
您應該每月進行多少次 A/B 測試?
已發表: 2023-01-19
這是測試計劃成功需要考慮的一個重要問題。
運行太多測試,您可能會浪費資源,而無法從任何單個實驗中獲得太多價值。
但是運行的測試太少,您可能會錯過可能帶來更多轉化的重要優化機會。
那麼,鑑於這個難題,理想的測試節奏是什麼?
為了幫助回答這個問題,看看世界上一些最成功和最先進的實驗團隊就很有趣了。
亞馬遜就是一個這樣的名字。
這家電子商務巨頭也是一個實驗巨人。 事實上,據說亞馬遜每年進行超過 12,000 次實驗! 這個數量分解為每月大約一千次實驗。
據說谷歌和微軟必應等公司也保持著類似的步伐。
根據維基百科,搜索引擎巨頭每年進行超過 10,000 次 A/B 測試,或每月進行約 800 次測試。
以這種速度運行的不僅僅是搜索引擎。
Booking.com 是另一個在實驗中值得注意的名字。 據報導,該旅遊預訂網站每年進行超過 25,000 次測試,相當於每月進行 2000 多次測試或每天進行 70 次測試!
然而,研究表明,一般公司每月只進行 2-3 次測試。
因此,如果大多數公司每個月只進行幾次測試,而世界上最好的一些公司每月進行數千次實驗,那麼理想情況下,您應該進行多少次測試?
在真正的 CRO 風格中,答案是:視情況而定。
它取決於什麼? 您需要考慮許多重要因素。
運行 A/B 測試的理想數量取決於具體情況和因素,例如樣本量、測試想法的複雜性和可用資源。
運行 A/B 測試時要考慮的 6 個因素
在決定每月進行多少次測試時,需要考慮 6 個基本因素。 他們包括
- 樣本量要求
- 組織成熟度
- 可用資源
- 測試思路的複雜性
- 測試時間表
- 交互作用
讓我們深入探討每一個。
樣本量要求
在 A/B 測試中,樣本量描述了運行可信測試所需的流量。
要進行統計上有效的研究,您需要大量具有代表性的用戶樣本。
雖然從理論上講,您可以只對幾個用戶進行實驗,但不會產生非常有意義的結果。
小樣本量仍然可以產生具有統計學意義的結果
例如,想像一個 A/B 測試,其中只有 10 個用戶看到版本 A 和 2 轉換。 只有 8 個用戶看到版本 B,其中 6 個用戶轉換了。
如圖表所示,結果具有統計顯著性:
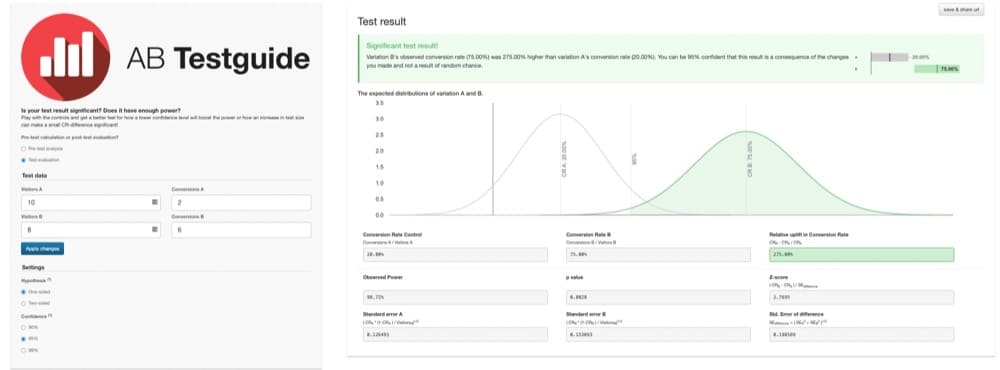
版本 B 似乎優於 275%。 但是,這些發現並不是很可信。 樣本量太小,無法提供有意義的結果。
這項研究動力不足。 它不包含大量具有代表性的用戶樣本。
由於測試動力不足,結果容易出錯。 目前尚不清楚結果是隨機發生的還是某個版本確實更優越。
有了這麼小的樣本,很容易得出錯誤的結論。
正確供電的測試
為了克服這個陷阱,A/B 測試需要有大量有代表性的用戶樣本來充分發揮作用。
多大才夠大?
