
多模式和多語言搜索的興起
已發表: 2022-01-06將搜索擴展到文本查詢之外並消除語言障礙是塑造搜索引擎未來的最新趨勢。 借助新的人工智能功能,搜索引擎正在尋求提升更好的搜索體驗,同時引入新工具來幫助用戶檢索特定信息。 在本文中,我們將討論多模式和多語言搜索系統這一新興話題。 我們還將展示我們在 Wordlift 構建的演示搜索工具的結果。
下一代搜索引擎
良好的用戶體驗包含用戶和搜索引擎之間的多個交互方面。 從用戶界面的設計及其可用性到對搜索意圖的理解和解決其模糊查詢,大型搜索引擎正在準備下一代搜索工具。
多模式搜索
描述多模式搜索引擎的一種方法是考慮一個能夠在單個查詢中處理文本和圖像的系統。 這樣的搜索引擎將允許用戶通過多模式搜索界面表達他們的輸入查詢,從而實現更自然和直觀的搜索體驗。
在電子商務網站上,多模式搜索引擎將允許從索引數據庫中檢索相關文檔。 通過測量可用產品與以多種格式(例如文本、圖像、音頻或視頻)的給定查詢的相似性來評估相關性。 因此,這個搜索引擎是一個多模式系統,因為它的底層機制能夠同時處理不同的輸入模式,即格式。
例如,搜索查詢可以採用“花裙”的形式。 在這種情況下,網上商店有大量的花卉連衣裙。 但是,搜索引擎返回的禮服並不真正讓用戶滿意,如下圖所示。
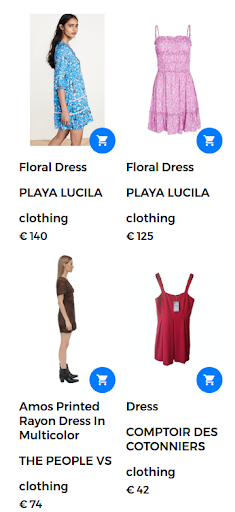
查詢“floral dress”的返回結果。
為了提供良好的搜索體驗並返回高度相關的結果,多模式搜索引擎能夠在單個查詢中組合文本和圖像。 在這種情況下,用戶提供所需產品的樣本圖像。 將此搜索作為多模式搜索運行時,輸入圖像是下圖所示的花卉連衣裙。

用於多模式查詢的用戶提供的圖像。
在這種情況下,查詢的第一部分保持不變(花裙),第二部分將視覺方面添加到多模式查詢中。 返回的結果產生與用戶提供的花卉連衣裙相似的連衣裙。 在此用例中,可以使用完全相同的連衣裙,因此是與其他類似連衣裙一起返回的第一個結果。
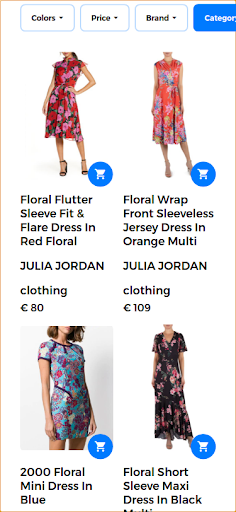
響應多模式查詢返回的相關搜索結果。
媽媽
谷歌推出了一項新技術來幫助用戶完成複雜的搜索任務。 這項名為 MUM 的新技術代表多任務統一模型,能夠打破語言障礙並跨網頁和圖片等不同內容格式解釋信息。
Google Lens是首批利用將圖像和文本組合成一個查詢的優勢的產品之一。 在搜索上下文中,MUM 將使用戶更容易在用戶提供的圖像中找到特定的花卉圖案等圖案。
MUM 是理解信息的新 AI 里程碑,如下所示:
“雖然我們處於探索 MUM 的早期階段,但它是邁向未來的重要里程碑,谷歌可以理解人們自然交流和解釋信息的所有不同方式。”
要了解有關 Google 的 MUM 多模式搜索的更多信息,請查看此網絡故事: 
跨語言擴展搜索
雖然圖像與語言無關,但搜索詞是特定於語言的。 設計多語言系統的任務歸結為跨多種語言構建語言模型。
多語言搜索
當前搜索系統的一個關鍵限制是它們檢索以用戶編寫搜索查詢的語言編寫或註釋的文檔。通常,這些引擎僅支持英語。 這種單語搜索引擎限制了這些系統在查找用不同語言編寫的有用信息方面的有用性。
