
Javascript:如何使用 Oncrawl 測試 SSR 和/或預渲染實現?
已發表: 2021-09-13用網站的 JavaScript 實現診斷 SEO 問題並不總是那麼容易。 當您為機器人選擇服務器端渲染或預渲染時,任務可能會變得更加複雜。
您必須確保提供給 Google bot 的版本是完整的,所有 javascript 元素都已在服務器端執行,並且存在於 bot 抓取的 html 中。
在本文中,我們將了解如何使用 Oncrawl 快速輕鬆地測試所有頁面的 JS 渲染。
搜索引擎優化和 JS
在開始實踐之前,讓我們快速回顧一下對服務器端渲染(SSR)的 SEO 和網站 javascript 元素的預渲染的興趣。
JS 和 Google:良好實踐
默認情況下,javascript 的 HTML 呈現由客戶端完成,即您的 Web 瀏覽器。 當您請求包含 JS 元素的頁面時,是您的瀏覽器執行此 javascript 代碼以顯示完整頁面。 這稱為客戶端渲染 (CSR)。
對於谷歌來說,這是一個問題,因為它需要大量的時間,尤其是資源。 它強制它瀏覽你的頁面兩次,一次是檢索代碼,第二次是在呈現 JS 的 HTML 之後。
作為您的 SEO 的 CSR 的直接後果,Google 不會立即看到您頁面的完整內容,因此它可能會延遲它們的索引。 此外,授予您網站的抓取預算也會受到影響,因為您的頁面需要被抓取兩次。
SSR(服務器端渲染)
在 SSR 的情況下,javascript 的 HTML 呈現是在服務器端為網站的所有訪問者、人類和機器人完成的。 這樣一來,Google 就不需要在 JS 中管理內容了,因為它在抓取的時候直接獲取了完整的 html。 這糾正了 javascript 在 SEO 中的缺陷。
另一方面,在服務器端實現這種渲染的資源成本可能很重要。 這是第三個選項出現的地方,預渲染。
預渲染
在這種混合配置中,除了搜索引擎機器人之外,所有訪問者 (CSR) 都在客戶端執行 JS。 將預渲染的 HTML 內容提供給 Google 機器人,以保持 SSR 的 SEO 優勢以及 CSR 的經濟優勢。
這種乍一看可以被視為偽裝(為機器人和網頁訪問者提供不同版本)的做法實際上是 Google 強烈推薦的一種想法。 我們很容易猜到原因。
如何使用 Oncrawl 測試 Javascript 渲染?
有很多方法可以診斷 JS 實現中的 SEO 錯誤。 通過使用 Oncrawl,您將能夠自動測試所有頁面,而無需進行任何手動比較。
Oncrawl 能夠通過在客戶端運行 javascript 來抓取網站。 這個想法是啟動兩次爬網並生成以下比較:
- 啟用 JS 渲染的爬網
- 禁用 JS 渲染的爬網
然後通過幾個指標來衡量這兩個爬蟲之間的差異,這表明部分 javascript 沒有在服務器端執行。
請注意,在預渲染的情況下,應使用 Google 用戶代理進行第二次抓取,以便抓取網站的預渲染版本。
該測試可以分三個步驟完成:
- 創建爬網配置文件
- 使用每個配置文件爬取站點並生成爬取爬取
- 分析結果
創建爬網配置文件
帶有 JS 的配置文件
