
Google 核心更新:YMYL 網站的影響、問題和解決方案
已發表: 2019-12-04在本案例研究中,我將研究 Hangikredi.com,它是土耳其最大的金融和數字資產之一。 我們將看到技術 SEO 副標題和一些圖形。
該案例研究在兩篇文章中介紹。 本文介紹了 3 月 12 日的 Google 核心更新,該更新對網站產生了強烈的負面影響,以及我們採取了哪些措施來抵消它。 我們將研究 13 個技術問題和解決方案,以及整體問題。
閱讀第二部分,了解我如何應用從這次更新中學到的知識,成為每次 Google 核心更新的贏家。
問題和解決方案:修復 3 月 12 日 Google 核心更新的影響
在 3 月 12 日核心算法更新之前,根據分析數據,網站的一切都很順利。 一天之內,核心算法更新的消息傳出後,排名大跌,辦公室裡一片沮喪。 我個人沒有看到那一天,因為我是在 14 天后他們僱用我開始新的 SEO 項目和流程時才到的。
[案例研究] 通過日誌文件分析提高排名、自然訪問量和銷售額
 閱讀案例研究
閱讀案例研究3 月 12 日核心算法更新後公司網站的損壞報告如下:
- 36% 有機會話損失
- 65% 點擊率下降
- 30% 點擊率損失
- 33% 自然用戶流失
- 每天損失 100 000 次展示。
- 9.72% 印象損失
- 8 000 個關鍵詞丟失

現在,正如我們在案例研究文章開頭所說的那樣,我們應該問一個問題。 我們不能問“下一次核心算法更新什麼時候發生?” 因為它已經發生了。 只剩下一個問題。
“谷歌在我和我的競爭對手之間考慮了哪些不同的標準?”
從上圖和損壞報告中可以看出,我們失去了主要流量和關鍵字。
1.問題:內部鏈接
我注意到,當我第一次檢查內部鏈接數、錨文本和鏈接流時,我的競爭對手領先於我。
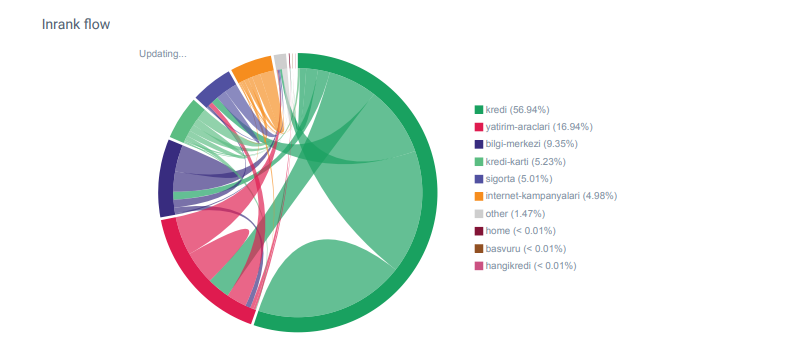
來自 OnCrawl 的 Hangikredi.com 類別的 Linkflow 報告
我的主要競爭對手擁有超過 340 000 個內部鏈接和數千個錨文本。 在這些日子裡,我們的網站只有 70 000 個沒有有價值的錨文本的內部鏈接。 此外,缺乏內部鏈接影響了網站的抓取預算和生產力。 儘管我們 80% 的流量僅在 20 個產品頁面上收集,但我們網站的 90% 包含為用戶提供有用信息的指南頁面。 我們的財務查詢的大部分關鍵字和相關性得分都來自這些頁面。 而且,孤頁數不勝數。
由於缺少內部鏈接結構,當我使用 Kibana 進行日誌分析時,我注意到爬取次數最多的頁面是流量最少的頁面。 此外,當我將其與內部鏈接網絡配對時,我發現流量最低的公司頁面(隱私、Cookie、安全、關於我們頁面)具有最大數量的內部鏈接。
正如我將在下一節中討論的那樣,這導致 Googlebot 在爬取網站時從 Pagerank 中刪除了內部鏈接因素,並意識到內部鏈接沒有按預期構建。
2. 問題:網站架構、國際網頁排名、流量和爬網效率
根據 Google 的聲明,內部鏈接和錨文本有助於 Googlebot 了解網頁的重要性和上下文。 內部 Pagerank 或 Inrank 的計算基於多個因素。 根據 Bill Slawski 的說法,內部或外部鏈接並不完全相同。 Pagerank 流的鏈接值根據其位置、種類、樣式和字體粗細而變化。

