
如何從 HTML 頁面中提取相關的文本內容?
已發表: 2021-10-13語境
在 Oncrawl 的研發部門,我們越來越希望為您網頁的語義內容增加價值。 使用自然語言處理 (NLP) 的機器學習模型,可以執行對 SEO 具有真正附加值的任務。
這些任務包括以下活動:
- 微調頁面內容
- 製作自動摘要
- 為您的文章添加新標籤或更正現有標籤
- 根據您的 Google Search Console 數據優化內容
- 等等
這次冒險的第一步是提取這些機器學習模型將使用的網頁的文本內容。 當我們談論網頁時,這包括 HTML、JavaScript、菜單、媒體、頁眉、頁腳…… 自動正確地提取內容並不容易。 通過這篇文章,我建議探索這個問題,並討論一些工具和建議來完成這個任務。
問題
從網頁中提取文本內容可能看起來很簡單。 用幾行 Python,例如,幾個正則表達式(regexp),一個像 BeautifulSoup4 這樣的解析庫,就完成了。
如果您暫時忽略越來越多的網站使用 Vue.js 或 React 等 JavaScript 渲染引擎這一事實,那麼解析 HTML 並不是很複雜。 如果你想通過在你的爬蟲中利用我們的 JS 爬蟲來解決這個問題,我建議你閱讀“如何用 JavaScript 爬取網站?”。
但是,我們希望提取有意義的文本,即盡可能提供信息。 例如,當您閱讀有關 John Coltrane 的最後一張遺作專輯的文章時,您會忽略菜單、頁腳……顯然,您並沒有查看整個 HTML 內容。 這些幾乎出現在所有頁面上的 HTML 元素稱為樣板。 我們想去掉它,只保留一部分:攜帶相關信息的文本。
因此,我們只想將這段文本傳遞給機器學習模型進行處理。 這就是為什麼提取盡可能定性至關重要的原因。
解決方案
總的來說,我們希望擺脫“掛在”主文本周圍的一切:菜單和其他側邊欄、聯繫元素、頁腳鍊接等。有幾種方法可以做到這一點。 我們最感興趣的是 Python 或 JavaScript 中的開源項目。
法理
jusText 是博士論文中提出的 Python 實現:“Removing Boilerplate and Duplicate Content from Web Corpora”。 該方法允許來自 HTML 的文本塊根據不同的啟發式分類為“好”、“壞”、“太短”。 這些啟發式方法主要基於字數、文本/代碼比、鏈接的存在與否等。您可以在文檔中閱讀有關該算法的更多信息。
螳螂
trafilatura 也是在 Python 中創建的,它提供關於 HTML 元素類型及其內容的啟發式方法,例如文本長度、元素在 HTML 中的位置/深度或字數。 trafilatura 也使用 jusText 進行一些處理。
可讀性
你有沒有註意到 Firefox 的 URL 欄中的按鈕? 這是閱讀器視圖:它允許您從 HTML 頁面中刪除樣板以僅保留主要文本內容。 用於新聞網站非常實用。 此功能背後的代碼是用 JavaScript 編寫的,Mozilla 將其稱為可讀性。 它基於 Arc90 實驗室發起的工作。
以下是如何為 France Musique 網站上的文章呈現此功能的示例。 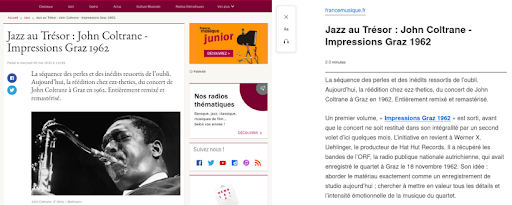
左邊是原始文章的摘錄。 右側是 Firefox 中閱讀器視圖功能的渲染。
其他
我們對 HTML 內容提取工具的研究也使我們考慮了其他工具:
- 報紙:一個內容提取庫,專門用於新聞網站(Python)。 該庫用於從 OpenWebText2 語料庫中提取內容。
- 鍋爐py3 是鍋爐管庫的Python 端口。
- dragnet Python 庫也受到鍋爐管的啟發。
抓取數據³
 學到更多
學到更多評估和建議
