
從 Google Search Console API 中提取數據以在 Python 中進行數據分析
已發表: 2022-03-01Google Search Console (GSC) 絕對是 SEO 專家最有用的工具之一,因為它允許您獲取有關索引覆蓋率的信息,尤其是您當前排名的查詢。 知道了這一點,很多人使用電子表格分析 GSC 數據,這很好,只要您了解編程語言等工具還有很大的改進空間。
不幸的是,GSC 界面在顯示的行(只有 5000 行)和可用時間段方面都非常有限,只有 16 個月。 很明顯,這會嚴重限制您獲得洞察力的能力,並且不適合更大的網站。
Python 允許您輕鬆獲取 GSC 數據並自動執行更複雜的計算,這在傳統電子表格軟件中需要付出更多的努力。
這是 Excel 中最大問題之一的解決方案,即行限制和速度。 如今,您有比以前更多的方法來分析數據,這就是 Python 發揮作用的地方。
您不需要任何高級編碼知識來學習本教程,只需了解一些基本概念和使用 Google Colab 進行一些練習。
開始使用 Google Search Console API
在開始之前,設置 Google Search Console API 很重要。 這個過程非常簡單,你只需要一個谷歌帳戶。 步驟如下:
- 在 Google Cloud Platform 上創建一個新項目。 你應該有一個谷歌帳戶,我很確定你有一個。 轉到控制台,然後您應該在頂部找到一個用於創建新項目的選項。
- 點擊左側菜單並選擇“API and services”,您將進入另一個屏幕。
- 從頂部的搜索欄中查找“Google Search Console API”並啟用它。
- 然後轉到“憑據”選項卡,您需要某種權限才能使用 API。
- 配置“同意”屏幕,因為這是強制性的。 無論是否公開,我們將要使用的用途都沒有關係。
- 您可以選擇“桌面應用程序”作為應用程序類型
- 我們將在本教程中使用 OAuth 2.0,您應該下載一個 json 文件,現在您就完成了。
對於大多數人來說,這實際上是最難的部分,尤其是那些不習慣 Google API 的人。 不用擔心,接下來的步驟會更容易,問題也更少。
使用 Python 從 Google Search Console API 獲取數據
我的建議是使用 Jupyter Notebook 或 Google Colab 之類的筆記本。 後者更好,因為您不必擔心要求。 因此,我要解釋的是基於 Google Colab 的。
在我們開始之前,使用以下代碼將您的 json 文件更新到 Google Colab:
從 google.colab 導入文件 文件.上傳()
然後,讓我們安裝分析所需的所有庫,並使用以下代碼片段製作更好的表格可視化:
%%捕獲 #加載需要的東西 !pip install git+https://github.com/joshcarty/google-searchconsole 將熊貓導入為 pd 將 numpy 導入為 np 將 matplotlib.pyplot 導入為 plt 從 google.colab 導入數據表 !git 克隆 https://github.com/jroakes/querycat.git !pip install -r querycat/requirements_colab.txt !pip 安裝 umap-learn data_table.enable_dataframe_formatter() #為了更好的表格可視化
最後,您可以加載 searchconsole 庫,它提供了最簡單的方法,無需依賴長函數。 使用我正在使用的參數運行以下代碼,並確保 client_config 與上傳的 json 文件具有相同的名稱。
導入搜索控制台 帳戶 = searchconsole.authenticate(client_config='client_secret_.json',serialize='credentials.json', flow='console')
您將被重定向到用於授權應用程序的 Google 頁面,選擇您的 Google 帳戶,然後將您將獲得的代碼複製並粘貼到 Google Colab 欄中。
我們還沒有完成,您必須選擇需要數據的屬性。 您可以通過 account.webproperties 輕鬆檢查您的屬性,看看您應該選擇什麼。
property_name = input('插入 GSC 中列出的網站名稱:')
webproperty=account[str(property_name)]
完成後,您將運行一個自定義函數來創建一個包含我們數據的對象。