另一方面,多語言系統接受一種語言的查詢並檢索以其他語言編制索引的文檔。 實際上,如果搜索系統能夠通過將用一種語言編寫的文檔內容或標題與另一種語言的文本查詢相匹配,從而從數據庫中檢索相關文檔,那麼它就是多語言的。 匹配技術的範圍從語法機製到語義搜索方法。
將不同語言的句子與視覺概念配對是促進跨語言視覺語言模型使用的第一步。 好消息是,所有人類幾乎都以相同的方式解釋視覺概念。 這些系統能夠整合來自多於一種來源和多於一種語言的信息,稱為多模式多語言系統。 然而,圖像-文本配對並不總是適用於大規模的所有語言,如下一節所述。
[案例研究] 通過頁面 SEO 推動新市場的增長
 閱讀案例研究
閱讀案例研究從媽媽到壁畫
將先進的深度學習和自然語言處理技術應用於搜索引擎的努力越來越多。 谷歌展示了一項新的研究工作,允許用戶使用圖像來表達單詞。 例如,“valiha”一詞指的是一種由管古箏製成的樂器,由馬達加斯加人演奏。 這個詞沒有直接翻譯成大多數語言,但可以很容易地用圖像來描述。
這個名為 MURA 的新系統代表 Multimodal, Multi-task Retrieval Across Languages。 它允許解決一種語言中的單詞可能無法直接翻譯成目標語言的問題。 由於這些問題,許多預訓練的多語言模型將無法找到語義相關的單詞或準確地將單詞翻譯成資源不足的語言或從資源不足的語言中翻譯出來。 事實上,MURAL 可以解決許多現實世界的問題:
- 用不同語言傳達不同心理含義的詞:一個例子是英語和印地語中的“婚禮”一詞,它傳達了不同的心理圖像,如下圖所示來自谷歌博客。
- 網絡上資源不足語言的數據稀缺性:網絡上90% 的文本圖像對屬於前 10 名資源豐富的語言。

圖像取自維基百科,歸功於 Psoni2402(左)和 David McCandless(右)並獲得 CC BY-SA 4.0 許可。

減少查詢的歧義並為資源不足的語言的圖像-文本對稀缺問題提供解決方案是對由人工智能驅動的下一代搜索引擎的另一項改進。
多語言和多模式搜索在行動
在這項工作中,我們使用現有的工具和可用的語言和視覺模型來設計一個多模態多語言系統,該系統超越了單一語言,並且一次可以處理多個模態。
首先,要設計一個多語言系統,在語義上連接來自不同語言的單詞很重要。 其次,為了使系統具有多模態,有必要將語言的表示與圖像相關聯。 因此,這是朝著多模式搜索多語言的長期目標邁出的一大步。
上下文
這種多模式多語言系統的主要用例是在給定同時結合圖像和文本的查詢的情況下從數據集中返回相關圖像。 在這種情況下,我們將展示一些示例來說明各種多模式和多語言場景。
這個演示應用程序的主幹由開源神經搜索生態系統 Jina AI 提供支持。 由深度神經網絡信息檢索(或神經 IR)提供支持的神經搜索是構建多模式系統的一種有吸引力的解決方案。 在這個演示中,我們使用 Hugging Face 的 MPNet Transformer 架構 multilingual-mpnet-base-v2 來處理文本描述和字幕。 至於視覺部分,我們使用 MobileNetV2。
