
如何使用 MMM 數據饋送電子表格自動化營銷組合建模
已發表: 2022-06-16營銷組合建模或 MMM 正在迎來復興,自它被普遍使用以來已有 60 多年的歷史。 與大多數營銷歸因方法不同,MMM 不需要用戶級別的數據,而是通過將支出的高峰和低谷統計映射到營銷渠道中的操作和事件來建模哪些渠道值得銷售。 從簡單的線性回歸升級到嶺回歸或貝葉斯方法等技術,營銷組合建模正在為現代重新發明。

想了解更多關於 MMM 的信息嗎?
閱讀有關營銷組合建模與歸因建模的優缺點
然而,有一些重大障礙需要克服。 根據 Meta/Facebook 的說法,構建模型可能需要 3 到 6 個月,該公司自 2021 年 10 月以來一直致力於其開源 MMM 庫。據估計,在建模開始之前,大約 50% 的時間用於收集和清理數據. 這與我在 Recast 以及之前在 Harry's 的經驗以及 CrowdFlower 研究的結果相吻合,該研究發現 60% 的數據科學時間用於清理和組織數據。
快進>>
- 數據清洗
- 建立營銷組合模型
- 自動化建模
數據清洗是60%的工作,如何做到0%
要構建準確的模型,您需要特定格式的數據。 準備好數據非常耗時,因此 MMM 項目花費的時間比他們需要的要長。 這使得 MMM 成為一項專業且昂貴的技能,因此大多數公司一年只能製造一到兩個模型。 如果您可以使用 Supermetrics 等工具自動執行該過程來構建 MMM 數據饋送,則可以定期更新模型,從而更好地優化營銷預算。
表格數據格式
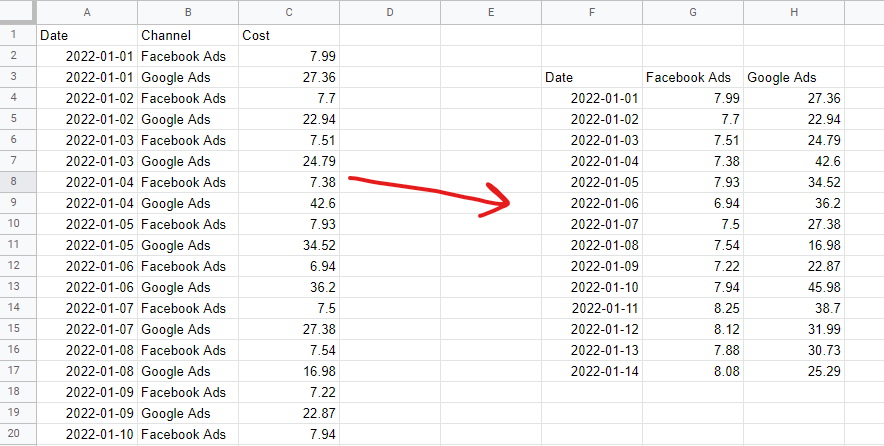
要構建營銷組合模型,您必須以未堆疊的表格格式佈置數據。 這意味著每次觀察一行——通常是幾天或幾週——和每個模型“特徵”一列——通常是媒體支出和有機或外部變量。 分類數據(例如,國定假日列表)需要編碼為虛擬變量——1 表示是那個假期,0 表示不是。
連接的數據源
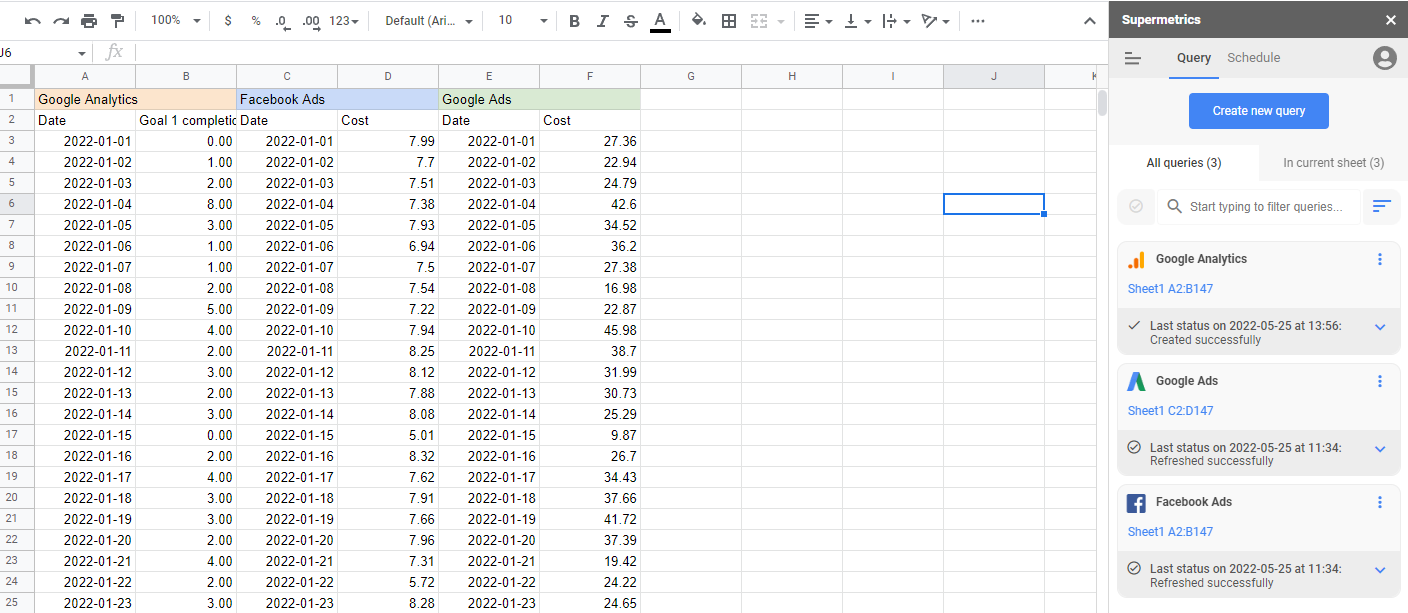
要構建營銷歸因模型,您需要將所有營銷數據放在一個位置。 這是 Supermetrics 自動為您處理的。 借助 90 多個連接器,您可以將所有營銷支出、事件和活動集中到一個地方,根據需要進行操作,然後導出為您需要的格式和位置。
