
在野外看到的 7 次 SEO 失敗(以及如何避免它們)
已發表: 2022-06-12
我們經常收到人們的疑問,他們想知道為什麼他們的網站沒有排名,或者為什麼它沒有被搜索引擎索引。
最近,我遇到了幾個存在重大錯誤的網站,只要所有者知道看,這些錯誤很容易修復。 雖然一些 SEO 錯誤非常複雜,但這裡有一些經常被忽視的“撞頭”錯誤。
因此,請查看這些 SEO 錯誤——以及如何避免自己犯這些錯誤。
SEO 失敗 #1:Robots.txt 問題
robots.txt 文件功能強大。 它指示搜索引擎機器人從其索引中排除什麼。
過去,我看到網站在重新設計網站後忘記從該文件中刪除一行代碼,並將整個網站置於搜索結果中。
因此,當花卉網站突出顯示問題時,我會從我經常在網站上進行的第一項檢查開始——查看 robots.txt 文件。
我想知道該網站的 robots.txt 是否阻止搜索引擎為其內容編制索引。 但是,我看到的不是預期的文本文件,而是一個向 Robots.Txt 提供鮮花的頁面。
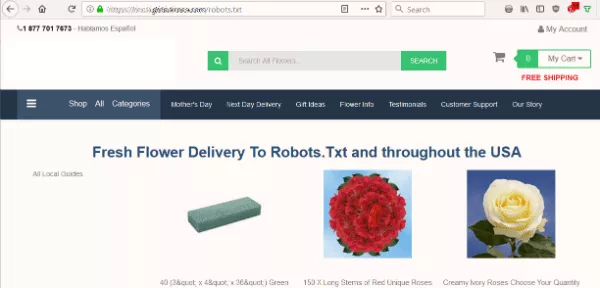
該網站沒有 robots.txt,這是機器人在抓取網站時首先查找的內容。 那是他們的第一個錯誤。 但是把那個文件作為目的地……真的嗎?
SEO 失敗 #2:自動生成變得瘋狂
其次,該網站會自動生成無意義的內容。 它可能會傳遞給聖誕老人或我在 URL 中輸入的任何文本。
我運行了一個檢查服務器頁面工具來查看自動生成的頁面顯示的狀態。 如果它是 404(未找到),那麼機器人將忽略該頁面。 但是,頁面的服務器標頭給出了 200 (OK) 狀態。 結果,虛假頁面為搜索引擎的索引打開了綠燈。
搜索引擎希望在每頁看到獨特且有意義的內容。 因此,索引這些非頁面可能會損害他們的 SEO。
SEO失敗#3:規範錯誤
接下來,我查看了搜索引擎對這個網站的看法。 他們可以抓取和索引頁面嗎?
查看各個頁面的源代碼,我注意到另一個重大錯誤。
每個頁面都有一個指向主頁的規範鏈接元素:
<link rel=”canonical” href=”https://www.domain.com/” />
換句話說,搜索引擎被告知每個頁面實際上都是主頁的副本。 基於此標籤,機器人應該忽略該域上的其餘頁面。
幸運的是,谷歌足夠聰明,可以找出這些標籤何時可能被錯誤使用。 所以它仍然在索引網站的一些頁面。 但是這個普遍的規範要求並沒有幫助網站的搜索引擎優化。
如何避免這些 SEO 失敗
對於花卉網站的多個錯誤,以下是修復:
- 有一個有效的 robots.txt 文件來告訴搜索引擎如何抓取和索引站點。 即使它是一個空白文件,它也應該存在於您的域的根目錄中。
- 為每個頁面生成適當的規範鏈接元素。 並且不要指向要編入索引的頁面。
- 當頁面 URL 不存在時顯示自定義 404 頁面。 確保它返回 404 服務器代碼,以便向搜索引擎提供明確的信息。
- 小心自動生成的頁面。 避免為搜索引擎和用戶生成無意義或重複的頁面。
即使您沒有遇到網站問題,為了安全起見,這些都是定期檢查的好點。
哦,永遠不要在您的 404 頁面上放置規範標籤,尤其是指向您的主頁……只是不要。
SEO失敗#4:隔夜排名自由落體
有時,一個簡單的改變可能是一個代價高昂的錯誤。 這個故事來自我們的一位 SEO 客戶的經歷。
當他們的域名的 .org 擴展名可用時,他們將其搶購一空。 到目前為止,一切都很好。 但他們的下一步行動導致了災難。
他們立即設置了一個 301 重定向,將新獲得的 .org 指向他們的主要 .com 網站。 他們的推理是有道理的——捕捉可能輸入錯誤擴展名的任性訪客。
但是第二天,他們打電話給我們,很瘋狂。 他們的網站流量不存在。 他們不知道為什麼。
一些快速檢查顯示,他們的搜索排名在一夜之間從谷歌中消失了。 不需要太多的問答就可以弄清楚發生了什麼。
他們在不考慮風險的情況下進行了重定向。 我們進行了一些挖掘,發現 .org 有一段骯髒的過去。