def extract_gsc_data(webproperty, start, stop, *args):
如果 webproperty 不是無:
print(f'為 {webproperty} 提取數據')
gsc_data = webproperty.query.range(start, stop).dimension(*args).get()
返回 gsc_data
別的:
print('Webproperty 未找到,請選擇正確的')
返回無
該函數的想法是獲取您之前定義的屬性和時間範圍,以開始和結束日期的形式,以及維度。
能夠選擇維度的選擇對於 SEO 專家來說至關重要,因為它可以讓您了解是否需要一定程度的粒度。 例如,在某些情況下,您可能對獲取日期維度不感興趣。
我的建議是始終選擇查詢和頁面,因為 Google Search Console 界面可以單獨導出它們,並且每次合併它們非常煩人。 這是 Search Console API 的另一個好處。
在我們的例子中,我們也可以直接獲取日期維度,以展示一些需要考慮時間的有趣場景。
ex = extract_gsc_data(webproperty,'2021-09-01','2021-12-31','查詢','頁面','日期')
選擇一個合適的時間範圍,考慮到對於較大的屬性,您將需要等待很多時間。 對於這個例子,我只考慮 3 個月的時間跨度,平均而言,這足以從大多數數據集中獲得有價值的見解。
如果您正在處理大量數據,您甚至可以選擇一周,我們關心的是過程。
為了適合示例,我將在這裡向您展示的內容要么基於合成數據,要么基於修改過的真實數據。 因此,您在此處看到的內容是完全真實的,並且可以反映真實世界的場景。
數據清洗
對於那些不知道的人,我們不能按原樣使用我們的數據,有一些額外的步驟可以確保我們正常工作。 首先,我們必須將我們的對象轉換為 Pandas 數據框,這是一種您必須熟悉的數據結構,因為它是 Python 中數據分析的基礎。
df = pd.DataFrame(data=ex) df.head()
head 方法可以顯示數據集的前 5 行,它非常便於查看數據的外觀。 我們可以使用一個簡單的函數來計算我們有多少頁。
刪除重複項的一個好方法是將對象轉換為集合,因為集合不能包含重複元素。
一些代碼片段的靈感來自於 Hamlet Batista 的筆記本和另一個來自 Masaki Okazawa 的筆記本。
刪除品牌條款
首先要做的是刪除品牌關鍵詞,我們正在尋找那些不包含我們品牌詞的查詢。 這對於自定義函數非常簡單,您通常會擁有一組品牌術語。
出於演示目的,您不需要將所有這些都過濾掉,但請進行實際分析。 這是 SEO 中最重要的數據清理步驟之一,否則您可能會出現誤導性結果。
domain_name = str(input('插入以逗號分隔的品牌詞:')).replace(',', '|')
重新進口
domain_name = re.sub(r"\s+", "", domain_name)
print('使用正則表達式刪除所有空格:\n')
df['品牌/非品牌'] = np.where(
df['query'].str.contains(domain_name), '品牌', '非品牌'
)
我們將在數據集中添加一個新列,以識別這兩個類之間的差異。 我們可以通過表格或條形圖可視化它們佔查詢總數的多少。
我不會向您展示條形圖,因為它非常簡單,而且我認為表格更適合這種情況。
brand_count_df = df['品牌/非品牌'].value_counts().rename_axis('cats').to_frame('counts')
brand_count_df['百分比'] = brand_count_df['counts']/sum(brand_count_df['counts'])
pd.options.display.float_format = '{:.2%}'.format
brand_count_df
您可以快速查看品牌關鍵字和非品牌關鍵字之間的比率,以了解要從數據集中刪除多少。 這裡沒有理想的比例,儘管您肯定希望擁有更高比例的非品牌關鍵字。
然後,我們可以刪除所有標記為品牌的行並繼續其他步驟。
#僅選擇非品牌關鍵字 df = df.loc[df['品牌/非品牌'] == '非品牌']
填充缺失值等步驟
如果您的數據集具有缺失值(或行話中的 NA),您有多種選擇。 最常見的是將它們全部刪除或用佔位符值(如 0 或該列的平均值)填充它們。