導出到 Google 表格
擁有 Supermetrics 帳戶後,您只需轉到 Extensions > Add-ons > Get add-ons 並安裝它。 它會要求您使用鏈接到您的 Supermetrics 帳戶的 Google 帳戶進行身份驗證,然後邊欄將出現在擴展菜單中。
完成此操作後,您可以啟動側邊欄(如果尚未啟動)並單擊以創建新查詢。 查詢是您決定從哪些帳戶提取哪些數據的方式。 當您選擇 Facebook Ads 和 Google Ads 等廣告平台之一時,它會提示您進行身份驗證並授予 Supermetrics 訪問權限。
然後,您將選擇要從中提取數據的帳戶和日期範圍。 最後,選擇您的指標——通常是 MMM 的成本或展示次數——和維度——只選擇與表格格式一致的日期。
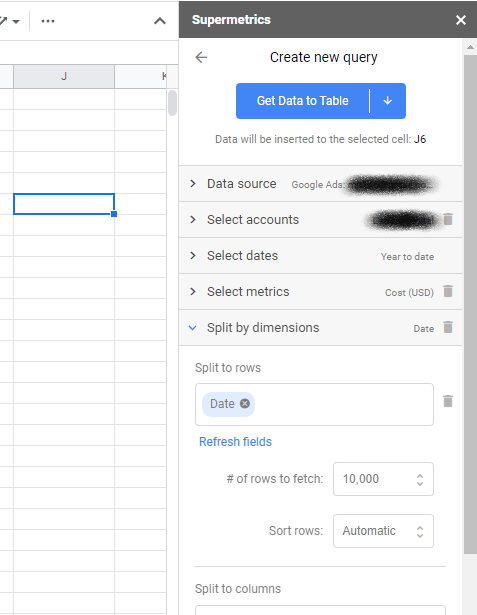
或者,如果您需要選擇一組特定的廣告系列,您可能需要添加過濾器。 例如,如果您的 YouTube 廣告系列名稱中有“YT:”,您可能希望選擇這些作為單獨的來源,然後為您的其他每個廣告系列類型複制查詢和過濾器。
完成查詢後,請確保您已選擇要將數據拉入的單元格,然後單擊“獲取數據到表”。 如果你犯了錯誤,只需複制查詢並將其放在正確的位置,刪除另一個。
我發現將每個來源的名稱放在表格上方的單元格中很有幫助,這樣我就知道我從哪裡提取數據。 結果應如下所示:
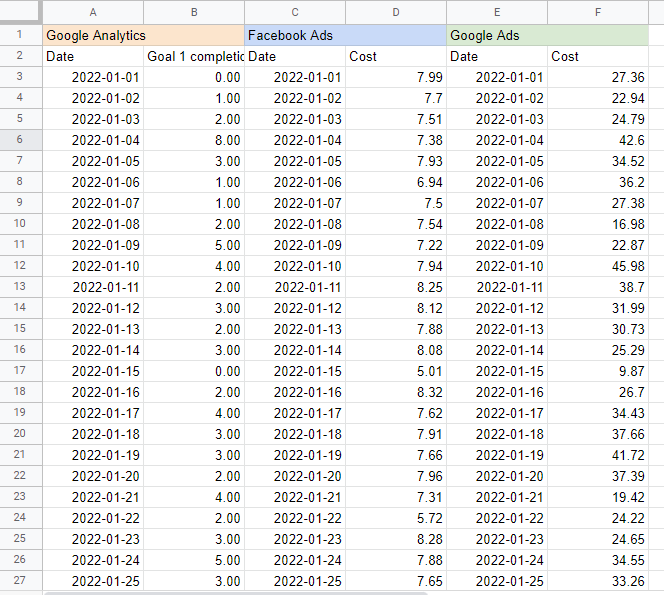
在 Google 表格中構建營銷組合模型
營銷組合建模是一種強大的歸因工具,但它實際上比您想像的更容易獲得。 大多數從業者使用自定義代碼和高級統計信息,但您可以在一個下午完成基礎知識,只需要 Excel 或 Google 表格。
使用 LINEST 函數進行線性回歸
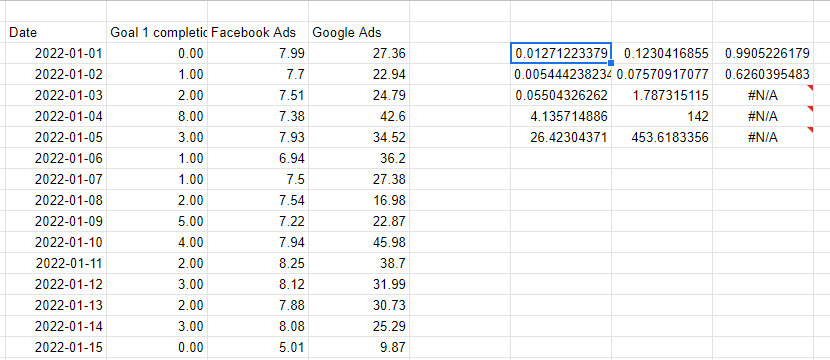
Excel 和 Google 表格都提供了一種簡單的方法,即 LINEST 函數,用於進行多變量線性回歸。 LINEST 的工作原理是傳遞我們試圖預測的列,然後傳遞代表我們用來進行預測的變量的多個列。 最後兩個參數是我們是否需要截距線(通常為 1 表示是)以及我們是否希望輸出詳細(包含模型的所有統計信息,而不僅僅是係數)。
