
如何在 Google 作為發布者的時代塑造片段
已發表: 2019-10-22谷歌長期以來一直將自己視為內容髮布者,儘管近年來這一趨勢變得難以忽視。 這在一定程度上得益於機器學習的進步和新的搜索引擎結果頁面 (SERP) 功能。
“谷歌作為內容髮布者”對於許多網站所有者來說是一個潛在的問題,因為它提出了一個艱難的選擇。 你應該:
- 保護您的內容並冒著被 Google 搜索結果拒之門外的風險?
- 向 Google 提供免費的內容來源,知道 Google 可能不會將訪問者帶到您的網站嗎?
2019 年 10 月下旬生效的新片段管理標籤可被視為 Google 的意向聲明。 在為網站所有者提供保護其內容和控制其頁面在 SERP 中的顯示方式方面,它們也是朝著正確方向邁出的一步。
為什麼要擔心高質量的內容?
谷歌資產仍為網站提供約 60% 的流量,具體取決於垂直領域,因此不玩谷歌的遊戲可能會對網站的知名度和流量產生巨大的負面影響。 但與此同時,通過 EAT 和質量評估指南,谷歌明確指出,互聯網用戶正在尋找高質量的內容,網站必須投資生產才能生存。
對獨特、高質量內容的投資是網站所有者自然想要保護的東西。 在贈送內容時,網站允許其他提供商(在這種情況下:搜索引擎)從他們的時間、金錢和專業知識中獲利。
Google 如何使用內容?
Google 使用、重新混合和重寫內容來為搜索引擎用戶提出的問題提供答案。 這些答案以多種形式顯示在 SERP 上。
搜索結果列表或“片段”
Google 使用最初從網頁本身提取的不同元素為搜索結果中的給定網頁組成一個片段:
- <title> 標籤
- <元描述=”片段文本”> 標籤
- 支持的結構化數據的 Schema.org 標記
- 網址
- Favicon(在某些地區的移動搜索結果中)
今天,其中很少有人按原樣使用。 Google 保留更換網站圖標的權利。 谷歌明確表示,他們“頁面標題和描述的生成是完全自動化的,並且……[谷歌使用]這些信息的許多不同來源,包括每個頁面的標題和元標記中的描述信息”。 最後,如最近的測試所示,谷歌已經開始抑制 SERP 中的 URL。
谷歌刪除 SERP 中的 URL 可能會稍微幫助“壞”的 TLD。
