
日誌文件分析:Google Analytics 的智能替代方案
已發表: 2022-03-08您知道您網站上每天發生的事情嗎? 回答這個問題時首先想到的可能是使用受眾和行為跟踪工具。 市場上有許多此類工具,包括:Google Analytics、At Internet、Matomo、Fathom Analytics 和 Simple Analytics 等等。 雖然這些工具確實讓我們能夠很好地了解我們網站上任何特定時間發生的事情,但這些工具所採用的道德實踐,更具體地說是谷歌分析,再次受到質疑。
這表明所有網站所有者目前還沒有充分利用其他數據來源:日誌。
分析工具和 GDPR(專注於 Google Analytics)
自通用數據保護條例 (GDPR) 實施和國家信息與自由委員會 (CNIL) 成立以來,個人數據已成為法國的一個敏感主題。 數據保護已成為優先事項。
那麼,您的網站是否仍然“對 GDPR 友好”?
如果我們查看所有網站,我們會發現許多網站已經找到了一種規避規則的方法,即使用他們的 cookie(數據收集橫幅)收集他們需要的信息,而其他網站仍然嚴格遵守官方規定。
通過收集這些信息,數據分析工具使我們能夠分析觀眾的來源和訪問者的行為。 這種分析需要一個無可挑剔的標記計劃來收集盡可能可靠和準確的數據,最終收集的數據是網站上每個動作和事件的結果。
在收到大量投訴後,CNIL 決定暫時將 Google Analytics 在法國定為非法行為,從而引起人們的注意。 這種制裁來自於在向美國情報機構轉移個人數據方面明顯缺乏監督,儘管之前已獲得同意收集訪問者信息。 應密切監測事態發展。
在當前情況下,對 Google Analytics 的訪問受限或無法訪問,看看其他數據收集選項可能會很有趣。 一個站點歷史事件的彙編和相對簡單的恢復,日誌文件是一個很好的信息來源。
儘管日誌文件提供了對有趣信息檔案的訪問以進行分析,但它們不允許我們顯示業務價值或網站訪問者的真實行為,例如從開始到他或她驗證購物車或離開網站的網站導航地點。 然而,行為方面仍然特定於上述工具; 日誌分析可以幫助我們走得更遠。
了解日誌文件
什麼是日誌文件? 日誌是一種文件類型,其主要任務是存儲事件的歷史。
我們在談論什麼樣的事件? 從本質上講,“事件”是每天訪問您網站的訪問者和機器人。
谷歌搜索控制台也可以收集這些信息,但出於多種原因——特別是隱私原因——它應用了一個非常具體的過濾器。
(來源:https://support.google.com/webmasters/answer/7576553。“Search Console 和其他工具之間的差異”。)
因此,您將只有一個日誌分析可以提供的樣本。 使用日誌文件,您可以訪問 100% 的數據!
分析日誌文件的行可以幫助您確定未來操作的優先級。
以下是過去從不同機器人訪問 Oncrawl 站點的一些示例:
FACEBOOK:
66.220.149.10 www.oncrawl.com - [07/Feb/2022:00:18:35 +0000] "GET /feed/ HTTP/1.0" 200 298008 "-" "facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)"
SEMRUSH:
185.191.171.20 fr.oncrawl.com - [13/Feb/2022:00:18:27 +0000] "GET /infographie/mises-jour-2017-algorithme-google/ HTTP/1.0" 200 50441 "-" "Mozilla/5.0 (compatible; SemrushBot/7~bl; +http://www.semrush.com/bot.html)"
必應:
207.46.13.188 www.oncrawl.com - [22/Jan/2022:00:18:40 +0000] "GET /wp-content/uploads/2018/04/url-detail-word-count.png HTTP/1.0" 200 156829 "-" "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)"
谷歌機器人:
66.249.64.6 www.oncrawl.com - [21/Jan/2022:00:19:12 +0000] "GET /product-updates/introducing-search-console-integration-skyrocket-organic-search/ HTTP/1.0" 200 73497 "-" "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
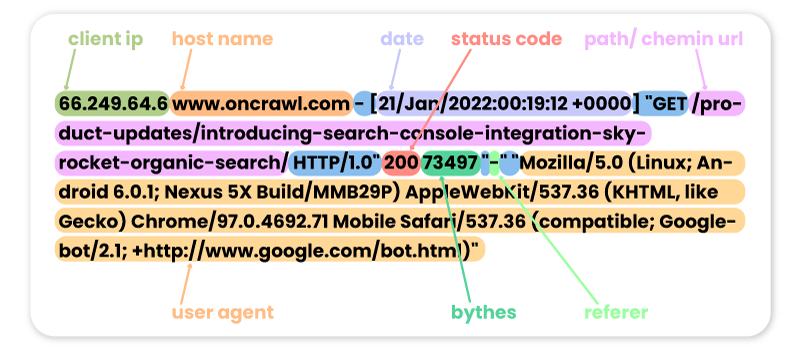
請注意,某些機器人訪問可能是假的。 請務必記住驗證 IP 地址以了解它們是否是來自 Googlebot、Bingbot 等的真實訪問。在這些虛假用戶代理背後,可能會有專業人員有時會啟動機器人來訪問您的網站並檢查您的價格、您的內容或其他他們認為有用的信息。 為了識別它們,只有 IP 會有所幫助!