在您的項目頁面中,單擊“+ 設置新爬網” 。
這將帶您進入爬網設置頁面。 將顯示您的默認爬網設置。 您可以更改它們或創建新的爬網配置。
爬網配置文件是一組以名稱保存以供將來使用的設置。
要創建新的抓取配置文件,請單擊右上角的藍色“+ 創建抓取配置文件”按鈕。
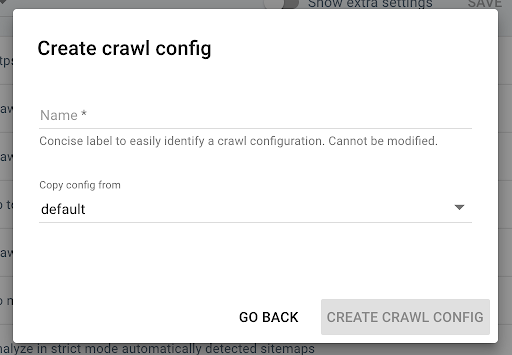
將其命名為“使用 JS 抓取”並複制您通常的抓取配置文件(例如默認值)。
要在這個新配置文件上激活 JS,您必須顯示默認隱藏的附加參數。 要訪問它們,請單擊頁面頂部的“顯示額外設置”按鈕。
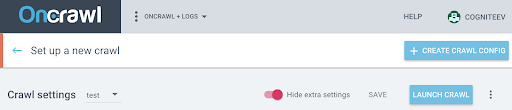
然後轉到額外設置並單擊 Crawl JS 選項中的“啟用” 。
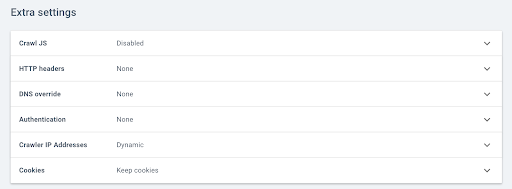
注意:請記住根據您網站服務器的容量調整您的抓取速度,因為 Oncrawl 會為每個 URL 進行更多調用,以便執行 Javascript 中的元素。 理想的速度是您的服務器和站點架構最能支持的速度。 如果 OnCrawl 的爬取速度過快,你的服務器可能跟不上。
沒有 JS 的配置文件
對於第二個爬網配置文件,按照相同的步驟並取消選中JS 啟用框。
注意:重要的是要有兩個具有相同範圍的配置文件,以便比較有意義。
如果您的站點處於服務器端渲染中,請轉到下一步。
如果您的網站處於基於 Google 漫遊器的預渲染狀態,您應該向我們發送請求以修改用戶代理以進行抓取。 創建配置文件後,直接在應用程序中通過對講機向我們發送消息,以便我們可以將 Oncrawl 用戶代理替換為 Google 機器人用戶代理。
開始您的 14 天免費試用
 開始試用
開始試用啟動您的爬網並生成 Crawl over Crawl
創建這兩個配置文件後,您只需依次使用這兩個配置文件來抓取您的網站。 為方便起見,您可以使用爬蟲編程功能。

安排爬網
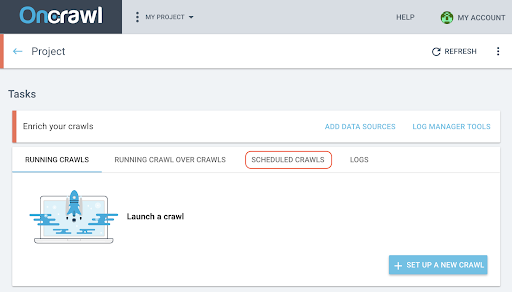
- 在項目頁面上,單擊抓取跟踪框頂部的“計劃抓取”選項卡。
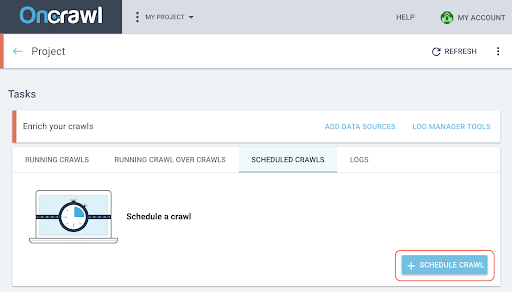
- 單擊“+計劃抓取”以安排新的抓取。
- 然後,您將需要選擇:
- 您要用於未來爬網的爬網配置文件
- 重複抓取的頻率,選擇“僅一次”。
- 您希望開始爬網的日期、時間(24 小時格式)和時區(按城市)。
- 點擊“計劃抓取” 。
一旦您的爬網的兩種分析都可用,您需要生成一次爬網。 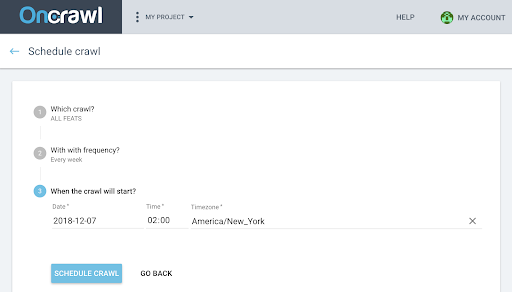
在爬行中生成爬行
- 從項目的主頁,啟動爬蟲爬蟲:
- 在“任務”下,單擊“運行爬行而不是爬行”選項卡。
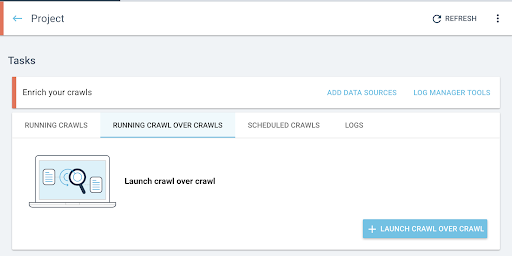
- 點擊“+開始爬行而不是爬行” 。
- 選擇要比較的兩個爬網。
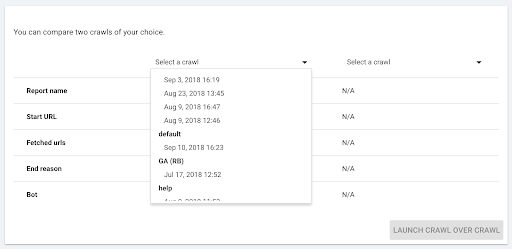
