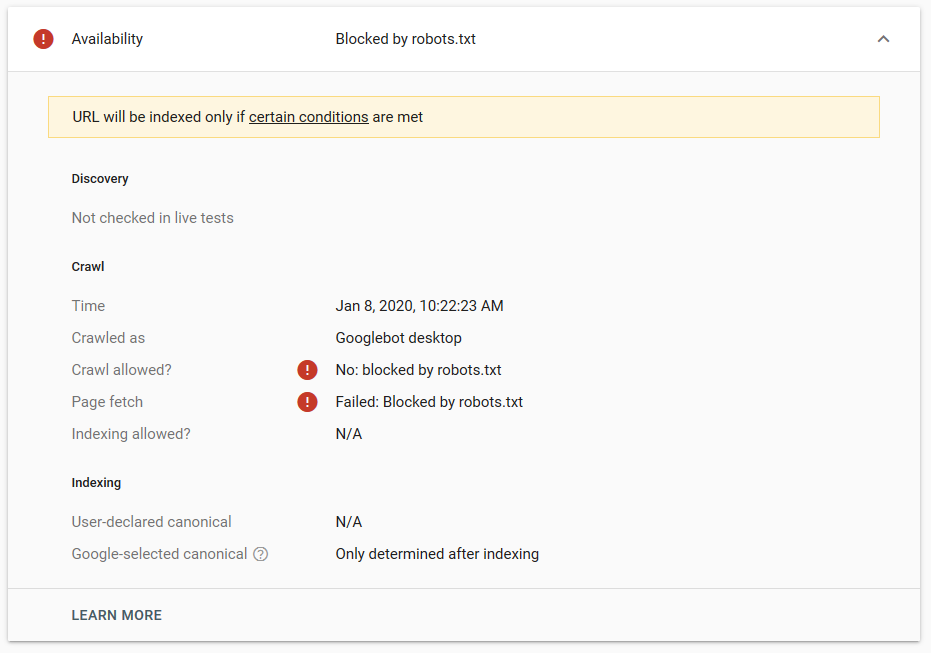
我們在 Google 中進行了幾次測試,並且該頁面從未從索引中刪除:
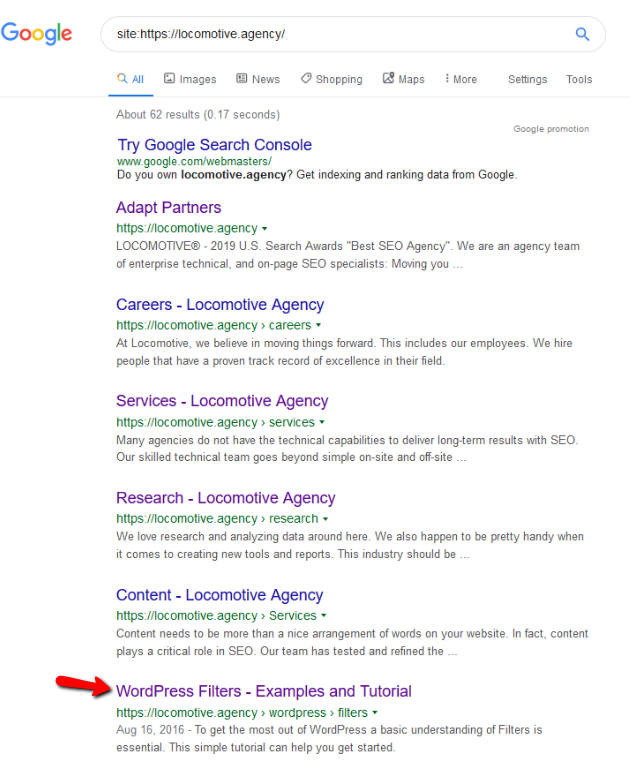
去年有一個關於在 robots.txt 中工作的 noindex 指令的討論,刪除頁面但谷歌。 這是 Gary Illyes 表示它正在消失的線程。 在這個測試中,我們可以看到谷歌的解決方案已經到位,因為 noindex 指令沒有從搜索結果中刪除頁面。

最近,克里斯蒂安·奧利維拉(Christian Oliveira)在 Twitter 上發布了另一個有趣的帖子,他在其中分享了一些細節,以供在處理您的 robots.txt 時考慮。
- 如果我們想擁有通用規則和僅適用於 Googlebot 的規則,我們需要復制 User-agent: Google bot 規則集下的所有通用規則。 如果未包含它們,Googlebot 將忽略所有規則:

- 另一個令人困惑的行為是規則的優先級(在同一個用戶代理組內)不是由它們的順序決定的,而是由規則的長度決定的。
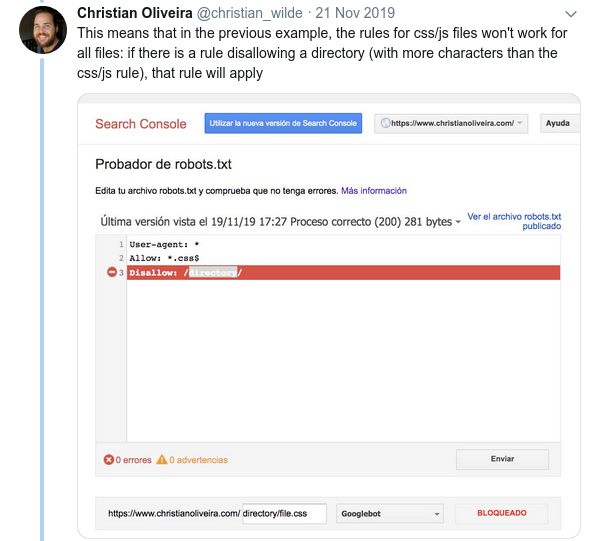
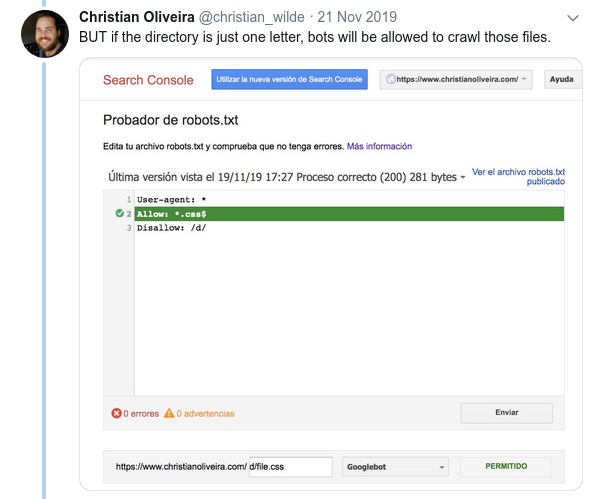