這個問題可以通過做一些簡單的樣本量計算來回答。
為了最輕鬆地計算您的樣本量要求,我建議使用樣本量計算器。 那裡有很多。
我最喜歡 Evan Miller 的,因為它靈活而透徹。 另外,如果你能理解如何使用它,你幾乎可以掌握任何計算器。
這是 Evan Miller 的計算器的樣子:
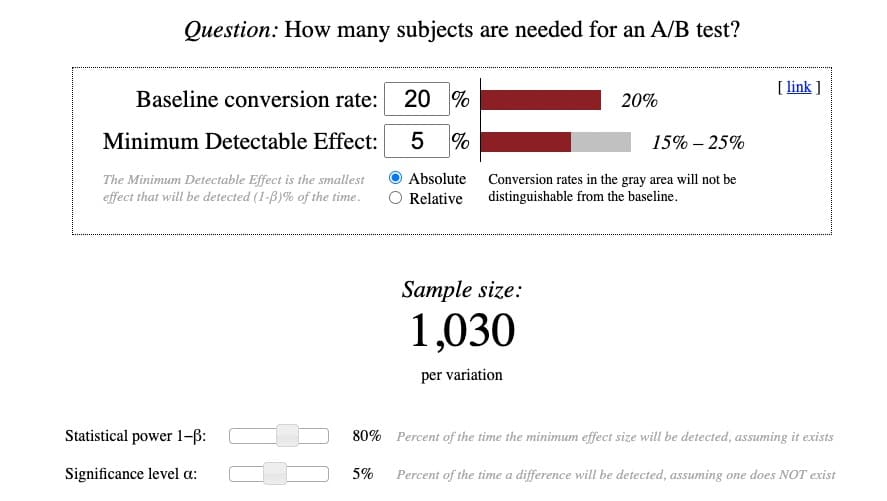
雖然計算本身相當簡單,但理解其背後的術語卻並非如此。 所以我試圖澄清這個複雜的問題:
基準轉化率
基線轉化率是控製或原始版本的現有轉化率。 在設置 A/B 測試時,它通常被標記為“版本 A”。
您應該能夠在您的分析平台中找到此轉化率。
如果您從未運行過 A/B 測試,或者不知道基線轉化率,請做出最有根據的猜測。
大多數網站、垂直行業和設備類型的平均轉化率在 2% 到 5% 之間。 因此,如果您真的不確定基準轉化率,請謹慎行事,從 2% 的基准開始。
基準轉化率越低,您需要的樣本量就越大。 反之亦然。
最小可檢測效應 (MDE)
最小可檢測效應 (MDE) 聽起來像是一個複雜的概念。 但是,如果將該術語分為三個部分,它就會變得更容易理解:
- 最小= 最小
- 可檢測= 希望您通過運行實驗來檢測或發現
- 效果= 對照和治療之間的轉化差異
因此,最小可檢測效果是您希望通過運行測試檢測到的最小轉化率提升。
一些數據純粹主義者會爭辯說這個定義實際上描述了最小利益效應 (MEI)。 不管你怎麼稱呼它,目標是預測你希望通過運行測試獲得多大的轉化率提升。
雖然這個練習可能會讓人覺得很投機,但您可以使用像這樣的樣本量計算器或 Convert 的 A/B 測試統計計算器來計算預期的 MDE。
作為一個非常普遍的經驗法則,2-5% 的 MDE 被認為是合理的。 在運行真正功率適當的測試時,任何更高的值通常都是不現實的。
MDE 越小,所需的樣本量就越大。 反之亦然。
MDE 可以表示為絕對量或相對量。
絕對
絕對 MDE 是控制和變體的轉換率之間的原始數字差異。
例如,如果基線轉化率為 2.77%,而您期望變體實現 +3% 的絕對 MDE,則絕對差異為 5.77%。
相對的
相反,相對效應表示變體之間的百分比差異。
例如,如果基線轉化率為 2.77%,而您期望變體實現 +3% 的相對 MDE,則相對差異為 2.89%。
通常,大多數實驗者使用相對百分比提升,因此通常最好以這種方式表示結果。
統計功效 1−β
功效是指在假設確實存在的情況下發現效果或轉換差異的概率。
