您可以在您的網站上運行的所有不同類型的測試(+ 何時運行它們)
已發表: 2022-09-20
實驗世界大多已經超越了簡單的按鈕顏色 A/B 測試。
它們可能在您正在運行的實驗組合中佔有一席之地,但希望在這一點上,它們不是實驗或 CRO 的代名詞。
實驗可以大得多。
通過不同類型的實驗,我們可以了解我們網站上的差異,測試新體驗,發現新的頁面路徑,實現大躍進或小步驟,並確定頁面上元素的最佳組合。
您希望從實驗中學到的東西應該反映在它的設計中,並且實驗的設計遠遠超出了使用具體假設簡單地測試 A 與 B 的範圍。
事實上,有一個完整的研究子領域,稱為實驗設計 (DoE),涵蓋了這一點。
- 實驗設計:實驗設計導論
- 16 種常見的實驗類型
- 1. A/A 測試
- 2. 簡單的 A/B 測試
- 3. A/B/n 測試
- 4. 多元測試
- 5. 目標測試
- 6.強盜測試
- 7. 進化算法
- 8. 拆分頁面路徑測試
- 9. 存在測試
- 10. 彩繪門測試
- 11. 發現測試
- 12. 迭代測試
- 13. 創新測試
- 14. 非劣效性檢驗
- 15. 功能標誌
- 16.準實驗
- 結論
實驗設計:實驗設計導論
實驗設計 (DoE) 是一種科學方法,用於確定影響過程的因素與該過程的輸出之間的關係。
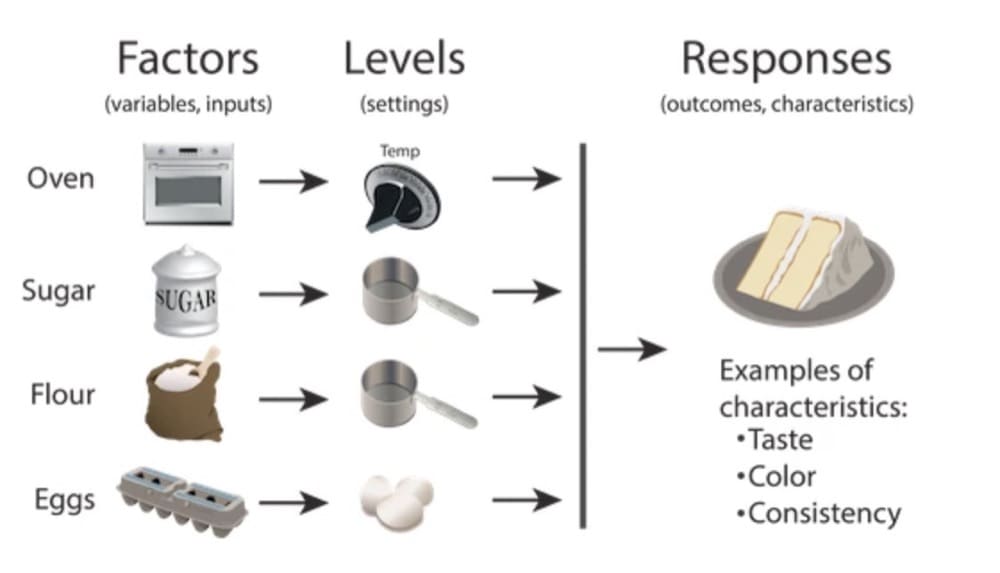
實驗設計是統計學家 Ron Fisher 在 1920 年代和 1930 年代推廣的概念。
DoE 允許我們通過系統地改變輸入並觀察輸出的結果變化來了解不同的輸入變量如何影響過程輸出。 這種方法可用於優化流程、開發新產品或功能,或了解哪些元素相互配合效果最佳。
在營銷中,我們使用 DoE 來提高我們對頁面上不同元素(因素)如何影響轉化率(輸出)的理解。 通過有效地設計實驗,我們可以確定哪些元素對轉化率的影響最大。
有許多不同類型的實驗,每種類型都可用於了解有關您的網站或應用程序的不同內容。
在本文中,我將介紹 16 種類型的實驗。
吹毛求疵的人可能會注意到,這些並不是完全不同的實驗設計。 相反,有些是不同的“類型”,因為你如何產生你的假設或者你運行實驗的原因是什麼框架。
此外,有些並不是完全“實驗”,而是建立在機器學習模型上的優化規則。
儘管如此,以下每一項都有不同的目的,並且可以被視為實驗者工具包中的獨特工具。
16 種常見的實驗類型
您可以在您的網站上運行許多不同類型的對照實驗,但這裡有 16 個最常見的:
1. A/A 測試
2.簡單的A/B測試
3. A/B/n 測試
4.多變量測試
5. 針對性測試
6.強盜測試
7. 進化算法
8.分頁路徑測試
9.存在測試
10. 彩繪門測試
11. 發現測試
12.增量測試
13.創新測試
14. 非劣效性檢驗
15. 功能標誌
16.準實驗
1. A/A 測試

