
如何處理機器人放牧和蜘蛛爭奪排名?
已發表: 2020-01-23
Google 抓取工具會將您在網站上發布的每條內容都編入索引。 這些爬蟲是經過編程的軟件,它們跟踪鏈接和代碼並將其傳遞給算法。 然後,算法將其編入索引並將您的內容添加到龐大的數據庫中。 這樣,每當用戶搜索關鍵字時,搜索引擎都會從已索引頁面的數據庫中提取相關結果並對其進行排名。
Google 會為每個網站分配一個抓取預算,並且抓取工具會相應地執行您網站的抓取。 您必須管理和利用抓取預算,以確保對整個網站進行智能抓取和索引。
在這篇文章中,您可以了解處理搜索引擎機器人/蜘蛛或爬蟲如何抓取和索引您的網站的技巧和工具。
1、優化Robot.txt的Disallow指令:

Robots.txt 是一個具有嚴格語法的文本文件,它的作用類似於蜘蛛確定如何抓取您的網站的指南。 robots.txt 文件保存在您網站的主機存儲庫中,爬蟲可從該存儲庫中查找 URL。 要優化這些 Robots.txt 或“機器人排除協議”,您可以使用一些技巧來幫助您網站的 URL 被 Google 爬蟲抓取以獲得更高的排名。
其中一個技巧是使用“禁止指令” ,這就像在您網站的特定部分放置“限制區域”的招牌。 要優化 Disallow 指令,您必須了解第一道防線: “用戶代理”。
什麼是用戶代理指令?
每個 Robots.txt 文件都包含一個或多個規則,其中,用戶代理規則最為重要。 此規則為爬蟲提供對網站上特定列表的訪問權和非訪問權。
因此,用戶代理指令用於尋址特定的爬蟲,並為它提供有關如何執行爬蟲的指令。
常用的谷歌爬蟲類型:

禁止指令:
現在,在了解了用於抓取您網站的機器人之後,您可以根據用戶代理的類型優化它的不同部分。 您可以遵循一些基本技巧和示例來優化您網站的 disallow 指令:
- 使用可在瀏覽器中顯示的完整頁面名稱以用於禁止指令。
- 如果要從目錄路徑重定向爬蟲,請使用“/”標記。
- 使用 * 表示路徑前綴、後綴或整個字符串。
使用 disallow 指令的示例如下:
# 示例 1:僅阻止 Googlebot
用戶代理:Googlebot
不允許: /
# 示例 2:阻止 Googlebot 和 Adsbot
用戶代理:Googlebot
用戶代理:AdsBot-Google
不允許: /
# 示例 3:阻止除 AdsBot 爬蟲之外的所有爬蟲
用戶代理: *
不允許: /
2. Robots.txt 的非索引指令:
當其他網站鏈接到您的網站時,您不希望爬蟲索引的 URL 可能會被暴露。 要解決此問題,您可以使用非索引指令。 讓我們看看,我們如何將非索引指令應用於 Robots.txt:
有兩種方法可以為您的網站應用非索引指令:
<元> 標籤:
元標記是以簡短的透視方式描述頁面內容的文本片段,讓訪問者知道接下來會發生什麼? 我們可以使用相同的方法來避免爬蟲索引頁面。
首先,在頁面的“<head>”部分放置一個元標記“<meta name=”robots” content=”noindex”>”,您不希望抓取工具對其進行索引。
對於 Google 爬蟲,您可以在“<head>”部分使用“<meta name=”googlebot” content=”noindex”/>”。
由於不同的搜索引擎爬蟲正在尋找您的頁面,它們可能會以不同的方式解釋您的非索引指令。 因此,您的頁面可能會出現在搜索結果中。
因此,如果您根據爬蟲或用戶代理為頁面定義指令,將會有所幫助。
您可以使用以下元標記將指令應用於不同的爬蟲:
<元名稱=”googlebot” 內容=”noindex”>
<元名稱=”googlebot-news” 內容=”nosnippet”>
X-Robots 標籤:
我們都知道 HTTP 標頭用於響應客戶端或搜索引擎對與您的網頁相關的額外信息(例如位置或提供它的服務器)的請求。 現在,要針對非索引指令優化這些 HTTP 標頭響應,您可以添加 X-Robots 標記作為您網站的任何給定 URL 的 HTTP 標頭響應的元素。
您可以將不同的 X-Robots 標籤與 HTTP 標頭響應結合起來。 您可以在以逗號分隔的列表中指定各種指令。 下面是一個 HTTP 標頭響應示例,其中包含不同指令和 X-Robots 標籤。
HTTP/1.1 200 正常
日期:格林威治標準時間 2020 年 1 月 25 日星期二 21:42:43
(……)
X-Robots-標籤:noarchive
X-Robots-標籤:不可用_之後:2020 年 7 月 25 日 15:00:00 PST
(……)

