
A/B 測試統計意義:如何以及何時結束測試
已發表: 2020-05-22
在我們最近對 Convert 客戶運行的 28,304 個實驗的分析中,我們發現只有 20%的實驗達到了 95% 的統計顯著性水平。 Econsultancy 在其 2018 年優化報告中發現了類似的趨勢。 三分之二的受訪者認為只有 30% 或更少的實驗是“明顯且具有統計學意義的贏家”。
所以大多數實驗(70-80%)要么沒有結論,要么提前停止。
其中,早期停止的那些是一個奇怪的案例,因為優化者會在他們認為合適的時候調用結束實驗。 當他們可以“看到”明顯的贏家(或輸家)或明顯無關緊要的測試時,他們就會這樣做。 通常,他們也有一些數據來證明這一點。
考慮到 50% 的優化器在他們的實驗中沒有標準的“停止點”,這可能並不令人驚訝。 對於大多數人來說,這樣做是必要的,因為必須保持一定的測試速度(每月 XXX 次測試)以及爭奪主導競爭的壓力。
此外,負面實驗也有可能損害收入。 我們自己的研究表明,非成功的實驗平均會導致轉化率下降 26% !
總而言之,提前結束實驗還是有風險的……
......因為它留下了實驗運行其預期長度的概率,由正確的樣本量提供支持,其結果可能會有所不同。
那麼,提前結束實驗的團隊如何知道什麼時候結束呢? 對大多數人來說,答案在於製定加速決策的停止規則,同時又不影響決策質量。
擺脫傳統的停止規則
對於網絡實驗,0.05 的 p 值作為標準。 這 5% 的容錯或 95% 的統計顯著性水平有助於優化人員保持測試的完整性。 他們可以確保結果是實際結果,而不是僥倖。
在用於固定水平測試的傳統統計模型中——測試數據在固定時間或特定數量的參與用戶中僅評估一次——當 p 值低於 0.05 時,您將接受結果為顯著。 此時,您可以拒絕零假設,即您的控制和治療是相同的,並且觀察到的結果不是偶然的。
