
Crawl over Crawl 現在可用
已發表: 2019-11-21我們的 Crawl over Crawl 功能允許您比較兩種不同的抓取並顯示抓取演變。
2016 年,它建立在我們之前發布的“趨勢”的基礎上,讓您有機會發現不同抓取之間的全球趨勢。 現在,您可以訪問您的 SEO 改進的完整視圖,並突出顯示給定主題的爬網之間的差異。 Crawl over Crawl 更新包括新類型的圖表來讀取您的數據。
2019 年,Crawl over Crawl 功能得到了改進。 您現在可以檢查:
- 包含相同或相似頁面的網站的兩個版本,例如生產與臨時網站,或移動與桌面版本。
- 同一個網站在兩個不同的時間點,比如網站發生變化之前和之後。
比較網站的兩個版本
為了比較兩個網站,OnCrawl 會查看您為兩個不同的爬網提供的起始 URL,以確定不同網站的網址的差異。 它假定這兩個版本的網站包含相同(或幾乎相同)的內容。 這意味著您要比較的兩個域、文件夾或子域中的大多數 URL 段必須是相同的。
以下是一些可以比較的網站示例:
| 用例 | 抓取 1 – 起始 URL | 抓取 2 – 起始 URL |
|---|---|---|
| 生產與暫存站點 | https://www.example.com | http://staging.example.com/site/ |
| 桌面與移動網站 | https://www.example.com | https://m.example.com |
| 區域版本 | https://www.example.com/en-us/ | https://www.example.com/en-ca/ |
| 區域版本 | https://www.example.com | https://www.example.co.uk |
對於起始 URL 之間的複雜差異,自動匹配可能不夠。 如果是這種情況,您會在設置爬網時看到一個錯誤,要求您通過聊天聯繫 OnCrawl。 我們能夠覆蓋自動匹配以適應您的具體情況。
在兩個不同時間點比較一個網站
要在兩個不同的時間點比較一個網站,例如網站改進或重大更改前後,您需要提供:
- 相同的起始 URL
- 相同的爬取寬度(相同的子域探索規則)
如何在爬行中設置爬行
您可以在兩個現有爬網之間運行 Crawl over Crawl,或者在創建新爬網時請求與以前的爬網進行比較。 更多關於創建 Crawl over Crawl 的信息可以在 OnCrawl 的知識庫中找到。
如何閱讀 Crawl over Crawl sunburst