請注意,我們用來進行預測的 X 變量需要是連續的,所以我剛剛引用了左側的列來重複相鄰的值。
用模型係數重新預測
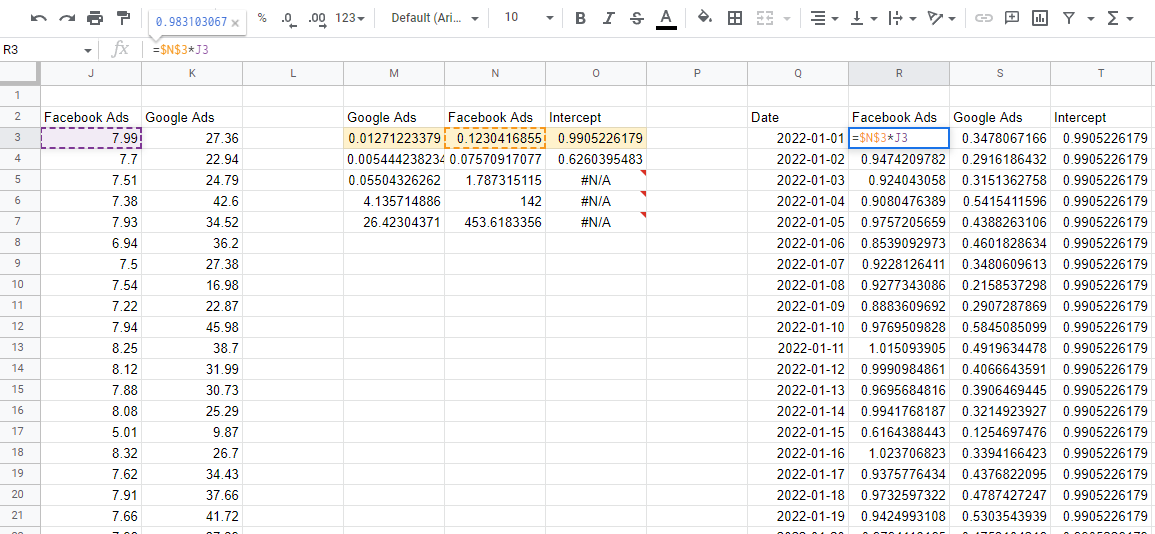
現在我們有了模型,我們需要使用係數來估計每個通道的影響。 如果我們取第一行數字,這些就是係數,並將它們乘以我們數據中的相應輸入值——我們將得到每個變量對總銷售額的貢獻。
需要注意的一件事是 LINEST 向後輸出係數。 從左邊開始的第一個值始終是您輸入的最後一個變量,然後它們以相反的順序繼續,直到您到達最後一個值,即截距。 如果您將所有這些貢獻值相加,它會為您提供模型的預測,您可以將其與實際值進行比較以確保模型準確。
檢查模型準確度指標
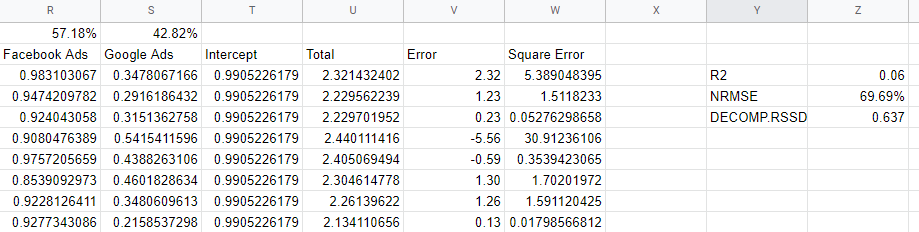
我們如何知道我們的模型是否可靠? 該模型應該很好地擬合數據,它應該能夠預測它沒有看到的新數據,並且它應該具有合理的係數。 幾個驗證指標捕獲了這些要求。

檢查模板中的函數以了解如何計算這些指標。
要使用該模板,請從附加組件列表中轉到“文件”>“製作副本”>“啟動 Supermetrics”> 將此文件複製到另一個帳戶,然後繼續進行帳戶選擇。
R2 或 R-Squared 衡量模型解釋了數據方差的多少,它介於 0 和 1 之間:一個好的模型會高於 0.7,但任何接近 1 的值都可能是可疑的。 接近 0,就像我們的模型一樣,表明我們的模型中沒有包含足夠的變量,需要納入有機渠道、假期和宏觀經濟因素等因素。
“歸一化均方根誤差”是我們衡量準確性的方式,它是通過獲取模型預測與實際值之間的差異,然後將平方值的根作為實際值的百分比來找到的。 理想情況下,這是基於看不見的數據(保留組)完成的,但在我們的簡單模型中,我們只是針對樣本內數據計算誤差。
根和平方過程為我們處理負值並採取行動懲罰真正的大錯誤。 這可以解釋為模型在任何一天關閉的百分比,因此它是一種有用且直觀的度量。