如果您無法判斷它是 .io、.org、.net、.ie 等,那麼您不能對它們產生偏見並單擊看起來更合法的 .com。 可能不是一個巨大的影響,但可能是一個微妙的影響,隨著時間的推移會變得更大。 pic.twitter.com/CcQ2E0lVtZ
- 羅斯哈金斯 (@RossHudgens) 2019 年 10 月 21 日
精選片段
谷歌通過從似乎回答搜索者問題的網頁中提取內容來創建出現在搜索結果列表之前的精選片段。 在 2019 年 2 月和 6 月,出現了多起沒有署名(或沒有可見或易於訪問的署名)的精選片段。在每種情況下,谷歌都譴責了繞過出版商權利的意圖,並聲稱缺乏署名是一個錯誤。
定義、天氣和食物
在特定位置搜索字典定義或天氣會在自動完成框中產生答案,無需註明出處,也無需執行搜索。
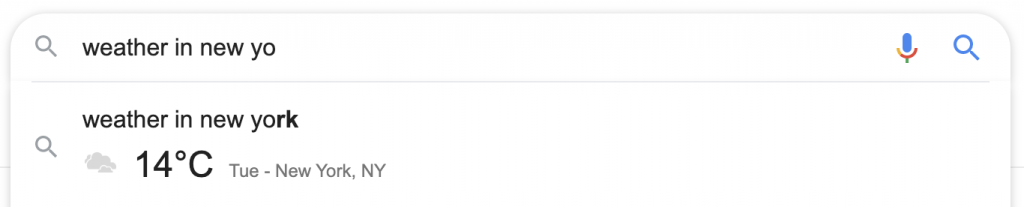
在定義的情況下,如果按下搜索按鈕,則可以使用完整的定義,包括聲音、同義詞和其他 SERP 內功能。 搜索者無需訪問牛津詞典網站,牛津署名在定義框下方以灰色小文本顯示。
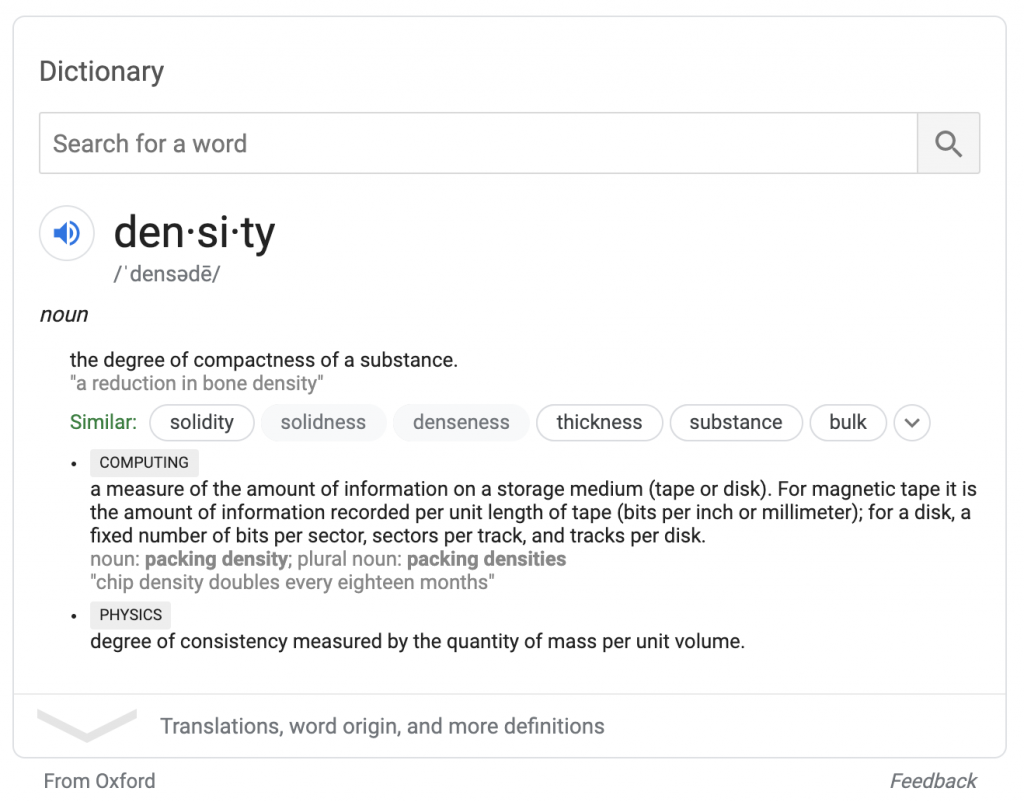
完整的天氣搜索提供了一個基於 weather.com 數據的類似預測框。 與牛津署名一樣,weather.com 署名出現在方框下方; 搜索者無需訪問weather.com 就可以與框中的數據進行交互。
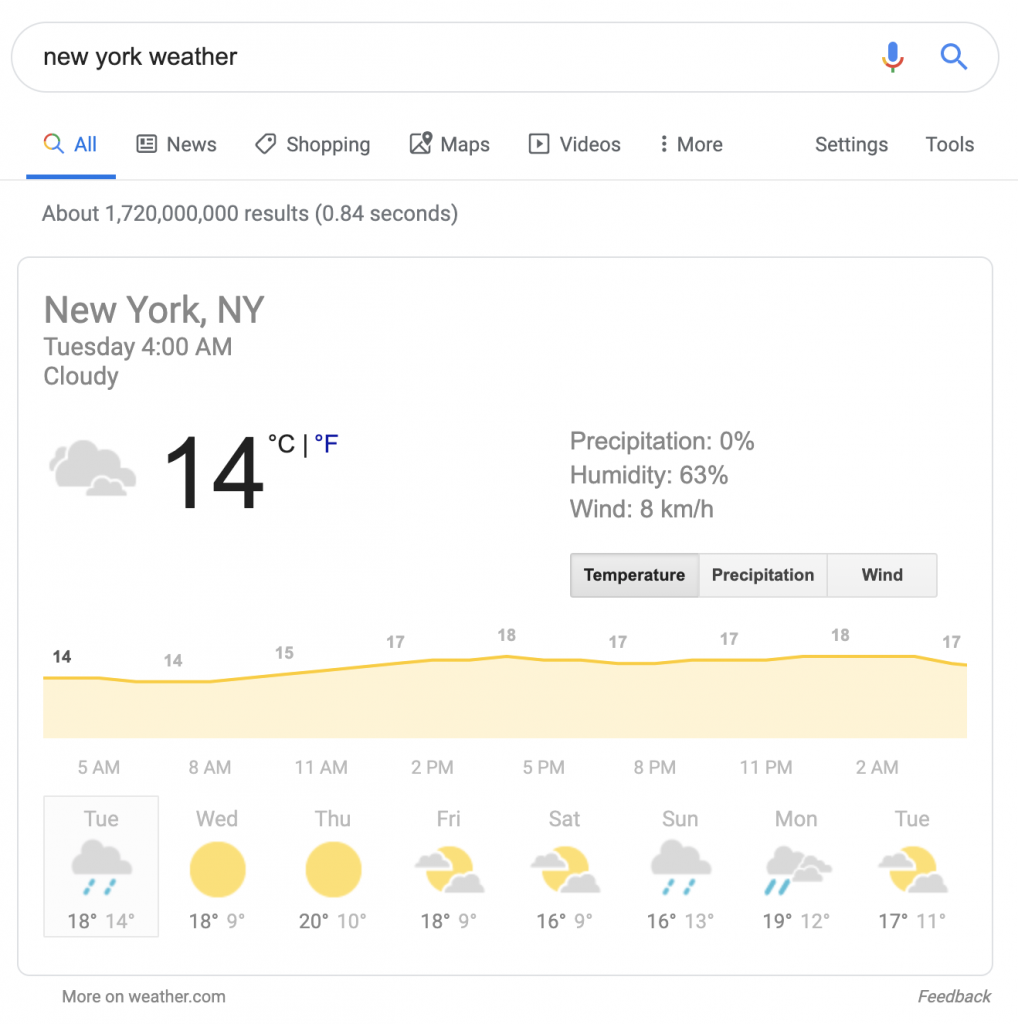
另一個類似的搜索結果是針對營養成分和食物成分:
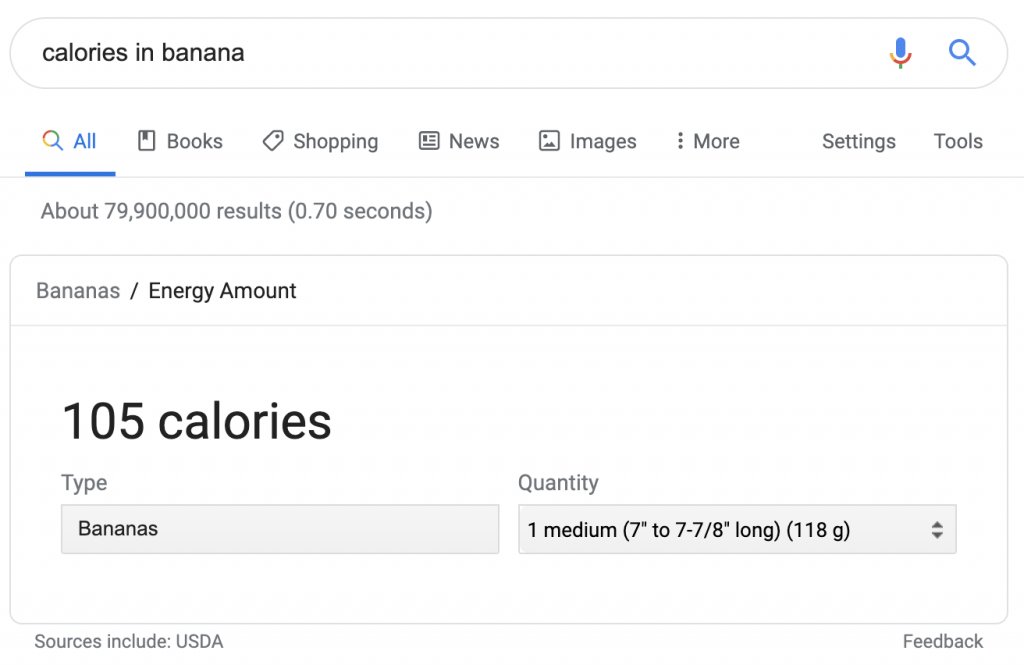
但是,在這種情況下,歸屬被列為“來源包括”。 如果使用其他來源,它們將不可見或不可訪問。
以本地為導向的結果
許多與本地活動相關的結果也來自不同的來源,以創建提供各種匯總和整理信息的 SERP。 例如,搜索者無需訪問不同的網站,而是可以查看附近正在播放的電影列表,查找不同影院的放映時間,並查找有關個別電影的詳細信息——評論、概要等。 搜索者在任何時候都不需要離開 Google 策劃的 SERP。
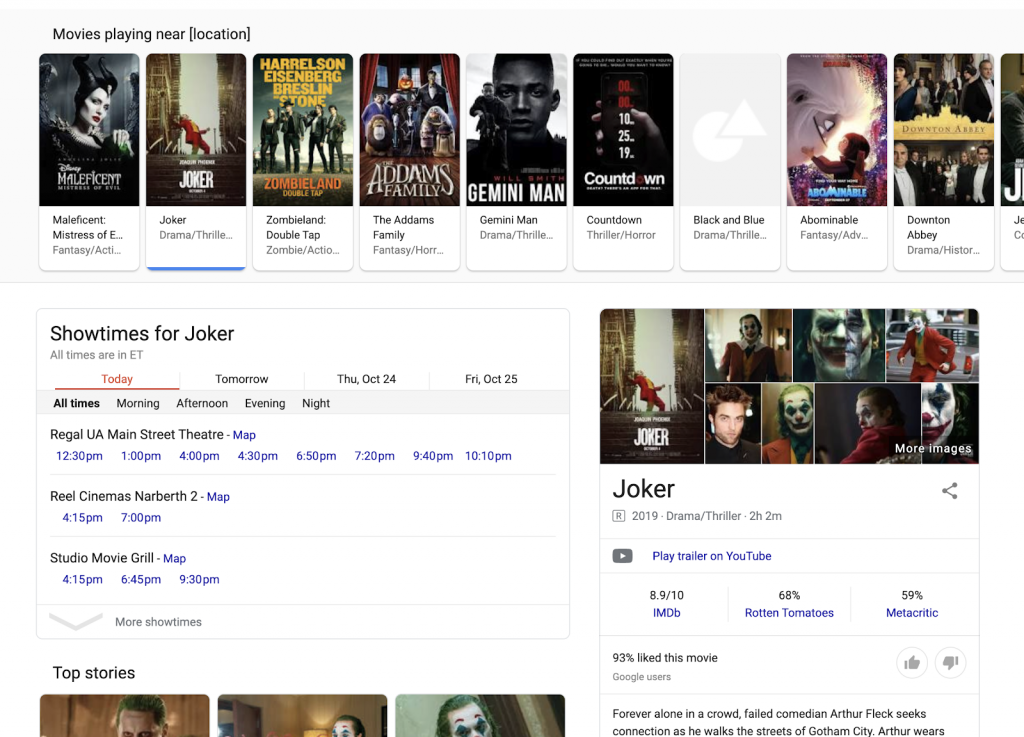
這種類型的 SERP 正在擴展到許多不同的領域,包括旅行。
