
為什麼 OnCrawl 不僅僅是桌面爬蟲:深入了解我們基於雲的 SEO 平台
已發表: 2018-12-06OnCrawl 是圍繞 2015 年排名第一的法國電子商務玩家的 SEO 需求而構建的。這意味著我們必須在短時間內擴展我們的分析並處理一個擁有超過 5000 萬個 URL 的網站。 你會說,對於新玩家來說很難嗎? 實際上,我們僅在研發上就花費了 150 萬歐元並且以前支持不同的數據項目的基礎設施使這一切變得容易。 由於桌面爬蟲和基於雲的爬蟲之間的區別有時仍不清楚,我們認為解釋為什麼 OnCrawl 提供的不僅僅是簡單的桌面爬蟲可能是有用的——從高擴展能力到第三方集成和分析速度。
擴展到無窮大和超越
由於運行它們的計算機的資源和內存,桌面爬蟲的爬取能力有限。 他們很可能會被限制為每次抓取僅抓取幾千個 URL。 雖然這對於小型網站來說是可以的,但與 SaaS(軟件即服務)爬蟲相比,爬取這些 URL 仍然需要更多時間。 基於雲的爬蟲分佈在許多服務器上,因此您不受機器速度和大小的限制。
這意味著沒有我們無法處理的爬行。 我們一直在為小型網站和大型網站工作,包括一些財富 500 強公司。 正如介紹中所說,我們在法國最大的電子商務網站 Cdiscount 要求我們為他們構建一個自定義解決方案以在一次抓取中處理他們 50M+ 的 URL 和 SEO 需求之後開發了我們的 SEO 爬蟲。 此外,我們的擴展能力使我們連續兩年成為歐洲搜索獎的最佳 SEO 工具,這是搜索行業的領先盛典。 目前,我們每天和每個網站收集多達 2500 萬個 URL,或每月大約 10 億個網頁和 1500 億個鏈接。 您可以在此處詳細了解我們的技術以及我們如何處理 GDPR 政策。
自定義速度,廣泛的功能
由於我們的應用程序是基於雲的,因此您無需考慮機器的資源和速度能力。 這也意味著對時間或可以啟動的爬網數量沒有限制。 您可以在訂閱允許的範圍內啟動盡可能多的抓取,並在抓取時執行其他操作。 使用基於雲的解決方案還意味著您可以關閉應用程序窗口並等待抓取完成——它可以自行運行,不需要您的監視。 OnCrawl 讓您可以根據您的 SEO 需求安排抓取,無論您需要每週或每月抓取一次您的網站。 如果您需要更快,您還可以決定加快分析速度。
