
優化 SEO 的構面過濾器
已發表: 2019-11-26在包含產品列表的大量頁面的網站上,分面搜索是一個反復出現的問題; 如果實施得當,分面搜索對網站非常有益。 事實上,創建新的、更具體的頁面可以響應更多的搜索查詢,從而提高搜索結果的可見性。
除了提供邏輯站點架構和優化的內部鏈接外,分面導航還允許用戶快速找到他們正在尋找的產品。
分面搜索的實現必須遵循一定的規則。 否則,可能會導致重大問題,例如大量創建不必要/重複的頁面或出現蜘蛛陷阱。
什麼是面?
分面搜索通常可以在電子商務或房地產網站的列表頁面上找到:這種類型的搜索是指用戶可以選擇以優化搜索的不同特徵組合。
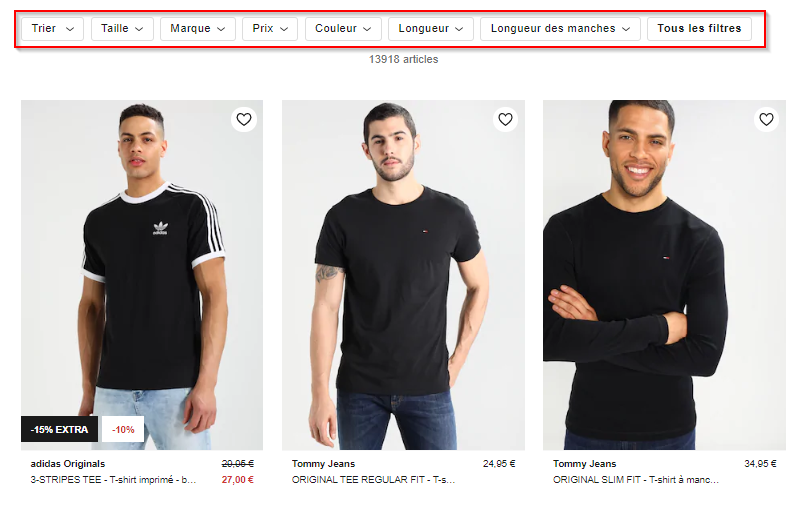
Zalando 上男士 T 恤的多面導航示例
在可用的組合中,區分構面和過濾器很重要。
方面:這是一個過濾的類別頁面,應該是爬行友好和可索引的。 它對應於用戶具有一定搜索量的查詢,它的創造為網站帶來了價值和潛在的流量。
過濾器:這是一個僅為用戶過濾的類別頁面。 無法匹配每月搜索量的查詢; 它只允許用戶使類別頁面更準確並瀏覽產品的不同屬性。
為什麼要創建分面?
如上所述,分面導航對於具有大量包含產品/屬性列表的頁面的網站是有益的。 優化管理的方面策略將具有 3 個主要優點:
- 定位通用或長尾關鍵字。 因此,創建面向特定請求的構面並提出相應屬性的列表是很有趣的。
- T 卹:每月 74,000 次搜索量
- 男士 T 卹:每月 9,900 次搜索量
- 男士黑色 T 卹:每月搜索量 590
- 根據一定的規則自動創建頁面:由於適用的站點通常有大量頁面,自動創建頁面是一個優勢;
- 通過自動創建這些頁面的內部鏈接自動化。
如何選擇創建哪些方面?
要選擇最有益的方面進行創建,遵循 3 個步驟很重要:
語義研究:經典語義研究,收集與網站相關的關鍵詞;
分類:根據通常的方法對關鍵詞進行分類,考慮到不同的相關方式來分解方面(例如價格、尺寸、品牌、性別、材料等)
結果分析:使用突出不同類別和可能組合的數據透視表分析語義研究結果。 這個想法是確定與每個可能的交叉相關的搜索量。
例如,為 T 卹類別中的某些顏色創建構面將是有益的:

抓取和索引:為什麼需要控制構面的創建?
如果分面導航正確實現,它將增加用戶和機器人的合格頁面數量,但如果不正確,則會導致幾種類型的問題:
- 蜘蛛陷阱的風險:
蜘蛛陷阱是創建大量或無限數量的 URL,以防止站點被正確瀏覽。 由於分面導航允許您創建大量重要的組合,如果管理不當,很容易導致蜘蛛陷阱。
- 爬行廢物:
網站結構中大量不可索引的鏈接必然會導致爬取浪費(即使從長遠來看,這些鏈接會被更少爬取)。
- 稀釋內部人氣:
網站結構內的大量不可抓取鏈接可能會損害內部人氣的分佈。
- 創建重複或接近重複的內容:
分面搜索自動創建的某些頁面具有相同或非常相似的內容。 應避免這種情況,以免創建內部重複內容。
- 創建空白頁面:
與內容相似的頁面一樣,不應生成沒有內容的頁面。
控制構面創建要遵循的規則
管理多個方面
首先,您需要定義如果同時選擇多個變量(無論是否在同一類別中),是否應創建一個構面
示例:創建性別 + 顏色方面
示例:當選擇了男裝 + 童裝時,不要創建性別方面
示例:不要創建性別 + 模式方面