以下是互聯網用戶訪問 Oncrawl 網站的一些示例:
來自 Google.com:
41.73.11x.xxx fr.oncrawl.com - [13/Feb/2022:00:25:29 +0000] "GET /seo-technique/predire-trafic-seo-prophet-python/ HTTP/1.0" 200 57768 "https://www.google.com/" "Mozilla/5.0 (Linux; Android 10; Orange Sanza touch) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.98 Mobile Safari/537.36"
來自 Google Ads UTM:
199.223.xxx.x www.oncrawl.com - [11/Feb/2022:15:18:30 +0000] "GET /?utm_source=sea&utm_medium=google-ads&utm_campaign=brand&gclid=EAIaIQobChMIhJ3Aofn39QIVgoyGCh332QYYEAAYASAAEgLrCvD_BwE HTTP/1.0" 200 50423 "https://www.google.com/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36"

來自LinkedIn,感謝推薦人:
181.23.1xx.xxx www.oncrawl.com - [14/Feb/2022:03:54:14 +0000] "GET /wp-content/uploads/2021/07/The-SUPER-SEO-Game-Building-an-NLP-pipeline-with-BigQuery-and-Data-Studio.pdf HTTP/1.0" 200 3319668 "https://www.linkedin.com/"
[電子書] 利用 SEO 日誌分析的四個用例
 免費下載
免費下載為什麼要分析日誌內容?
現在我們知道日誌實際包含什麼,我們可以用它做什麼? 答案:分析它們,就像任何其他分析工具一樣。
機器人或機器人
在這裡,我們可以問自己以下問題:
哪些機器人在我的網站上花費的時間最多?
如果我們專注於搜索引擎,詳細了解每個機器人,我們可以看到以下內容:
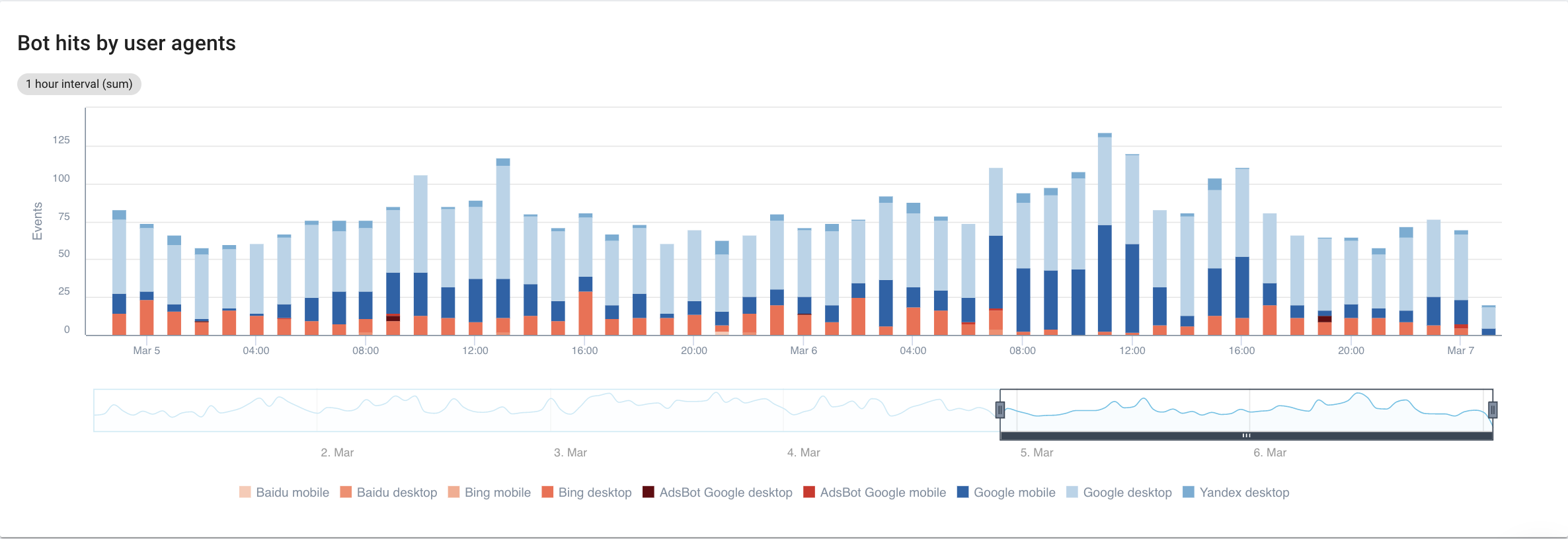
來源:Oncrawl 應用程序
顯然,谷歌移動和桌面比 Bing 或 Yandex 機器人花費更多的時間進行爬行。 Googlebot 擁有超過 90% 的全球市場份額。
如果 Google 抓取我的網頁,它們會自動編入索引嗎? 不,不一定。
如果我們回到幾年前,谷歌會在訪問頁面後直接使用自動反射來索引頁面。 今天,考慮到它必須處理的頁面量,情況已不再如此。 結果,關於抓取預算的搜索引擎優化之戰隨之而來。
說了這麼多,您可能會問:知道哪個機器人在我的網站上花費的時間比另一個機器人多有什麼意義?
這個問題的答案完全取決於每個機器人的算法。 它們每個都有點不同,並且不一定出於相同的原因返回。
每個搜索引擎都有自己的抓取預算,分配給這些機器人。 換句話說,這意味著谷歌將其抓取預算分配給所有這些機器人。 因此,仔細研究一下 GooglebotAds 的作用變得非常有趣,尤其是在我們周圍有 404 的情況下。 清理它們是優化抓取預算並最終優化您的 SEO 的一種方法。
Oncrawl 日誌分析器
 學到更多
學到更多使用 Oncrawl Crawler 數據交叉引用 Googlebot 數據