由於 OnCrawl 應用程序可用於抓取任何網站,因此我們的機器人將遵循在目標網站上找到的 robots.txt 文件中表示的 Crawl-Delay 指令(如果有)。
否則,我們將抓取速度限制在每秒 1 頁的速度,因此我們的機器人不會對目標網站過於激進。
當網站的 Crawl-Delay 指令高於 1 時,我們的應用程序會發出警告,告訴您抓取速度將低於請求的速度。
如果 Crawl-Delay 高於 30,我們會顯示錯誤。 我們根本不允許您配置具有如此高的抓取延遲的抓取。
在這些情況下設置爬網的唯一方法是使用虛擬 robots.txt 文件。
為此,您必須首先使用您的 Google Analytics(分析)帳戶驗證該項目,這樣我們才能確保您對要抓取的域擁有某種所有權。
我們有一些不同的參數可讓您控制抓取:
- 加快爬行速度
- 暫停、停止、重新啟動或中止爬網
- 當我們的機器人訪問您的站點時,安排一次爬網以避免高峰流量時間並減輕您服務器上的壓力
- 實時查看已獲取的頁面,到目前為止我們檢索到的 URL 數量,並查看是否有任何問題會減慢您的抓取速度。
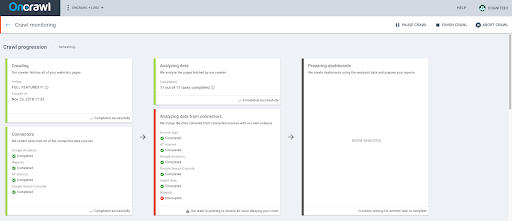
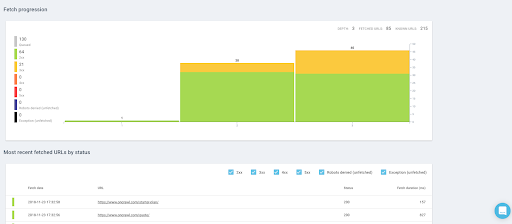
日誌文件分析變得容易
OnCrawl 不僅僅是一個簡單的 SEO 爬蟲。 在過去的幾年裡,我們還發布了一個強大的日誌文件分析器來解決其他 SEO 解決方案沒有發現的問題。
完整的日誌文件是您網站生命週期的完美反映。 無論是訪問者還是機器人、顯示的頁面還是對資源的調用,您網站上的任何活動都寫入其中。
借助 IP 地址、狀態碼、用戶代理、引薦來源網址和其他技術數據等信息,每行日誌(服務器端數據)都可以幫助您完成站點的分析,這通常基於分析(更多客戶端導向)。
我們的日誌文件分析器支持任何類型的日誌格式,從 IIS、Ngnix 上的 Apache 等標準格式到更多自定義格式。 沒有我們做不到的分析。 我們還讓我們的用戶直接從 Splunk、ELK / Elastic Stack、Amazon S3、OVH (ES) 或 Cloudflare 等第三方解決方案檢索他們的日誌數據。