當您點擊“+ Run Crawl Over Crawl”時,Oncrawl 會分析兩個現有爬取的差異,並將 Crawl Over Crawl 報告添加到兩個爬取的分析結果中。
您可以在項目主頁的“Start crawl over crawl”選項卡中跟踪此爬取的進度。 由於爬取已經完成,過度爬取將跳過“Crawling”狀態,直接從“Analysis”開始。
分析結果
轉到以下三個視圖的爬蟲報告:
- 結構
- 內容
- 內部鏈接
您還可以下載我們的自定義儀表板。
要看哪些指標?
頁面爬網、每頁平均字數和平均文本代碼比
如果兩個配置文件已爬取了相同數量的頁面,第一個指標 Page crawled 會立即向您顯示。
如果差異不顯著,您可以檢查兩個頁面指示器:
- 每頁平均字數
- 平均文本與代碼的比率
這兩個指標將突出顯示在客戶端執行或不執行 javascript 的 html 內容的差異。
如果平均每頁字數較少,則說明部分頁面內容沒有JS渲染是不可用的。
同理,如果 text to ratio 較低,則表示部分頁面內容在沒有 JS 渲染的情況下是不可用的。
文本與代碼的比率衡量頁面內容有多少是可見的(文本),有多少是編碼的內容(代碼)。 報告的百分比越高,與代碼量相比,頁麵包含的文本就越多。
深度、排名和鏈接
然後,您可以查看與內部網格相關的更敏感的指標。 如果沒有 JS 渲染,一小部分頁面內容不可用,這對您的 SEO 來說不一定有問題,但如果它影響您的內部網格,那麼對您網站的可抓取性和抓取預算的影響更為重要。
比較平均深度、平均 Inrank、平均 Inlinks 數和內部外鏈數。
平均深度的增加、平均 inrank 的減少以及內鍊和外鏈的平均數量的減少是在服務器端未預渲染的 JS 中管理的網格塊存在的指標。 因此,某些鏈接無法立即提供給 google bot。
這可能會對您的網站的全部或部分產生影響。 然後有必要按頁面組研究這些修改,以確定某些類型的頁面是否因這個 javascript 網格而處於不利地位。
數據瀏覽器將允許您使用過濾器來突出這些元素。
進一步使用數據瀏覽器和 URL 詳細信息
在數據瀏覽器中
當您在數據資源管理器中查看 Crawl over Crawl 數據時,您將看到兩列 URL:一列用於 Crawl 1 URL,另一列用於 Crawl 2 URL。
然後,您可以將上面提到的每個指標(抓取的頁面、字數、文本編碼比率、深度、排名、鏈接)添加兩次,以並排顯示 Crawl 1 和 Crawl 2 的值。
通過使用過濾器,您將能夠識別差異最大的 URL。
網址詳情
如果您已確定 SSR 和/或預渲染版本與客戶端渲染版本之間的差異,那麼您需要更詳細地了解哪些 JS 元素未針對 SEO 進行優化。
通過單擊數據瀏覽器中的頁面,您可以切換到 URL 詳細信息,然後您可以通過單擊“查看源”選項卡查看 Oncraw 所看到的源代碼。
然後,您可以通過單擊複製 HTML 源來檢索 HTML 代碼。
在左上角,您可以從一個爬取切換到另一個爬取來檢索另一個版本的代碼。
通過使用 html 代碼比較工具,您可以比較一個頁面的兩個版本,在客戶端執行 JS 和不執行 JS。 剩下的就看你自己了!