沒有正確的答案,兩種方法各有利弊,也有風險。 對於 Google Search Console 數據,我最好的建議是使用 0 之類的佔位符值,以低估某些指標的影響。
df.fillna(0, inplace = True)
在我們進行實際數據分析之前,我們需要調整我們的特徵,即數據集的列。 這個位置特別有趣,因為我們想將它用於一些很酷的數據透視表。
我們可以將位置四捨五入為整數,這符合我們的目的。
df['position'] = df['position'].round(0).astype('int64')
您應該遵循上述所有其他清潔步驟,然後調整日期列。
我們在 pandas 的幫助下提取數月和數年。 如果在較短的時間範圍內工作,則無需如此具體,這是一個考慮半年的示例。
#將日期轉換為正確的格式 df['date'] = pd.to_datetime(df['date']) #提取月份 df['month'] = df['date'].dt.month #提取年份 df['year'] = df['date'].dt.year
[電子書] 數據 SEO:下一次大冒險
 閱讀電子書
閱讀電子書探索性數據分析
Python 的主要優點是您可以執行與 Excel 中相同的操作,但選項更多且更容易。 讓我們從每個分析師都非常熟悉的東西開始:數據透視表。
分析每個職位組的平均點擊率
分析平均每個職位組的點擊率是最有洞察力的活動之一,因為它可以讓您了解網站的一般情況。 應用樞軸,然後繪製它。
pd.options.display.float_format = '{:.2%}'.format
query_analysis = df.pivot_table(index=['position'], values=['ctr'], aggfunc=['mean'])
query_analysis.sort_values(by=['position'], 升序=True).head(10)
ax = query_analysis.head(10).plot(kind='bar')
ax.set_xlabel('平均位置')
ax.set_ylabel('CTR')
ax.set_title('CTR 按平均位置')
ax.grid('on')
ax.get_legend().remove()
plt.xticks(旋轉=0)
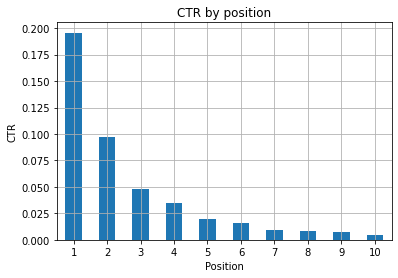
圖 1:按位置表示 CTR 以發現異常。
此處的理想情況是圖表左側的點擊率更高,因為通常位置 1 的點擊率應該更高。 不過要小心,您可能會看到前 3 個廣告位的點擊率低於預期的情況,您必須進行調查。
請同時考慮邊緣情況,例如位置 11 比第一更好的情況。 正如 Search Console 的 Google 文檔中所解釋的那樣,該指標並不遵循您最初可能想到的順序。
此外,它補充說,這個指標是一個平均值,因為鏈接的位置每次都在變化,不可能有 100% 的準確度。
有時您的頁面排名很高但不夠令人信服,因此您可以嘗試修復標題。 由於這是一個高級概述,您不會看到細微的差異,因此如果這個問題是大規模的,請期望快速採取行動。
還要注意,當一組處於較低位置的頁面的平均點擊率高於處於較好位置的頁面時。
出於這個原因,您可能希望將分析擴展到 15 位或更多位置,以發現奇怪的模式。
每個位置的查詢計數和衡量 SEO 工作量
您為其排名的查詢的增加總是一個好的信號,但這並不一定意味著將來會有更好的排名。 查詢計數是計算您為其排名的查詢數量的過程,並且是您可以使用 GSC 數據執行的最重要的任務之一。
數據透視表再次提供了巨大的幫助,我們可以繪製結果。
ranking_queries = df.pivot_table(index=['position'], values=['query'], aggfunc=['count']) ranking_queries.sort_values(by=['position']).head(10)
作為 SEO 專家,您想要的是在最左側,即頂部位置有更高的查詢計數。 原因很自然,平均而言,較高的位置可以獲得更好的點擊率,這可以轉化為更多的人點擊您的頁面。
斧頭=ranking_queries.head(10).plot(kind='bar')
ax.set_ylabel('查詢次數')
ax.set_xlabel('位置')
ax.set_title('排名分佈')
ax.grid('on')
ax.get_legend().remove()
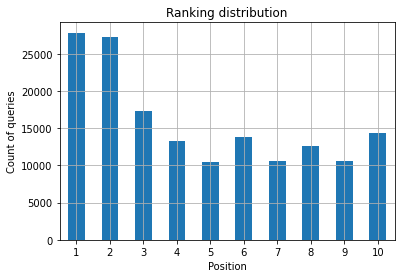
圖 2:按職位劃分,我有多少查詢?