您可以像閱讀傳統餡餅一樣閱讀旭日形文字。 這些圖形對於跟踪網站的演變、一次次抓取或檢查網站的兩個版本之間的差異(例如,在實時版本之間和在重組期間)非常有用。
此多級餅圖可讓您根據給定主題比較兩次爬網:
- 第一級和內圈:顯示屬於第一次爬網(舊爬網)的頁面。
- 二級外圈:顯示內圈各段對應的二次爬取(較新的)的頁面。
因此,您可以輕鬆地找到,例如,第一次爬網中不再出現在第二次爬網中的可索引頁面,反之亦然。
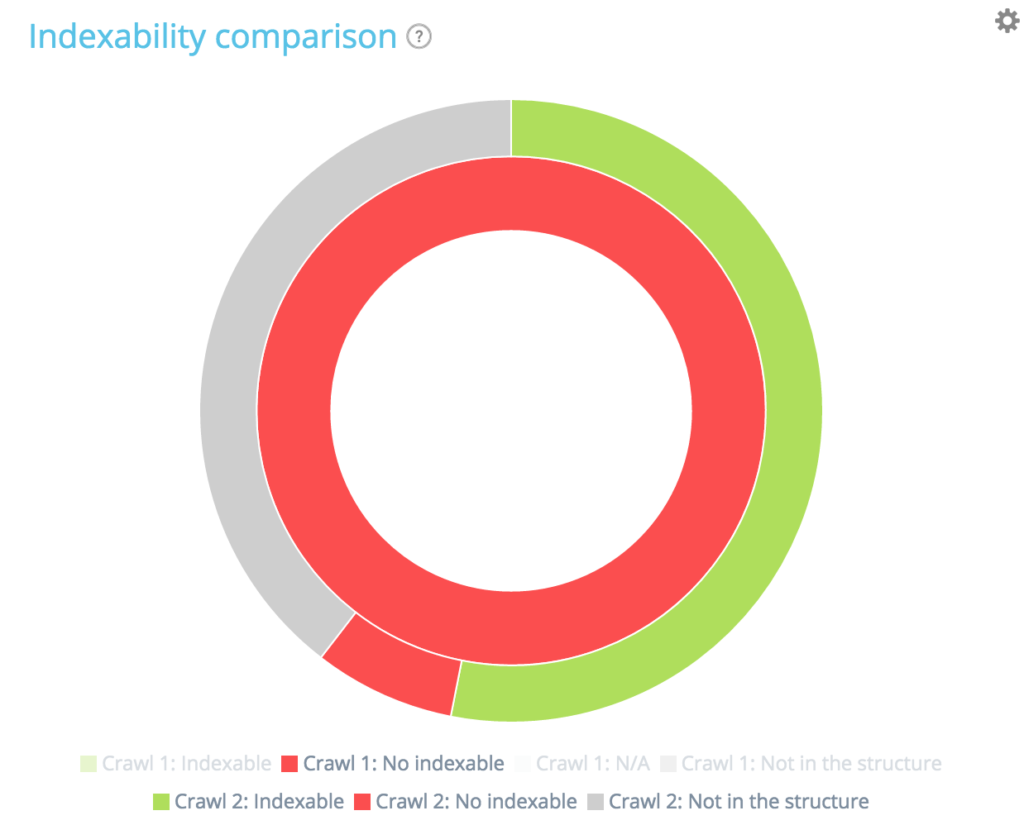
在此圖表中,內圈顯示了從第一次抓取的角度(較舊的角度)對頁面的重新分區。 您可以看到有可索引的頁面,沒有可索引的頁面以及不在第一次爬網但出現在第二次(灰色部分)中的頁面。
然後,對於內圈的每個部分,您可以在第二次抓取中看到頁面對給定部分的重新分區。 內部灰色部分錶示那些頁面在第一次爬網中不存在,但出現在第二次爬網中(外部綠色和紅色部分屬於內部灰色部分)。
灰色部分錶示頁面在結構中是新的還是不存在的,具體取決於它們屬於哪個區域。
通過單擊圖例,您可以決定要顯示或關注哪些數據。 Crawl 2 提供了更全球化的視圖。
讓我們看看內圈。
第一次爬網中頁面的可索引性分佈