接下來,我們將展示一系列測試來展示多語言和多模式搜索引擎的強大功能。 在展示我們的演示工具的結果之前,這裡列出了描述這些測試的關鍵元素:
- 該數據庫由 1k 幅描繪人們演奏音樂的圖像組成。 這些圖像取自公共數據集 Flickr30K。
- 每張圖片都有一個用英文寫的標題。
第 1 步:從英文文本查詢開始
首先,我們從反映大多數搜索引擎當前運行方式的文本查詢開始。 查詢是“音樂家組”。
查詢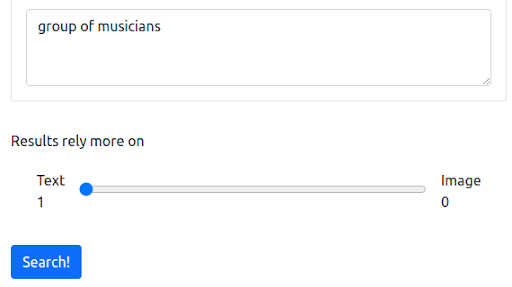
結果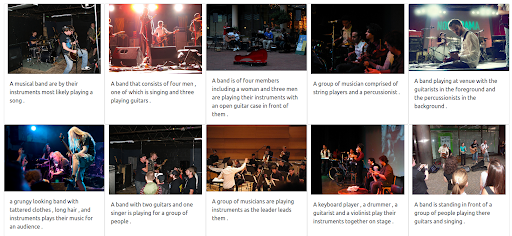
我們基於 Jina 的演示搜索引擎返回與輸入查詢語義相關的音樂家圖像。 然而,這可能不是我們想要的音樂家類型。
第 2 步:添加多模態
現在讓我們通過發出一個結合了先前文本查詢和圖像的查詢來添加一些多模態。 該圖像更準確地代表了我們正在尋找的音樂家。
首先,UI 需要支持發出這種類型的查詢。 然後,我們必須分配一個權重來平衡每個模態在檢索結果時的重要性。 在這種情況下,文本和圖像都具有相同的權重 (0.5)。 正如我們在下面看到的,新的搜索結果包括許多在視覺上與輸入圖像查詢相似的圖像。
查詢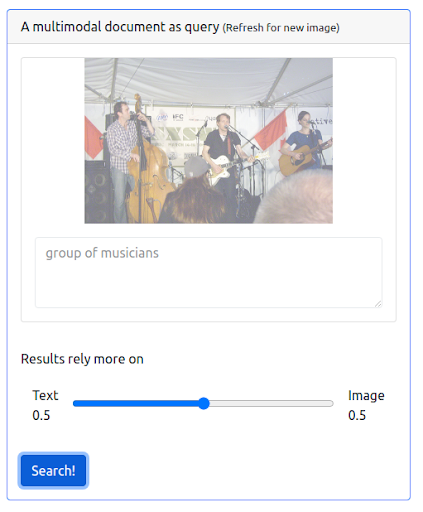
結果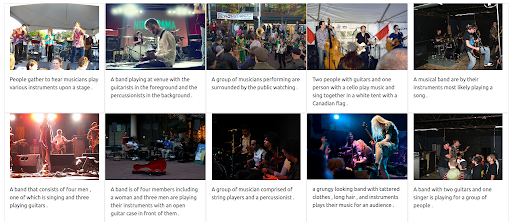
第 3 步:為圖像分配最大權重
也可以為圖像賦予最大權重。 這樣做會從查詢中排除輸入文本。 在這種情況下,返回更多與輸入圖像在視覺上相似的圖像並將其排在第一位。 要記住的一件事是,結果僅限於數據集中可用的圖像。
查詢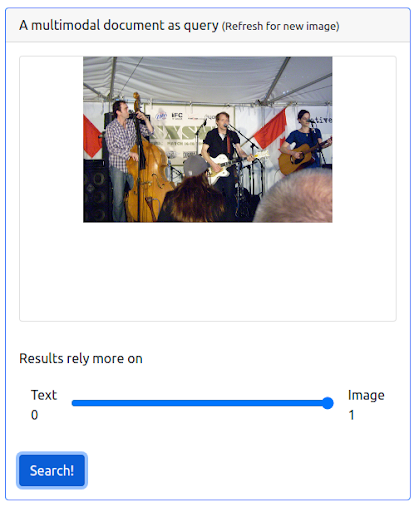
結果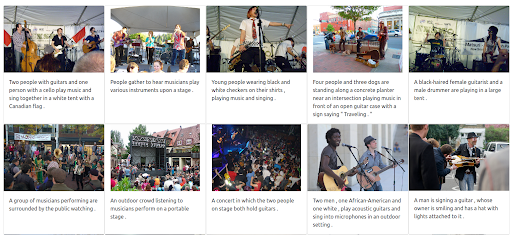
第 4 步:測試多語言搜索
現在讓我們嘗試發出相同的查詢,但使用不同的語言。 為了說明這個多語言系統的全部功能,文本的權重被最大化。 請記住,圖片的標題只有英文。 重複搜索以涵蓋以下語言:
- 法語: Groupe de musiciens
- 意大利語: Gruppo di musicisti
- 德語: Gruppe von Musikern
無論輸入查詢的語言是什麼,返回的結果都是相關的,並且在三種語言中是一致的。 結果如下所示。
法語查詢的結果
意大利語查詢的結果
德語查詢的結果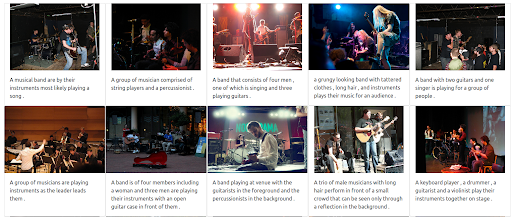
多模式多語言搜索的未來
未來幾年,人工智能將越來越多地改變搜索方式,並為人們提供表達查詢和探索信息的全新方式。 正如穀歌已經宣布的那樣,通過 MUM 了解信息是人工智能的一個里程碑。 未來更多由人工智能驅動的系統將包括功能和改進,從提供更好的搜索體驗到回答複雜的問題,從打破語言障礙到將不同的搜索模式組合到一個查詢中。