與允許您在收集數據時評估數據的統計模型不同,此類測試模型禁止您在實驗運行時查看實驗數據。 這種做法(也稱為窺視)在此類模型中是不鼓勵的,因為 p 值幾乎每天都在波動。 你會發現某天實驗很重要,第二天,它的 p 值會上升到不再重要的程度。
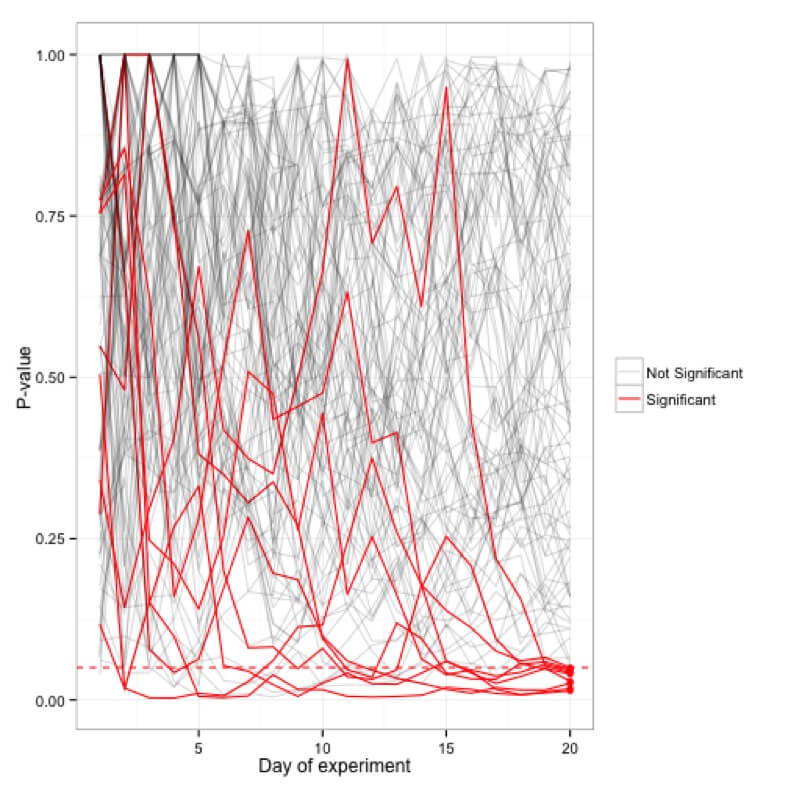
為一百個(20 天)實驗繪製的 p 值模擬; 實際上只有 5 個實驗最終在 20 天大關時具有顯著性,而許多實驗偶爾會在過渡期間達到 <0.05 的臨界值。
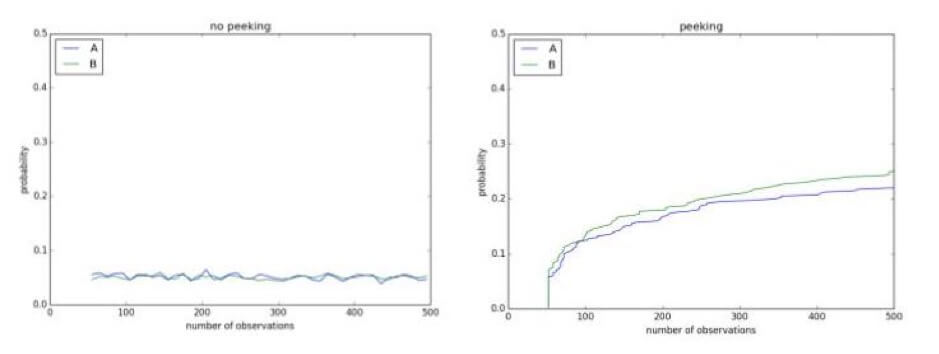
在此期間查看您的實驗可能會顯示不存在的結果。 例如,下面有一個使用顯著性水平 0.1 的 A/A 測試。 由於它是 A/A 測試,因此控制和治療之間沒有區別。 然而,在正在進行的實驗中進行 500 次觀察後,有超過 50% 的機會得出結論認為它們不同並且可以拒絕原假設:
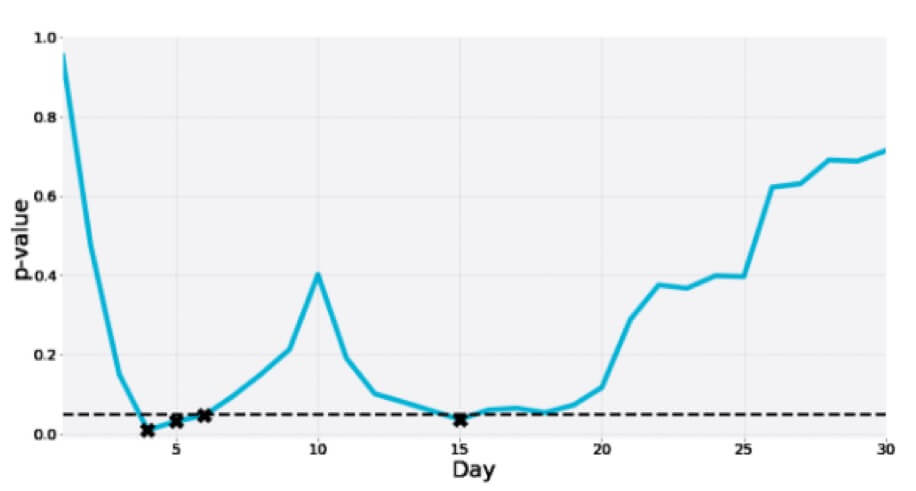
這是另一個為期 30 天的 A/A 測試,其中 p 值在過渡期間多次跌至顯著性區域,但最終遠高於臨界值:
正確報告固定水平實驗的 p 值意味著您需要預先承諾固定的樣本量或測試持續時間。 一些團隊還會在此實驗停止標準和預期長度中添加一定數量的轉換。
然而,這裡的問題是,對於大多數網站來說,使用這種標準做法來獲得足夠的測試流量來支持每個實驗以實現最佳停止是很困難的。
這裡是使用支持可選停止規則的順序測試方法有幫助的地方。
轉向靈活的停止規則,以實現更快的決策
順序測試方法可讓您在實驗數據出現時利用它,並使用您自己的統計顯著性模型更快地發現獲勝者,並具有靈活的停止規則。