 第一次爬網包含 10854 個可索引頁面和 177 個不可索引頁面。 僅在第二次爬取中發現了 1 661 個頁面。
第一次爬網包含 10854 個可索引頁面和 177 個不可索引頁面。 僅在第二次爬取中發現了 1 661 個頁面。

現在看看外圈。 對於第一個圈的每個段,我們在第二次爬取中找到這些頁面的分佈。
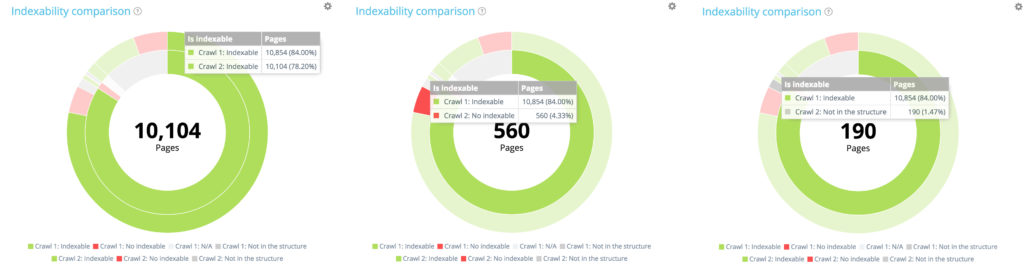
在第一次爬網的 10 854 個可索引頁面中,只有 10 104 個在第二次爬網中仍可索引。 560 個現在不可索引,190 個頁面在第二次抓取時不再是可抓取網站的一部分。
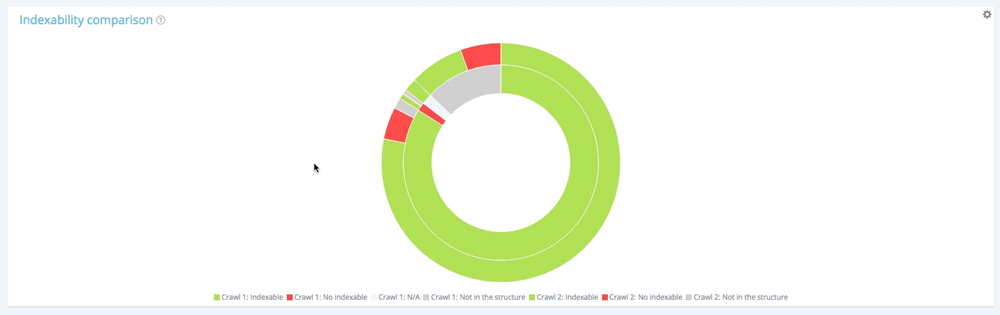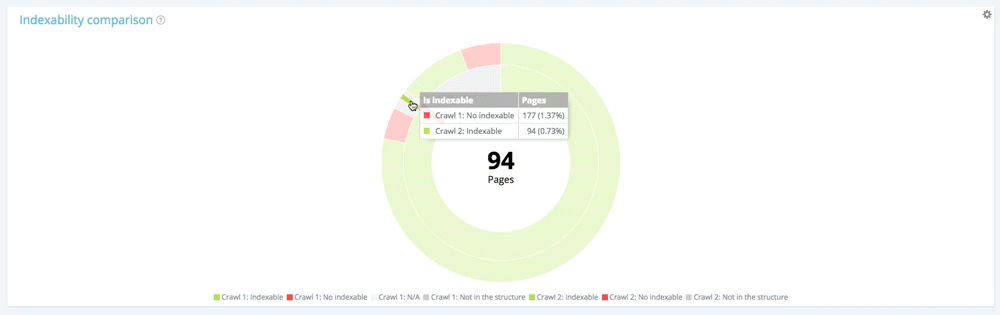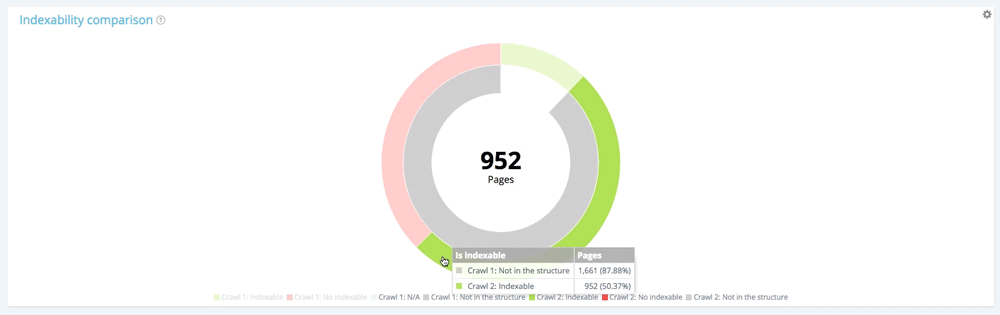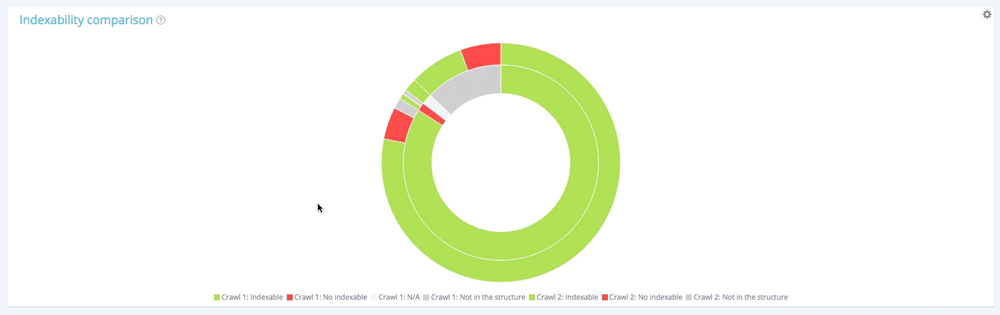
讓我們關註一個小部分:第一次爬取的不可索引頁面
通過使用圖例隱藏第一次爬取時可索引的頁面和不在網站結構中的頁面,我們可以只專注於第一次爬取時不可索引的頁面。