A/A 測試是一個簡單的概念:您正在測試一個頁面的兩個相同版本。
你為什麼要這樣做?
有很多原因,主要是為了校準和了解測試工具的基礎數據、用戶行為和隨機化機制。 A/A 測試可以幫助您:
- 確定數據的方差水平
- 識別測試工具中的抽樣錯誤
- 建立基線轉化率和數據模式。
運行 A/A 測試是非常有爭議的。 有些人發誓。 有人說這是浪費時間。
我的看法? 由於上述所有原因,它可能值得至少運行一次。 我喜歡運行 A/A 測試的另一個原因是向測試新手解釋統計數據。
當你向某人展示一個收集了兩天數據的“重要”實驗,後來才發現它是一個 A/A 測試,那麼利益相關者通常會理解為什麼你應該運行一個實驗直到完成。
如果您想了解更多關於 A/A 測試的信息(實際上這是一個巨大的主題),Convert 有一個關於它們的深入指南。
用例:校準和確定數據方差、審計實驗平台錯誤、確定基線轉換率和样本要求。
2. 簡單的 A/B 測試

每個人都知道什麼是簡單的 A/B 測試:您正在測試一個頁面的兩個版本,一個有更改,一個沒有更改。
A/B 測試是實驗的基礎。 它們易於設置且易於理解,但也可用於測試重大更改。
A/B 測試最常用於測試用戶界面的更改,簡單的 A/B 測試的目標幾乎總是提高給定頁面的轉化率。
順便說一句,轉化率是一個通用指標,涵蓋了各種比例,例如新產品用戶的激活率、免費增值用戶的貨幣化率、網站上的潛在客戶轉化率和點擊率。
通過簡單的 A/B 測試,您有一個單一的假設並一次更改一個元素,以便盡可能多地了解更改的因果元素。 這可能是標題更改、按鈕顏色或大小更改、添加或刪除視頻或其他任何內容。

當我們說“A/B 測試”時,我們主要使用一個通用術語來涵蓋我將在這篇文章中列出的大多數其他實驗類型。 它通常用作一個概括性術語,意思是“我們改變了*某些東西*——大的、小的或許多元素——以改進指標。”
用例:很多! 通常用於測試由具體假設通知的數字體驗的單一變化。 A/B 測試通常是為了改進指標而運行的,同時也是為了了解干預後用戶行為發生的任何變化。
3. A/B/n 測試

A/B/n 測試與 A/B 測試非常相似,但不是測試頁面的兩個版本,而是測試多個版本。
A/B/n 測試在某些方麵類似於多變量測試(我將在接下來探討)。 然而,我認為這些不是“多變量”測試,而是多變量測試。
多變量測試有助於理解頁面上不同元素之間的關係。 例如,如果您想在產品頁面上測試不同的標題、圖像和描述,並且還想查看哪些組合看起來交互效果最好,您可以使用多變量測試。
A/B/n 測試對於測試單個元素的多個版本很有用,並且不太關心元素之間的交互效果。
例如,如果您想在著陸頁上測試三個不同的標題,您將使用 A/B/n 測試。 或者,您可以只測試七個完全不同的頁面版本。 這只是一個 A/B 測試,測試了兩個以上的經驗。
當您有大量流量並希望有效地測試多個變體時,A/B/n 測試是可靠的選擇。 當然,需要對多個變體的統計數據進行校正。 關於在 A/B/n 測試中應該包含多少變體也存在很多爭論。
通常,您可以在一次測試多個體驗時推送一些更具原創性和創造性的變體,而不是在多個簡單的 A/B 測試中迭代。
用例:當您擁有可用流量時,多個變體非常適合測試各種體驗或元素的多次迭代。
4. 多元測試