如果 Googlebot 了解哪些頁面對您的網站很重要,它會更多地抓取它們並更快地將它們編入索引。 內部鏈接和正確的站點樹設計是其中的重要因素。 多年來,其他專家也對這種相關性發表了評論:
“大多數鏈接確實通過它們的錨文本提供了一些額外的上下文。 至少他們應該,對吧?”
——約翰·穆勒,谷歌 2017“如果您認為您的網站上有重要的頁面,請不要將它們隱藏在您的網站深處 15 個鏈接,我不是在談論目錄長度,我說的是實際您必須點擊 15 個鏈接才能找到該頁面如果有一個頁面很重要,或者有很大的利潤空間或者轉化率真的——嗯——升級,從你的根頁面放置一個指向該頁面的鏈接,這是很有意義的事情。”
——馬特·卡茨,谷歌 2011“如果一個頁面使用“聯繫人”或“關於”一詞鏈接到另一個頁面,並且鏈接到的頁麵包含地址,則該地址位置可能被認為與進行該鏈接的頁面相關。”
12 種可能已經改變的 Google 鏈接分析方法——Bill Slawski
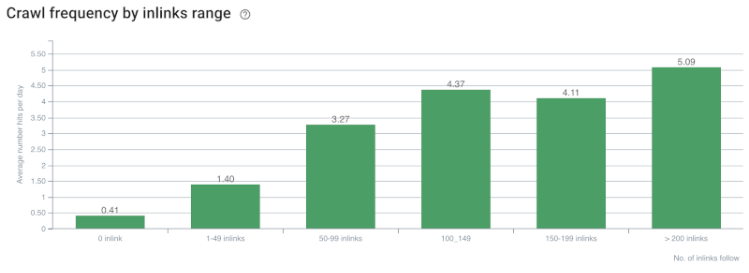
爬網率/需求和內部鏈接計數相關性。 資料來源:OnCrawl。
到目前為止,我們可以做出以下推論:
- 谷歌關心點擊深度。 如果一個網頁離主頁更近,它應該更重要。 John Mueller 在 2018 年 7 月 1 日英語谷歌網站管理員環聊中也證實了這一點。
- 如果一個網頁有很多指向它的內部鏈接,那麼它應該很重要。
- 錨文本可以賦予網頁上下文的力量。
- 內部鏈接可以根據其位置、類型、字體粗細或樣式傳輸不同的 Pagerank 數量。
- 向搜索引擎爬蟲提供有關內部頁面權限的明確消息的 UX 友好型站點樹是 Inrank 分發和爬網效率的更好選擇。
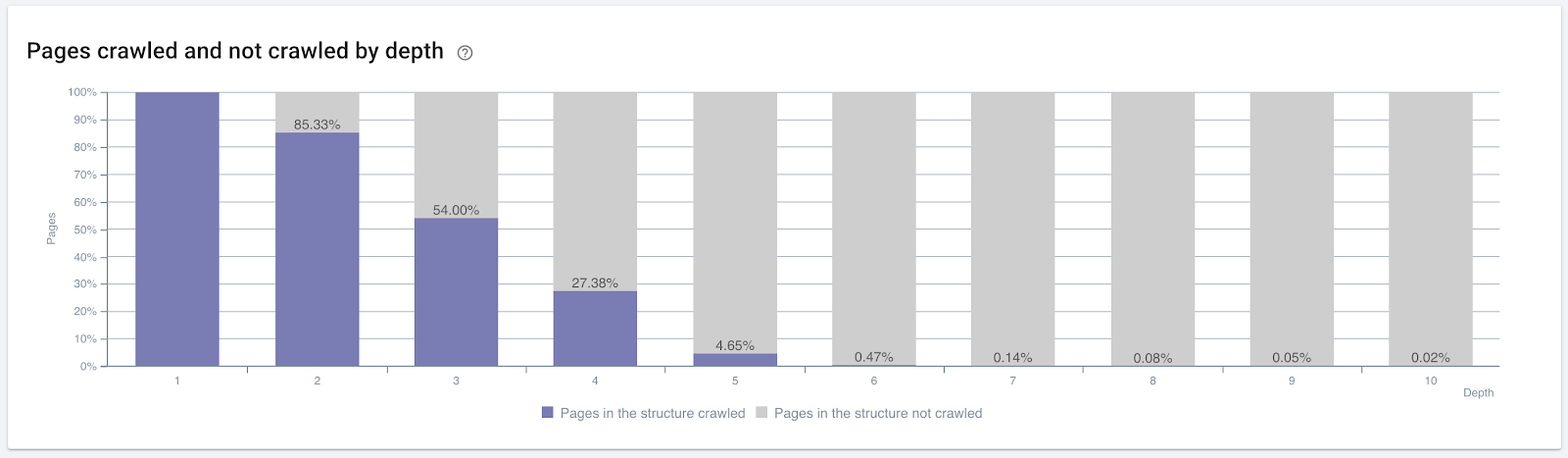
按點擊深度抓取的頁面百分比。 資料來源:OnCrawl。
但這些還不足以了解內部鏈接的性質和對爬網效率的影響。
Oncrawl 搜索引擎優化爬蟲
 學到更多
學到更多如果您最內部鏈接的頁面沒有產生流量或被點擊,它會發出信號,表明您的站點樹和內部鏈接結構不是根據用戶意圖構建的。 谷歌總是試圖找到與用戶意圖或搜索實體最相關的頁面。 我們從 Bill Slawski 那裡得到另一個引文,使這個主題更加清晰:
“如果一個資源與通過使用這些鏈接接收的流量不成比例的多個資源鏈接,則該資源可能會在排名過程中被降級。”
土撥鼠更新剛剛發生在谷歌嗎? — 比爾·斯拉夫斯基“導致停留時間長(例如,大於閾值時間段)的選擇的選擇質量分數可能高於導致短停留時間的選擇的選擇質量分數。”
土撥鼠更新剛剛發生在谷歌嗎? — 比爾·斯拉夫斯基
所以我們還有兩個因素:
- 鏈接頁面中的停留時間。
- 鏈接產生的用戶流量。
內部鏈接數量和样式/位置不是唯一的因素。 關注這些鏈接的用戶數量及其行為指標也很重要。 此外,我們知道被點擊/訪問的鏈接和頁面被 Google 抓取的次數遠遠多於未被點擊或訪問的鏈接和頁面。
“我們越來越傾向於了解網站的各個部分,以了解這些部分的質量。”
John Mueller,2017 年 5 月 2 日,英文版 Google Webmasters Hangout。
鑑於所有這些因素,我將分享兩個不同且不同的 Pagerank Simulator 結果:
這些 Pagerank 計算是在假設所有頁面都相等的情況下進行的,包括主頁。 真正的區別是由鏈接層次結構決定的。
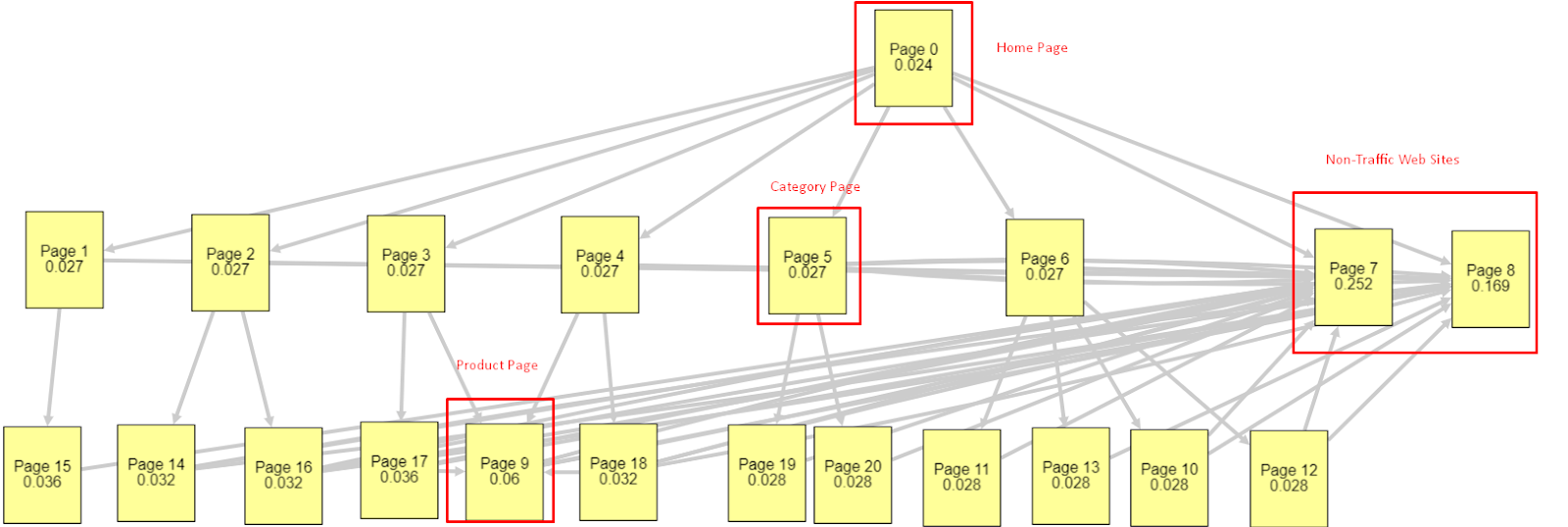
此處顯示的示例更接近 3 月 12 日之前的內部鏈接結構。 主頁 PR:0.024,類別頁面 PR:0.027,產品頁面 PR:0.06,非流量網頁 PR:0.252。
您可能會注意到,Googlebot 無法信任這種內部鏈接結構來計算內部頁面排名和內部頁面的重要性。 非流量和無產品頁面的權限是主頁的 12 倍。 它不僅有產品頁面。

這個例子更接近我們在 6 月 5 日核心算法更新之前的情況。主頁 PR:0.033,類別頁面:0,037,產品頁面:0,148 和非流量頁面的 PR:0,037。
您可能會注意到,內部鏈接結構仍然不正確,但至少非流量網頁沒有比類別頁面和產品頁面更多的 PR。
有什麼進一步的證據表明谷歌根據用戶流量和請求和意圖將內部鏈接和站點結構排除在 Pagerank 範圍之外? 當然 Googlebot 的行為與 Inlink Pagerank 和 Ranking 相關性:
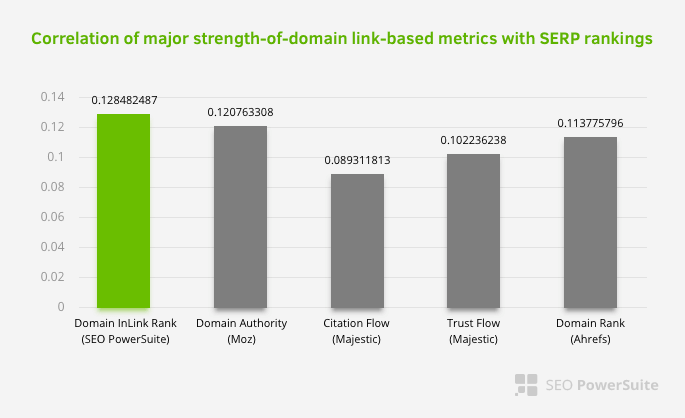
這並不意味著內部鏈接網絡尤其比其他因素更重要。 專注於單點的 SEO 視角永遠不會成功。 在第三方工具之間的比較中,它表明內部 Pagerank 值相對於其他標準正在進步。
根據 Aleh Barysevich 的 Inlink Rank 和排名相關性研究,內部鏈接最多的頁面的排名高於網站的其他頁面。 根據 2019 年 3 月 4 日至 6 日進行的調查,根據 33,500 個關鍵字的內部 Pagerank 指標分析了 1,000,000 個頁面。 SEO PowerSuite 進行的這項研究的結果與 Moz、Majestic 和 Ahrefs 的不同指標進行了比較,並給出了更準確的結果。
以下是 3 月 12 日核心算法更新之前我們網站的一些內部鏈接號:
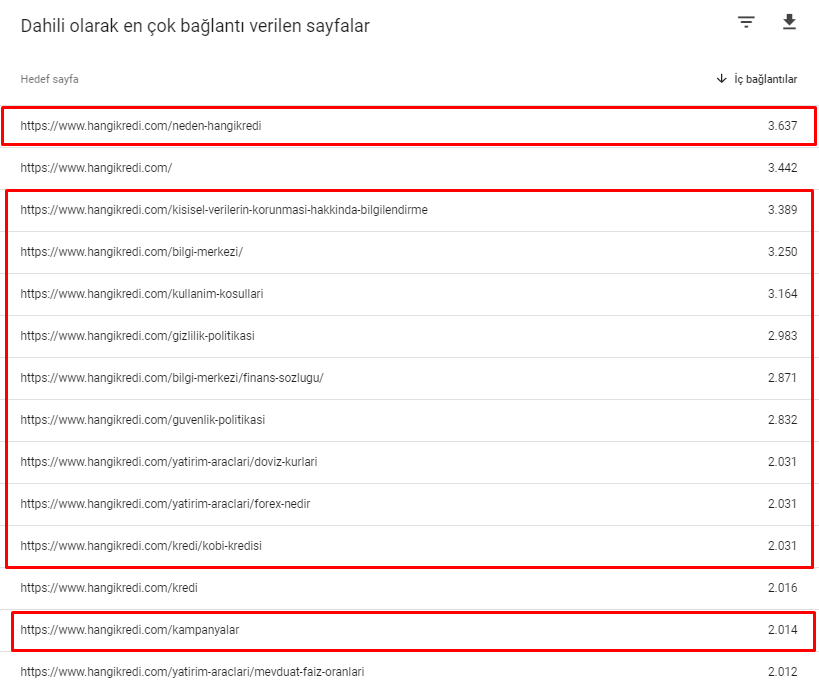
如您所見,我們的內部連接方案並沒有反映用戶意圖和流量。 獲得最少訪問量的頁面(次要產品頁面)或從未獲得訪問量的頁面(紅色)直接在 1st Click Depth 並從首頁獲得 PR。 有些甚至比主頁有更多的內部鏈接。
鑑於這一切,我們只能在這個主題上展示最後兩點。
- 對內部鏈接最多的頁面的抓取率/需求
- 鏈接雕刻和Pagerank
在 2 月 1 日至 3 月 31 日期間,以下是 Googlebot 最常抓取的網頁:
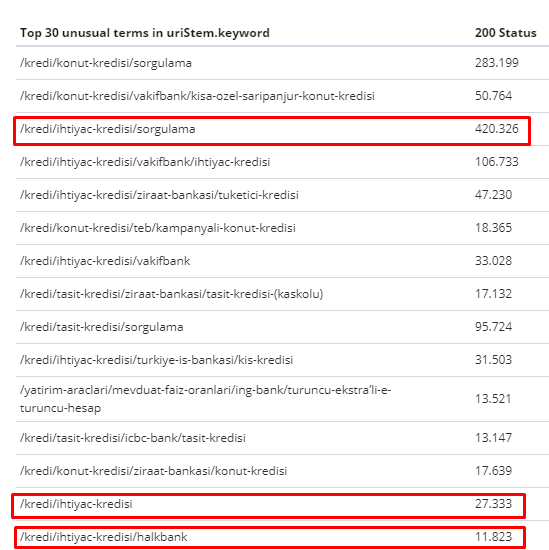
您可能會注意到,抓取的頁面和具有最多內部鏈接的頁面彼此完全不同。 內部鏈接最多的頁面不便於用戶使用; 他們沒有有機關鍵字或任何類型的直接 SEO 價值。 (
紅色框中的 URL 是我們訪問量最大和最重要的產品頁麵類別。 此列表中的其他頁面是訪問量第二或第三的重要類別。)
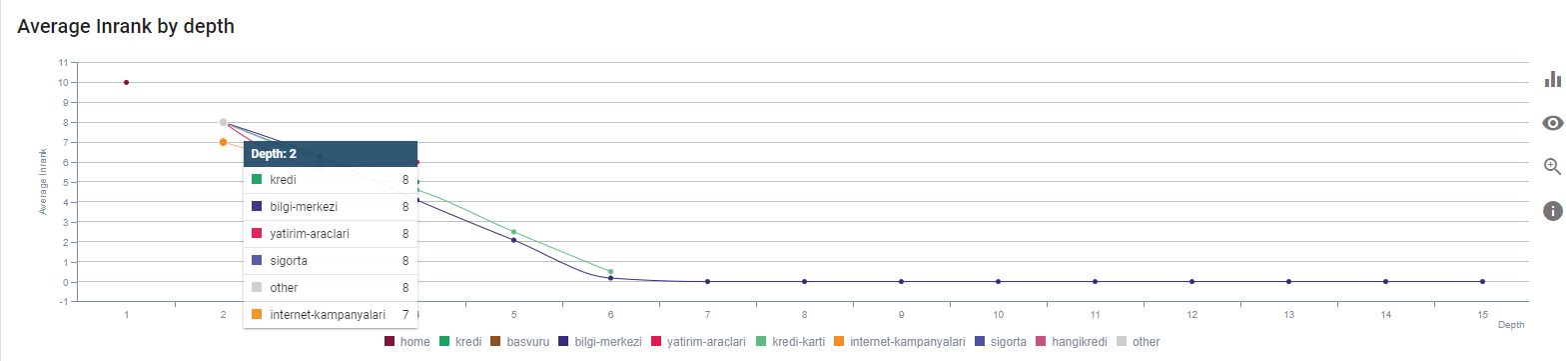
我們當前按頁面深度排列的 Inrank。 資料來源:Oncrawl。
什麼是鏈接雕刻以及如何處理內部未遵循的鏈接?
