
如何為下一次 SEO 遷移擴展產品重定向
已發表: 2020-07-21向任何 SEO 詢問與 SEO 相關的哪些任務最讓他們畏縮。 他們可能會通過鏈接構建或網站遷移來回應。 大多數人都同意第一個:鏈接建設真的很痛苦。 第二個反應總是讓我感到驚訝。 我是網站遷移的忠實粉絲,甚至寫過為什麼你現在應該優先考慮遷移。
為什麼對網站遷移如此焦慮? 這並非沒有優點。 沒有考慮到 SEO 的糟糕遷移可能會導致性能顯著下降。 下面是一張讓 SEO 徹夜難眠的例子。 我不會寫成功遷移的每一步,但會詳細介紹針對更大痛點之一的擴展解決方案:重定向。
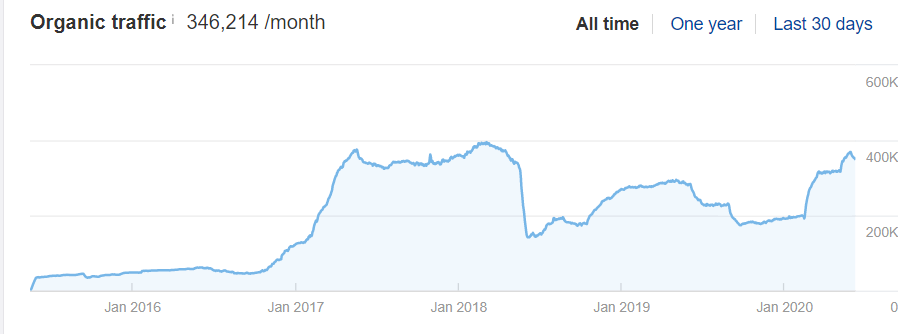
該網站在 2018 年遷移失敗,他們用了近 3 年的時間才恢復了有機性能
網站遷移重定向的目的
為了避免發生網站遷移後災難性的自然性能下降,需要實施 301 重定向。 該過程從將舊網站上的每個頁面映射到新網站開始。 這需要 1:1 映射。 映射 URL 後,您可以利用 HTACCESS 文件為每個 URL 實現 301 狀態重定向。 未能正確映射重定向或使用正確的 301 狀態通常是啟動後自然流量下降的原因。
即使是手動完成,映射您的核心網站頁面(主頁、關於我們、類別頁面甚至文章/博客)也相當簡單。 但是,您如何為擁有數千、數十萬甚至數百萬項目頁面的電子商務網站映射重定向? 讓我們介紹兩種獨特的方法。
方法一:識別 URL 模式
利用您當前的網站和開發環境,您將能夠比較單個產品。 假設您的遷移現在需要更改 URL,是時候確定任何模式了。 例如,如果您當前網站的 CMS 是 Magento 並且您正在遷移到 Shopify,則以下是同一產品的兩個不同 URL。
MAGENTO .com/product-name.html
SHOPIFY .com/products/product-name
在這種情況下,我們可以使用一些 Excel 嚮導來擴展 URL 映射,而無需單獨映射每個產品。

A 列 –列出您現有網站的所有產品 URL(利用您最喜歡的爬蟲獲取此信息)
B 列 –使用“連接”公式 =CONCATENATE(“/products”,A2)
C 列 –通過 LEFT 公式刪除最後 5 個字符 (.html) =LEFT(B2, LEN(B2)-5)
通過您的 SEO 爬蟲(在附加您的開發 URL 之後)運行您的 C 列值,以確保所有行的狀態為 200。 如果此操作成功,您現在可以為從舊 Magento 站點到新 Shopify 站點的所有產品 URL 提供可擴展的解決方案。
方法二:如果產品 URL 不同怎麼辦?