3.掌握規範鏈接: 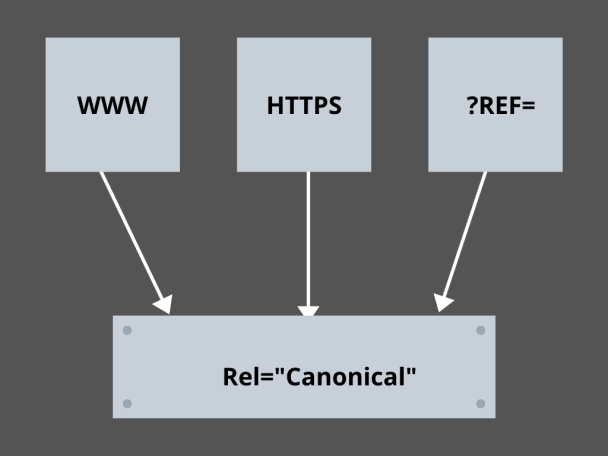
當今 SEO 中最可怕的因素是什麼? 排名? 交通? 不! 擔心搜索引擎會因重複內容而懲罰您的網站。 因此,在製定抓取預算策略時,您需要注意不要暴露重複的內容。
在這裡,掌握您的規範鏈接將幫助您處理重複的內容問題。 重複內容這個詞不是它的意思。 讓我們以電子商務網站的兩個頁面為例:
例如,您有一個電子商務網站,其中包含一對相同的智能手錶頁面,並且兩者都有相似的內容。 當搜索引擎機器人抓取您的 URL 時,它們會檢查重複的內容,並且它們可能會選擇任何 URL。 要將它們重定向到對您至關重要的 URL,可以為頁面設置規範鏈接。 讓我們看看你是怎麼做到的:
- 從兩頁中選擇任何一頁作為您的規範版本。
- 選擇接待更多訪客的那個。
- 現在將 rel=”canonical” 添加到您的非規範頁面。
- 將非規範頁面鏈接重定向到規範頁面。
- 它將您的兩個頁面鏈接合併為一個規範鏈接。
4. 構建網站:
爬蟲需要標記和招牌來幫助他們發現您網站的重要 URL,如果您不構建您的網站,爬蟲會發現很難對您的 URL 執行爬網。 為此,我們使用站點地圖,因為它們為爬蟲提供了指向您網站所有重要頁面的鏈接。
通過移動應用程序開發流程開發的網站甚至應用程序的標準站點地圖格式是 XML 站點地圖、Atom 和 RSS。 要優化抓取,您需要結合 XML 站點地圖和 RSS/Atom 提要。
- 由於 XML 站點地圖為爬蟲提供了指向您網站或應用程序上所有頁面的路線。
- 並且 RSS/Atom 提要在您的網站頁面中向爬蟲提供更新。
- 由於 XML 站點地圖為爬蟲提供了指向您網站或應用程序上所有頁面的路線。
5. 頁面導航:
頁面導航對於蜘蛛甚至您網站的訪問者來說都是必不可少的。 這些靴子在您的網站上查找頁面,預定義的層次結構可以幫助爬蟲找到對您的網站重要的頁面。 要獲得更好的頁面導航,要遵循的其他步驟是:
- 將編碼保留在 HTML 或 CSS 中。
- 分層排列您的頁面。
- 使用淺層網站結構以獲得更好的頁面導航。
- 使標題上的菜單和選項卡保持最小和具體。
- 它將幫助頁面導航更容易。
6.避免蜘蛛陷阱:
蜘蛛陷阱是當抓取工具抓取您的網站時,指向相同頁面上相同內容的無限 URL。 這更像是射擊空白。 最終,它會吃掉你的爬蟲預算。 此問題會隨著每次爬網而升級,並且您的網站被認為具有重複的內容,因為在陷阱中爬網的每個 URL 都不是唯一的。
您可以通過 Robots.txt 阻止該部分來打破陷阱,或者使用跟隨或不跟隨指令之一來阻止特定頁面。 最後,您可以通過阻止無限 URL 的出現來從技術上解決問題。
7.鏈接結構:
互連是爬網優化的重要組成部分之一。 爬蟲可以通過整個網站結構良好的鏈接更好地找到您的頁面。 一個偉大的鏈接結構的一些關鍵技巧是:
- 使用文本鏈接,因為搜索引擎很容易抓取它們: <a href=”new-page.html”>文本鏈接</a>
- 在鏈接中使用描述性錨文本
- 假設您經營一個健身房網站,並且想要鏈接您所有的健身房視頻,您可以使用這樣的鏈接 - 隨意瀏覽我們所有的<a href=”videos.html”>健身房視頻</a>。
8. HTML 幸福:
清理您的 HTML 文檔並保持 HTML 文檔的有效負載大小最小很重要,因為它允許爬蟲快速爬取 URL。 HTML 優化的另一個優點是,由於搜索引擎的多次抓取,您的服務器會負載過重,這可能會減慢您的頁面加載速度,這對於 SEO 或搜索引擎抓取來說不是一個好兆頭。 HTML優化可以減少服務器的爬取負載,保持頁面加載迅速。 它還有助於解決由於服務器超時或其他重要問題導致的抓取錯誤。
9.嵌入簡單:
今天,任何網站都不會提供沒有精美圖像和視頻來支持內容的內容,因為這使得它們的內容在視覺上更具吸引力,並且對於搜索引擎爬蟲來說更容易獲得。 但是,如果這個嵌入的內容沒有被優化,它會降低加載速度,讓爬蟲遠離你可以排名的內容。
在這裡,堅持嵌入內容的 HTML 有助於更好地從搜索引擎中抓取。 AJAX、Javascript 等技術非常擅長提供新功能,但它們也使搜索引擎的抓取變得相當棘手。
結論:
隨著對 SEO 和更高流量的更多關注,每個網站所有者都在尋找更好的方法來處理機器人群聚和蜘蛛爭吵。 但是,解決方案在於您需要在您的網站和抓取 URL 中進行細粒度優化,這可以使搜索引擎抓取更加具體和優化,以代表您的網站中可以在搜索引擎結果頁面中排名更高的最佳網站。