CRO 成熟度最高的優化團隊通常會設計自己的統計方法來支持此類測試。 一些 A/B 測試工具也將這一點融入其中,並且可以建議某個版本是否會勝出。 有些可以讓您完全控制您希望如何計算統計顯著性,以及您的自定義值等等。 因此,即使在正在進行的實驗中,您也可以窺視並發現獲勝者。

Georgi Georgiev 是流行的 A/B 測試統計 CXL 課程的統計學家、作者和講師,他非常喜歡這樣的順序測試方法,這些方法允許中期分析的數量和時間靈活:
“順序測試允許您通過儘早部署獲勝的變體來最大化利潤,並儘早停止產生獲勝可能性很小的測試。 後者將由於劣質變體造成的損失降至最低,並在變體根本不可能勝過對照時加快測試速度。 在所有情況下都保持統計嚴謹性。 ”
Georgiev 甚至開發了一個計算器,它可以幫助團隊放棄固定樣本測試模型,轉而使用一種可以在實驗仍在運行時檢測出獲勝者的模型。 他的模型考慮了很多統計數據,並幫助您調用測試比標準統計顯著性計算快 20-80%,而不會犧牲質量。
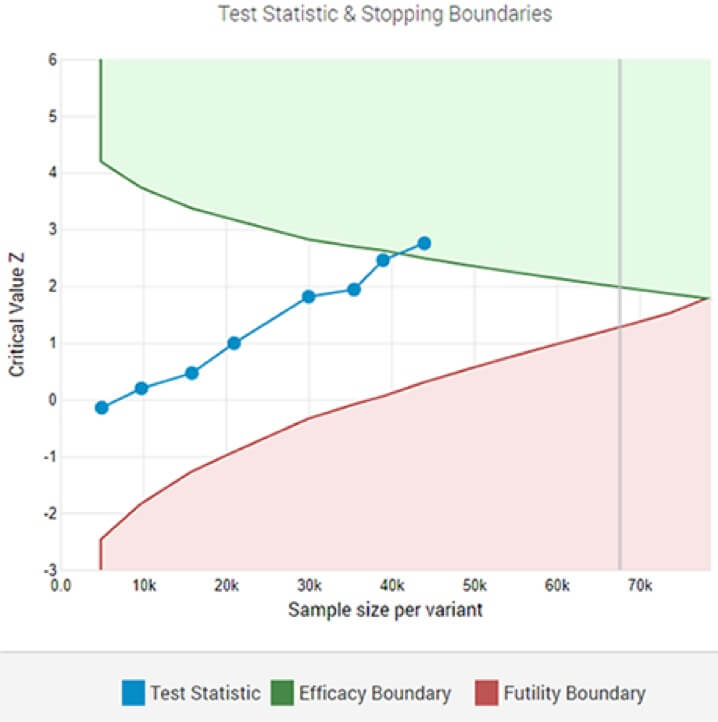
在第 8 次中期分析後,自適應 A/B 測試顯示在指定顯著性閾值處具有統計學意義的獲勝者。
雖然此類測試可以加快您的決策過程,但有一個重要方面需要解決:實驗的實際影響。 在此期間結束實驗可能會導致您高估它。
Georgiev 警告說,查看效應大小的未經調整的估計值可能是危險的。 為了避免這種情況,他的模型使用了一些方法來應用調整,這些調整考慮到了由於臨時監控而產生的偏差。 他解釋了他們的敏捷分析如何“根據停止階段和觀察到的統計值(超調,如果有的話)”來調整估計值。 下面,您可以看到上述測試的分析:(注意估計的提升如何低於觀察到的,並且間隔不是以它為中心。)
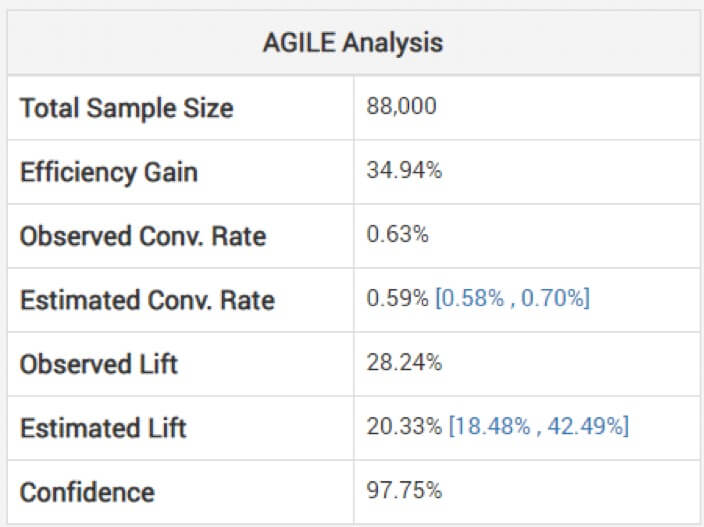
因此,根據您的短於預期的實驗,勝利可能沒有看起來那麼大。