多變量測試是具有多個更改的實驗。 如果 A/B/n 測試是針對其他變體測試每個變體的複合版本,多變量測試還旨在確定被測元素之間的相互作用效果。
例如,想像一下您正在重新設計一個主頁。 您已經完成了轉換研究並發現了標題的清晰度問題,但您也對 CTA 中的對比度和清晰度水平有一些假設。
您不僅有興趣單獨改進這兩個元素中的每一個,而且這些元素的性能也可能是相關的。 因此,您想查看新標題和 CTA 的哪種組合效果最好。
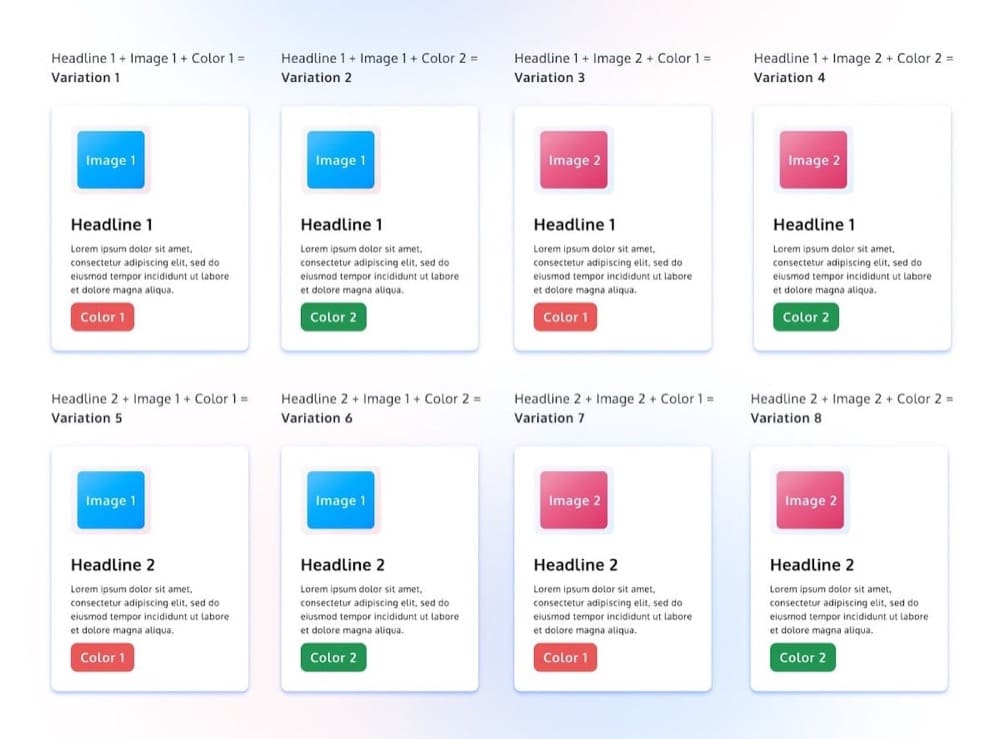
當您進入多變量領域時,實驗設計變得更加複雜。 有幾種不同類型的多變量實驗設置,包括全因子設計、部分或部分因子設計以及田口檢驗。
就像統計常識一樣,多變量測試幾乎肯定需要比簡單的 A/B 測試更多的流量。 您更改的每個附加元素或體驗都會增加您獲得有效結果所需的流量。
用例:多變量實驗似乎對通過調整幾個小變量來優化體驗特別有益。 每當您想確定元素的最佳組合時,都應考慮多變量測試。
5. 目標測試
針對性測試,更廣為人知的個性化測試,都是關於在正確的時間向正確的人展示正確的信息。
通過定位測試,您可以創建不同版本的頁面並將每個版本顯示給不同的人群。 目標通常是通過向每個用戶展示相關內容來提高轉化率。
請注意,個性化和實驗不是同義詞。 您可以個性化體驗,而無需將其視為實驗。 例如,您可以根據零數據或收集數據的意圖來決定,您將在電子郵件中使用名字令牌來個性化帶有收件人姓名的消息。
個性化? 是的。 實驗? 不。
但您也可以針對特定用戶群進行實驗。 這在產品實驗中尤其常見,您可以根據他們的定價層、註冊時間、註冊來源等來隔離群組。
相同的統計數據適用於個性化實驗,因此選擇有意義的細分受眾群非常重要。 如果您過於細化——比如針對擁有 5 到 6 次會話的堪薩斯農村移動 Chrome 用戶——不僅無法從統計上量化影響,而且也不太可能產生有意義的業務影響。
個性化通常被視為簡單 A/B 測試的自然擴展,但在許多方面,它引入了大量新的複雜性。 對於您採用的每條新的個性化規則,這就是您為用戶創建的一個新的“宇宙”,以便管理、更新和優化。
預測性個性化工具可幫助您識別目標細分以及似乎更適合它們的體驗。 否則,個性化規則通常通過進行測試後分割來識別。
用例:將治療隔離到用戶群的特定部分。
6.強盜測試

