
Python中的語義關鍵字聚類
已發表: 2021-04-19在一個充滿數字營銷神話的世界中,我們相信為日常問題提出切實可行的解決方案是我們所需要的。
在 PEMAVOR,我們始終分享我們的專業知識和知識,以滿足數字營銷愛好者的需求。 因此,我們經常發布免費的 Python 腳本來幫助您提高投資回報率。
我們使用 Python 進行的 SEO 關鍵字聚類為獲得大型 SEO 項目的新見解鋪平了道路,Python 代碼僅不到 50 行。
該腳本背後的想法是允許您對關鍵字進行分組,而無需支付“誇大的費用”來……好吧,我們知道誰……
但我們意識到僅靠這個腳本是不夠的。 需要另一個腳本,所以你們可以進一步理解你的關鍵字:你需要能夠“按含義和語義關係對關鍵字進行分組。 ”
現在,是時候將Python 用於 SEO更進一步了。
抓取數據³
 學到更多
學到更多傳統的語義聚類方式
如您所知,語義的傳統方法是建立word2vec 模型,然後使用Word Mover's Distance 對關鍵字進行聚類。
但是這些模型需要花費大量時間和精力來構建和訓練。 因此,我們想為您提供更直接的解決方案。 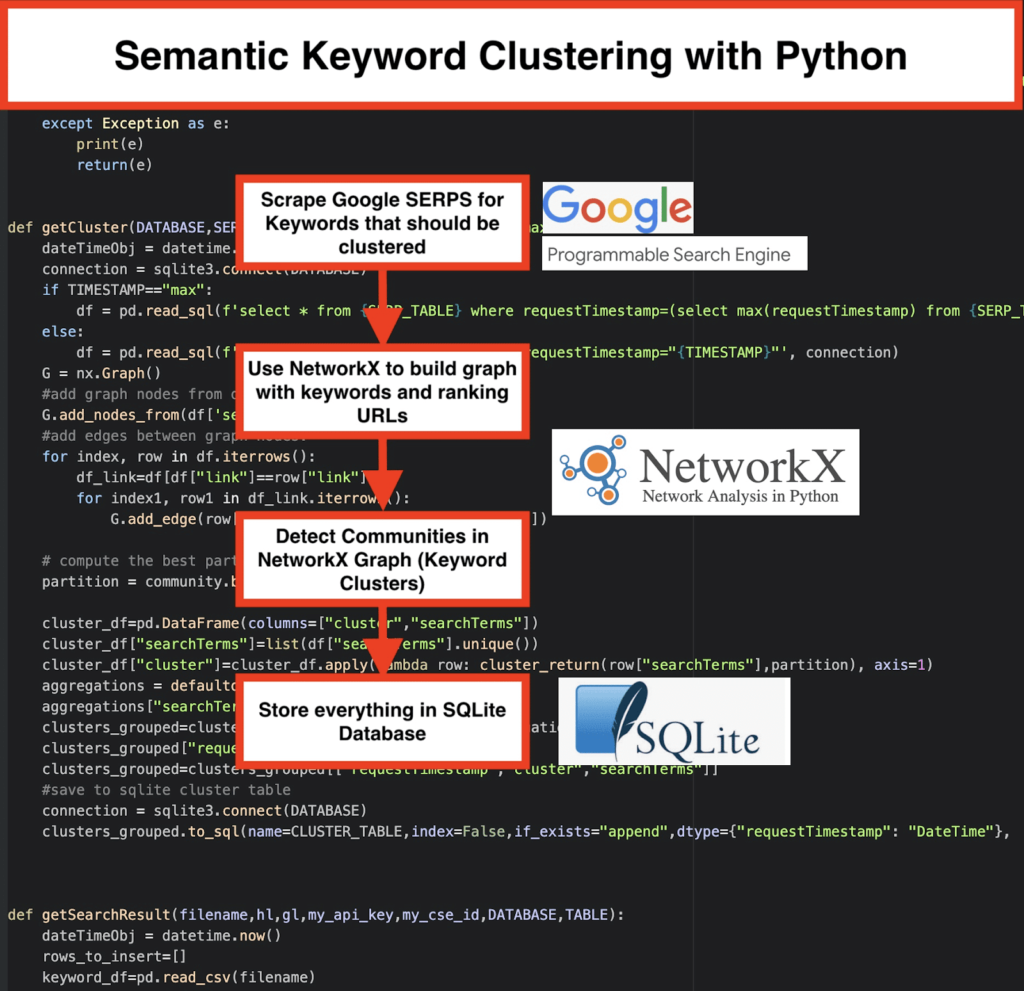
Google SERP 結果和發現語義
Google 利用 NLP 模型提供最佳搜索結果。 這就像潘多拉的盒子被打開,我們並不完全知道。
但是,我們可以使用此框按語義和含義對關鍵字進行分組,而不是構建我們的模型。
我們是這樣做的:
️首先,拿出一個主題的關鍵字列表。
️ 然後,為每個關鍵字抓取 SERP 數據。
️ 接下來,創建一個圖表,其中包含排名頁面和關鍵字之間的關係。
️ 只要相同的頁面針對不同的關鍵字排名,就意味著它們是相關的。 這是創建語義關鍵字集群的核心原則。
是時候用 Python 把所有東西放在一起了
Python 腳本提供以下功能:
- 通過使用 Google 的自定義搜索引擎,下載關鍵字列表的 SERP。 數據保存到SQLite 數據庫。 在這裡,您應該設置一個自定義搜索 API。
- 然後,利用每天 100 個請求的免費配額。 但是,如果您不想等待或擁有大型數據集,他們還提供每 1000 個任務 5 美元的付費計劃。
- 如果您不著急,最好使用SQLite 解決方案- SERP 結果將在每次運行時附加到表中。 (當你第二天再次有配額時,只需採取一系列新的 100 個關鍵字。)
- 同時,您需要在Python Script中設置這些變量。
- CSV_FILE=”keywords.csv” => 在此處存儲您的關鍵字
- 語言 = “en”
- 國家=“en”
- API_KEY=” xxxxxxx”
- CSE_ID=”xxxxxxx”
- 運行
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)會將 SERP 結果寫入數據庫。 - 聚類由networkx和社區檢測模塊完成。 數據是從SQLite 數據庫中獲取的——使用
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)調用集群 - 聚類結果可以在SQLite 表中找到——只要不更改,默認名稱為“keyword_clusters”。
下面,您將看到完整的代碼:
# Pemavor.com 的語義關鍵字聚類 # 作者:Stefan Neefischer ([email protected]) 從 googleapiclient.discovery 導入構建 將熊貓導入為 pd 進口文史丹 從日期時間導入日期時間 從fuzzywuzzy導入fuzz 從 urllib.parse 導入 urlparse 從 tld 導入 get_tld 導入懶惰 導入json 將熊貓導入為 pd 將 numpy 導入為 np 將 networkx 導入為 nx 進口社區 導入 sqlite3 導入數學 導入 io 從集合導入 defaultdict def cluster_return(searchTerm,partition): 返回分區[searchTerm] def 語言檢測(str_lan): lan=langid.classify(str_lan) 返回局域網[0] def extract_domain(url, remove_http=True): uri = urlparse(url) 如果刪除_http: domain_name = f"{uri.netloc}" 別的: domain_name = f"{uri.netloc}://{uri.netloc}" 返回域名 def extract_mainDomain(url): res = get_tld(url, as_object=True) 返回 res.fld def 模糊比率(str1,str2): 返回 fuzz.ratio(str1,str2) def blur_token_set_ratio(str1,str2): 返回 fuzz.token_set_ratio(str1,str2) def google_search(search_term, api_key, cse_id,hl,gl, **kwargs): 嘗試: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='查詢(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)' ,num=10, cx=cse_id, **kwargs).execute() 返回資源 例外為 e: 打印(e) 返回(e) def