在評估和比較不同工具之前,我們想知道 NLP 社區是否使用其中一些工具來準備他們的語料庫(大量文檔)。 例如,用於訓練 GPT-Neo 的名為 The Pile 的數據集包含來自 Wikipedia、Openwebtext2、Github、CommonCrawl 等的 +800 GB 英文文本。與 BERT 一樣,GPT-Neo 是一種使用類型轉換器的語言模型。 它提供了一個類似於 GPT-3 架構的開源實現。

文章“The Pile: An 800GB Dataset of Diverse Text for Language Modeling”提到了在 CommonCrawl 的大部分語料庫中使用 jusText。 這組研究人員還計劃對不同的提取工具進行基準測試。 不幸的是,由於缺乏資源,他們無法完成計劃的工作。 在他們的結論中,應該指出:
- jusText 有時會刪除太多內容,但仍然提供了良好的質量。 鑑於他們擁有的數據量,這對他們來說不是問題。
- trafilatura 更擅長保留 HTML 頁面的結構,但保留了太多樣板文件。
對於我們的評估方法,我們使用了大約 30 個網頁。 我們“手動”提取了主要內容。 然後,我們將不同工具的文本提取與這種所謂的“參考”內容進行了比較。 我們使用主要用於評估自動文本摘要的 ROUGE 分數作為衡量標準。
我們還將這些工具與基於 HTML 解析規則的“自製”工具進行了比較。 事實證明,trafilatura、jusText 和我們自製的工具在這個指標上的表現優於大多數其他工具。
以下是 ROUGE 分數的平均值和標準偏差表:
| 工具 | 意思是 | 標準 |
|---|---|---|
| 螳螂 | 0.783 | 0.28 |
| 爬行 | 0.779 | 0.28 |
| 法理 | 0.735 | 0.33 |
| 鍋爐py3 | 0.698 | 0.36 |
| 可讀性 | 0.681 | 0.34 |
| 拉網 | 0.672 | 0.37 |
鑑於標準偏差的值,請注意提取的質量可能會有很大差異。 HTML 的實現方式、標籤的一致性以及語言的適當使用都會導致提取結果的很多變化。
表現最好的三個工具是 trafilatura,這是我們為這種場合命名為“oncrawl”的內部工具和 jusText。 由於 trafilatura 使用 jusText 作為後備,我們決定使用 trafilatura 作為我們的首選。 但是,當後者失敗並提取零詞時,我們使用自己的規則。
請注意,trafilatura 代碼還提供了數百頁的基準。 它根據提取的內容中是否存在某些元素來計算精度分數、f1 分數和準確度。 兩個工具脫穎而出:trafilatura 和 goose3。 您可能還想閱讀:
- 選擇正確的工具從 Web 中提取內容 (2020)
- Github 存儲庫:文章提取基準:開源庫和商業服務
結論
HTML 代碼的質量和頁麵類型的異質性使得提取優質內容變得困難。 正如 The Pile 和 GPT-Neo 背後的 EleutherAI 研究人員發現的那樣,沒有完美的工具。 當沒有刪除所有樣板文件時,有時會在文本中截斷的內容和殘餘噪音之間進行權衡。
這些工具的優點是它們是上下文無關的。 這意味著,除了頁面的 HTML 之外,它們不需要任何數據來提取內容。 使用 Oncrawl 的結果,我們可以想像一種混合方法,使用站點所有頁面中某些 HTML 塊的出現頻率將它們分類為樣板。
至於我們在 Web 上遇到的基準測試中使用的數據集,它們通常是同一類型的頁面:新聞文章或博客文章。 它們不一定包括保險、旅行社、電子商務等網站,其中文本內容有時更難以提取。
關於我們的基準測試並且由於缺乏資源,我們知道三十頁左右不足以獲得更詳細的分數視圖。 理想情況下,我們希望有更多不同的網頁來完善我們的基準值。 我們還希望包含其他工具,例如 goose3、html_text 或 inscriptis。