在測試中,您的目標是確保您有足夠的能力準確無誤地檢測出差異(如果存在)。 因此,更高的功率總是更好。 但代價是,它需要更大的樣本量。
0.80 的冪被認為是標準的最佳實踐。 因此,您可以將其保留為該計算器的默認範圍。
這個數量意味著有 80% 的機會,如果有影響,您將準確無誤地檢測到它。 因此,您只有 20% 的機率會錯過正確檢測效果的機會。 值得冒的風險。
顯著性水平α
作為一個非常簡單的定義,顯著性水平 alpha 是誤報率,或者檢測到轉換差異的時間百分比——即使實際上並不存在。
作為 A/B 測試最佳實踐,您的顯著性水平應為 5% 或更低。 所以你可以把它保留為這個計算器的默認值。
5% 的顯著性水平 α 意味著您有 5% 的機會發現對照和變體之間的差異——當實際不存在差異時。
同樣,值得冒的風險。
評估您的樣本量要求
將這些數字輸入計算器後,您現在可以確保您的站點有足夠的流量來在標準的 2 到 6 週測試時間段內運行適當的測試。
要進行驗證,請進入您首選的分析平台,查看您要測試的網站或頁面在有限時間內的歷史平均流量。
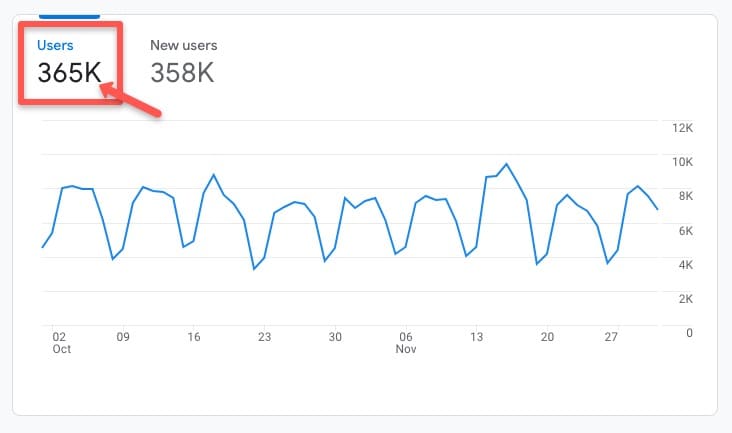
例如,在這個 Google Analytics 4 (GA4) 帳戶中,通過轉到“生命週期”>“獲取”>“獲取概覽”選項卡,您可以看到在 2022 年 10 月至 11 月的最近歷史時間段內有 36.5 萬用戶:
基於 3.5% 的現有基線轉化率、5% 的相對 MDE、80% 的標準功效和 5% 的標準顯著性水平,計算器顯示每個變體需要 174,369 名訪問者的樣本量才能正確運行-動力 A/B 測試:
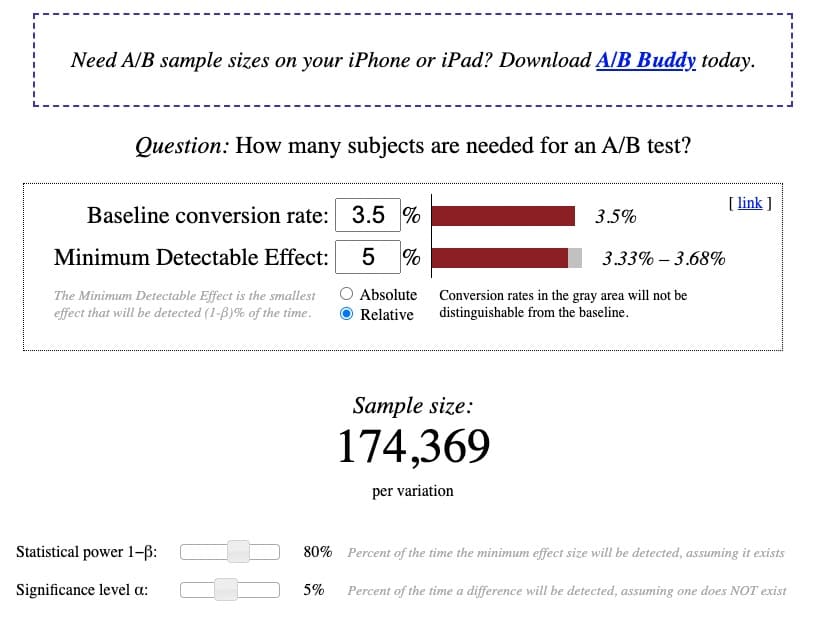
假設未來幾個月的流量趨勢保持相對穩定,則有理由預計該網站將在合理的測試時間範圍內達到約 36.5 萬用戶或(36.5 萬/2 個變體)每個變體 18.2 萬訪問者。
樣本量要求是可以實現的,為繼續進行測試開了綠燈。
重要說明,此樣本量要求驗證練習應始終在運行任何研究之前完成,以便您知道是否有足夠的流量來運行正確的測試。
此外,在運行測試時,您永遠不應該在達到預先計算的樣本量要求之前停止測試——即使結果出現得更早。
在滿足樣本量要求之前過早地宣布贏家或輸家就是所謂的“窺視”,這是一種危險的測試做法,可能導致您在結果完全出爐之前做出錯誤的判斷。
如果您有足夠的流量,您可以運行多少測試?