AMP 故事
AMP 故事為“移動新聞消費”提供“以故事為中心”的模式。 它們是基於實體的索引如何提高 Google 從不同來源提取內容並重新混合的能力的一個例子。 例如,在谷歌為名人出現的一些故事中,谷歌將一個來源的圖像與另一個來源的文本配對。
知識面板
知識面板是“當您搜索實體時出現在 Google 上的信息框”,是 Google 知識圖譜的一部分。 這些面板中顯示的信息來自多個來源,谷歌將其列為:
- 提供有關電影或音樂等特定主題的權威數據的數據合作夥伴
- 開放網絡資源
- 已在自己的知識面板上建議對事實進行編輯的經過驗證的實體
- 實體的 Google 圖片結果預覽
谷歌此前曾表示,他們的知識圖譜依賴於維基百科/維基數據、中央情報局世界概況、公共網絡上的結構化數據、谷歌我的業務等來源。
它們還可以顯示相關實體,允許搜索用戶在不離開搜索引擎網站的情況下瀏覽知識圖譜。
其他 SERP 功能
其他 SERP 功能包括查詢預測元素,這些元素試圖回答或重新引導搜索活動,而無需將搜索用戶發送到不同的網站。 示例包括移動搜索或自動完成中的無結果答案,以及“人們也問”(PAA)框。

無結果搜索示例(移動),直接在桌面的自動完成框中顯示為答案

搜索結果中的內容管理
Schema.org 標記
由於對構成搜索列表的其他元素幾乎沒有直接控制,SEO 已經通過 Schema.org 標記大量依靠豐富片段的力量,以使他們的列表在 SERP 上脫穎而出。
然而,谷歌一直在打擊濫用豐富標記的行為,包括評論星和常見問題標記:
自更新以來,搜索結果中的 Google Review Stars 下降了 14%:
— 金融網站下降 46%
— 房地產網站下降 46%
— 法律和政府網站下降 28%新數據來自@dr_pete https://t.co/DdlrCFIrsm pic.twitter.com/w2lj9WzpLR
- 賽勒斯(@CyrusShepard)2019 年 9 月 24 日
為了避免 SERP 充滿#FAQ 結果,#Google 似乎已將上限設置為 3 個常見問題解答結果 #SEO @brodieseo @sengineland https://t.co/V8vSiKwrrv pic.twitter.com/A0Spmu9iMg