這意味著您不會再像我們的一些競爭對手那樣被額外的第三方日誌文件管理器所困。
我們的界面使您可以輕鬆地通過安全和私有的 FTP 自動上傳您的日誌文件。 只需幾個步驟即可完成您的日誌文件分析。
您還可以實時監控正在處理的文件,看看是否有任何錯誤阻止了它們的上傳。
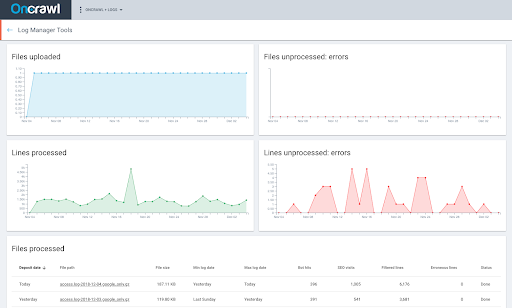
無限的第三方集成
OnCrawl 致力於使用領先的搜索營銷解決方案開發內置連接器,這些解決方案是 SEO 不可或缺的:Google Search Console、Google Analytics、Adobe Analytics 或 Majestic,僅舉幾例。 將這些解決方案集成到您的審核流程中並非多餘:它可以更全面地了解您的網站在搜索引擎上的性能和健康狀況,並闡明機器人和訪問者在您的網站上的真實行為。 您還可以節省時間和精力,因為您無需稍後在 Excel 電子表格中手動處理這些數據。
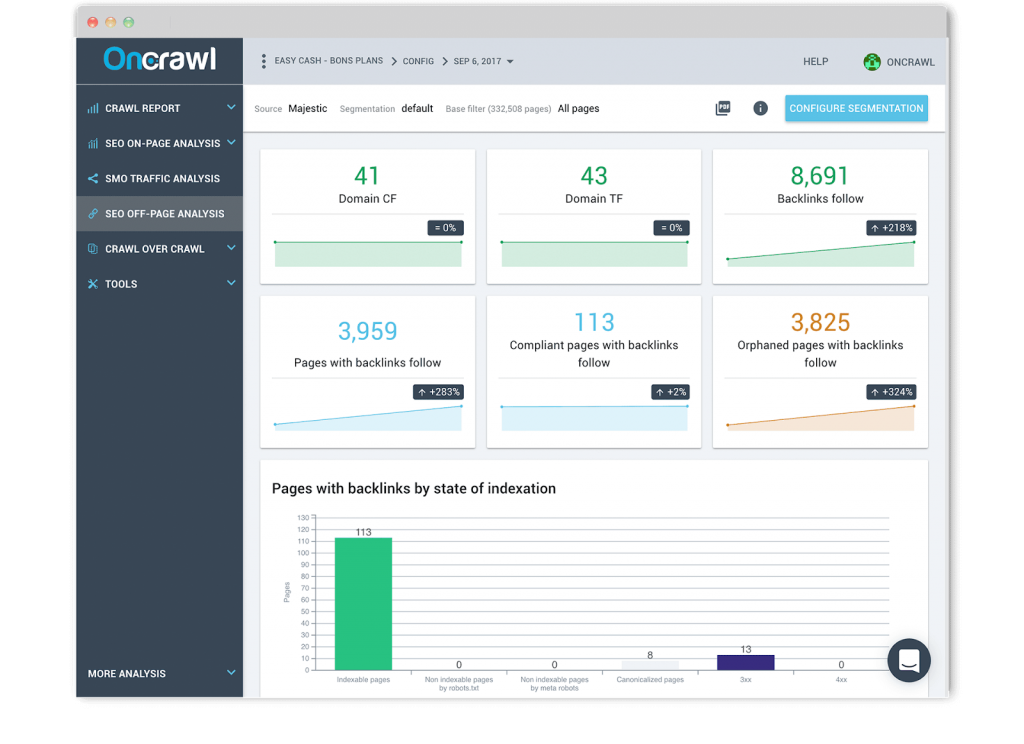
反向鏈接報告
我們與領先的鏈接智能解決方案 Majestic 建立了值得信賴的關係。 我們的交叉數據分析讓您可以將您的抓取數據和日誌數據與您的反向鏈接數據結合起來,以了解反向鏈接對您的 SEO 流量和抓取頻率的影響。 一旦您根據最重要的 KPI 設置了站點範圍的自定義頁面組細分。 您還可以可視化與頁麵點擊深度級別相關的反向鏈接數量,或檢查反向鏈接數量是否對 Google 的行為有影響。
我們提供的分析,其中反向鏈接數據在 URL 和機器人點擊級別上關聯和組合,是目前市場上唯一的分析。

排名報告
我們還為 Google Search Console 開發了一個獨特的連接器,以了解您的網站是如何被發現和編入索引的,以及您的頁面優化如何影響您的流量和索引。 我們提供有關您的關鍵字分佈、展示次數、點擊次數和點擊率隨時間變化的標準而詳盡的見解,無論是在桌面還是移動設備上,針對品牌或非品牌關鍵字,還是關於您的網頁組。 更重要的是,我們還提供了我們的競爭對手都沒有做到的獨特分析。
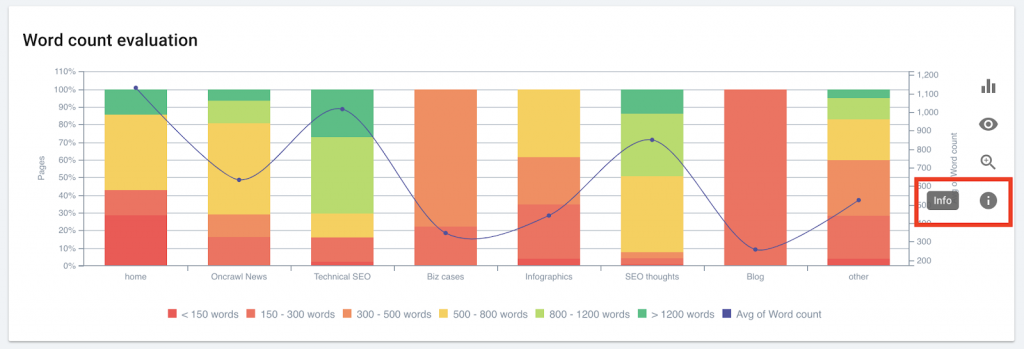