.org 網站的前任所有者已將其用於垃圾郵件。 通過重定向,Google 將所有這些毒藥分配給了公司的主站點! 我們只用了兩天時間就恢復了該網站在 Google 中的地位。
如何避免這種 SEO 失敗
始終研究您註冊的任何域名的鏈接配置文件和歷史記錄。
合格的 SEO 顧問可以做到這一點。 您還可以運行一些工具來查看站點的壁櫥中可能有哪些骷髏。
每當我選擇一個新域名時,我喜歡讓它休眠至少六個月到一年,然後再嘗試使用它。 我希望搜索引擎能夠清楚地區分我的網站的新版本與過去的版本。 這是保護您的投資的額外預防措施。
SEO失敗#5:不會消失的頁面
有時網站可能會遇到不同的問題——搜索索引中的頁面太多。
搜索引擎有時會保留不再有效的頁面。 如果人們在從搜索結果中進入錯誤頁面時,這是一種糟糕的用戶體驗。
一些網站所有者出於挫敗感,在 robots.txt 文件中列出了各個 URL。 他們希望谷歌能接受提示並停止索引它們。
但是這種方法失敗了! 如果 Google 尊重 robots.txt,則不會抓取這些網頁。 因此,Google 永遠不會看到 404 狀態,也不會發現頁面無效。
如何避免這種 SEO 錯誤
修復的第一部分是不允許robots.txt 中的這些 URL。 您希望機器人四處爬行並知道應該從搜索索引中刪除哪些 URL。
之後,在舊 URL 上設置 301 重定向。 將訪問者(和搜索引擎)發送到網站上最近的替換頁面。 這會照顧您的訪問者,無論他們來自搜索還是來自直接鏈接。
SEO失敗#6:錯過的鏈接資產
我點擊了一個大學網站的鏈接,收到了 404(未找到)錯誤。
這種情況並不少見,除了鏈接指向 /home.html — 該站點以前的主頁 URL。
在某些時候,他們一定改變了他們的網站架構並刪除了舊式的 /home.html,在洗牌中失去了重定向。
具有諷刺意味的是,他們的 404 頁面說您可以從主頁重新開始,這正是我最初想要達到的。
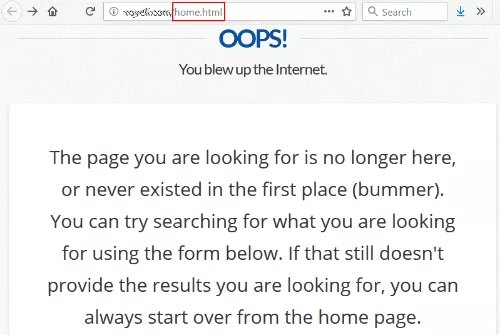
這是一個非常安全的賭注,這個網站希望有一個來自受人尊敬的大學的很好的鏈接到他們的主頁。 而實現這一點完全在他們的控制範圍內。 他們甚至不必聯繫鏈接站點。
如何解決此故障
要修復此鏈接,他們只需將 301 重定向指向 /home.html 到當前主頁。 (有關如何設置 301 重定向的說明,請參閱我們的文章。)
如需額外積分,請訪問 Google Search Console 並查看索引覆蓋率狀態報告。 查看所有報告為返回 404 錯誤的頁面,並在此處修復盡可能多的錯誤。
SEO失敗#7:複製/粘貼失敗
網站重新設計啟動,規範標籤到位,並安裝了新的谷歌標籤管理器。 然而,仍然存在排名問題。 事實上,一個新的著陸頁並沒有在 Google Analytics 中顯示任何訪問者。
開發團隊回應說,他們已經按照書本完成了所有工作,並且嚴格按照示例進行操作。
他們完全正確。 他們遵循示例——包括留下示例代碼! 複製粘貼後,開發者忘記輸入自己的目標站點信息。
以下是我們的分析師在網站代碼中遇到的三個示例:
- <link rel=”canonical” href=”http://example.com/”>
- 'analyticsAccountNumber':'UA-123456-1'
- _gaq.push(['_setAccount', 'UA-000000-1']);
如何避免這種 SEO 失敗
當事情不正常時,不要只看“這個元素在源代碼中嗎?” 可能從未在您的 HTML 代碼中指定正確的驗證代碼、帳號和 URL。
錯誤發生了,人只是人。 我希望這些示例將幫助您避免自己的類似 SEO 錯誤。 為了您的利益,我們創建了一個深入的 SEO 指南,概述了 SEO 技巧和最佳實踐。
但是一些 SEO 問題比你想像的要復雜。 如果您有索引問題,那麼我們隨時為您提供幫助。 致電我們或填寫我們的申請表,我們會與您取得聯繫。
喜歡這個帖子嗎? 請訂閱我們的博客,以便將新帖子發送到您的收件箱。