如果您的舊網站產品 URL 沒有使用產品名稱或由數據庫動態生成怎麼辦? 我也有這方面的提示。 這將需要識別模式和 SEO 爬蟲,例如 OnCrawl 或 Screaming Frog SEO Spider。
示例:舊網站根據產品 SKU 值生成產品 URL。
舊網址:.com/product/38472
新網址:/com/product/grey-baseball-cap
解決方案 1:比較/匹配標題標籤 (VLOOKUP)
如果兩個站點之間不存在簡單的 URL 匹配解決方案,我們將不得不轉向下一個解決方案。 生產標題標籤值是否被拉到新的開發站點? 如果是這樣,我們可以利用爬蟲來比較生產站點和新開發站點以找到匹配值。
示例:沒有產品 URL 相關性,但標題標籤值匹配
第一步:運行當前生產網站和開發環境的完整爬網。
第二步:將兩個爬網導出到一個 Excel 文檔,每個文檔都在自己的專用選項卡中。


第二步:我們將運行一個 VLOOKUP 值,為了使這個函數正常工作,我們需要將標題標籤值放在 URL 的前面。 將 G 列移動到 B 列後,每個選項卡將如下所示。
第三步:打開“sheet 3”選項卡,在 A 列中復制並粘貼開發選項卡中的標題標籤值。 設置 B 列以列出您的生產 URL。 C 列將是您的新開發 URL。
第四步:從 sheet3 中針對匹配標題標籤值的生產和開發選項卡運行 VLOOKUP。 如果您完全按照我的方式設置工作表,這就是每個值都需要的 VLOOKUP 代碼。
=VLOOKUP(A2,生產!$A1:B100000,2,FALSE)
=VLOOKUP(A2,發展!$A1:B100000,2,FALSE)