為了更深入地分析 Googlebot 的行為,Oncrawl 將日誌數據與抓取數據進行交叉引用,以獲得最詳細、最準確的信息。
目標也是肯定或反駁與深度、內容、性能等幾個 KPI 相關的假設。
因此,您必須問自己正確的問題:
- Googlebot 會抓取您網站上的所有網頁嗎? 對爬網率感興趣,它清楚地提供了這些信息,您也可以通過頁面分段來過濾這些信息。
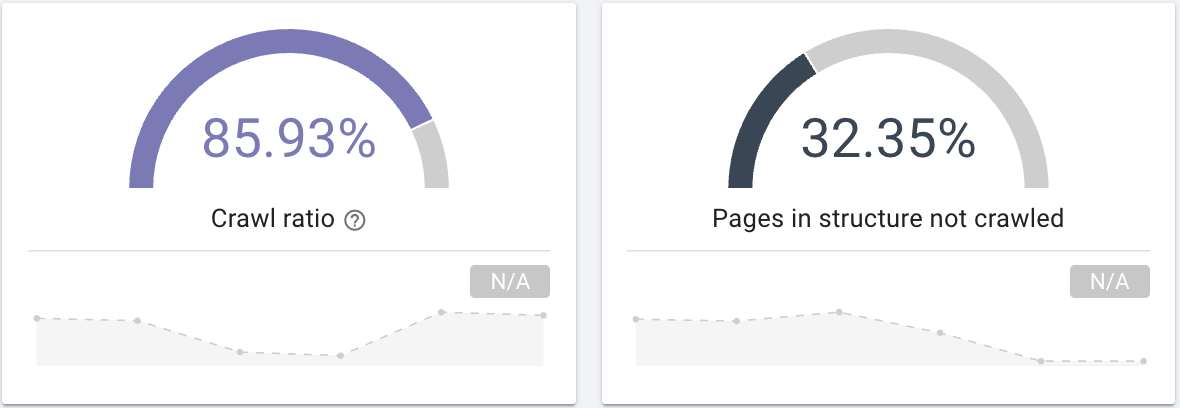
來源:Oncrawl 應用程序
- Googlebot 將時間花在哪個類別上? 這是對爬網預算的最佳使用嗎? Oncrawl 的 SEO 影響報告中的這張圖表交叉引用了數據並為您提供了這些信息。
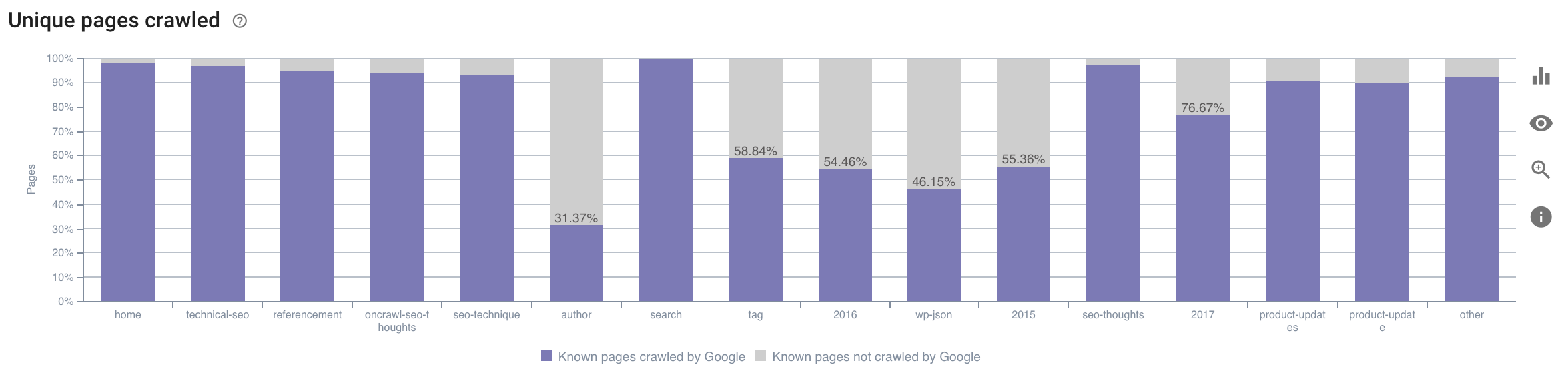 來源:Oncrawl 應用程序
來源:Oncrawl 應用程序
- 我們可能還會對 Oncrawl 爬網報告默認提供的範圍之外的問題存有疑問。 例如,描述的長度是否會影響 Googlebot 的行為? 由於爬網,我們擁有這方面的數據,因此我們可以使用它來創建細分,如下所示:
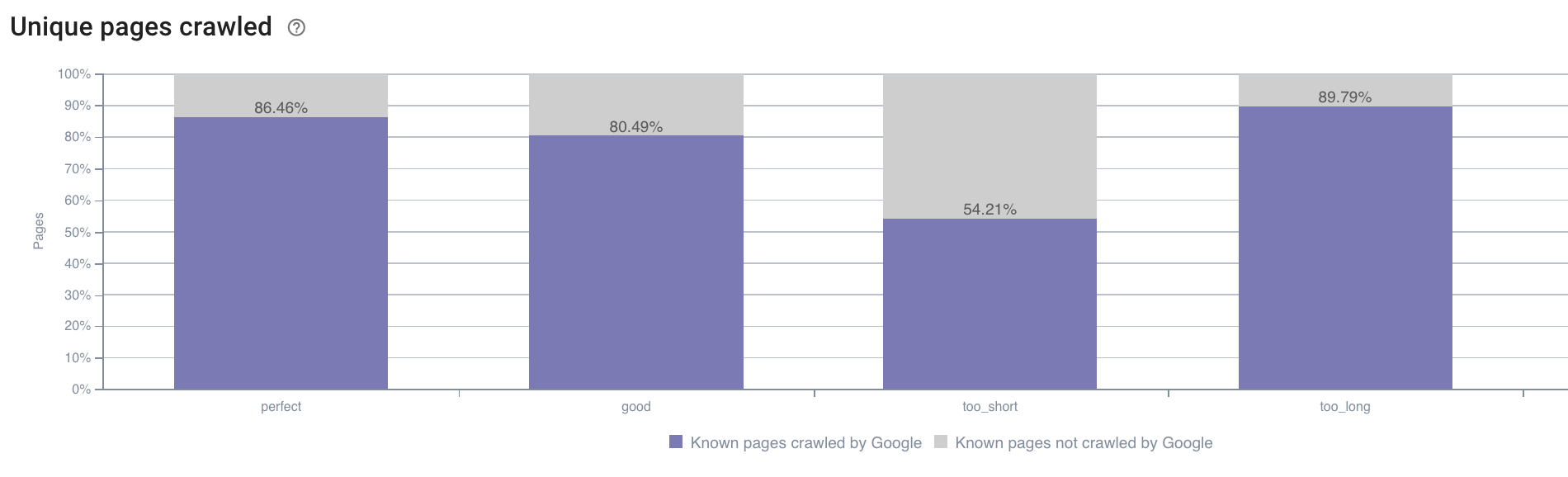
來源:Oncrawl 應用程序
與在此處被 Oncrawl 應用程序指定為“完美”或“良好”的理想尺寸(110 到 169 個字符之間)的描述相比,太短的描述被抓取的次數要少得多。
如果描述符合相關性和大小等標準,Googlebot 將很樂意增加其在相關頁面上的抓取預算。
注意:被認為太長的頁面有時會被 Google 重寫。
使用日誌分析網站訪問
接下來,如果我們看一下 SEO 的例子,因為這是我們試圖用 Oncrawl 分析的內容,我建議你再問自己一個問題:
- Googlebot 的行為與 SEO 訪問之間有什麼關聯?