與大多數 SEO 認為的相反,標有“nofollow”標籤的鏈接仍然傳遞內部 Pagerank 值。 對我來說,這麼多年過去了,沒有人比 Matt Cutts 在他 2009 年 6 月 15 日的 Pagerank Sculpting 文章中更好地敘述了這個 SEO 元素。
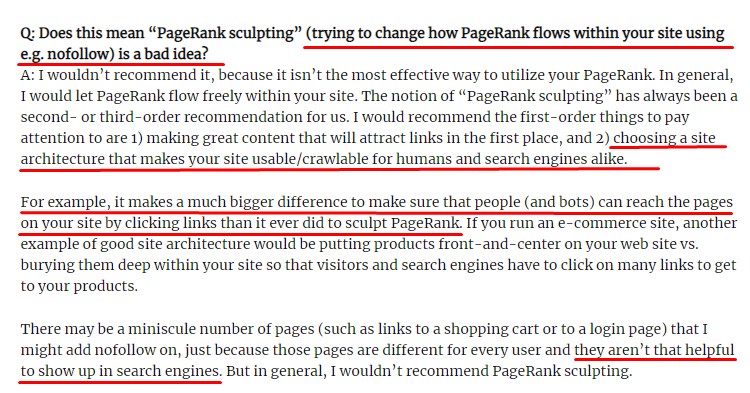
Link Sculpting 的一個有用部分,它顯示了 Pagerank Sculpting 的真正用途。
“我建議不要在網站內使用 nofollow 來進行 PageRank 雕刻,因為它可能不會像您認為的那樣做。”
——約翰·穆勒,谷歌 2017
如果您的網頁在 Google 和用戶方面毫無價值,則不應將它們標記為“nofollow”。 它不會停止 Pagerank 流程。 您應該從 robots.txt 文件中禁止它們。 這樣,Googlebot 不會抓取它們,也不會將內部 Pagerank 傳遞給它們。 但正如十年前馬特卡茨所說,你應該只將它用於真正毫無價值的頁面。 為聯屬網絡營銷進行自動重定向的頁面或幾乎沒有內容的頁面是這裡的一些方便示例。
解決方案:更好更自然的內部鏈接結構
我們的競爭對手有一個劣勢。 他們的網站有更多的錨文本,更多的內部鏈接,但它們的結構並不自然和有用。 在他們網站的每個頁面上,相同的錨文本與相同的句子一起使用。 每個頁面的條目段落都覆蓋了這種重複的內容。 每個用戶和搜索引擎都可以很容易地認識到,這不是一個考慮用戶利益的自然結構。
所以我決定做三件事來修復內部鏈接結構:
- 站點信息架構或站點樹應該遵循與放置在內容中的鏈接不同的路徑。 它應該更緊密地跟隨用戶的思想和關鍵字神經網絡。
- 在每條內容中,側關鍵字應與目標頁面的主要關鍵字一起使用。
- 錨文本應該自然,適應內容,並且應該在每個頁面的不同點使用,同時注意用戶的感知
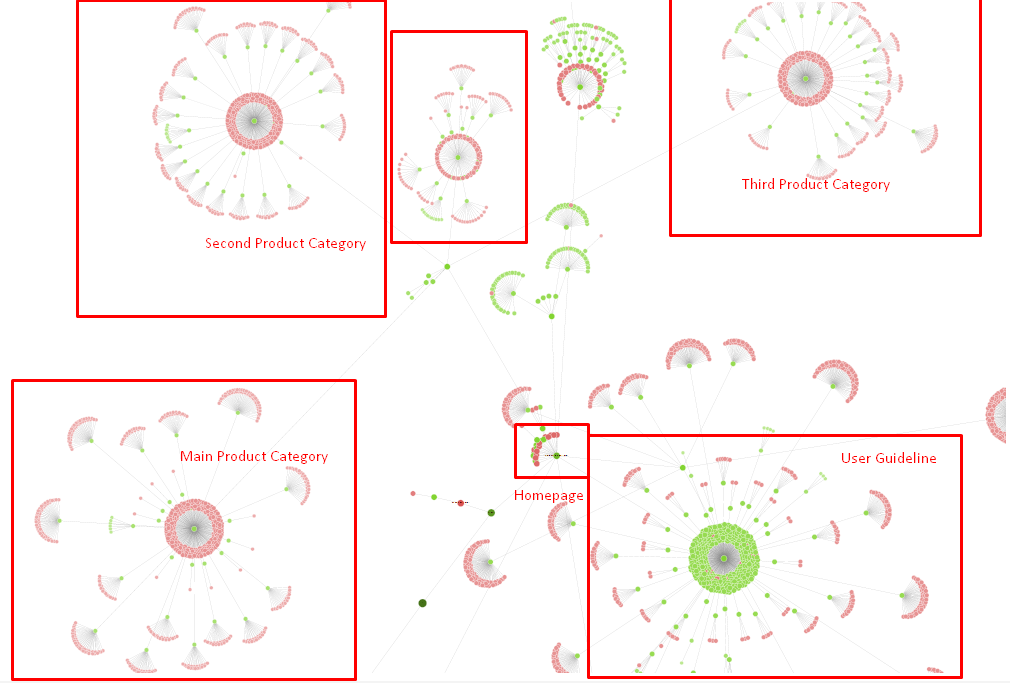
我們現在的站點樹和鏈接結構的一部分。
在上圖中,您可以看到我們當前的內部鏈接鏈接和站點樹。
我們為解決此問題所做的一些事情如下:
- 我們用有用的錨創建了 30 000 多個內部鏈接。
- 我們為用戶使用了自然景點和關鍵詞。
- 我們沒有使用重複的句子和模式進行內部鏈接。
- 我們向 Googlebot 提供了有關網頁 Inrank 的正確信號。
- 我們通過日誌分析檢查了正確的內部鏈接結構對爬取效率的影響,我們發現與之前的統計數據相比,我們的主要產品頁面被爬取的次數更多。
- 為孤立頁面創建了超過 50 000 個內部鏈接。
- 使用主頁內部鏈接為子頁面提供動力,並在主頁上創建更多內部鏈接源。
- 為了保護 Pagerank Power,我們還對一些不必要的外部鏈接使用了 nofollow 標籤。 (這不是關於內部鏈接,但它服務於相同的目標。)
3.問題:內容結構
谷歌表示,對於 YMYL 網站,可信度和權威性比其他類型的網站更重要。

在過去,關鍵字只是關鍵字。 但現在,它們也是定義明確的、單一的、有意義的和可區分的實體。 在我們的內容中,有四個主要問題:
- 我們的內容很短。 (通常,內容的長度並不重要。但在這種情況下,它們沒有包含足夠的主題信息。)
- 我們作家的名字作為一個實體不是單一的、有意義的或可區分的。
- 我們的內容對眼睛不友好。 換句話說,它不是“快餐”內容。 這是沒有副標題的內容。
- 我們使用營銷語言。 在一個段落的空間中,我們可以為用戶識別品牌名稱及其廣告。
- 有很多按鈕可以將用戶從信息頁面引導到產品頁面。
- 在我們產品頁面的內容中,沒有足夠的信息或全面的指南。
- 設計不是用戶友好的。 我們對字體和背景使用基本相同的顏色。 (由於基礎設施問題,大多數情況仍然如此。)
- 圖片和視頻並未被視為內容的一部分。
- 特定關鍵字的用戶意圖和搜索意圖以前並不被視為重要。
- 同一主題有很多重複、不必要和重複的內容。
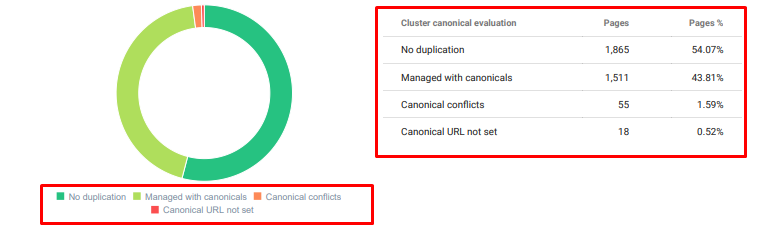
Oncrawl 從今天開始重複內容審核。
解決方案:更好的用戶信任內容結構