*請注意,如果您的電子表格中有超過 100,000 個值,那麼您需要將 B1 值更改為大於我設置的默認值 100,000。

運行爬網、組織電子表格中的數據和運行 VLOOKUP 的最終結果是一張包含當前 URL 和新開發站點 URL 的工作表。

解決方案 2:比較產品正文副本 (XPath/VLOOKUP)
當 URL 完全不同並且標題標籤不匹配時,您可能會想捲起袖子並開始手動匹配 URL。 停止- 我還有一個提示給你。
我們將使用自定義提取來提取和匹配單個產品頁面的正文副本。 然後,我們將利用我們在標題標籤示例中使用的 VLOOKUP 命令來匹配這兩個 URL。
第一步:在生產和開發站點上打開一個匹配的產品頁面。 驗證兩個站點上的產品描述確實相同。
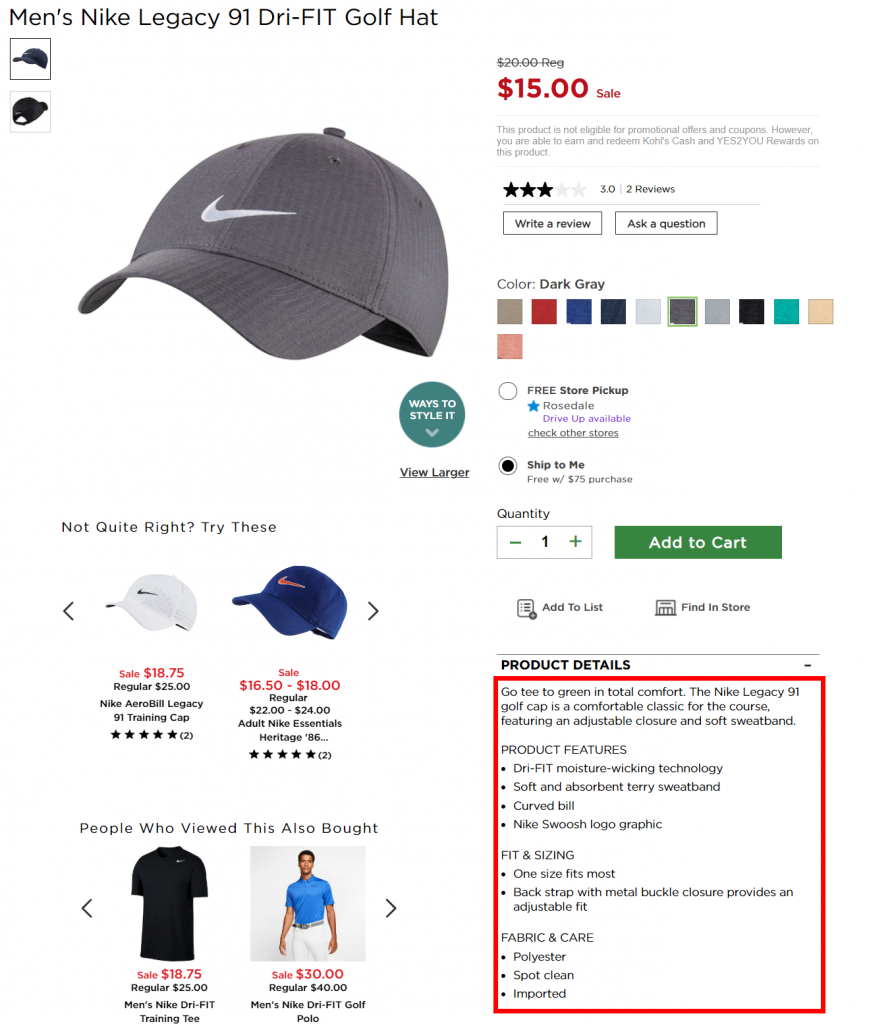
第二步:在 Chrome 網絡瀏覽器中,您可以右鍵單擊產品描述,然後單擊“檢查元素”。 這將打開 Chrome 開發工具並將您帶到我們將要抓取的代碼部分。
在 Chrome 開發工具中,再次右鍵單擊並選擇“複製”,然後選擇“複製 XPath”。 您將獲得類似於 //*[@id=”3796805_productDetails”]/div/p[1] 的值
第三步:在 OnCrawl 中,導航到抓取配置文件設置中的抓取(+ 設置新抓取 > 抓取)。 輸入此字段的名稱,例如“說明”,然後粘貼您最近從 Chrome 開發工具複製的 XPath 代碼。 您需要在末尾添加“/text()”以捕獲產品描述文本。
在此示例中,我還選中了“壓縮空白”以避免描述中出現任何段落字符。
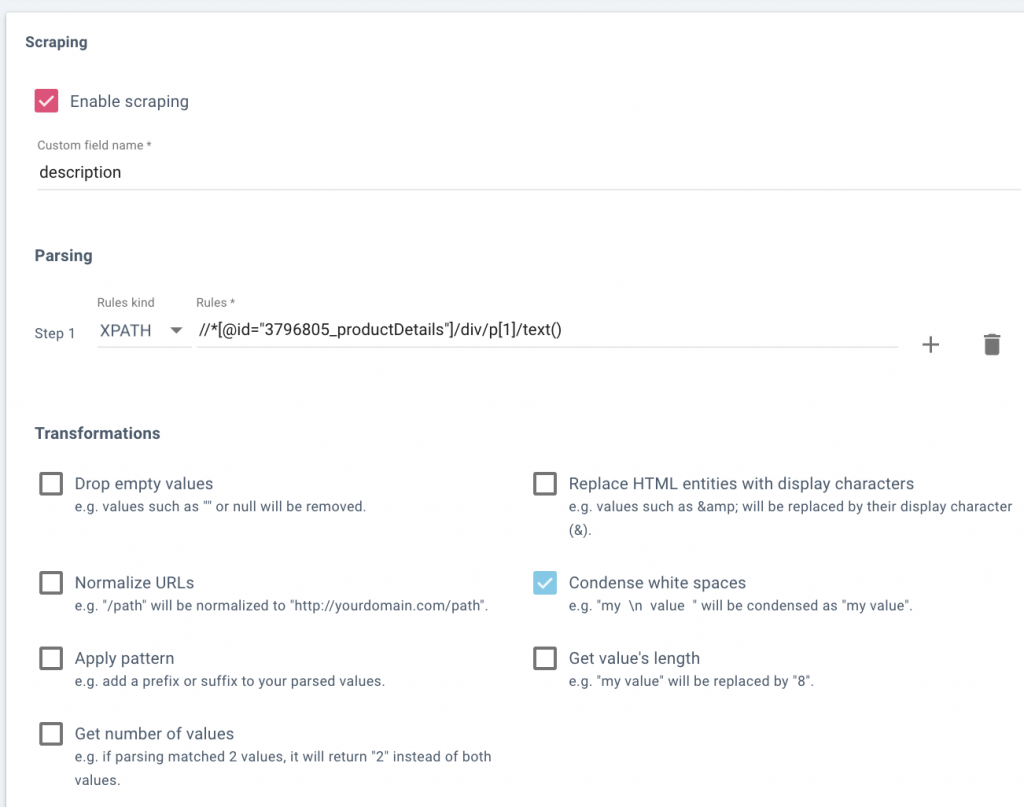