定義產品/商品的最小數量
僅當產品/商品數量足夠時才應自動創建構面
示例:當至少有 3 件待售 T 卹時,創建性別(男式或女式)方面

文本:
類別頁面
男士方面
女性方面
至少有 3 件男士 T 卹
沒有3 件女士 T 卹
設置 SEO 標籤
創建的構面必須包含經典的 SEO 優化標記,因此有必要定義自動標記規則。
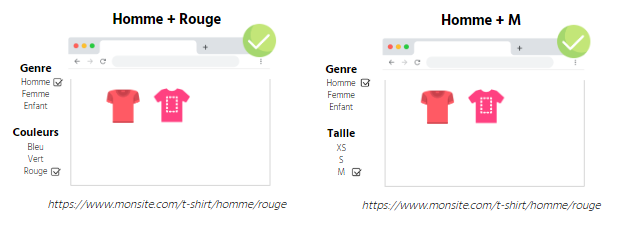
文本:
男裝+紅
男裝 + M
性別:男裝、女裝、兒童裝
顏色:藍色、綠色、紅色
性別:男裝、女裝、兒童裝
尺碼: XS, S, M
| 刻面 | H1 | 標題規則 | 描述規則 |
| 性別+顏色 | [性別] [顏色] T 卹 | [性別] [顏色] T 卹 – 我的品牌 | 在 Mysite.com 上發現我們所有的 ➤ [性別] [顏色] T 卹! 免費送貨✚ 1 500 款! |
| 性別+尺寸 | [性別] [尺碼] T 卹 | [性別] [尺碼] T 卹 – 我的品牌 | 在 Mysite.com 上發現我們所有的 ➤ [性別] [尺碼] T 卹! 免費送貨✚ 1 500 款! |
設置 URL 重寫
由於構面最初是您要索引的過濾器,因此在打開索引時將創建“醜陋”的 URL。 然後必須重寫這些 URL 以獲得“乾淨”的 URL(即沒有特殊字符,例如 %、? 或 &)。

示例:我正在尋找耐克的黑色T 卹

這些“乾淨”的 URL 針對抓取和索引進行了優化
管理 URL 穩定性
URL 結構不得根據用戶所遵循的路徑而改變。
示例:兩個人正在尋找一件黑色耐克品牌 T 卹,但方式不同。