— AJ Ghergich (@SEO) 2019 年 10 月 8 日
明確指示哪些內容不能使用
本週,谷歌正在推出代碼片段管理標籤,可以用來向谷歌表明一些限制,可以用來在 SERP 中創建頁面片段。
新的管理標籤有兩個主要限制:
- 它們不適用於頁面上的結構化數據(Schema.org 標記) 。 Google 支持的 Schema.org 結構化數據始終可以顯示在搜索結果中。
- 如果它們不符合 SERP 功能要求的最小長度,它們可能會阻止您的頁面在 SERP 中的某些“特殊功能”中使用,包括特色片段。 由於長度因語言而異,因此 Google 不會公佈精選片段的最小長度。 Insead,“不希望內容顯示為特色片段的[t]軟管可以嘗試使用較低的最大片段長度。”
網站所有者有兩種選擇來實施這些標籤:
1. 元機器人標籤
從 10 月下旬開始,在全球範圍內,這些元機器人標籤可以添加到頁面 <head> 或 x-robots HTTP 標頭中。
- <meta name=”robots” content=” nosnippet “> – 不顯示此頁面的片段文本。 仍然可以使用圖像縮略圖。
- <meta name=”robots” content=” max-snippet: 50″> – 設置片段的最大字符數。 片段長度“0”相當於“nosnippet”; “-1”的片段長度被解釋為意味著片段長度沒有限制。
- <meta name=”robots” content=” max-video-preview: 3″> – 設置視頻預覽的最大長度,以秒為單位。 視頻長度為“0”將阻止顯示視頻預覽; “-1”的視頻長度被解釋為意味著對視頻預覽長度沒有限制。
- <meta name=”robots” content=” max-image-preview: standard”> – 設置此頁面中圖像的最大圖像尺寸。 選項有:“無”、“標準”或“大”。
您可以在同一個元機器人標籤中使用多個片段管理運算符。 用逗號分隔每個運算符。
2. Data-nosnippet HTML 屬性