OnCrawl 使用您的細分和日誌文件中的數據來解釋您的排名數據。 因此,您可以識別排名頁面和不排名頁面的共同特徵,包括深度、內部流行度、字數、鏈接、加載時間和標題評估。 不僅如此,您還可以檢查描述長度和結構化數據對點擊率的影響。
最後,OnCrawl Rankings 可讓您大規模組合抓取、日誌文件和 Search Console 數據,以突出顯示排名頁面並了解抓取預算是否影響您的排名。 沒有其他爬網,無論是桌面還是基於雲的,都支持此類功能。
分析報告
我們讓您連接您的 Google Analytics 或 Adobe Analytics(前 Omniture),以了解頁面和技術 SEO 如何影響搜索引擎的自然流量性能。 我們幫助您監控網站每個部分的 SEO 流量性能和用戶行為。
CSV 攝取
雖然我們一直在努力與第三方解決方案進行新的集成,但我們不想讓您沒有運行技術 SEO 審核可能需要的特定類型的數據。 這就是為什麼我們允許您大規模上傳 CSV 文件(您可以上傳數百萬行)以在 URL 級別添加新的數據層。 您可以根據這些特定數據(排名、CRM、業務、Google Ads 數據等)構建您自己的細分和過濾器,以查看您最具戰略意義的頁面是否符合您的目標。
開放API,自定義分析
OnCrawl 基於圍繞 API 構建的平台。 OnCrawl REST API 用於訪問您的爬網數據以及管理您的項目和爬網。 要使用此 API,您需要擁有 OnCrawl 帳戶、有效訂閱和訪問令牌。
您可以創建自己的應用程序來非常輕鬆地請求此 API。 這可以使用用戶帳戶生成的 API 令牌或使用 OAuth 應用程序使用用戶帳戶連接到 OnCrawl 來完成。
使用我們的 API,您可以使用您喜歡的編程語言和平台編寫應用程序,充分利用 OnCrawl 的許多功能,部署在您自己的環境中。 這意味著您可以創建自定義儀表板,將我們的數據集成到其他平台,並在網站更新時自動觸發抓取。
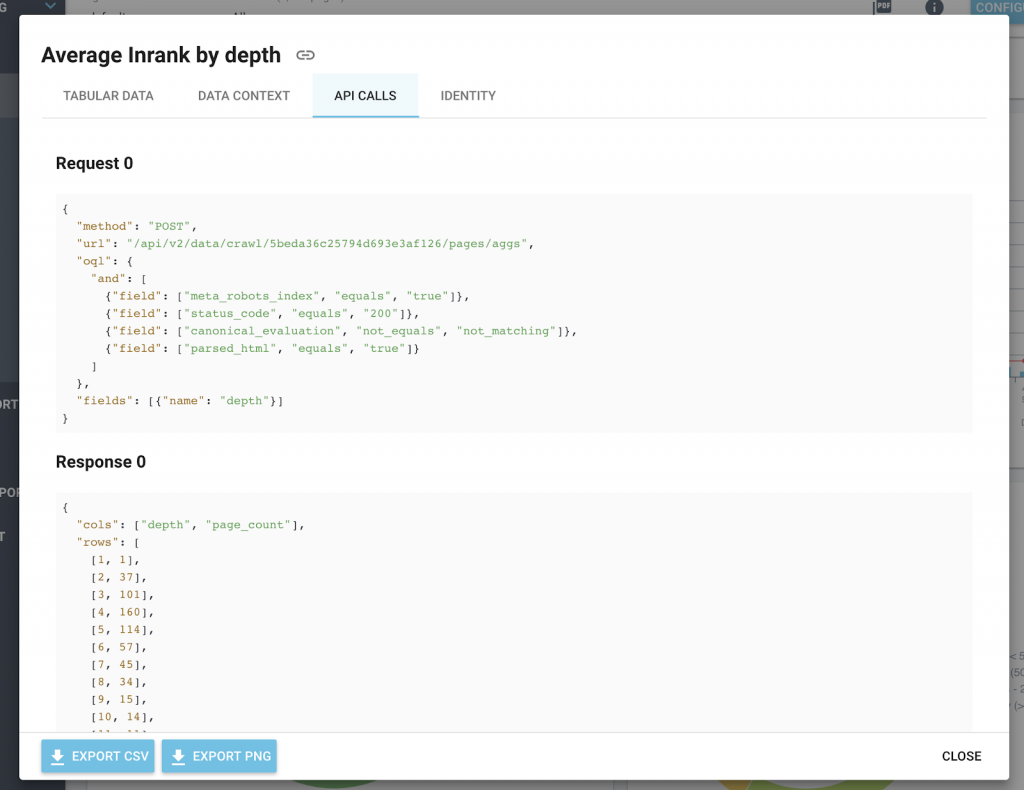
此外,為了讓您更輕鬆地進行集成,我們所有的圖表都在信息圖標中包含 API 調用和響應格式。
隨時間變化的趨勢和優化