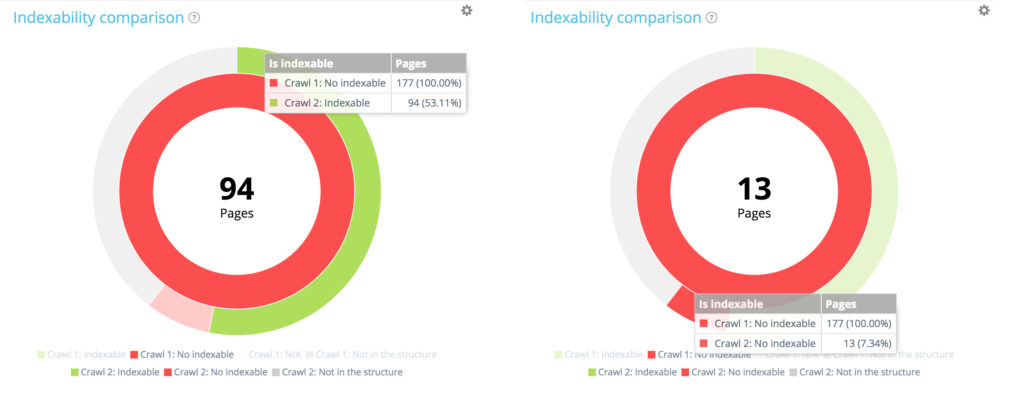 在第一次爬網的 177 個不可索引頁面中,現在有 94 個可以在第二次爬網中索引,13 個仍然可以索引。
在第一次爬網的 177 個不可索引頁面中,現在有 94 個可以在第二次爬網中索引,13 個仍然可以索引。
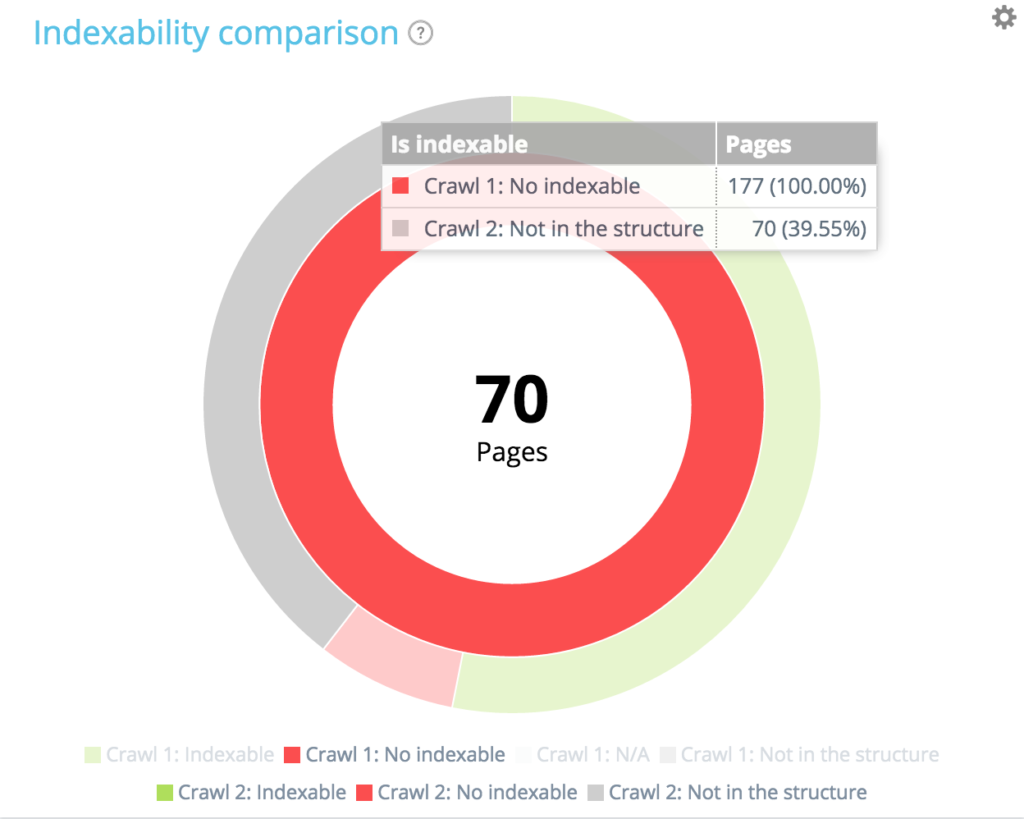
在第一次爬網中的 177 個不可索引頁面中,有 70 個在第二次爬網中不再存在。 94 + 13 + 70 = 177。我們從第一次抓取中找到了 177 個不可索引頁面的預期細分。
關注新頁面:僅在第二次抓取中找到的頁面
現在讓我們使用圖例從第一次爬網中隱藏可索引和不可索引的頁面,並僅顯示在此爬網期間不屬於網站結構的頁面。 這使您可以根據索引查看新頁面的狀態。
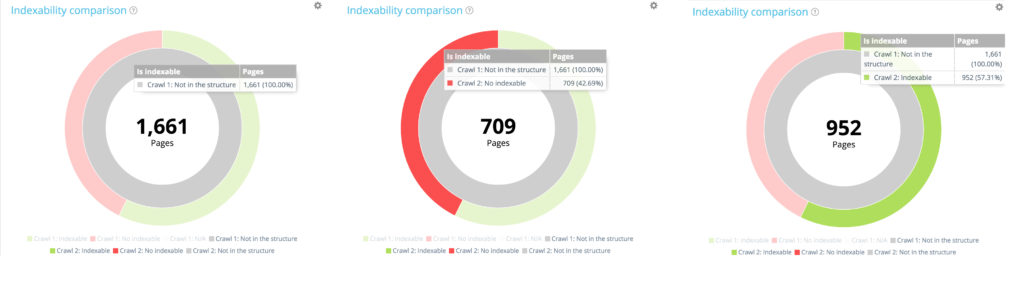
所有新頁面:1 661 頁。
在 1 661 個新創建的頁面中,有 709 個不可索引。
在 1661 個新創建的頁面中,952 個是可索引的。
摘要:第二次抓取的所有頁面
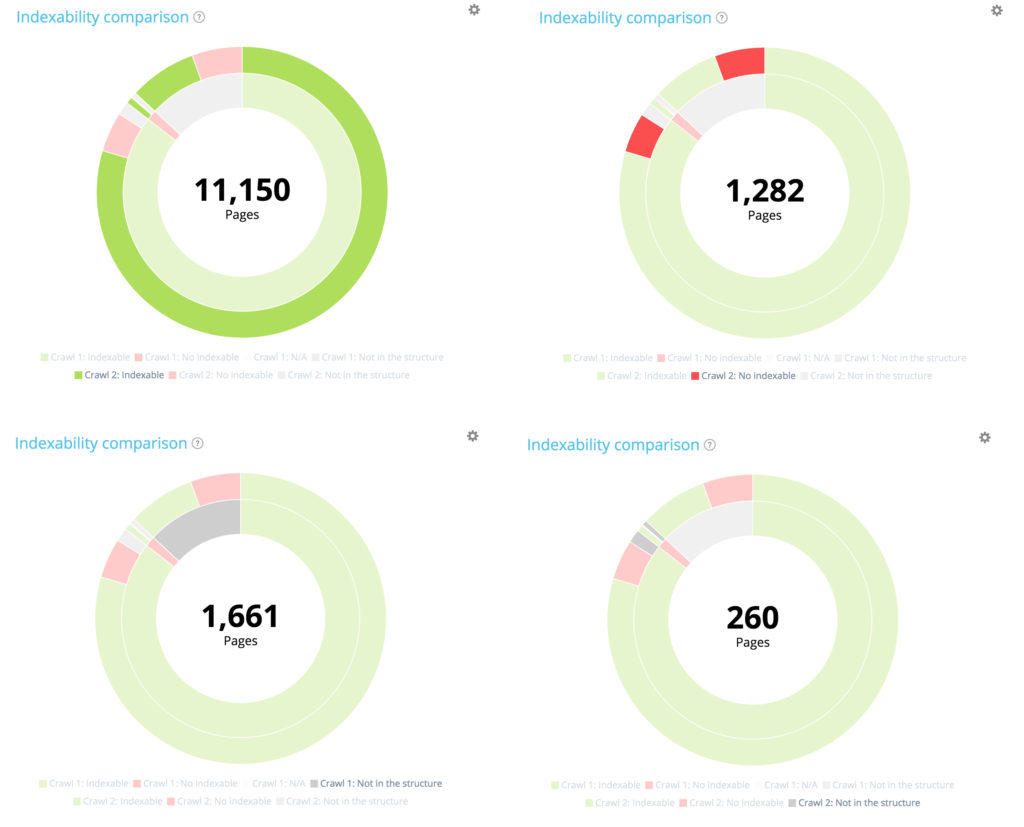 在第一次爬網中,有 10104 個頁面是可索引的。 11 150 現在可以在第二個中進行索引。 177 個頁面在第一次爬網中不可索引,但現在有 1282 個頁面在第二次爬網中不可索引。