強盜測試或使用強盜算法有點技術性。 但基本上它們與 A/B 測試不同,因為它們不斷學習和更改向用戶顯示的變體。
A/B 測試通常是“固定範圍”實驗(使用順序測試的技術警告),這意味著您在運行測試時預先確定了試用期。 完成後,您將決定是推出新變體還是恢復為原始變體。
Bandit 測試是動態的。 他們根據其性能不斷更新每個變體的流量分配。
理論是這樣的:你走進一家賭場,偶然發現幾台老虎機(多臂強盜)。 假設每台機器有不同的獎勵,老虎機問題有助於“決定玩哪台機器,每台機器玩多少次,以什麼順序玩它們,以及是繼續使用當前機器還是嘗試不同的機器。”
這裡的決策過程被分解為“探索”,您嘗試收集數據和信息,以及“利用”,利用這些知識產生高於平均水平的回報。
因此,網站上的強盜測試將尋求實時找到最佳變體,並向該變體發送更多流量。
用例:具有高“易腐性”的短期實驗(意味著從結果中學到的知識不會延伸到很遠的未來),以及長期的“設置它並忘記它”動態優化。
7. 進化算法
進化算法是多變量測試和老虎機測試之間的一種組合。 在營銷實驗的背景下,進化算法允許您同時測試大量變體。
進化算法的目標是找到頁面上元素的最佳組合。 它們的工作原理是創建一個變體“群體”,然後對它們進行相互測試。 然後將性能最佳的變體用作下一代的起點。

顧名思義,它使用進化迭代作為優化模型。 你有大量不同版本的標題、按鈕、正文和視頻,你將它們拼接在一起以創建新的突變,並動態地嘗試消除弱變體並將更多流量發送到強變體。
這就像對類固醇的多變量測試,儘管交互效果的透明度較低(因此,學習潛力較低)。
這些實驗還需要相當多的網站流量才能正常工作。
用例:大規模的多變量測試,將多個創意版本拼接在一起,並在所有組合中找到新的贏家。
8. 拆分頁面路徑測試
拆分頁面路徑測試也是一種非常常見的 A/B 測試。
您不是在更改單個頁面上的元素,而是更改用戶通過您的網站的整個路徑。
通過拆分頁面路徑測試,您實際上是在測試您的網站、產品或渠道的兩個不同版本。 目標通常是找到能帶來更多轉化或銷售的版本。 它還可以幫助識別漏斗中的下降點,從而診斷重點區域以進行進一步優化。
基本上,不是更改按鈕上的副本,而是更改按鈕發送給您的下一頁(如果您單擊它)。 這是試驗客戶旅程的有效方式。
用例:識別和改進產品或網站中的頁面路徑和用戶漏斗。
9. 存在測試

存在測試是一個有趣的概念。 您要做的是量化產品或網站中給定元素的影響(或缺乏影響)。
根據 CXL 文章,“簡單地說,我們會刪除您網站的元素,看看您的轉化率會發生什麼變化。”
換句話說,您正在測試一個更改是否有任何影響。
從戰略上講,這是一個被低估的戰略。 我們經常通過我們自己的啟發式或通過定性研究來假設頁面上哪些元素是最重要的。
當然,產品演示視頻很重要。 存在測試是一種質疑這種信念並迅速得到答案的方法。
您只需刪除視頻,看看會發生什麼。
轉化率提高還是降低? 有趣——這意味著它所佔據的元素或房地產在某種程度上是有影響的。
沒有影響? 這也很有趣。 在這種情況下,我會將我的團隊的重點放在數字體驗的其他部分,因為我知道即使完全刪除元素也不會對我們的 KPI 產生任何影響。
用例: “轉換信號映射”。 從本質上講,這可以告訴您網站上元素的彈性,也就是它們是否足以讓您專注於優化工作?
10. 彩繪門測試

