
評估因果影響預測的質量
已發表: 2022-02-15CausalImpact 是 SEO 實驗中最流行的軟件包之一。 它的受歡迎程度是可以理解的。
SEO 實驗為 SEO 提供了令人興奮的見解和方法來報告其工作的價值。
然而,任何機器學習模型的準確性都取決於它所提供的輸入信息。
簡而言之,錯誤的輸入可能會返回錯誤的估計。
在這篇文章中,我們將展示 CausalImpact 是多麼可靠(和不可靠)。 我們還將學習如何對您的實驗結果更有信心。
首先,我們將簡要概述 CausalImpact 的工作原理。 然後,我們將討論 CausalImpact 估計的可靠性。 最後,我們將學習一種可用於估計您自己的 SEO 實驗結果的方法。
什麼是因果影響,它是如何工作的?
CausalImpact 是一個包,它使用貝葉斯統計來估計在沒有實驗的情況下事件的影響。 這種估計稱為因果推斷。
因果推理估計觀察到的變化是否由特定事件引起。
它通常用於評估 SEO 實驗的性能。
例如,當給定事件的日期時,CausalImpact (CI) 將使用乾預前的數據點來預測干預後的數據點。 然後它將預測與觀察到的數據進行比較,並以一定的置信度閾值估計差異。
此外,控制組可用於使預測更準確。
不同的參數也會對預測的準確性產生影響:
- 測試數據的大小。
- 實驗前的時間長度。
- 選擇要與之比較的對照組。
- 季節性超參數。
- 迭代次數。
所有這些參數都有助於為模型提供更多上下文並提高其可靠性。
爬行BI
 發現
發現為什麼評估 SEO 實驗的準確性很重要?
在過去的幾年裡,我分析了許多 SEO 實驗,有些事情讓我印象深刻。
很多時候,在相同的測試集和乾預日期上使用不同的對照組和時間框架會產生不同的結果。
為了說明,下面是同一事件的兩個結果。
第一個返回了統計上的顯著下降。 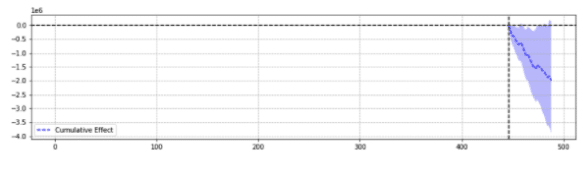
第二個沒有統計學意義。 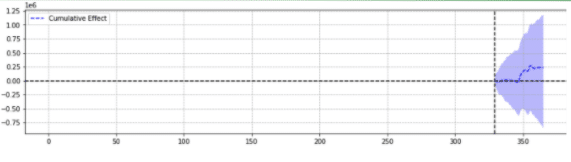