您關心的是隨著時間的推移增加頂部位置的查詢計數。
玩弄日期維度
讓我們看看點擊次數在考慮的時間間隔內如何變化,讓我們首先獲得點擊次數的總和:
clicks_sum = df.groupby('date')['clicks'].sum()
我們按日期維度對數據進行分組,並獲得每個點擊次數的總和,這是一種匯總。
我們現在已經準備好繪製我們得到的東西了,代碼會很長,只是為了改善可視化,不要被它嚇到。
# 整個時期的點擊總和
%config InlineBackend.figure_format = '視網膜'
從 matplotlib.pyplot 導入圖
圖(圖尺寸=(8, 6),dpi=80)
ax = clicks_sum.plot(color='red')
ax.grid('on')
ax.set_ylabel('點擊總和')
ax.set_xlabel('月')
ax.set_title('每月點擊次數的變化')
xlab = ax.xaxis.get_label()
ylab = ax.yaxis.get_label()
xlab.set_style('斜體')
xlab.set_size(10)
ylab.set_style('斜體')
ylab.set_size(10)
ttl = ax.title
ttl.set_weight('粗體')
ax.spines['right'].set_color((.8,.8,.8))
ax.spines['top'].set_color((.8,.8,.8))
ax.yaxis.set_label_coords(-.15, .50)
ax.fill_between(clicks_sum.index, clicks_sum.values, facecolor='yellow')
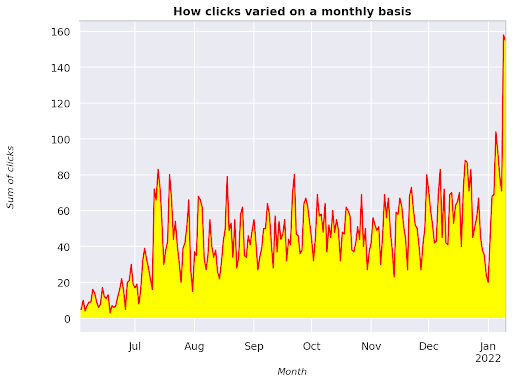

圖 3:繪製與月份變量相關的點擊總和
這是一個從 2021 年 6 月開始一直到 2022 年 1 月一半的示例。您在上面看到的所有線條都具有使此可視化更漂亮的作用,您可以嘗試使用它來看看會發生什麼。
每個位置的查詢計數,每月快照
我們可以在 Python 中繪製的另一個很酷的可視化是熱圖,它比簡單的條形圖更直觀。 我將向您展示如何根據時間和位置顯示查詢計數。
將 seaborn 導入為 sns sns.set_theme() df_new = df.loc[(df['position'] <= 10) & (df['year'] != 2022),:] # 加載示例航班數據集並轉換為長格式 df_heat = df_new.pivot_table(index = "position", columns = "month", values = "query", aggfunc='count') # 用每個單元格中的數值繪製熱圖 f, ax = plt.subplots(figsize=(20, 12)) x_axis_labels = [“九月”、“十月”、“十一月”、“十二月”] sns.heatmap(df_heat, annot=True, linewidths=.5, ax=ax, fmt='g', cmap = sns.cm.rocket_r, xticklabels=x_axis_labels) ax.set(xlabel = 'Month', ylabel='Position', title = '每個位置的查詢計數如何隨時間變化') #rotate 位置標籤使它們更具可讀性 plt.yticks(旋轉=0)
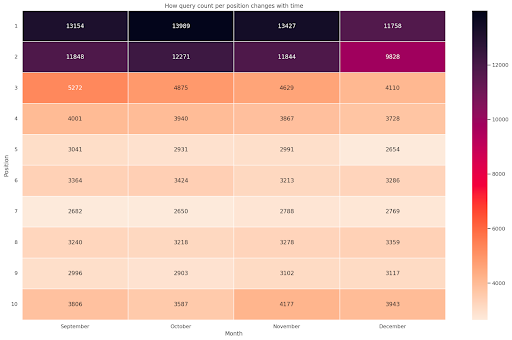
圖 4:根據位置和月份顯示查詢計數進度的熱圖。
這是我最喜歡的一個,熱圖可以非常有效地顯示數據透視表,例如在這個例子中。 該時間跨度超過 4 個月,如果您橫向閱讀,您可以看到查詢計數如何隨著時間的推移而變化。 從 9 月到 12 月,位置 10 略有增加,但位置 2 顯著下降,如紫色所示。
在以下場景中,您的大部分查詢都排在最前面,這可能是非常不尋常的。 如果發生這種情況,您可能需要返回並分析數據框,尋找可能的品牌術語(如果有)。
正如您從代碼中看到的那樣,製作複雜的繪圖並不難,只要您掌握了背後的邏輯。
如果你做的是“正確”的事情,查詢計數應該會隨著時間增加,我們可以繪製兩個不同時間範圍內的差異。 在我提供的示例中,情況顯然並非如此,尤其是對於最高職位,您應該有更高的點擊率。
介紹一些基本的 NLP 概念
自然語言處理 (NLP) 是 SEO 的天賜之物,您無需成為專家即可應用基本算法。 N-gram 是最強大但最簡單的想法之一,可以讓您深入了解 GSC 數據。
N-gram 是字母、音節或單詞的連續序列。 對於我們的分析,單詞將是度量單位。 當相鄰元素是兩個(一對)時,n-gram 稱為 bigram,如果它們是三個,則稱為 trigram,依此類推。 我建議你用不同的組合來測試,最多不超過 5 克。