在檢查站點範圍的問題時,使用站點範圍的審計程序作為助手是組織花在 SEO 項目上的時間的更好方法。 與內部鏈接部分一樣,我使用了 Oncrawl Site Audit 以及其他工具和 Xpath 檢查。
首先,解決內容部分中的每個問題會花費太多時間。 在那些崩潰的危機日子裡,時間是一種奢侈。 所以我決定解決速成問題,例如:
- 刪除重複、不必要和重複的內容
- 統一缺乏全面信息的簡短內容
- 重新發布缺少副標題和眼球追踪結構的內容
- 在內容中固定密集的營銷基調
- 從內容中刪除大量號召性用語按鈕
- 通過圖像和視頻更好地進行視覺傳達
- 使內容和目標關鍵字與用戶和搜索意圖兼容
- 在內容中使用和展示金融和教育實體以獲得信任
- 使用社交社區創建社會認可證明
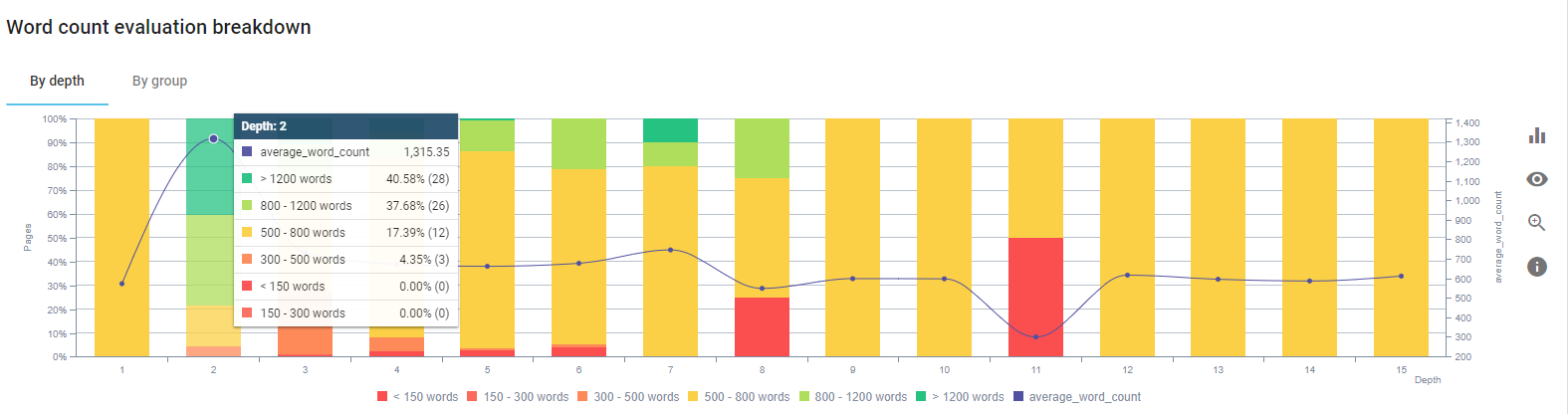

我們專注於修復產品頁面和最接近它們的指南頁面的內容。
在此過程開始時,我們的大多數產品和交易登陸/指南頁面都少於 500 字,沒有全面的信息。
在 25 天內,我們開展的行動如下:
- 刪除了包含重複、不必要和重複內容的 228 頁。 (在刪除過程之前檢查了 Ccontent 的反向鏈接配置文件。我們使用 301 或 410 狀態代碼來更好地與 Googlebot 通信。)
- 合併超過 123 頁,缺乏全面的信息。
- 根據內容的重要性和用戶需求使用副標題。
- 刪除了帶有營銷風格語言的品牌名稱和 CTA 按鈕。
- 在圖像中包含文本以強化主題。
這是谷歌 Vision AI 的截圖。 Google 可以讀取圖像中的文本並檢測實體中的感受和身份。
- 激活我們的社交網絡以吸引更多用戶。
- 檢查競爭對手與我們之間的內容差距,並創建了 80 多個新內容。
- 使用 Google Analytics、Search Console 和 Google Data Studio 來確定跳出率高、流量低的表現不佳的頁面。
- 對精選片段及其關鍵字和內容結構進行了研究。 我們在相關內容中添加了相同的標題和內容結構,這增加了我們的精選片段。
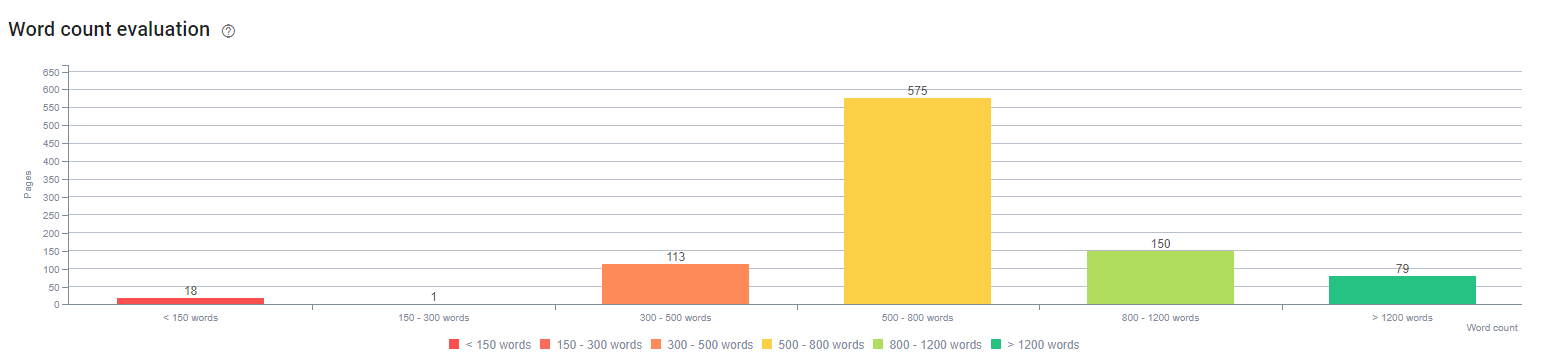
在這個過程開始時,我們的內容主要由 150 到 300 個單詞組成。 我們網站範圍內的平均內容長度增加了 350 個字。
4. 問題:索引污染、膨脹和規範標籤
谷歌從未就索引污染髮表過聲明,事實上我不確定是否有人曾將其用作 SEO 術語。 應該從 Google 索引頁面中刪除所有對 Google 沒有意義以獲得更有效的索引分數的頁面。 導致索引污染的頁面是幾個月沒有產生流量的頁面。 他們的點擊率為零,自然關鍵字為零。 在他們有一些自然關鍵字的情況下,他們將不得不成為您網站上其他頁面的相同關鍵字的競爭對手。
此外,我們對索引膨脹進行了研究,發現更多不必要的索引頁面。 由於錯誤的站點信息結構或錯誤的 URL 結構而存在這些頁面。
這個問題的另一個原因是錯誤地使用了規範標籤。 兩年多來,規範標籤一直被視為對 Googlebot 的提示。 如果使用不當,Googlebot 在評估網站時不會計算或關注它們。 而且,對於這個計算,您可能會低效地消耗您的爬網預算。 由於不正確的規範標籤使用,我們有超過 300 個帶有重複內容的評論頁面被編入索引。
我的理論旨在向 Google 展示只有質量和必要的頁面,這些頁面具有獲得點擊和為用戶創造價值的潛力。
解決方案:修復索引污染和膨脹
首先,我聽取了 Google 的 John Mueller 的建議。 我問他我是否對這些頁面使用了 noindex 標籤,但仍然讓 Googlebot 跟踪它們,“我會失去鏈接權益和抓取效率嗎?”
你可以猜到,他一開始說是的,但後來他建議使用內部鏈接可以克服這個障礙。
我還發現,在 dofollow 的同時使用 noindex 標籤會降低 Googlebot 在這些頁面上的抓取率。 這些策略讓我可以讓 Googlebot 更頻繁地抓取我的產品和重要指南頁面。 我還按照 John Mueller 的建議修改了我的內部鏈接結構。
短時間內:
- 發現了不必要的索引頁面。
- 從索引中刪除了 300 多頁。
- 實施了 Noindex 標籤。
- 對於從索引中刪除的頁面接收鏈接的頁面,已修改內部鏈接結構。
- 隨著時間的推移,對爬網效率和質量進行了檢查。