假設您要測試的站點或頁面滿足樣本量要求,您可以運行多少次測試?
答案是,這又取決於。
根據微軟 Bing 前實驗副總裁 Ronny Kohavi 分享的一份報告,微軟通常每天進行 300 多次實驗。
但是他們有足夠的流量來做這件事。

每個實驗都會看到超過 100,000 個用戶:
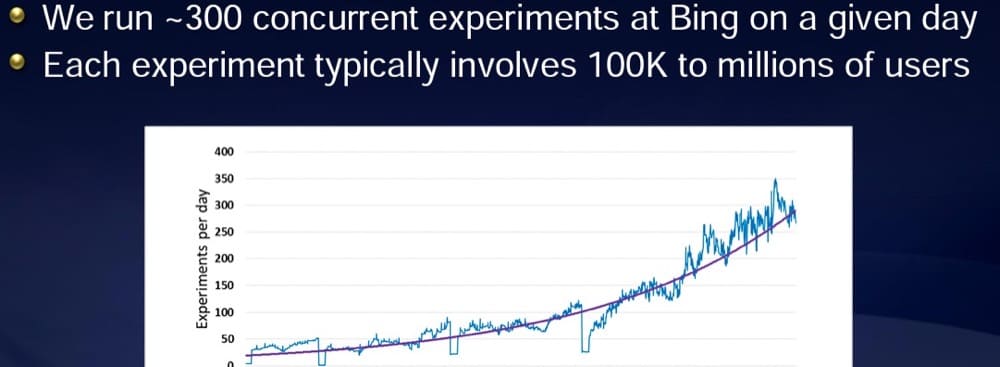
您的可用流量越大,您可以運行的測試就越多。
對於任何測試,您都需要確保您有足夠大的樣本量來運行動力充足的實驗。
如果您是流量更有限的小型組織,請考慮進行更少的更高質量測試。
歸根結底,重要的不是您運行了多少測試,而是您的實驗結果。
無法滿足樣本量要求時的選擇
如果您發現無法滿足樣本量要求,請不要擔心。 實驗對您來說並非不可能。 您有一些可用的潛在實驗選項:
- 專注於流量獲取
即使是大型網站,某些頁面的訪問量也會很低。
如果您發現網站流量或某些頁面上的流量不符合樣本量要求,請考慮集中精力獲取更多流量。
為此,您可以採取積極的搜索引擎優化 (SEO) 策略,以在搜索引擎中排名更高並獲得更多點擊次數。
您還可以通過 Google Ads、LinkedIn 廣告甚至橫幅廣告等渠道獲得付費流量。
這兩種獲取活動都可以幫助增加網絡流量,並讓您更有能力測試哪些內容最能吸引用戶。
但是,如果您確實使用付費流量來滿足樣本量要求,請考慮按流量類型對測試結果進行細分,因為訪問者的行為可能因流量來源而異。
- 評估 A/B 測試是否是最適合您的實驗方法
雖然 A/B 測試被認為是實驗的黃金標準,但結果的好壞取決於其背後的數據。
如果您發現您沒有足夠的流量來運行適當的動力測試,您可能需要考慮 A/B 測試是否真的是最適合您的實驗選擇。
還有其他基於研究的方法需要小得多的樣本,但仍然可以產生非常有價值的優化見解。
用戶體驗 (UX) 測試、消費者調查、出口民意調查或客戶訪談是您可以嘗試替代 A/B 測試的其他一些實驗方式。
- 實現結果可能僅提供方向性數據
但是,如果您仍然專注於 A/B 測試,您仍然可以運行測試。
請注意,結果可能不完全準確,只會提供表明可能(而非完全可信)結果的“方向性數據”。
由於結果可能不完全正確,因此您需要密切監控一段時間內的轉換效果。
也就是說,通常比準確的轉換數字更重要的是銀行賬戶中的數字。 如果它們在上升,您就知道您正在進行的優化工作正在發揮作用。
測試成熟度
除了樣本量要求之外,影響測試節奏的另一個因素是測試組織的成熟度級別。
測試成熟度是一個術語,用於描述組織文化中根深蒂固的實驗以及高級實驗實踐的程度。
像 Amazon、Google、Bing 和 Booking 這樣的組織——每月進行數千次測試——擁有先進、成熟的測試團隊。