- 現在,當您有兩條規則,具有相同的長度和相反的行為(一個允許爬行,另一個不允許爬行)時,限制較少的規則適用:
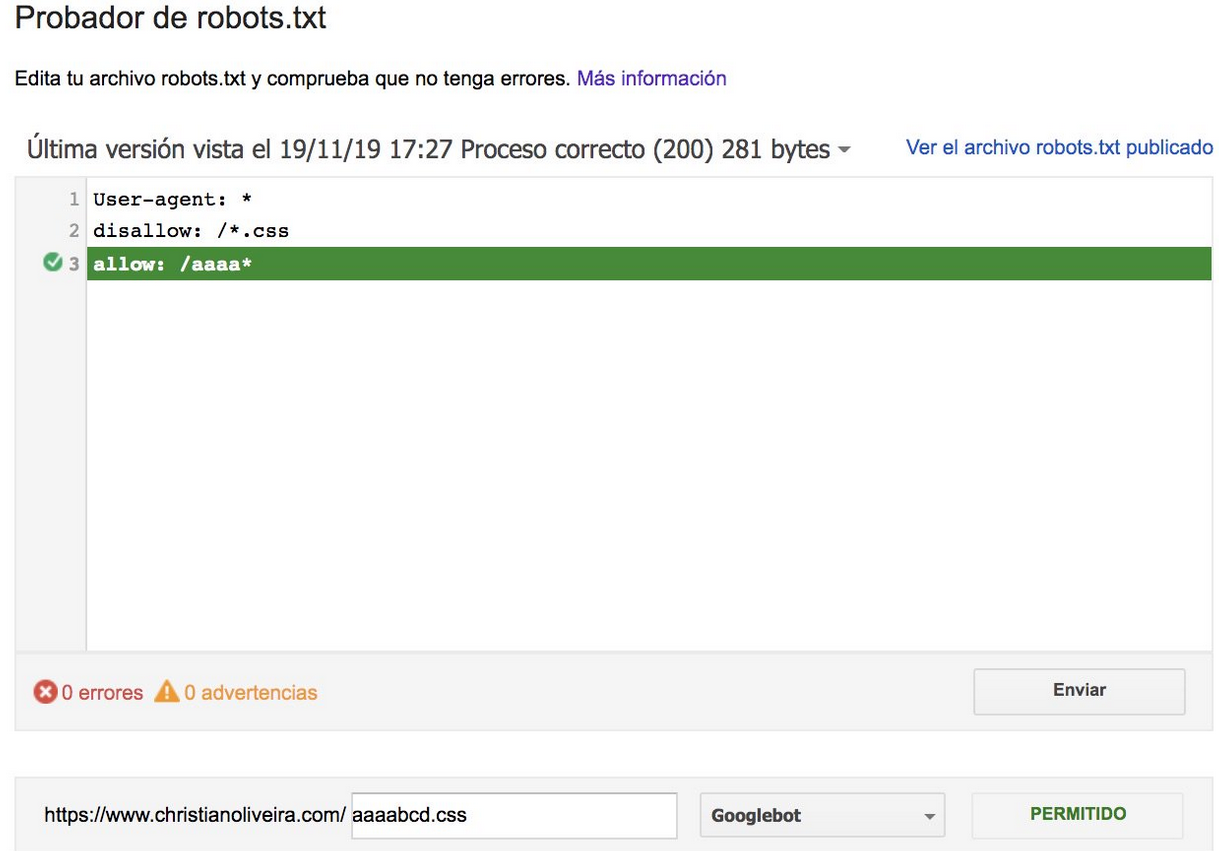
如需更多示例,請閱讀 Google 提供的 robots.txt 規範。
測試您的 Robots.txt 的工具
如果你想測試你的 robots.txt 文件,有幾個工具可以幫助你,如果你想自己製作,還有幾個 github 存儲庫:
- 蒸餾的
- Google 已將舊 Google Search Console 中的 robots.txt 測試工具留在此處
- 在 Python 上
- 在 C++ 上
示例結果:有效使用 Robots.txt 進行電子商務
下面我介紹了一個案例,我們正在使用一個沒有 robots.txt 文件的 Magento 站點。 Magento 和其他 CMS 都有管理頁面和目錄,其中包含我們不希望 Google 抓取的文件。 下面,我們包含了我們在 robots.txt 中包含的一些目錄的示例:
## 通用 Magento 目錄 禁止:/app/ 禁止:/下載器/ 不允許:/錯誤/ 禁止:/包括/ 禁止:/lib/ 禁止:/pkginfo/ 禁止:/shell/ 禁止:/var/ ##不索引搜索頁面和未優化的鏈接類別 禁止:/catalog/product_compare/ 禁止:/catalog/category/view/ 不允許:/catalog/product/view/ 禁止:/catalog/product/gallery/ 禁止:/catalogsearch/
大量不打算被抓取的頁面影響了他們的抓取預算,Googlebot 無法抓取網站上的所有產品頁面。
您可以在下圖中看到索引頁面在 10 月 25 日(即 robots.txt 實施之時)之後如何增加:
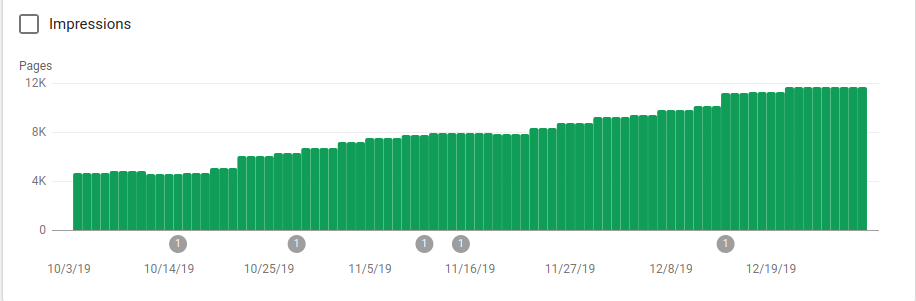
除了阻止幾個不打算被抓取的目錄之外,機器人還包括一個指向站點地圖的鏈接。 在下面的屏幕截圖中,您可以看到與排除的頁面相比,索引頁面的數量是如何增加的:
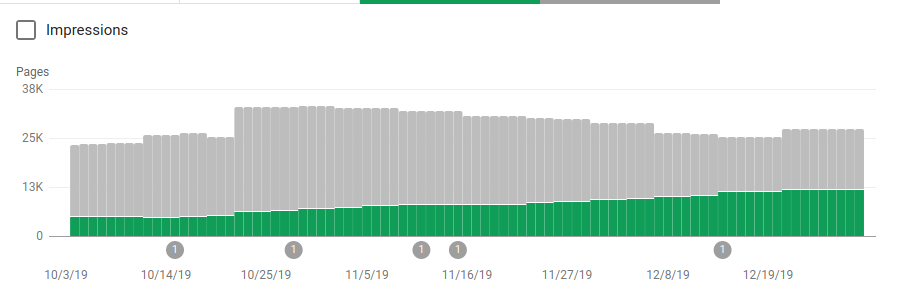
如綠色條所示,已編入索引的有效頁面呈正趨勢,而灰色條表示的排除頁面呈負趨勢。
包起來
robots.txt 的重要性有時會被低估,正如您從這篇文章中看到的那樣,在創建一個文件時需要考慮很多細節。 但工作得到了回報:我已經展示了正確設置 robots.txt 可以獲得的一些積極結果。