google_search_default_language(search_term, api_key, cse_id,gl, **kwargs): 嘗試: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,gl=gl,fields='查詢(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10 , cx=cse_id, **kwargs).execute() 返回資源 例外為 e: 打印(e) 返回(e) def getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="max"): dateTimeObj = datetime.now() 連接 = sqlite3.connect(數據庫) 如果 TIMESTAMP=="max": df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp=(select max(requestTimestamp) from {SERP_TABLE})', 連接) 別的: df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp="{TIMESTAMP}"', 連接) G = nx.Graph() #從數據框列添加圖形節點 G.add_nodes_from(df['searchTerms']) #在圖節點之間添加邊: 對於索引,df.iterrows() 中的行: df_link=df[df["link"]==row["link"]] 對於 df_link.iterrows() 中的 index1、row1: G.add_edge(row["searchTerms"], row1['searchTerms']) # 計算社區(集群)的最佳分區 分區 = community.best_partition(G) cluster_df=pd.DataFrame(columns=["cluster","searchTerms"]) cluster_df["searchTerms"]=list(df["searchTerms"].unique()) cluster_df["cluster"]=cluster_df.apply(lambda row: cluster_return(row["searchTerms"],partition), axis=1) 聚合 = defaultdict() 聚合["searchTerms"]=' | '。加入 clusters_grouped=cluster_df.groupby("cluster").agg(聚合).reset_index() clusters_grouped["requestTimestamp"]=dateTimeObj clusters_grouped=clusters_grouped[["requestTimestamp","cluster","searchTerms"]] #保存到sqlite集群表 連接 = sqlite3.connect(數據庫) clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) def getSearchResult(文件名,hl,gl,my_api_key,my_cse_id,DATABASE,TABLE): dateTimeObj = datetime.now() rows_to_insert=[] 關鍵字_df=pd.read_csv(文件名) 關鍵字=keyword_df.iloc[:,0].tolist() 用於關鍵字查詢: 如果 hl=="默認": 結果 = google_search_default_language(查詢,my_api_key,my_cse_id,gl) 別的: 結果 = google_search(查詢,my_api_key,my_cse_id,hl,gl) 如果結果中出現“項目”,結果中出現“查詢”: 對於範圍內的位置(0,len(result [“items”])): 結果[“項目”][位置][“位置”]=位置+1 結果["items"][position]["main_domain"]= extract_mainDomain(result["items"][position]["link"]) 結果["items"][position]["title_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["title"],query) 結果["items"][position]["snippet_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["snippet"],query) 結果["items"][position]["title_matchScore_order"]=fuzzy_ratio(result["items"][position]["title"],query) 結果["items"][position]["snippet_matchScore_order"]=fuzzy_ratio(result["items"][position]["snippet"],query) 結果["items"][position]["snipped_language"]=language_detection(result["items"][position]["snippet"]) 對於範圍內的位置(0,len(result [“items”])): rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl, "totalResults":result["queries"]["request"][0]["totalResults"],"link":result["items"][position]["link"], "displayLink":result["items"][position]["displayLink"],"main_domain":result["items"][position]["main_domain"], “位置”:結果[“項目”][位置][“位置”],“片段”:結果[“項目”][位置][“片段”], "snipped_language":result["items"][position]["snippet_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"], "snippet_matchScore_token":result["items"][position]["snippet_matchScore_token"],"title":result["items"][position]["title"], "title_matchScore_order":result["items"][position]["title_matchScore_order"],"title_matchScore_token":result["items"][position]["title_matchScore_token"], }) df=pd.DataFrame(rows_to_insert) #將serp結果保存到sqlite數據庫 連接 = sqlite3.connect(數據庫) df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) ################################################# ################################################# ######################################### #讀我:# ################################################# ################################################# ######################################### #1- 你需要設置一個谷歌自定義搜索引擎。 # # 請提供 API Key 和 SearchId。 # # 還要設置您想要監控 SERP 結果的國家和語言。 # # 如果你還沒有 API Key 和 Search Id,# # 您可以按照此頁面 https://developers.google.com/custom-search/v1/overview#prerequisites 的先決條件部分下的步驟進行操作 # ## #2- 您還需要輸入用於保存結果的數據庫、serp 表和集群表名稱。 # ## #3-輸入包含將用於serp的關鍵字的csv文件名或完整路徑# ## #4- 對於關鍵字聚類,輸入將用於聚類的 serp 結果的時間戳。 # # 如果您需要對最後一個 serp 結果進行聚類,請輸入“max”作為時間戳。 # # 或者您可以輸入特定的時間戳,例如“2021-02-18 17:18:05.195321”# ## #5- 通過數據庫瀏覽器瀏覽 Sqlite 程序的結果 # ################################################# ################################################# ######################################### #csv 包含 serp 關鍵字的文件名 CSV_FILE="keywords.csv" # 確定語言 語言 = "en" #確定城市 國家=“en” #google自定義搜索json api鍵 API_KEY="在此處輸入密鑰" #搜索引擎ID CSE_ #sqlite 數據庫名稱 數據庫="keywords.db" #table name 將serp結果保存到它 SERP_TABLE="keywords_serps" # 為關鍵字運行 serp getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE) #table 名稱,集群結果將保存到它。 CLUSTER_TABLE="keyword_clusters" #請輸入時間戳,如果你想為特定的時間戳製作集群 #如果您需要為最後一個serp結果製作集群,請使用“max”值發送 #TIMESTAMP="2021-02-18 17:18:05.195321" TIMESTAMP="最大" #根據網絡和社區算法運行關鍵字集群 getCluster(數據庫,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)

Google SERP 結果和發現語義
我們希望您喜歡這個腳本,它可以在不依賴語義模型的情況下將關鍵字分組到語義集群中。 由於這些模型通常既複雜又昂貴,因此尋找其他方法來識別共享語義屬性的關鍵字非常重要。
通過將語義相關的關鍵字放在一起,您可以更好地涵蓋某個主題,更好地將您網站上的文章相互鏈接,並提高您網站針對給定主題的排名。