
網絡爬蟲簡介
已發表: 2016-03-08當我與人們談論我的工作以及 SEO 是什麼時,他們通常會很快得到它,或者他們會照常行事。 良好的網站結構,良好的內容,良好的背書反向鏈接。 但有時,它會變得更具技術性,我最終會談論搜索引擎抓取您的網站,而我通常會失去它們……
為什麼要抓取網站?
網絡爬蟲始於映射互聯網以及每個網站如何相互連接。 搜索引擎也使用它來發現和索引新的在線頁面。 網絡爬蟲還用於通過測試網站並分析是否發現任何問題來測試網站的漏洞。
現在,您可以找到抓取您網站的工具,以便為您提供見解。 例如,OnCrawl 提供有關您的內容和現場 SEO 或 Majestic 的數據,它提供有關指向頁面的所有鏈接的見解。
爬蟲用於收集信息,然後可以使用和處理這些信息來對文檔進行分類並提供有關所收集數據的見解。
任何懂一點代碼的人都可以構建爬蟲。 然而,製作一個高效的爬蟲更加困難並且需要時間。
它是如何工作的 ?
為了爬取網站或網絡,您首先需要一個入口點。 機器人需要知道您的網站存在,以便他們可以來查看它。 回到過去,您會將您的網站提交給搜索引擎,以便告訴他們您的網站在線。 現在,您可以輕鬆地建立一些指向您的網站的鏈接,瞧,您就在循環中!
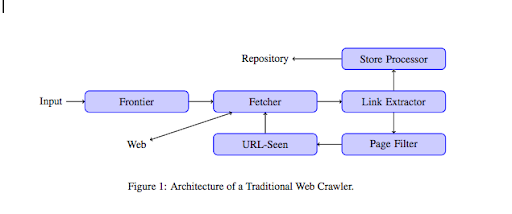
一旦爬蟲登陸您的網站,它就會逐行分析您的所有內容,並跟踪您擁有的每個鏈接,無論它們是內部的還是外部的。 依此類推,直到它到達沒有更多鏈接的頁面,或者遇到 404、403、500、503 之類的錯誤。
從更技術的角度來看,爬蟲使用 URL 的種子(或列表)工作。 這被傳遞給將檢索頁面內容的 Fetcher。 然後將該內容移至鏈接提取器,該提取器將解析 HTML 並提取所有鏈接。 這些鏈接被發送到存儲處理器,正如它的名字所說,存儲它們。 這些 URL 還將通過頁面過濾器,該過濾器會將所有有趣的鏈接發送到 URL-seen 模塊。 該模塊檢測 URL 是否已經被看到。 如果不是,它會被發送到 Fetcher,它將檢索頁面的內容等等。
請記住,蜘蛛無法抓取某些內容,例如 Flash。 GoogleBot 現在正在正確抓取 Javascript,但有時它不會抓取任何內容。 圖片不是谷歌在技術上可以抓取的內容,但它變得足夠聰明,可以開始理解它們!
如果不告訴機器人相反,它們會爬行所有東西。 這是 robots.txt 文件變得非常有用的地方。 它告訴爬蟲(它可以是每個爬蟲特定的,即 GoogleBot 或 MSN Bot - 在此處了解有關機器人的更多信息)他們無法爬取哪些頁面。 例如,假設您有使用構面的導航,您可能不希望機器人抓取所有這些,因為它們幾乎沒有附加值,並且會使用抓取預算。 使用這條簡單的線將幫助您防止任何機器人爬行它
用戶代理: *
禁止:/文件夾-a/
這告訴所有機器人不要爬取文件夾 A。
用戶代理:GoogleBot
禁止:/repertoire-b/
另一方面,這指定只有 Google Bot 不能抓取文件夾 B。
您還可以在 HTML 中使用指示,它告訴機器人不要使用 rel=”nofollow” 標籤跟踪特定鏈接。 一些測試表明,即使在鏈接上使用 rel=”nofollow” 標籤也不會阻止 Googlebot 關注它。 這與其目的相矛盾,但在其他情況下會很有用。
[案例研究] 通過提高 Googlebot 的網站可抓取性來提高知名度
 閱讀案例研究
閱讀案例研究
您提到了抓取預算,但它是什麼?
假設您有一個已被搜索引擎發現的網站。 他們會定期查看您是否在網站上進行了任何更新並創建了新頁面。
每個網站都有自己的抓取預算,具體取決於幾個因素,例如您的網站擁有的頁面數量和它的健全性(例如,如果它有很多錯誤)。 您可以通過登錄 Search Console 輕鬆快速了解您的抓取預算。
您的抓取預算將確定機器人每次訪問您的網站時抓取的頁面數量。 它與您網站上的頁面數量成正比,並且已經被抓取。 有些頁面比其他頁面更頻繁地被抓取,特別是如果它們定期更新或者它們是從重要頁面鏈接的。
例如,您的家是您的主要入口點,經常會被抓取。 如果您有博客或類別頁面,如果鏈接到主導航,它們將經常被抓取。 博客也會經常被抓取,因為它會定期更新。 博客文章剛發佈時可能會經常被抓取,但幾個月後可能不會更新。
一個頁面被抓取的次數越多,機器人認為它與其他頁面相比就越重要。 這是您需要開始優化抓取預算的時候。
優化您的抓取預算
為了優化您的預算並確保您最重要的頁面得到應有的關注,您可以分析您的服務器日誌並查看您的網站是如何被抓取的:
- 您的首頁被抓取的頻率
- 您是否看到任何不那麼重要的頁面比其他更重要的頁面被更多地抓取?
- 機器人在抓取您的網站時是否經常出現 4xx 或 5xx 錯誤?
- 機器人會遇到任何蜘蛛陷阱嗎? (馬修亨利寫了一篇關於他們的精彩文章)
通過分析您的日誌,您將看到您認為不太重要的頁面被大量抓取。 然後,您需要深入挖掘您的內部鏈接結構。 如果它正在被抓取,它必須有很多指向它的鏈接。
您還可以使用 OnCrawl 修復所有這些錯誤(4xx 和 5xx)。 它將提高可抓取性和用戶體驗,這是一個雙贏的案例。
爬行 VS 抓取?
爬行和抓取是用於不同目的的兩種不同的東西。 抓取網站是登陸頁面並跟隨您在掃描內容時找到的鏈接。 然後爬蟲將移動到另一個頁面,依此類推。
另一方面,抓取是掃描頁面並從頁面中收集特定數據:標題標籤、元描述、h1 標籤或您網站的特定區域,例如價格列表。 抓取工具通常充當“人”,它們會忽略 robots.txt 文件中的任何規則,以表格形式歸檔並使用瀏覽器用戶代理以免被檢測到。
搜索引擎爬蟲通常充當抓取工具,並且他們需要收集數據以便為他們的排名算法處理數據。 與抓取工具相比,他們不尋找特定數據,他們只是使用頁面上的所有可用數據,甚至更多(加載時間是您無法從頁面獲得的)。 搜索引擎爬蟲將始終將自己標識為爬蟲,因此網站所有者可以知道他們上次訪問其網站的時間。 這在您跟踪真實用戶活動時非常有用。
所以現在你對爬網有了更多的了解,它是如何工作的以及為什麼它很重要,下一步就是開始分析服務器日誌了。 這將為您提供有關機器人如何與您的網站交互、他們經常訪問哪些頁面以及他們在訪問您的網站時遇到多少錯誤的深入見解。
有關網絡爬蟲的更多技術和歷史信息,您可以閱讀“網絡爬蟲簡史”