2019 年底,Google 將識別一個新的 HTML 屬性: data-nosnippet 。 它可以應用於 <span>、<div> 或 <selection> 標籤。
data-nosnippet 屬性防止應用它的標籤中的文本顯示在頁面的片段中。
明確允許在法國為歐洲媒體重複使用內容
谷歌對新聞內容的重新混合和重新發布已經在某些地方突破了版權法的限制。 法國最近成為人們關注的焦點:
由於法國版權法的變化,Google 搜索不會在法國顯示受影響的歐洲新聞出版物的文本片段或圖像縮略圖,除非該網站已實施元標記以允許搜索預覽。 (來源)
換言之,谷歌將從法國的搜索結果中排除任何未明確允許其重新發布並最終重新混合內容的歐洲出版物。
具有諷刺意味的是,授予權限的方式並不是特別清楚:唯一明確允許的元機器人標籤是“全部”,它“是默認值,如果明確列出則無效”,除了現在在法國 SERP 上。
否則,發布者只能通過未包含在片段管理公告中的約定來表明對文本和視頻預覽的長度沒有限制,或者他們可以施加任意限制以表明他們不想禁止搜索預覽.
走鋼絲
每個網站都需要在保護其內容和塑造其在 Google 的 SERP 上的存在之間找到適當的平衡。
隨著谷歌越來越多地充當內容髮布者,我們可以期待更多具有最少歸屬的 SERP 功能,以及更多國家的版權法——旨在保護內容的所有者和創建者——對谷歌可以顯示和不能顯示的內容產生影響。
我認為有趣的是這對版權的影響……人們抱怨 G 在未經許可的情況下獲取內容 - 片段標籤將是默認許可。 需要很久嗎?
- 珍妮哈拉斯 (@jennyhalasz) 2019 年 10 月 15 日
幸運的是,新的片段管理工具為網站所有者提供了一個工具箱的開始,以塑造谷歌可以在 SERP 上重用其內容的哪些部分以及多少。
目前,我認為在具有大量原始內容的網站上適當實施片段管理標籤是明智的,儘管我擔心僅具有限制性的標籤不會對所有網站都有用。 儘管有這個警告,但仍有一些方法可以使用它們來優化 SERP 的體驗並獲得更多流量。
我認為人們會採用新標籤。 我認為有很多機會可以用這些標籤“塑造”一個片段,以提供比谷歌自動提取的更好的體驗並優化點擊率。
— Kevin_Indig (@Kevin_Indig) 2019 年 10 月 16 日
我期待看到不同垂直領域的實驗,以找到最有效的方法。