合理性是一個很大的話題,通常分析師應該擁有最終決定權。 但是,擁有一個可以以編程方式計算的指標會很有幫助,這樣您就可以了解模型與當前渠道組合的發現偏差有多遠。
Decomp RSSD 是 Facebook 的 Robyn 團隊發明的一個指標,用於衡量您當前的支出分配與模型預測的最大影響的渠道之間的差異。 如果模型說您最大的渠道實際上並沒有推動那麼多銷售,那麼您將擁有高 Decomp RSSD。
在我們的例子中,我們有一個 0.6 的高值,因為該模型給 Facebook 提供了太多的功勞,這代表了少量的支出。
自動大規模交付 MMM
營銷組合建模是可無限擴展的活動之一。 就像我們在這裡所做的那樣,您可以在一個下午使用 Excel 或 Google 表格和 Supermetrics 獲得不錯的結果,但您也可以花 3 個月的時間與 6 名數據科學家組成的團隊使用貝葉斯 MCMC 等複雜算法編寫自定義代碼來構建更多東西健壯和準確。
有一個用於構建高級模型的功能清單,其中一些需要高級統計知識。 如果您不使用 Supermetrics 為您自動化該部分,請添加幾位昂貴的數據工程師來構建數據管道。
想了解更多關於建模混合自動化的信息嗎?
查看我們的自動化營銷組合建模文章
請注意:MMM 很難。 您可以在建模上花費 500 美元、5,000 美元或 50,000 美元,並在準確性和穩健性方面看到截然不同的結果。 真正重要的是讓您的營銷支出分配錯誤的機會成本。
如果您每月花費 10 美元,那麼每季度使用一次電子表格模型就可以了。 但是,如果您每月花費超過 100,000 美元,即使減少 5% 也可能在一年內花費您數万美元。
不確定您的 MMM 提要需要哪種數據訪問模型?
查看我們的文章以選擇適合您業務的文章
那時投資更高級的建模是有意義的。 進行構建與購買分析,以決定是基於 Facebook 的 Robyn 等開源庫構建的自定義解決方案,還是我們在 Recast 構建的高級歸因軟件。
關於作者
Michael Kaminsky 是一位訓練有素的計量經濟學家,擁有醫療保健和環境經濟學背景。 在共同創立 Recast 之前,他曾在男士美容品牌 Harry's 建立營銷科學團隊。

提高您的業務績效
通過在您的數據倉庫中結合營銷和商業智能