簡單地說,對於同一個事件,根據選擇的參數返回不同的結果。
人們不得不懷疑哪種預測是準確的。
最後,“統計顯著性”不應該增強我們估計的信心嗎?
定義
為了更好地了解 SEO 實驗的世界,讀者應該了解 SEO 實驗的基本概念:
- 實驗:為檢驗假設而進行的程序。 在因果推理的情況下,它有一個特定的開始日期。
- 測試組:應用更改的數據子集。 它可以是整個網站或網站的一部分。
- 對照組:未應用更改的數據子集。 您可以擁有一個或多個控制組。 這可以是同一行業中的單獨站點,也可以是同一站點的不同部分。
下面的示例將有助於說明這些概念:
修改標題(實驗)應該會使五個城市(測試組)的產品頁面的有機點擊率增加 1%(假設)。 將使用所有其他城市(對照組)的未更改標題來改進估計。
準確 SEO 實驗預測的支柱
- 為簡單起見,我整理了一些有趣的見解,供 SEO 專業人士學習如何提高實驗的準確性:
- CausalImpact 中的一些輸入將返回錯誤的估計,即使在統計上顯著。 這就是我們所說的“假陽性”和“假陰性”。
- 沒有一個通用規則來管理對測試集使用哪個控件。 需要進行實驗來定義用於特定測試集的最佳控制數據。
- 使用具有正確控制和正確長度的前期數據的 CausalImpact 可以非常精確,平均誤差低至 0.1%。
- 或者,使用帶有錯誤控制的 CausalImpact 可能會導致很高的錯誤率。 個人實驗顯示統計顯著變化高達 20%,而實際上沒有變化。
- 不是所有的東西都可以測試。 一些測試組幾乎從不返回準確的估計。
- 有或沒有對照組的實驗在干預之前需要不同長度的數據。
並非所有測試組都會返回準確的估計值
一些測試組總是會返回不准確的預測。 它們不應該用於實驗。
具有較大異常流量變化的測試組通常返回不可靠的結果。
例如,同一年某網站進行了網站遷移,受新冠肺炎疫情影響,部分網站因技術錯誤連續 2 週“無索引”。 在該站點上進行實驗將提供不可靠的結果。