Oncrawl 具有相同的圖表來交叉引用爬取數據和在日誌中檢索到的 SEO 訪問之間的數據。
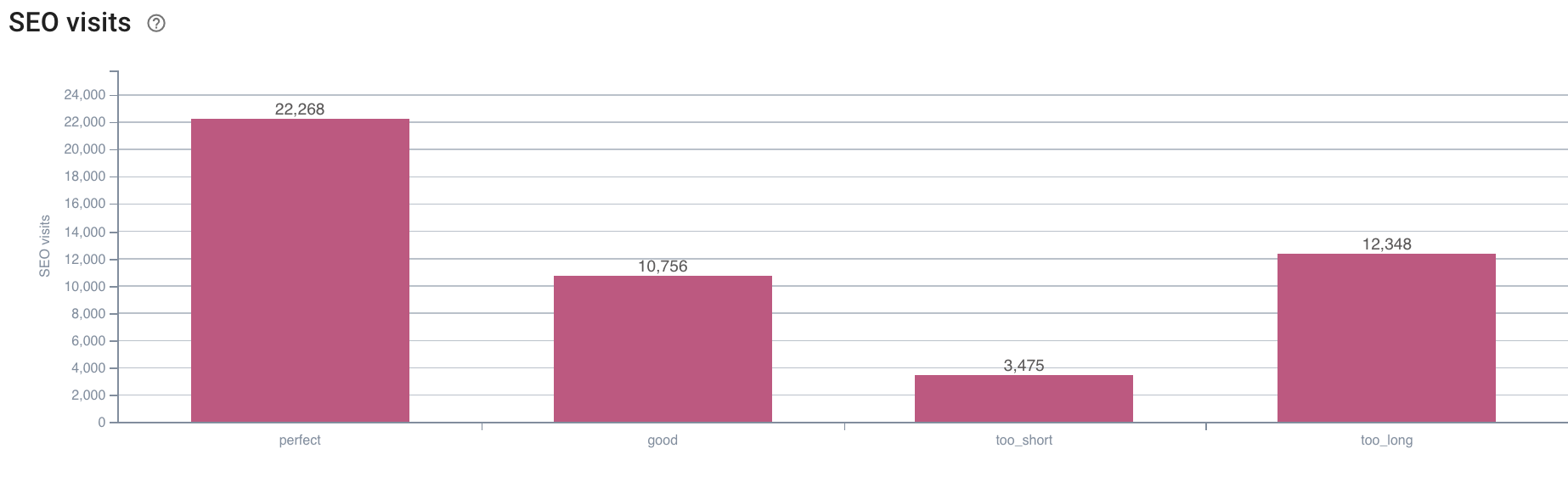 來源:Oncrawl 應用程序
來源:Oncrawl 應用程序
答案很明確:具有“完美”描述長度的頁面似乎會產生最多的 SEO 訪問。 因此,我們必須集中精力在這個軸心上。 除了“餵”Googlebot,用戶似乎還欣賞描述的相關性。
Oncrawl 應用程序為許多其他 KPI 提供了類似的數據。 隨意驗證你的假設!
綜上所述
既然您知道並理解了通過日誌探索您網站上每天發生的事情的可能性,我鼓勵您分析互聯網用戶和機器人訪問,以便找到各種優化您的網站的方法。 答案可能與技術或內容相關,但請記住,良好的細分是良好分析的關鍵。
然而,谷歌分析工具無法進行這種分析; 他們的數據有時會與我們的爬蟲數據混淆。 擁有盡可能多的數據供您使用也是一個很好的解決方案。
要從您的日誌數據和爬網分析中獲得更多信息,請隨時查看 Oncrawl 團隊進行的一項研究,該研究彙編了與電子商務網站上的日誌相關的 5 個 SEO KPI。