第四步:測試您的自定義提取邏輯。
在 OnCrawl 中,在保存規則之前,您應該在底部的“檢查輸出”框中輸入一些 URL,並確保當您單擊“檢查”時,您會看到右側框中的說明:
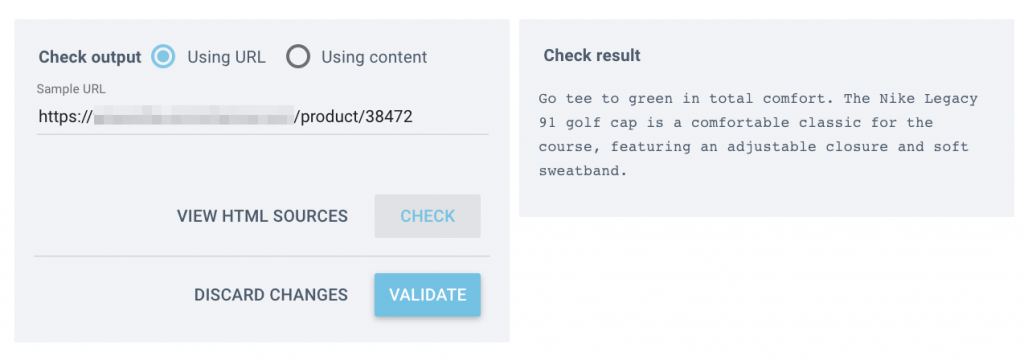
驗證提取邏輯是否正常工作後,繼續運行所有產品 URL。 抓取完成後,您將能夠導出所有提取的描述(綁定到 URL)。

第五步:此時,您將為您的開發站點重複步驟 1-3。 現在,每個環境都有兩個不同的選項卡,其中每個產品 URL 都有與其關聯的提取描述。
第六步:與標題標籤示例類似,我們將使用 VLOOKUP 來匹配生產和開發站點之間的產品描述。 如果操作正確,您將獲得一個新舊 URL 列表,您現在可以使用它們來映射您的重定向。

URL 邏輯、標題標籤和描述匹配失敗?
不要放棄。 我向您保證,您要做的最後一件事是花費手動匹配所有這些 URL 所需的小時數。 以下是我見過的其他一些取得不同程度成功的策略:
- 識別和匹配 Schema.org 標記值
- 識別並匹配圖像名稱和/或圖像 alt 標籤
- 有時您很幸運,實際的 SKU 將成為產品模板的一部分
- 識別和匹配產品評論
映射產品重定向的最後努力
有時產品會經歷這樣的大修,以至於不必手動構建 1:1 映射是不可能的。 如果這是您的情況,請考慮使用上述所有策略來盡可能多地識別。 作為最後的手段,請考慮分配您的暑期實習生或更多初級資源來幫助解決剩餘的無與倫比的產品。
雖然上面列出的策略不是防火解決方案,但我發現它可以解決大量工作。 即使它解決了 75% 的重定向問題,您也會很感激能夠節省您原本會花費在手動映射這些重定向上的時間。