因此,有必要定義一個默認順序,例如:[服裝類別] > [顏色] > [品牌] 並保持此順序而不管用戶的路徑如何。
優化內部鏈接
與傳統的站點結構一樣,要使開放構面可抓取和索引,該站點的 URL 必須具有指向該開放構面的永久鏈接。 後者必須存在於 DOM 中並且即使 JavaScript 和 CSS 被禁用也可以訪問。
示例:已創建男士+彩色T 恤的刻面
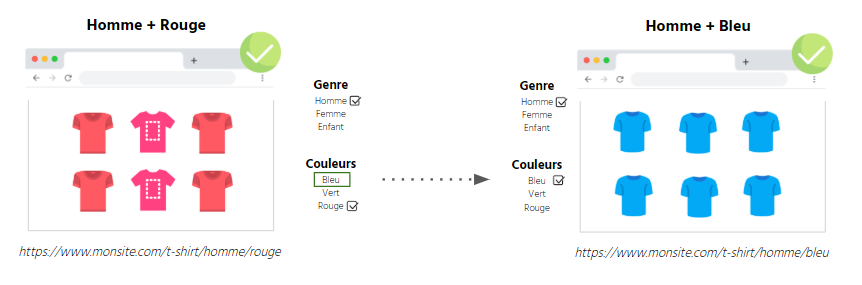
Men's blue t-shirts 我確實有一個“靜態”鏈接<a href =”https://mysite.com/t-shirts/mens/blue”>男士藍色 T 卹使構面無法訪問的幾種方法
既然我們已經討論了有關創建構面的規則,我們需要定義一種方法來使不應創建的構面不可抓取/不可索引。
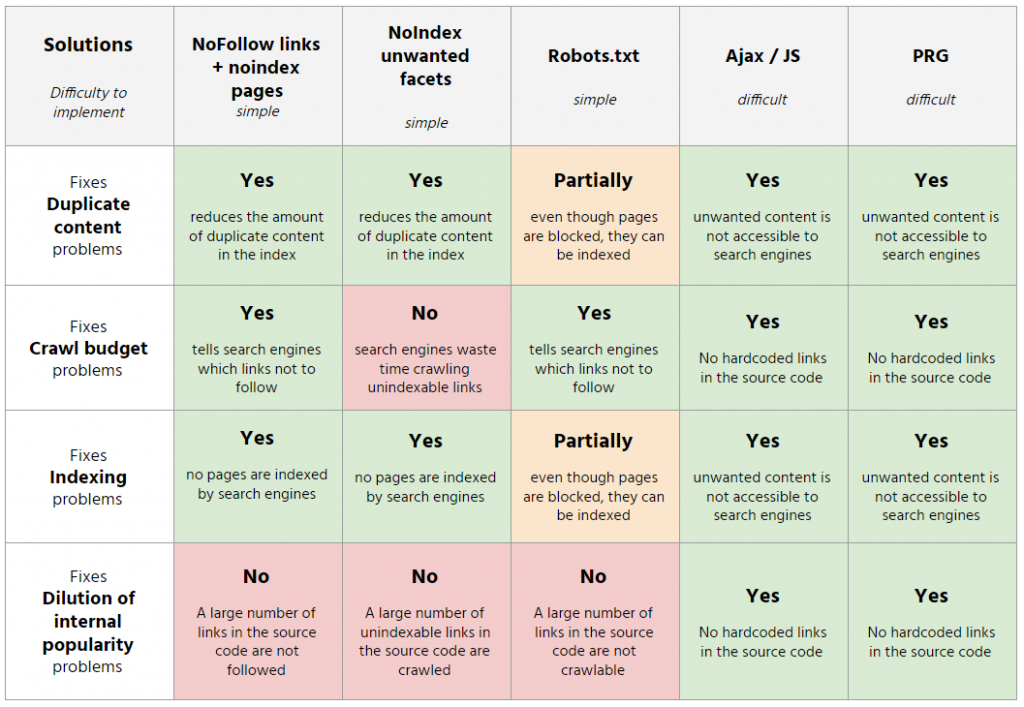
通常,可以通過多種方式阻止不需要的方面,每種方式都有其優點和缺點。
- 在不需要的方面鏈接上添加 nofollow + 元機器人 noindex
此解決方案限制了不需要的頁面上的爬網浪費,並確保關閉的頁面不會被索引(如果它們通過其他方式被搜索引擎知道)。 但是,這並不能解決內部人氣稀釋的問題,因為頁面上存在大量不可抓取的鏈接。
- 在不需要的頁面上添加元機器人 noindex
使用這種方法,只能解決索引和重複內容問題。 事實上,爬蟲的浪費和內部人氣的稀釋仍然會出現在網站上。
- 使用 robots.txt 阻止構面
通過使用 robots.txt 阻止不需要的方面的模式,一種易於設置的解決方案。 儘管此選項可以避免在無用頁面上浪費爬網預算,但它不提供涉及索引、重複內容和稀釋內部流行度的解決方案。
- JS/阿賈克斯
使用 Javascript / Ajax 來阻止 facets 可以讓我們有效地解決所有問題。 事實上,不需要的方面的鏈接只有用戶可以訪問,並且不存在於頁面的源代碼中,因此機器人無法訪問它們。 請注意,Google 執行 Javascript,並且此解決方案的理想實現是在客戶端完成的:類別頁面的過濾應直接在瀏覽器中進行,並且不會創建新頁面。
- PRG(Post-Redirect-Get):就像使用JS/Ajax一樣,這種方法可以高效地解決所有問題。 提醒一下,GET 請求允許在 URL 中傳輸信息,並且可由 Google 執行。 另一方面,對於 POST 請求,信息包含在表單中,Google 無法執行。
因此,PRG 方法的目的是在 POST 模式下使用表單來處理不需要的方面,以便 Google 不會執行它們。 這將產生:
第 1 步 POST:用戶單擊不需要的方面的過濾器,然後使用 POST 方法發送請求。
第 2 步 REDIRECT:服務器通過重定向到過濾後的 URL 來響應請求。
步驟 3 GET:遵循重定向,過濾後的 URL 使用 GET 方法返回。 用戶會看到過濾後的結果。
[案例研究] 處罰後網站重新設計的監控和優化
 閱讀案例研究
閱讀案例研究總結
綜上所述
為了順利進行構面創建,有必要遵循幾條規則並在預生產環境中為所有可能的情況進行計劃。 同樣重要的是要注意,構面管理特定於站點上使用的 CMS,並且有不同的解決方案來管理創建和限制構面,每種都有優點和缺點。