塗漆門測試在某種程度上類似於存在測試。 它們在測試新報價以及測試對新產品功能的需求方面非常常見。
基本上,塗漆門測試是一個實驗,看看人們是否會真正使用新功能。 您實際上並沒有花費時間和資源來*創建*新的產品或功能。 相反,您創建一扇“彩繪門”以查看路過的人是否會嘗試打開它(即您創建一個按鈕或登錄頁面並查看人們是否甚至單擊它,從而推斷出興趣)。
塗漆門測試的目的是找出您正在測試的東西是否有任何需求。 如果人們真的在使用這個新功能,那麼你就知道它值得追求。 如果沒有,那麼你知道這不值得你花時間,可以放棄這個想法。
它們也被稱為冒煙測試。
彩繪門測試是測試新想法的好方法,無需投入大量時間或金錢。
因為您實際上沒有報價或創建經驗,所以通常不能使用轉化率等 KPI。 相反,您必須模擬出期望值的最小閾值。 例如,創建 X 功能將花費 Y,因此鑑於我們現有的基線數據,我們需要查看 Y 點擊率來保證創建“真實”體驗。
在某些方面,發布前的等待名單是一個塗漆的門測試(著名的例子是哈利的剃須刀)。
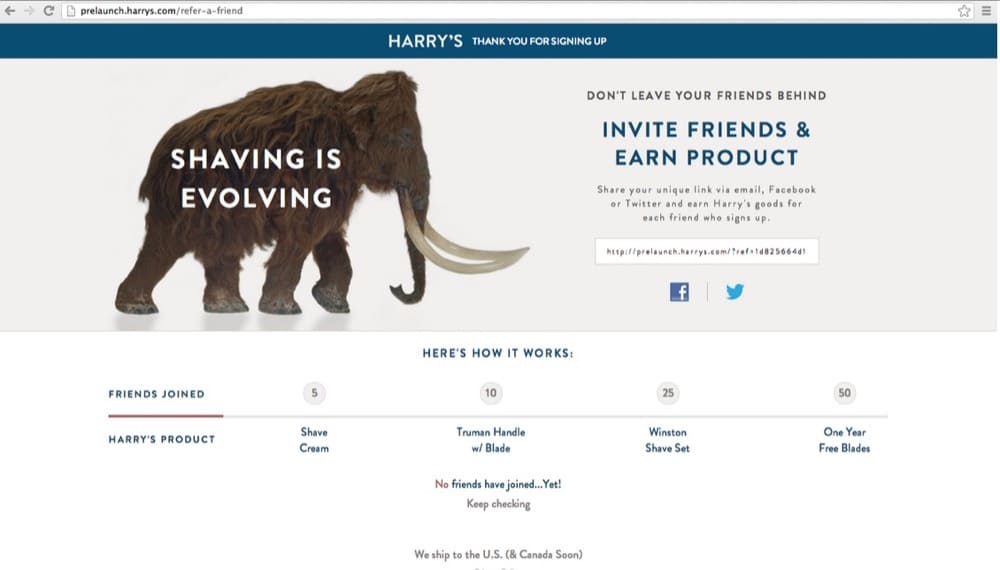
用例:證明投入時間和資源來創建新功能、產品或體驗的商業案例。
11. 發現測試

我從 Andrew Anderson 的基於學科的測試方法中提取的發現測試都是關於增加可能選項的範圍。
它們幾乎總是具有多種變體的 A/B/n 測試的一個版本,但它們不一定必須這樣設計。 這些的更大目的是測試超出您通常認為合理的範圍的選項。 這減輕了你自己的偏見,這可能會限制你曾經考慮過的選項的範圍。
與其狹隘地定義一個假設,你希望擺脫自己的偏見,並有可能了解一些關於什麼對你的聽眾有效的全新的東西。
要進行發現測試,您需要在您的產品或網站上獲取一塊不動產並生成一堆不同的變體。 目標是每個變體都與上一個完全不同,為您提供多種不同的選擇。 目標是找到有用的東西,即使你事先不知道它是什麼。
在發現測試中,重要的是要將您的實驗映射到您的宏觀 KPI,而不是針對微觀轉化進行優化。 對有意義的高流量體驗進行測試也很重要,因為您需要適當的統計能力來發現眾多變體之間的提升。
要查看此類實驗的示例,請查看來自 Malwarebytes 的 Andrew Anderson 的示例,他們在其中測試了 11 種截然不同的變體。
用例:將您的實驗工作從有偏見的假設中解脫出來,並找到開箱即用的解決方案,儘管它們可能違背您的直覺,但最終會推動業務成果。
12. 迭代測試