上述要點是通過使用下述方法進行的一系列廣泛測試收集的。
不使用控制組時
- 使用控件而不是簡單的 pre-post 可以將估計精度提高多達 18 倍。
- 使用之前 16 個月的數據與使用 3 年的數據一樣精確。
使用控制組時
- 使用正確的控件通常比使用多個控件更好。 但是,在控件的流量變化很大的情況下,單個控件會增加錯誤預測的風險。
- 選擇正確的控制可以將精度提高 10 倍(例如,一個報告 +3.1%,另一個報告 +4.1%,而實際上它是 +3%)。
- 測試數據和控制數據之間的大多數相關流量模式不一定意味著更好的估計。
- 使用之前 16 個月的數據不如使用 3 年精確。
實驗前註意數據長度
有趣的是,在對對照組進行實驗時,使用 16 個月之前的數據會導致非常高的錯誤率。
事實上,在沒有實際變化的情況下,錯誤可能與估計流量增加 3 倍一樣大。
然而,使用 3 年的數據消除了該錯誤率。這與簡單的事後實驗形成對比,後者的錯誤率並未通過將長度從 16 個月增加到 36 個月而增加。
這並不意味著使用控件是不好的。 情況恰恰相反。
它只是顯示了添加控制如何影響預測。
當對照組有很大的變化時就是這種情況。
對於在過去一年中出現異常流量變化(關鍵技術錯誤、COVID 大流行等)的網站來說,這一點尤為重要。
如何評估因果影響預測?
現在,CausalImpact 庫中沒有內置準確度分數。 因此,必須以其他方式推斷。

人們可以看看其他機器學習模型如何估計其預測的準確性,並意識到平方和誤差 (SSE) 是一個非常常見的指標。
平方和誤差或殘差平方和計算期望值 (yi) 和實際結果 (f(xi)) 之間的所有 (n) 差異的平方和。 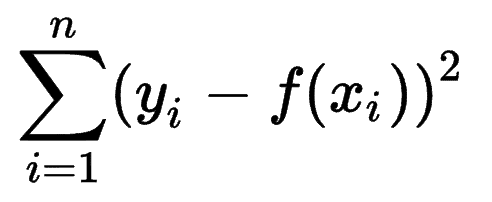
SSE 越低,結果越好。
挑戰在於,對於 SEO 流量的事前實驗,沒有實際結果。
儘管現場沒有進行任何更改,但某些更改可能超出了您的控制範圍(例如,Google 算法更新、新競爭對手等)。 SEO 流量也沒有固定數量的變化,而是逐漸上下變化。