在第一次爬網中,有 10104 個頁面是可索引的。 11 150 現在可以在第二個中進行索引。 177 個頁面在第一次爬網中不可索引,但現在有 1282 個頁面在第二次爬網中不可索引。
已創建 1661 個頁面,並已從結構中刪除 260 個頁面。
Crawl over Crawl:可用數據
此新功能按業務專業知識劃分並在以下選項卡之間:
- 結構
- 內部鏈接
- 內容
- 狀態碼
- 表現
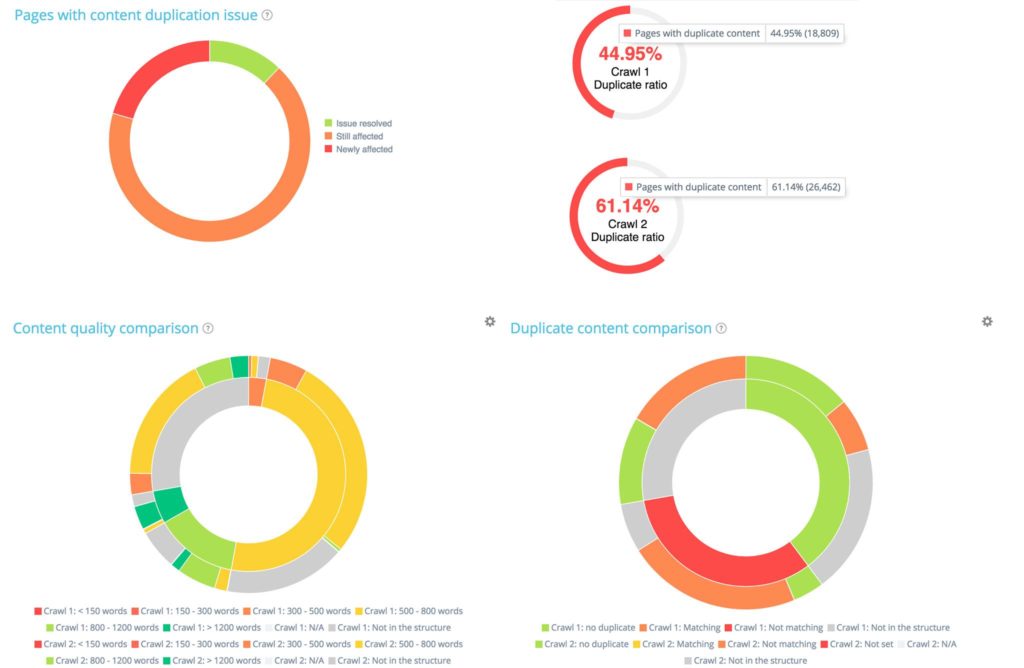
例如,在“內容”部分,您會發現兩個抓取之間的重複差異非常重要:
此外,您可以分析兩次爬網之間的頁面深度有何不同。 在下圖中,您可以看到深度差異:
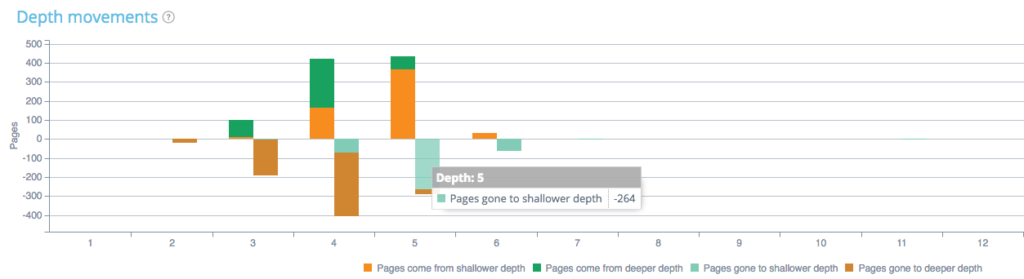
例如,如果我們查看深度 5,我們可以看到進入較淺或較深深度的頁面,或者在爬行 1 和 2 之間來自較淺或較深深度的頁面。這裡,在爬行 1 和深度 5 中的 264 個頁面已進入較淺的深度(深度 4、3 或 2)。
這只是對可用內容的概述。 我們的數據瀏覽器還可以讓您深入了解 700 多個指標以進行爬網比較。