
使用 OnCrawl 的 Splunk 集成改進 SEO 日誌分析的五種方法
已發表: 2019-01-03OnCrawl 最近發布了一個 Splunk 集成,以方便 Splunk 用戶的日誌監控。 我們發現公司將我們的 Splunk 集成用於兩個主要目的:流程自動化和增強的安全控制。 但該工具的優勢還不止於此。 這裡有五種方法可以讓您使用 OnCrawl Splunk 集成來改進您的技術 SEO。
SEO日誌分析:基礎知識
什麼是SEO日誌分析?
您的日誌文件代表網站服務器本身記錄的您網站上的所有活動。 它是有關您網站上發生的事情的最完整和最可靠的信息來源。 這包括機器人點擊的數量和頻率、來自 SERP 的 SEO 有機點擊的數量和頻率、按設備類型(台式機與移動設備)或 URL 類型(頁面與資源)的細分、精確的頁面大小和實際 HTTP 狀態代碼。
SEO日誌分析提供的眾多優勢中的一些:
- 發現抓取行為的峰值或變化,表明 Google 處理您的網站的方式發生了變化
- 了解新頁面平均需要多長時間才能被編入索引並接收第一批自然訪問者
- 監控機器人和用戶活動如何影響頁面的排名
- 了解機器人和用戶行為如何與其他 SEO 因素相關聯

什麼是 Splunk?
Splunk 是用於機器數據聚合的企業解決方案。 能夠大規模索引和管理來自多個來源的數據,它包括用於站點安全和報告目的的服務器日誌處理功能。
Splunk 的一些優點:
- 索引和搜索改進的數據相關性
- 向下鑽取和透視功能以獲得更好的報告
- 實時警報
- 數據儀表板
- 高度可擴展
- 靈活的部署選項
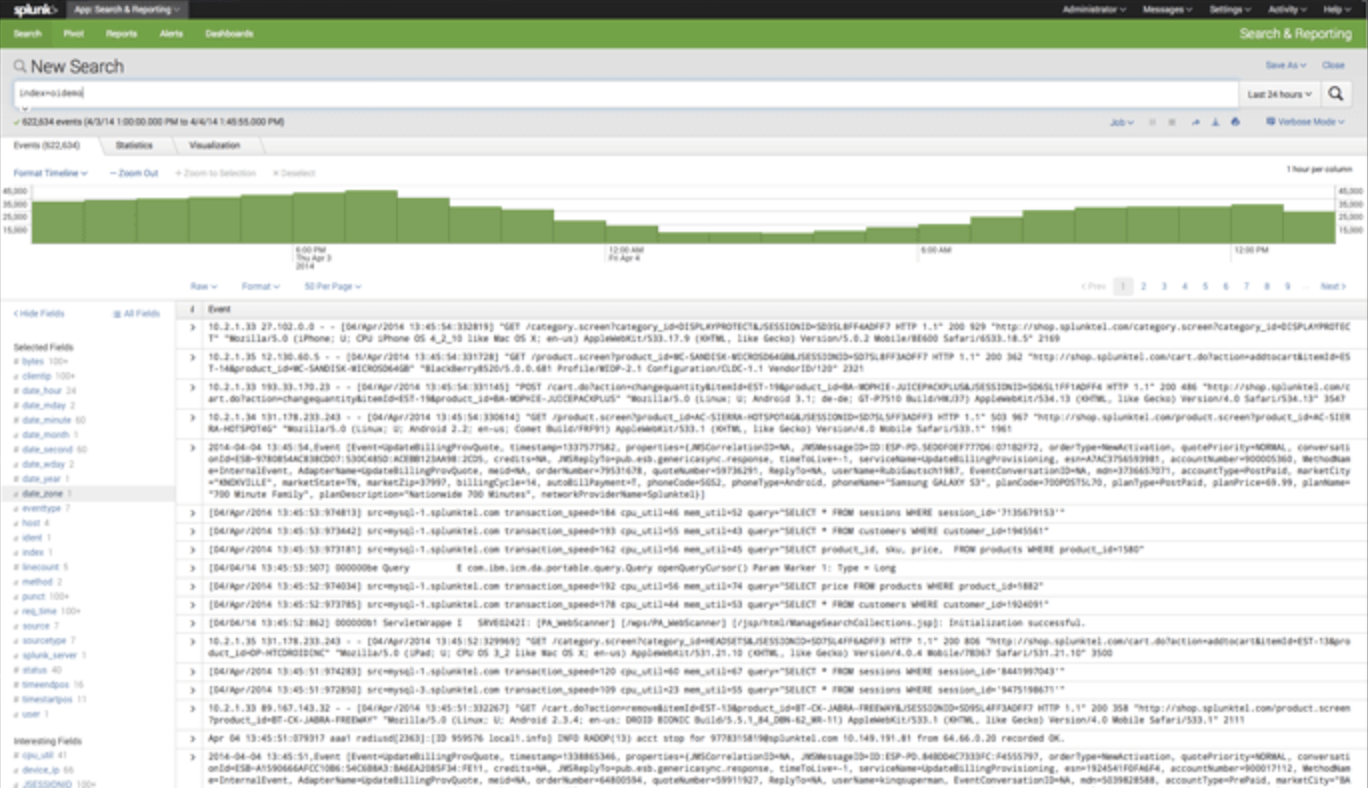
Splunk 中的日誌監控
Splunk 用戶受益於 OnCrawl 集成,將 Splunk 中管理的服務器日誌數據與 OnCrawl 平台中的 SEO 數據連接起來。
Oncrawl 日誌分析器
 學到更多
學到更多使用 OnCrawl + Splunk 改進您的技術 SEO
1. 使用日誌進行深入的 SEO 分析
Splunk 證明了聚合、搜索、監控和設置日誌數據警報的能力。 它解析和重新索引服務器日誌中的內容。 使用強大的搜索和過濾器,它可以回答有關日誌文件中數據的問題。 此處理步驟提供日誌數據中顯示的趨勢的統計信息。
但是,當您想將其應用於 SEO 數據時,最好從原始數據開始。 這正是 OnCrawl Splunk 集成所做的。
這不僅可以顯示日誌數據的單獨統計信息,還允許您將來自日誌的信息與 OnCrawl 平台中的所有其他數據源集成。 反過來,這允許您檢查 SEO 指標與日誌文件中有關用戶和機器人行為的信息之間的關係。