SEO 專家可能想知道如何克服這一挑戰。
引入假變體
為了確定一個事件引起的變化的大小,實驗者可以在不同的時間點引入固定的變化,看看 CausalImpact 是否成功地估計了變化。
更好的是,SEO 專家可以為不同的測試組和對照組重複該過程。
使用 Python,在後期的不同干預日期將固定變化引入數據。
然後在 CausalImpact 報告的變異和引入的變異之間估計平方誤差之和。
這個想法是這樣的:
- 選擇測試和控制數據。
- 在不同日期對真實數據進行虛假干預(例如,增加 5%)。
- 將 CausalImpact 估計值與每個引入的變體進行比較。
- 計算平方和誤差 (SSE)。
- 對多個控件重複步驟 1。
- 為實際實驗選擇具有最小 SSE 的對照
方法論
使用下面的方法,我創建了一個表,我可以用它來確定哪個控件在不同時間點具有最佳和最差錯誤率。
首先,選擇一個測試和控制數據並引入從 -50% 到 50% 的變化。
然後,運行 CausalImpact (CI) 並將 CI 報告的變化減去您實際引入的變化。
之後,計算這些差異的平方並將所有值相加。
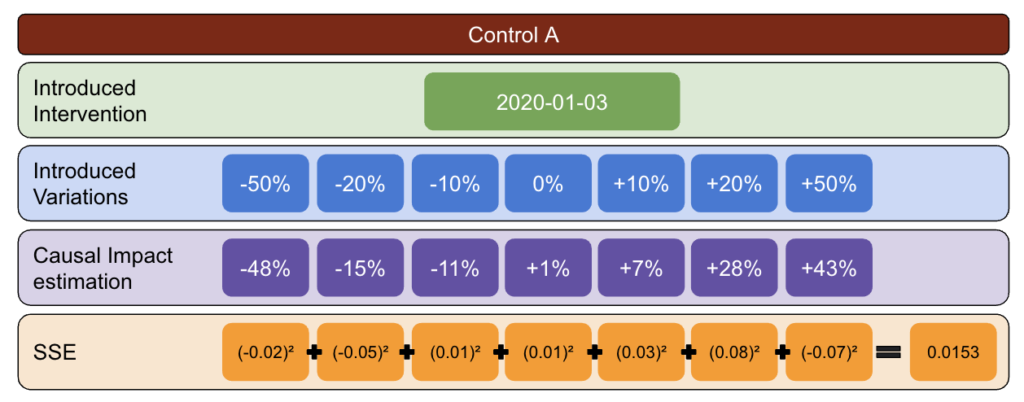
接下來,在不同的日期重複相同的過程,以降低因特定日期的實際變化而導致偏差的風險。
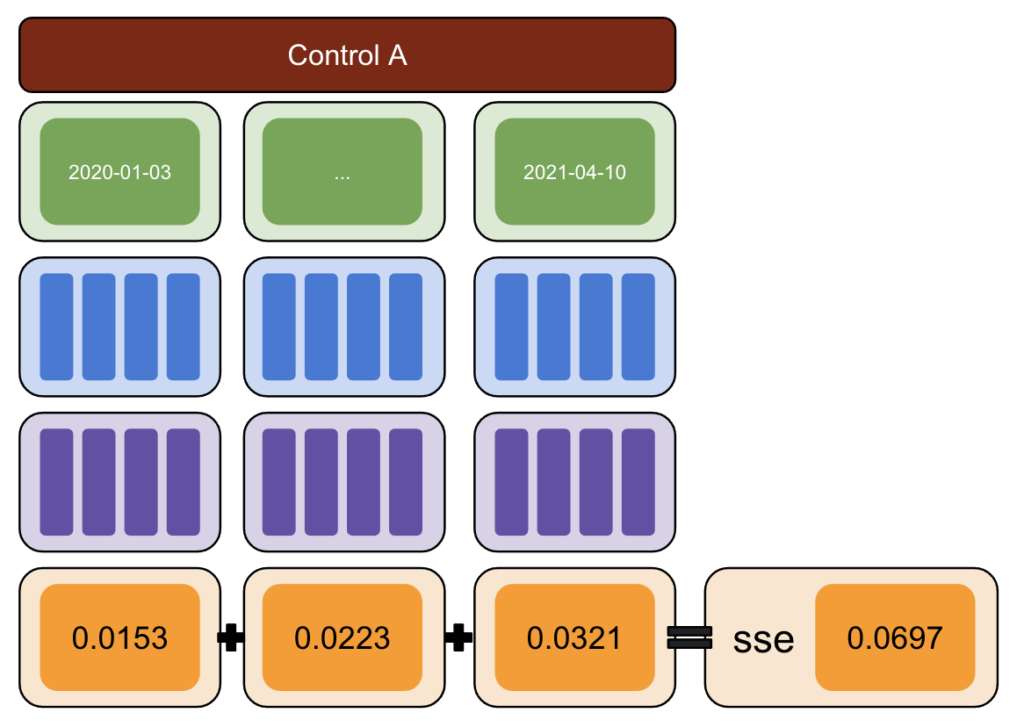
再次,重複多個對照組。
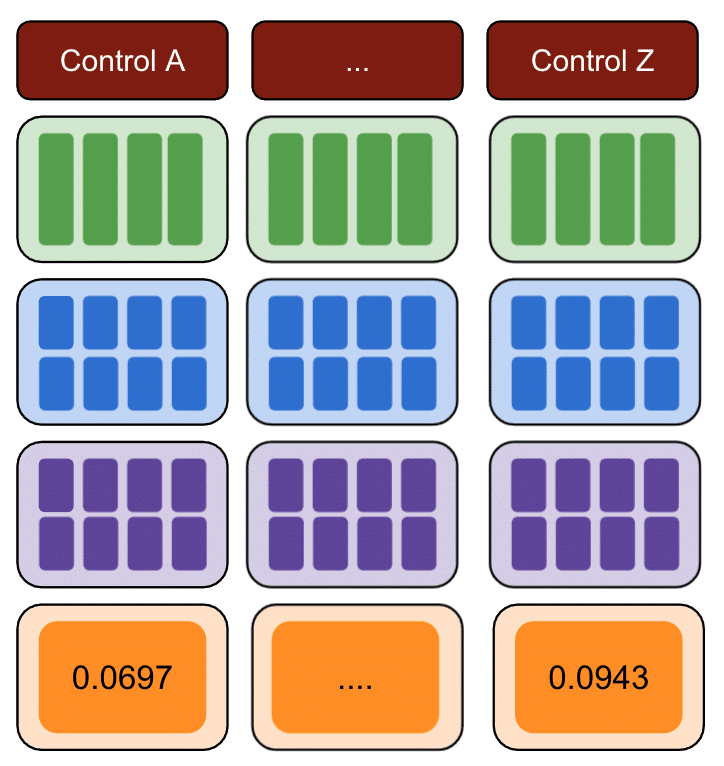
最後,誤差平方和最小的控制組是用於測試數據的最佳控制組。
如果您對每個測試數據重複每個步驟,結果會有所不同。
在結果表中,每一行代表一個對照組,每一列代表一個測試組。 裡面的數據是SSE。
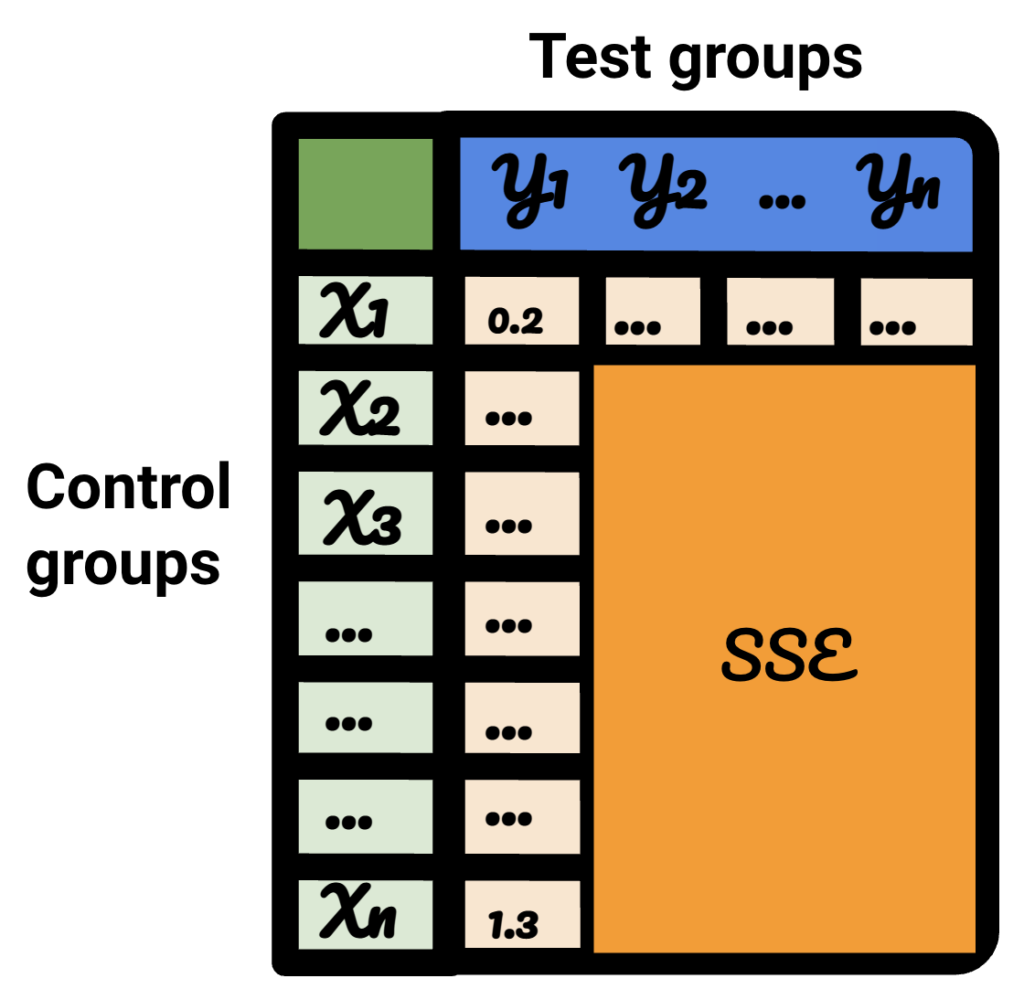
對該表進行排序,我現在確信,對於每個測試組,我都可以為其選擇最佳控制組。
我們應該使用控制組嗎?