OnCrawl 在您的項目中按日期組織您的爬網。 我們會在您的訂閱處於活動狀態時存儲您的爬網數據,這意味著您可以跟踪數月甚至數年的分析。 請注意,如果您使用我們的日誌監控功能,OnCrawl 應用程序會以您網站訪問者的 IP 地址形式處理個人數據。 需要此信息才能可靠地區分 Googlebot 和其他訪問者。 IP 地址不存儲在 OnCrawl 應用程序中。 此數據僅存在於您上傳到私人安全 FTP 的原始文件中。
我們還提供了廣泛的功能,讓您可以比較基於相同爬網配置的兩次爬網,以發現趨勢和隨時間的變化。 這是比較暫存版本和實時版本並檢查遷移過程中是否一切順利的好方法。
您還可以與隊友或客戶分享您的項目,這是證明優化價值和分享結果的好方法。
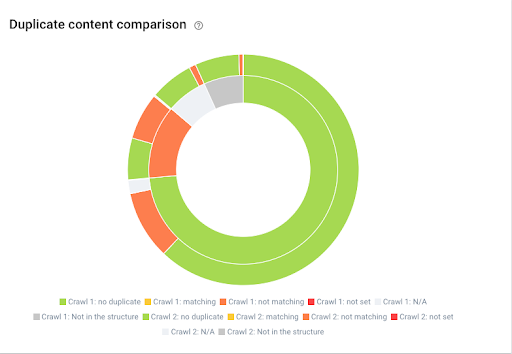
顯示兩次爬網之間重複內容的演變
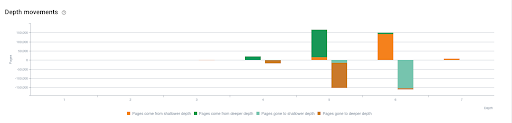
顯示兩次爬行之間深度運動的演變
無處不在的語義
創新是我們的核心 DNA,多年來我們一直致力於推廣技術 SEO。 OnCrawl 的首席技術官 Tanguy Moal 在自然語言處理問題上工作了超過 15 年,他幫助我們融合了語義和大數據技術,以理解網絡上可用的海量數據。 我們使用 Simhash 算法實現了第一個近乎重複的內容檢測器。
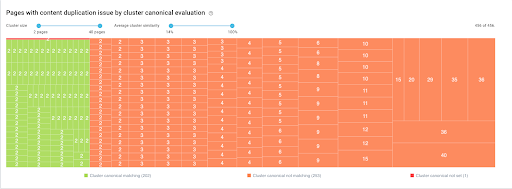
具有規範評估的相似頁面集群 - 集群可以按頁面數或內容相似性百分比進行過濾
我們最近還在研究熱圖內容檢測器,它可以幫助我們的用戶識別獨特內容的塊以及跨網頁和整個網站的重複百分比。 語義是我們 SEO 爬蟲的一部分:n-gram 分析從一開始就可以幫助您了解單詞序列在網站中的分佈方式。 我們是唯一具有這種語義功能的基於雲的爬蟲。 在對話式搜索查詢不斷增加的領域,語義 SEO 可幫助您通過有意義的元數據和語義相關內容來改善網站流量,這些內容可以明確地為特定搜索意圖提供答案。
OnCrawl 不僅僅是一個桌面爬蟲,它還提供無與倫比的大規模基於雲的 SEO 分析。 OnCrawl 允許您採取行動,真正了解搜索引擎在您網站上的行為,並自信地創建 SEO 策略。
不要相信我們的話。 親自嘗試並立即開始免費試用。