5. 問題:錯誤的狀態碼
一開始,我注意到 Googlebot 會訪問很多過去已刪除的內容。 甚至八年前的頁面仍在被抓取。 這是由於使用了不正確的狀態代碼,尤其是對於已刪除的內容。
404 和 410 功能之間存在巨大差異。 其中一個用於不存在內容的錯誤頁面,另一個用於已刪除的內容。 此外,有效頁面還引用了大量已刪除的源和內容 URL。 一些已刪除的圖像和 CSS 或 JS 資產也被用作有效發布頁面上的資源。 最後,還有很多軟 404 頁面和多個重定向鏈,以及用於永久重定向頁面的 302-307 臨時重定向。
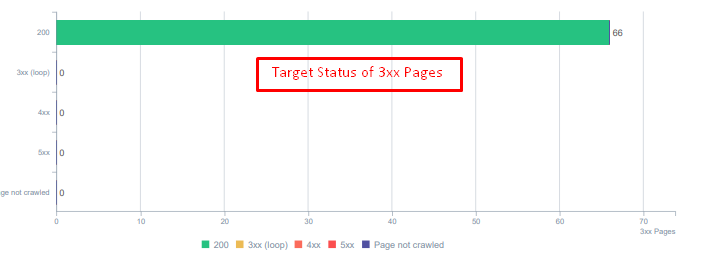
今天重定向資產的狀態代碼。
解決方案:修復錯誤的狀態碼
- 每個 404 狀態碼都轉換為 410 狀態碼。 (超過30000)
- 每個具有 404 狀態代碼的資源都被替換為新的有效資源。 (超過 500 個)
- 每個 302-307 重定向都轉換為 301 永久重定向。 (超過 1500 個)
- 重定向鏈已從正在使用的資產中刪除。
- 每個月,我們在 Log Analysis 中收到超過 25,000 次頁面和資源點擊,狀態碼為 404。 現在,每月 404 個狀態碼少於 50 個,410 個狀態碼的命中率為零……
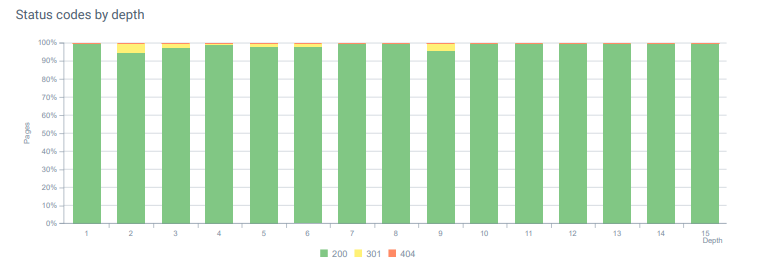
今天整個頁面深度的狀態代碼。
6.問題:語義HTML
語義是指事物的含義。 語義 HTML 包括為層次結構中的頁面組件賦予含義的標籤。 通過這種分層代碼結構,您可以告訴 Google 部分內容的用途是什麼。 此外,在 Googlebot 無法抓取完整呈現您的頁面所需的所有資源的情況下,您至少可以將網頁的佈局和內容部分的功能指定給 Googlebot。
在 Hangikredi.com 上,在 3 月 12 日 Google 核心算法更新之後,我知道由於網站結構未優化,抓取預算不足。 因此,為了讓 Googlebot 更容易理解網頁的目的、功能、內容和有用性,我決定使用 Semantic HTML。
解決方案:語義 HTML 用法
根據谷歌的質量評估指南,每個搜索者都有一個意圖,每個網頁都有一個根據這個意圖的功能。 為了向 Googlebot 證明這些功能,我們對一些被 Googlebot 抓取較少的頁面的 HTML 結構進行了一些改進。
- 使用 <main> 標籤來顯示頁面的主要內容和功能。
- <nav> 用於導航部分。
- 使用 <footer> 作為網站的頁腳。
- 使用 <article> 表示文章。
- 每個標題標籤都使用 <section> 標籤。
- 使用 <picture>、<table>、<citation> 標籤用於內容中的圖像、表格和引號。
- 用於補充內容的 <aside> 標記。
- 修復了 H1-H6 層次結構問題(儘管谷歌最新的“使用兩個 H1 不是問題”聲明,使用正確的結構,有助於 Googlebot。)
- 就像在內容結構部分一樣,我們也為精選片段使用語義 HTML,我們使用表格和列表來獲得更多精選片段結果。

對我們來說,這對於整個網站來說並不是一個切實可行的開發。 儘管如此,隨著每次設計更新,我們將繼續為其他網頁實施語義 HTML 標籤。
7. 問題:結構化數據的使用
與語義 HTML 的使用一樣,結構化數據可用於向 Googlebot 顯示網頁部件的功能和定義。 此外,結構化數據對於豐富的結果是必不可少的。 在我們的網站上,直到 3 月底,結構化數據都沒有被使用,或者更常見的是被錯誤地使用。 為了與我們網站上的實體和離頁帳戶建立更好的關係,我們開始實施結構化數據。
解決方案:正確且經過測試的結構化數據使用
對於金融機構和 YMYL 網站,結構化數據可以解決很多問題。 例如,它們可以顯示品牌的身份、內容的種類並創建更好的片段視圖。 我們為網站範圍和單個頁面使用了以下結構化數據類型:
- 主要產品頁面的常見問題解答結構化數據
- 網頁結構化數據
- 組織結構化數據
- 麵包屑結構化數據
8.站點地圖和Robots.txt優化