有證據表明,與簡單的事前發布相比,使用對照組有助於獲得更好的估計。
然而,只有當我們選擇正確的控制組時,這才是正確的。
估計期應該多長?
答案取決於我們選擇的控件。
當不使用對照時,16 個月前的實驗似乎就足夠了。
使用對照時,僅使用 16 個月可能會導致大量錯誤率。 使用 3 年有助於降低誤解的風險。
我們應該使用 1 個控件還是多個控件?
該問題的答案取決於測試數據。
與多個對照相比,非常穩定的測試數據可以表現良好。 在這種情況下,這很好,因為使用大量控制可以減少模型受到其中一個控制中意外波動的影響。
在其他數據集上,使用多個控件可以使模型的精度比使用單個控件低 10-20 倍。
SEO社區中有趣的工作
CausalImpact 不是唯一可用於 SEO 測試的庫,上述方法也不是測試其準確性的唯一解決方案。
要了解替代解決方案,請閱讀 SEO 社區中人們分享的一些令人難以置信的文章。
首先,Andrea Volpini 寫了一篇關於使用 CausalImpact Analysis 測量 SEO 有效性的有趣文章。
然後,Daniel Heredia 介紹了 Facebook 的 Prophet 包,用於使用 Prophet 和 Python 預測 SEO 流量。
雖然 Prophet 庫比實驗更適合預測,但值得學習各種庫以牢牢掌握預測世界。
最後,我對 Sandy Lee 在 Brighton SEO 上的演講感到非常高興,他分享了對 SEO 測試的數據科學的見解,並提出了 SEO 測試的一些陷阱。
做 SEO 實驗時要考慮的事情
- 第三方 SEO 拆分測試工具很棒,但也可能不准確。 選擇解決方案時要徹底。
- 儘管我過去曾寫過它,但除非在服務器端,否則您無法使用 Google 跟踪代碼管理器進行 SEO 拆分測試實驗。 最好的方法是通過 CDN 進行部署。
- 測試時要大膽。 CausalImpact 通常不會接受小的變化。
- SEO 測試不應該總是您的首選。
- 除了測試較小的更改(例如標題標籤)之外,還有其他方法。 Google Ads A/B 測試或平台 A/B 測試。 真正的 A/B 測試比 SEO 拆分測試更準確,通常可以更深入地了解標題的質量。
可重現的結果
在本教程中,我想專注於如何在不知道如何編碼的情況下提高 SEO 實驗的準確性。 此外,數據的來源可能會有所不同,並且每個站點都不同。
因此,我用來生成此內容的 Python 代碼不在本文的討論範圍之內。
但是,通過邏輯,您可以重現上述實驗。
結論
如果您從這篇文章中只有一個收穫,那就是因果影響分析可能非常準確,但總是很遙遠。
對於希望使用此軟件包的 SEO 了解他們正在處理的內容非常重要。 我自己的旅程的結果是,如果不首先在輸入數據上測試模型的準確性,我不會相信 CausalImpact。