按頁麵點擊深度劃分的自然訪問次數。
這種跨數據分析可以包括對 SEO 有用的軸:
- 單個機器人的抓取行為細分
- 第一次抓取和第一次自然訪問之間的時間
- 提供給用戶和機器人的頁面與審計爬網期間提供的頁面之間的比較
- 發現孤立頁面
- 抓取頻率與排名、展示次數、點擊率之間的相關性
- 內部鏈接策略對用戶/機器人活動的影響
- 頁麵點擊深度與用戶/機器人活動之間的關係
- 內部頁面流行度與用戶/機器人活動之間的關係
- 按 SEO 性能分組的頁面中的用戶和機器人活動細分
2. 使設置更容易
無論您是否需要自動化或更精細的數據安全控制,如果您是 Splunk 用戶,您將
就像設置有多簡單。

如果您不是系統管理員,那麼為 SEO 設置日誌監控似乎是一項複雜的任務。
我們的建議是簡單地跳過困難的部分。 您現在可以直接在 Splunk 中設置所有內容,並使用您生成的密鑰創建與 OnCrawl 的連接。
就是這樣。 你準備好了。 這再簡單不過了。
3. 利用 Splunk 的流程自動化
使用 Splunk 中收集的日誌數據的手動過程需要多個步驟:
- 創建過濾器以搜索正確選擇的日誌數據
- 創建已保存的搜索
- 為運行搜索設置自動化
- 輸出到 CSV
- 在 SSH 中連接到您的 Splunk 實例
- 導航到 CSV 輸出文件夾
- 將文件傳輸到您的計算機
- 連接到 OnCrawl ftp 空間
- 將文件傳輸到 OnCrawl...
必須定期重複此過程,以避免日誌數據出現空白。 這通常成為一項日常任務。
如果您選擇為 OnCrawl 使用 Splunk 集成,則不再需要定期啟動任務。 您只需要設置流程(而且,如前所述,這再簡單不過了)。 您不再需要擔心每天啟動腳本——或者更糟糕的是,一系列手動操作; 集成為您處理。
4. 保護您的流程
在出現問題時保護自己免於丟失數據。 由於日誌監控依賴於連續的數據流,因此差距可能會導致錯誤的結論。 你不應該問這樣的問題:今天早上明顯沒有自然訪問是由於谷歌上發生的事情,還是我只是錯過了數據?
OnCrawl Splunk 集成可在您的服務器關閉或連接丟失時保護您,並在您沒有時間或忘記上傳數據時防止人為錯誤。 如果我們無法連接到服務器,也不會導致您的數據出現空白; 我們稍後會收集它。 如果您發現忘記添加到 Splunk 的一組較早日期的數據,OnCrawl 集成也會自動獲取它。
5. 控制數據安全
在 OnCrawl,我們非常重視您數據的安全性。
與往常一樣,日誌中的敏感數據會保存在您將它們放在您的私有、安全 FTP 空間中的位置,並且永遠不會在其他地方提供。 例如,在驗證 Googlebot 訪問的真實性時,我們處理的唯一個人數據是 IP 地址。 我們不記錄所使用的 IP 地址——只記錄驗證的結果。 如有必要,您可以隨時通過從 FTP 空間中刪除文件來刪除可供分析的敏感信息。
Splunk 的集成更進一步。 我們確保您在整個過程中保持對數據的控制。 您可以在 OnCrawl 中定義訪問權限、要共享的數據以及更新頻率。 當您通過 Splunk 集成與 OnCrawl 共享數據時,我們使用標準的安全協議與 Splunk 進行通信,並受您設置的密碼和密鑰的保護。
因為設置是在 Splunk 中完成的,所以 OnCrawl 永遠不會看到您不允許我們看到的任何內容。 您選擇與 OnCrawl 共享的信息。 不僅如此,由於您管理設置,如果您的日誌記錄過程或您公司的標準發生變化,您可以隨時進行更改。