在 Hangikredi.com 上,沒有動態站點地圖。 當時現有的站點地圖不包括所有必要的頁面,還包括已刪除的內容。 此外,在 Robots.txt 文件中,一些包含數千個外部鏈接的附屬引薦頁面未被禁止。 這還包括一些與內容無關的第三方 JS 文件以及 Googlebot 不需要的其他附加資源。
應用了以下步驟:
- 為根據站點類別創建的多個站點地圖創建了一個 sitemap_index.xml,以便更好地抓取信號和更好的覆蓋檢查。
- robots.txt 文件中不允許使用一些第三方 JS 文件和一些不必要的 JS 文件。
- 正如我們在 Pagerank 或 Internal Link Sculpting 部分中提到的那樣,不允許使用具有外部鏈接且沒有登錄頁面值的附屬頁面。
- 修復了 500 多個覆蓋問題。 (其中大部分是儘管被 Robots.txt 禁止但仍被編入索引的頁面。)
您可以從下表中看到我們的抓取速度、負載和需求增加:
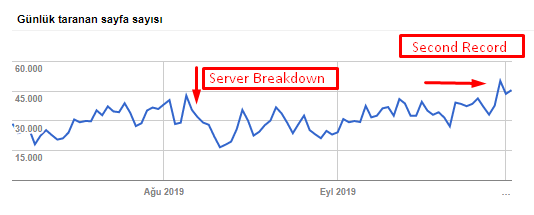
Googlebot 每天抓取的頁面數。 直到 8 月 1 日,每天抓取的頁面數量穩步增加。 在 8 月初的一次攻擊導致服務器故障後,它在一個多月的時間裡恢復了穩定。

Googlebot 每天抓取的負載與每天抓取的頁面數量同步發展。
9. 修復 AMP 問題
在公司的網站上,每個博客頁面都有一個 AMP 版本。 由於不正確的代碼實現和缺少 AMP 規範,所有 AMP 頁面都被反復從索引中刪除。 這造成了一個不穩定的指數得分和網站缺乏信任。 此外,AMP 頁面在土耳其語內容中默認包含英語術語和單詞。
- 為 400 多個 AMP 頁面修復了規範標籤。
- 發現並修復了不正確的代碼實現。 (這主要是由於 AMP-Analytics 和 AMP-Canonical 標記的實施不正確。)
- 默認情況下,英語術語被翻譯成土耳其語。
- 為公司網站的博客部分創建了索引和排名穩定性。
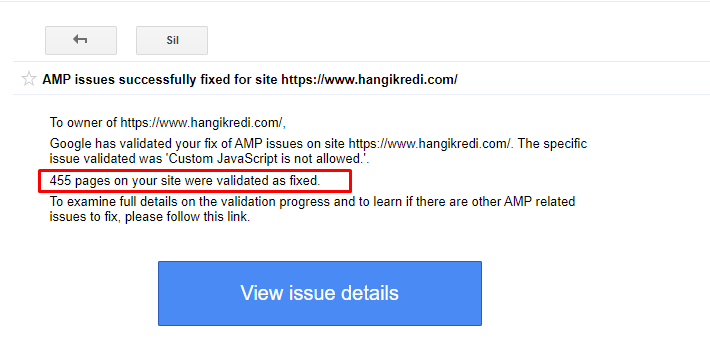
GSC 中有關 AMP 改進的示例消息
10. 元標籤問題和解決方案
由於抓取預算問題,有時在重要的主要產品頁面的關鍵搜索查詢中,Google 沒有索引或顯示元標記中的內容。 SERP 列表沒有顯示元標題,而是僅顯示由兩個單詞組成的公司名稱。 沒有顯示片段描述。這降低了我們的點擊率並損害了我們的品牌形象。 我們通過將元標記移動到源代碼頂部來解決此問題,如下所示。
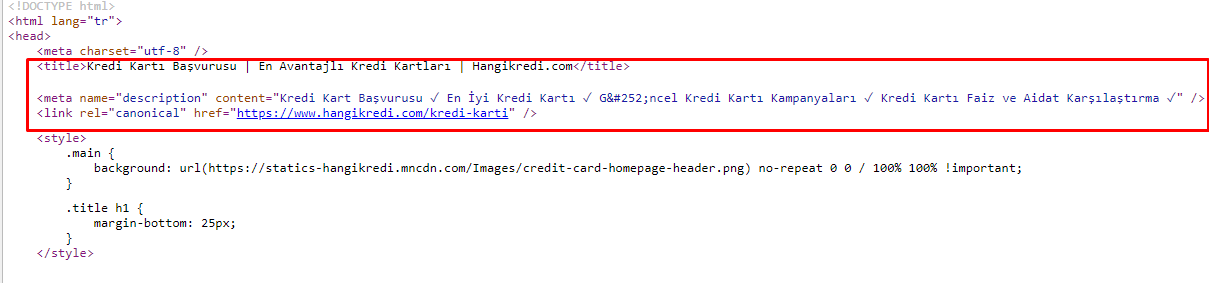
除了抓取預算外,我們還為交易和信息頁面優化了 600 多個元標記:
- 優化移動設備的字符長度。
- 在標題中使用更多關鍵字
- 使用不同風格的元標籤並檢查點擊率、關鍵字差距和排名變化
- 由於這些優化過程,創建了更多具有正確站點樹結構的頁面,以更好地定位次要關鍵字。
- 在我們的網站上,我們仍然有不同的元標題、描述和標題,用於測試 Google 的算法和搜索用戶 CTR。
11. 圖像性能問題及解決方案
圖像問題可以分為兩種類型。 為了內容方便和頁面速度。 對於兩者而言,公司的網站仍然有很多事情要做。
在 3 月 12 日負面核心算法更新之後的 3 月和 4 月:
- 圖像沒有 alt 標籤或它們有錯誤的 alt 標籤。
- 他們沒有頭銜。
- 他們沒有正確的 URL 結構。
- 他們沒有下一代擴展。
- 他們沒有被壓縮。
- 他們沒有適合每種設備屏幕尺寸的分辨率。
- 他們沒有字幕。
為下一次 Google 核心算法更新做準備:
- 圖像被壓縮。
- 他們的擴展部分被改變了。
- Alt 標籤是為它們中的大多數編寫的。
- 為用戶固定了標題和說明。
- URL 結構為用戶部分固定。
- 我們發現瀏覽器仍在加載一些未使用的圖像,並將其從系統中刪除。
由於網站基礎設施,我們部分實施了圖像 SEO 更正。
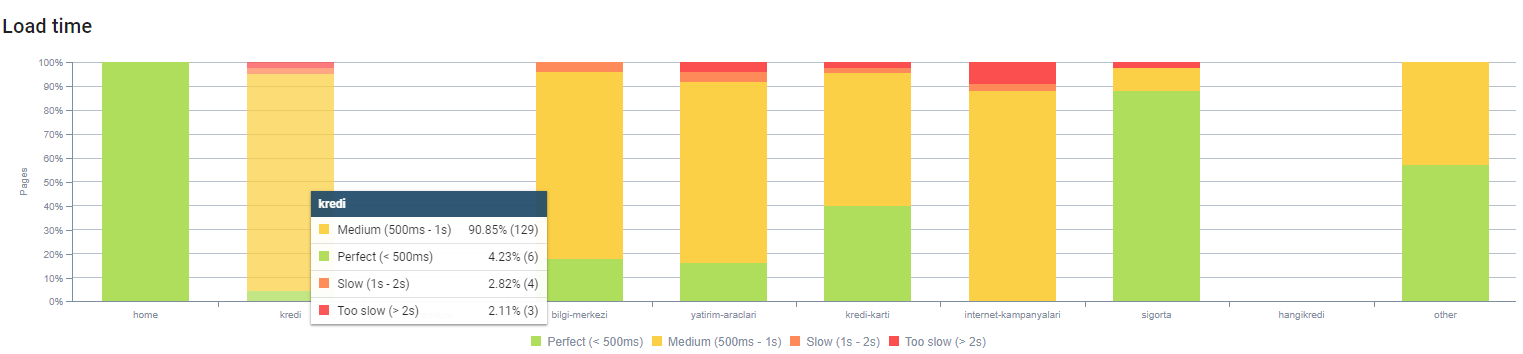
您可以通過上面的頁面深度觀察我們的頁面加載時間。 如您所見,大多數產品頁面仍然很重。
12. 緩存、預取和預加載問題及解決方案
在 3 月 12 日核心算法更新之前,公司網站上有一個鬆散的緩存系統。 一些內容部分在緩存中,但其中一些不在。 這對於產品頁面尤其成問題,因為它們比我們競爭對手的產品頁面慢 2 倍。 我們網頁的大部分組件實際上都是靜態資源,但它們仍然沒有用於說明緩存範圍的 Etag。