這不是巧合。
測試節奏往往與組織的成熟度水平密切相關。
如果實驗在組織中根深蒂固,管理層就會致力於此。 同樣,通常鼓勵整個組織的員工支持實驗並確定實驗的優先級,甚至可以幫助提供測試想法。
當這些因素結合在一起時,運行一個權宜之計的測試程序就容易多了。
如果您希望加強測試,首先查看您組織的成熟度級別可能會有所幫助。
首先評估問題,例如
- 實驗對 C-Suite 有多重要?
- 提供哪些資源來促進實驗?
- 有哪些溝通渠道可用於傳達測試更新?
如果答案是“無”或接近於“無”,請考慮首先致力於創建測試文化。
隨著您的組織採用更先進的實驗文化,自然會更容易加快測試節奏。
有關如何創建實驗文化的建議,請查看本文和這篇文章等資源。
資源限制
假設您已經有一定程度的組織支持,下一個要解決的問題是資源限制。
時間、金錢和人力都是可能限制您測試能力的限制。 并快速測試。
要克服資源限制,從評估測試複雜性開始可能會有所幫助。
平衡簡單和復雜的測試
作為實驗者,您可以選擇運行從超級簡單到瘋狂複雜的測試。
簡單的測試可能包括優化元素,如副本或顏色、更新圖像或在頁面上移動單個元素。
複雜的測試可能涉及更改多個元素、更改頁面結構或更新轉換渠道。 這些類型的測試通常需要深入的編碼工作。
通過運行數以千計的 A/B 測試,我發現始終同時運行大約 ⅗ 更簡單和 ⅖ 更複雜的測試是很有用的。
更簡單的測試可以讓您快速、輕鬆地獲勝。
但是更大的測試,更大的變化,通常會產生更大的效果。 事實上,根據一些優化研究,您運行的測試越多、越複雜,您成功的可能性就越大。 所以不要害怕經常進行大擺動測試。
請注意,代價是您將花費更多資源來設計和構建測試。 而且不能保證它會贏。
基於現有人力資源的測試
如果您是單獨的 CRO 策略師,或者與一個小團隊合作,您的能力是有限的。 無論簡單還是複雜,您可能會發現每月 2-5 次測試對您很有幫助。
相比之下,如果您所在的組織擁有一支由研究人員、戰略家、設計師、開發人員和 QA 專家組成的專門團隊,您可能有能力每月運行數十到數百次測試。
要確定您應該運行多少測試,請評估您的人力資源可用性。
平均而言,一個簡單的測試可能需要 3-6 個小時來構思、線框、設計、開發、實施、QA 和監控結果。
另一方面,高度複雜的測試可能需要 15-20 小時以上的時間。
一個月大約有 730 小時,因此您需要對測試和測試數量進行非常計算,您在這段寶貴的時間裡運行。
計劃並優先考慮您的測試想法
為了幫助您規劃出最佳測試結構,請考慮使用測試優先級框架,例如 PIE、ICE 或 PXL。
這些框架提供了一種定量技術,用於對您的最佳測試想法進行排名、評估實施的難易程度以及評估哪些測試最有可能提升轉化率。