損失也需要考慮在內,因為您最終可能仍然錯誤地過早地稱贏家。 但即使在固定水平測試中也存在這種風險。 然而,與運行時間較長的固定水平測試相比,在早期調用實驗時,外部有效性可能是一個更大的問題。 但正如 Georgiev 解釋的那樣,這是“樣本量較小以及測試持續時間較小的簡單結果。 “
最後……這與贏家或輸家無關……
……但正如 Chris Stucchio 所說,關於更好的商業決策。
或者正如湯姆·雷德曼(《數據驅動:從您最重要的商業資產中獲利》一書的作者)所斷言的那樣:“在商業中:“通常有比統計顯著性更重要的標準。 重要的問題是,“結果是否在市場上站得住腳,哪怕只是短暫的一段時間? ''
Georgiev 指出,“如果它具有統計意義,並且在設計階段以令人滿意的方式解決了外部有效性考慮,那麼它很可能會,而且不僅僅是短期內。”
實驗的全部本質是使團隊能夠做出更明智的決定。 因此,如果您可以更快地傳遞結果(您的實驗數據指向的結果),那為什麼不呢?
這可能是一個小的 UI 實驗,您實際上無法獲得“足夠”的樣本量。 這也可能是一個實驗,你的挑戰者粉碎了原版,你可以接受這個賭注!
正如 Jeff Bezos 在給亞馬遜股東的信中所寫的那樣,大型實驗付出了巨大的時間:
“假設有 10% 的機會獲得 100 倍的回報,你應該每次都下注。 但是十有八九你還是會錯。 我們都知道,如果你在圍欄上揮桿,你會打出很多三振,但你也會打出一些本壘打。 然而,棒球和商業之間的區別在於,棒球有一個截斷的結果分佈。 當你揮桿時,無論你與球的連接有多好,你最多可以跑四次。 在商業中,每隔一段時間,當你踏上盤子時,你就可以獲得 1000 分。 這種長尾的回報分佈就是為什麼大膽很重要。 大贏家為如此多的實驗買單。 “
在很大程度上,提早進行實驗就像每天都在偷看結果,然後停在一個可以保證下注的地方。