為下一次 Google 核心算法更新做準備:
- 我們為每個網頁緩存了一些組件並使它們成為靜態的。
- 這些頁面是重要的產品頁面。
- 由於站點基礎設施,我們仍然不使用電子標籤。
- 尤其是圖像、靜態資源和一些重要的內容部分現在已在站點範圍內完全緩存。
- 我們已經開始對一些被遺忘的外包資源使用 dns-prefetch 代碼。
- 我們仍然不使用預加載代碼,但我們正在網站上開髮用戶旅程,以便將來實施。
13. HTML、CSS 和 JS 優化和縮小
由於網站基礎設施問題,網站速度方面沒有太多事情要做。 我試圖用我能做到的每一種方法來縮小差距,包括刪除一些頁面組件。 對於重要的產品頁面,我們清理了 HTML 代碼結構,對其進行了縮小和壓縮。
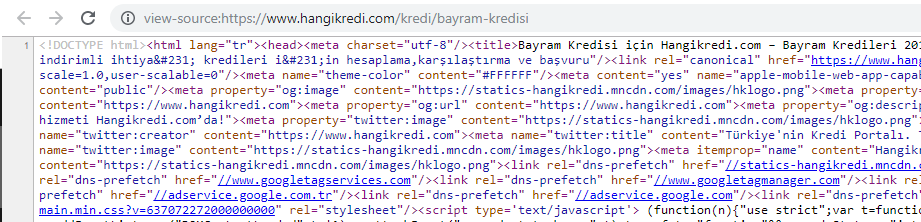
我們季節性但重要的產品頁面源代碼之一的屏幕截圖。 使用常見問題解答結構化數據、HTML 縮小、圖像優化、內容刷新和內部鏈接讓我們在正確的時間獲得了第一名。 (關鍵字是土耳其語中的“Bayram Kredisi”,意思是“假日信用”)
我們還通過小步驟部分實現了 CSS Factoring、Refactoring 和 JS Compression。 當排名下降時,我們檢查了競爭對手頁面與我們的頁面之間的網站速度差距。 我們選擇了一些我們可以加快速度的緊急頁面。 我們還對這些頁面上的關鍵 CSS 文件進行了部分純化和壓縮。 我們啟動了刪除公司不同部門使用的一些第三方JS文件的過程,但尚未刪除。 對於某些產品頁面,我們還能夠更改資源加載順序。
檢查競爭對手
除了每項技術 SEO 改進之外,檢查競爭對手是我了解核心算法更新的性質和目標的最佳指南。 我使用了一些有用且有幫助的程序來跟踪我的競爭對手的設計、內容、排名和技術變化。
- 對於關鍵字排名變化,我使用了 Wincher、Semrush 和 Ahrefs。
- 對於品牌提及,我使用了 Google Alerts、BuzzSumo、Talkwalker。
- 對於新鏈接和新關鍵字獲取報告,我使用了 Ahrefs Alert。
- 對於內容和設計更改,我使用了 Visualping。
- 對於技術變革,我使用了 SimilarTech。
- 對於 Google Update News and Inspection,我主要使用了 Semrush Sensor、Algoroo 和 CognitiveSEO Signals。
- 為了檢查競爭對手的 URL 歷史,我使用了 Wayback Machine。
- 對於競爭對手的服務器速度,我使用了 Chrome DevTools 和 ByteCheck。
- 對於抓取和渲染成本,我使用了“我的網站成本是多少”。 (Since last month, I have started using Onely's new JS Tools like WWJD or TL:DR..)

A screenshot from SimilarTech for my main competitor.
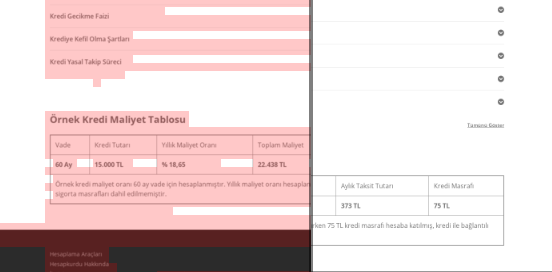
A screenshot from Visualping which shows the layout changes for my secondary competitor.
Testing the value of the changes
With all of these problems identified and solutions in place, I was ready to see whether the website would hold up to the next Google core algorithm updates.
In the next article, I'll look at the major core algorithm updates over the next several months, and how the site performed.