通過這種方式,您可以發現競爭對手頁面中最常見的句子或評估您自己的句子。 由於 Google 可能依賴基於短語的索引,因此最好針對句子而不是單個關鍵字進行優化,如涉及該主題的 Google 專利所示。
正如 Bill Slawski 本人在上頁所述,理解相關術語的價值對於優化和您的用戶都具有重要價值。
nltk 庫以 NLP 應用程序而聞名,它使我們能夠刪除給定語言(如英語)中的停用詞。 將它們視為您想要刪除的噪音,事實上,文章和非常常用的詞不會增加理解文本的任何價值。
導入 nltk
nltk.download('停用詞')
從 nltk.corpus 導入停用詞
stoplist = stopwords.words('english')
從 sklearn.feature_extraction.text 導入 CountVectorizer
c_vec = CountVectorizer(stop_words=stoplist, ngram_range=(2,3))
# ngram 矩陣
ngrams = c_vec.fit_transform(df['query'])
# ngram 的計數頻率
count_values = ngrams.toarray().sum(axis=0)
# ngram 列表
vocab = c_vec.vocabulary_
df_ngram = pd.DataFrame(sorted([(count_values[i],k) for k,i in vocab.items()], reverse=True)
).rename(columns={0: '頻率', 1:'bigram/trigram'})
df_ngram.head(20).style.background_gradient()
我們獲取查詢列併計算二元組的頻率,以創建一個存儲二元組及其出現次數的數據框。
這一步實際上對於分析競爭對手的網站也非常重要。 您可以通過每次調整 n 來查看他們的文本並檢查最常見的 n-gram 以查看您是否在高排名頁面中發現不同的模式。
如果您考慮一下它會更有意義,因為單個關鍵字不會告訴您有關上下文的任何信息。
低垂的果實
最可愛的事情之一是檢查低垂的果實,那些你可以輕鬆改進的頁面,以便儘早看到好的結果。 這對於說服您的利益相關者的每個 SEO 項目的第一步至關重要。 因此,如果有機會利用這些頁面,那就去做吧!
我們考慮這樣一個頁面的標準是展示次數和點擊率的分位數。 換句話說,我們正在過濾位於前 80% 印像中但在 20% 中獲得最低 CTR 的行。 這些行的點擊率將低於其餘行的 80%。
top_impressions = df[df['impressions'] >= df['impressions'].quantile(0.8)]
(top_impressions[top_impressions['ctr'] <= top_impressions['ctr'].quantile(0.2)].sort_values('impressions', 升序 = False))
現在您有一個列表,其中包含按展示次數降序排列的所有機會。
根據您的網站需求及其大小,您可以考慮其他標準來定義什麼是容易實現的目標。
對於較小的網站,您可能會考慮尋找更高的百分比,而在大型網站中,您應該已經根據我使用的標準獲得了大量信息。
[電子書] 面向非技術思想家的技術 SEO
 閱讀電子書
閱讀電子書介紹querycat:分類和關聯
Querycat 是一個簡單但功能強大的庫,具有用於聚類關鍵字的關聯規則挖掘等功能。 我只會向您展示關聯,因為它們在此類分析中更有價值。
您可以通過查看 querycat GitHub 存儲庫來了解有關這個很棒的庫的更多信息。
關於關聯規則學習的簡短介紹
關聯規則學習是一種查找規則的方法,這些規則定義了項目集之間的關聯和共現。 這與另一種無監督機器學習方法,即所謂的聚類略有不同。
最終目標是相同的,獲取關鍵字集群以了解我們的網站在某些主題上的表現。
Querycat 讓您可以在兩種算法之間進行選擇:Apriori 和 FP-Growth。 我們將選擇後者以獲得更好的性能,因此您可以忽略前者。
FP-Growth 是 Apriori 的改進版本,用於查找數據集中的頻繁模式。 關聯規則學習對於電子商務交易也非常有用,例如,您可能有興趣了解人們一起購買什麼。
在這種情況下,我們的重點全部放在查詢上,但我提到的另一個應用程序可能是谷歌分析數據的另一個有用的想法。
從數據結構的角度解釋這些算法非常具有挑戰性,我認為這對於您的 SEO 任務來說是不必要的。 我將僅解釋一些基本概念以了解參數的含義。
2種算法的3個主要元素是:
- 支持——它表達了一個項目或一個項目集的流行度。 用技術術語來說,它是查詢 X 和查詢 Y 一起出現的事務數除以事務總數。