進行此評估後,您的測試想法優先列表將如下所示:

在對您的最佳測試想法進行排名後,還建議您創建一個測試路線圖,以直觀地規劃您的測試時間表和後續步驟。
您的路線圖可能如下所示:
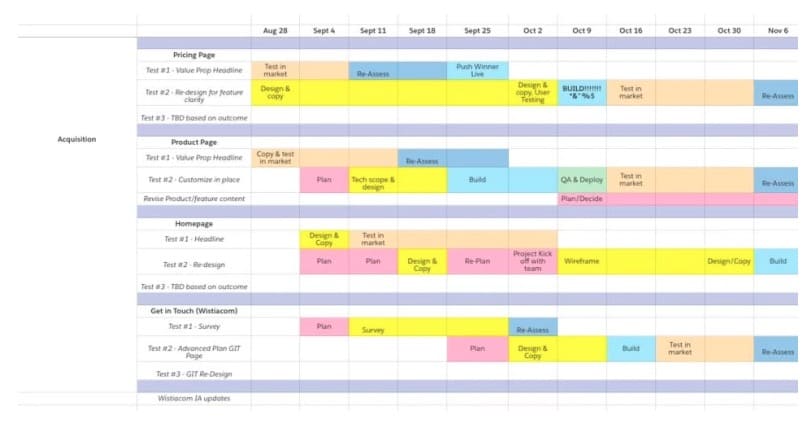
它應該包括:
- 您計劃測試的想法列表,按頁顯示。
- 您預計每個測試階段(設計、開發、QA 等)將花費多長時間。
- 根據預先計算的樣本量要求,您計劃運行每個測試多長時間。 您可以使用像這樣的測試持續時間計算器來計算測試持續時間要求。
通過規劃您的測試想法,您將能夠更準確地確定測試節奏和容量。
當您填充測試路線圖時,您可能會很清楚可以運行的測試數量取決於您可用的資源。
你應該一次運行多個測試嗎?
但僅僅因為你可以做某事,並不總是意味著你應該做。
當談到一次運行多個測試時,關於最佳方法的爭論很大。
Experiment Nation 領導人 Rommil Santiago 的文章,如這篇文章,提出了一個有爭議的問題:同時運行多個 A/B 測試是否可以?
有的實驗者會說,絕對不會!
他們會爭辯說你應該只運行一個測試,一次一頁。 否則,您將無法正確隔離任何效果。
我曾經參加過這個營地,因為那是近十年前我被教導的方式。
嚴格地告訴我,你一次只能在一頁上運行一個測試,進行一次更改。 多年來,我一直以這種心態運作——這讓那些想要更快獲得更多結果的焦慮客戶感到沮喪。
然而,Facebook 前數據科學家、現任 Statsig 首席數據科學家 Timothy Chan 的這篇文章徹底改變了我的想法。
Chan 認為,在他的文章中,交互作用被高估了。
事實上,同時運行多個測試不僅不是問題; 這真的是唯一的測試方法!
這一立場得到了他在 Facebook 期間的數據的支持,Chan 看到這家社交媒體巨頭同時成功地進行了數百項實驗,其中許多實驗甚至在同一頁面上進行。
Ronny Kohavi 和 Hazjier Pourkhalkhali 等數據專家一致認為:交互效應的可能性很小。 而且,事實上,測試成功的最佳方法是在持續的基礎上多次運行多個測試。
所以,在考慮測試節奏時,不要擔心重疊測試的交互效果。 自由測試。
概括
在 A/B 測試中,您應該運行的 A/B 測試沒有最佳數量。
理想的數字是適合您的獨特情況的數字。
這個數字基於幾個因素,包括您站點的樣本大小限制、測試想法的複雜性以及可用的支持和資源。
最後,與其說是你運行的測試數量,不如說是測試的質量和你獲得的結果。 帶來巨大提升的單個測試遠比沒有移動針頭的多個不確定測試更有價值。
測試確實是關於質量而不是數量!
有關如何從 A/B 測試程序中獲得最大價值的更多信息,請查看這篇 Convert 文章。