此外,它可以用作去除不常見項目的閾值。 對於提高統計顯著性和性能非常有用。 設置一個好的最小支撐是非常好的。 - 置信度——您可以將其視為術語同時出現的概率。
- Lift – 對(第 1 期和第 2 期)的支持與第 1 期的支持之間的比率。我們可以查看它的值以深入了解術語之間的關係。 如果大於 1,則項是相關的; 如果小於 1,則項不太可能有關聯:如果 lift 恰好為 1(或接近),則沒有顯著關係。
本文提供了有關庫作者編寫的 querycat 的更多詳細信息。
現在我們準備進入實際部分。
導入查詢貓
query_cat = querycat.Categorize(df, 'query', min_support=10, alg='fpgrowth')
dfgrouped = df.groupby('category').agg(sumclicks = ('clicks', 'sum')).sort_values('sumclicks', ascending=False)
#create group 過濾少於 15 次點擊的類別(任意數量)
filtergroup = dfgrouped[dfgrouped['sumclicks'] > 15]
過濾器組
#應用過濾器
df = df.merge(filtergroup, on=['category','category'], how='inner')
在此過程中,我們過濾了頻率較低的類別,我選擇了 15 個作為基準。 這只是一個隨意的數字,背後沒有標準。
讓我們使用以下代碼段檢查我們的類別:
df['category'].value_counts()
那麼點擊率最高的 10 個類別呢? 讓我們檢查一下每個查詢有多少個查詢。
df.groupby('category').sum()['clicks'].sort_values(ascending=False).head(10)
選擇的數字是任意的,一定要選擇一個能過濾掉大部分群體的數字。 一個可能的想法是獲取展示次數的中位數並降低最低的 50%,前提是您要排除小組。
獲取集群以及如何處理輸出
我的建議是導出你的新數據框以避免再次運行 FP-Growth,請這樣做以節省有用的時間。
一旦您有了集群,您就想知道每個集群的點擊次數和展示次數,以便評估哪些領域需要最多改進。
grouped_df = df.groupby('category')[['clicks', 'impressions']].agg('sum')
通過一些數據處理,我們能夠改善我們的關聯結果,並為每個集群獲得點擊和印象。
group_ex = df.groupby(['category'])['query'].apply(' | '.join).reset_index()
#刪除重複的查詢,然後按字母順序排序
group_ex['query'] = group_ex['query'].apply(lambda x: ' | '.join(sorted(list(set(x.split('|'))))))
df_final = group_ex.merge(grouped_df, on=['category', 'category'], how='inner')
df_final.head()
您現在擁有一個 CSV 文件,其中包含所有關鍵字集群以及點擊次數和展示次數。
#save csv 文件並將其下載到本地計算機。 如果您使用 Safari,請考慮切換到 Chrome 下載這些文件,因為它可能無法正常工作。
df_final.to_csv('clusters_queries.csv')
files.download('clusters_queries.csv')
實際上,有更好的聚類方法,這只是一個示例,說明如何使用 querycat 執行多個任務以立即使用。 這裡的主要目標是獲得盡可能多的見解,特別是對於您沒有那麼多知識的新網站。
目前最好的方法涉及語義,所以如果你想專注於聚類,我建議你考慮學習圖或嵌入。
但是,如果您是新手,這些都是高級主題,您可以簡單地嘗試一些在線提供的預構建 Streamlit 應用程序。
抓取數據³
 學到更多
學到更多結論和下一步
Python 可以在分析您的網站方面提供重要幫助,並且可以幫助您將數據清理、可視化和分析結合在一個地方。 更高級的任務肯定需要從 GSC API 中提取數據,並且是對數據自動化的“溫和”介紹。
雖然您可以使用 Python 進行許多更高級的計算,但我的建議是檢查在 SEO 價值方面什麼是有意義的。
例如,從長遠來看,查詢計數作為一個整體更為重要,因為您希望您的網站被考慮用於更多查詢。
使用 notebook 對使用註釋打包代碼有很大幫助,這也是我建議您習慣 Google Colab 的主要原因。
這只是數據分析可以為您提供的開始,因為最好的想法來自合併不同的數據集。
Google Search Console 本身就是一個強大的工具,而且它是完全免費的,您可以從中獲得的實用信息量幾乎是無限的。