計算機科學中有一個被稱為“爬山問題”的概念。 基本上,爬山算法通過從底部開始並不斷向上移動來尋找景觀中的最高點。
同樣的概念也可以應用於營銷實驗。
通過迭代測試,您從一個小的更改開始,然後不斷擴大,直到達到收益遞減點。 這個收益遞減點被稱為“局部最大值”。 局部最大值是從您的起點可以到達的景觀中的最高點。
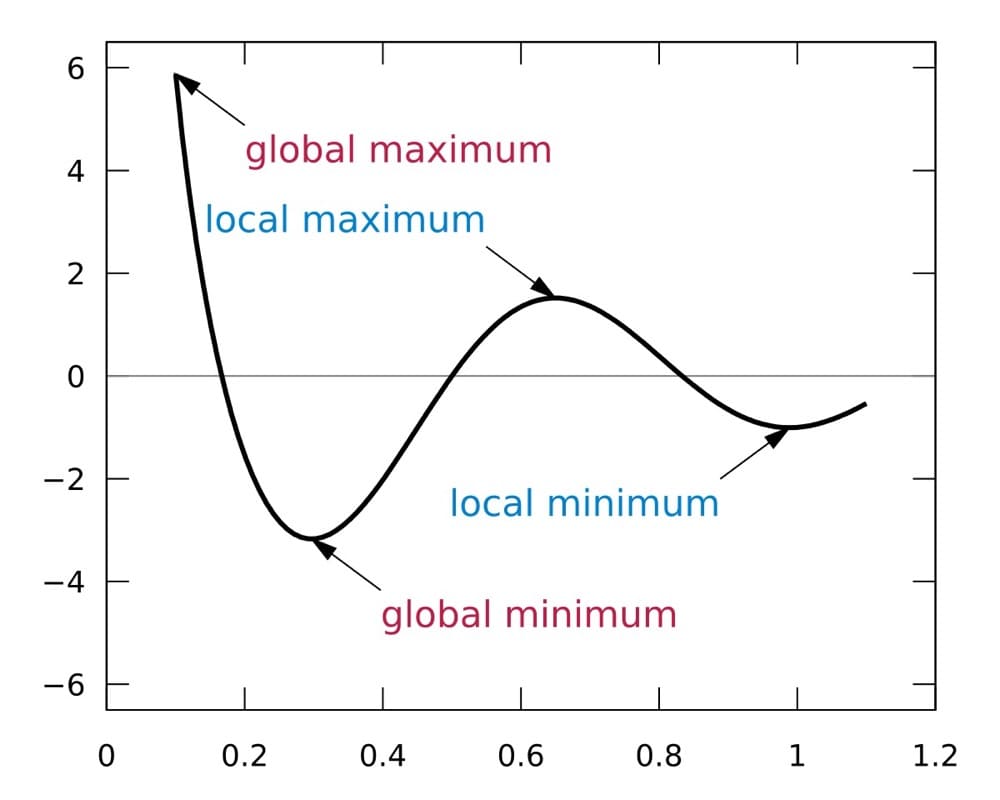
迭代測試的目標是找到給定變化的局部最大值。 這可能是一種非常有效的方法來測試諸如報價更改或定價更改之類的事情,以及您通過研究或通過存在測試發現有影響的任何元素。
基本上,您知道 X 元素很重要,並且您知道通過改進元素 X 來改進 KPI Y 有額外的迴旋餘地。因此,您在更改元素 X 時進行了幾次小的迭代嘗試,直到看起來您無法再改進指標(或這樣做非常困難)。
一個簡單的迭代測試示例來自我自己的網站。 我運行鉛磁鐵彈出窗口。 我知道他們推動電子郵件,並且可能存在收益遞減點,但我認為我還沒有達到它。 所以每隔幾個月,我就會改變一個變量——要么是標題,要么是報價本身,要么是圖片,希望能擠出一點點。
用例:通過連續測試幾次小迭代來優化目標元素或體驗以達到局部最大值。
13. 創新測試

與迭代測試相反,創新測試尋求找到全新的山峰來攀登。
根據 CXL 的一篇文章,創新測試“旨在探索未知領域並尋找新機會”。
創新測試都是關於嘗試全新的東西。 它們通常比其他類型的實驗風險更大,但它們也可能非常有益。 如果您正在尋找重大勝利,那麼創新測試就是您的最佳選擇。
完整的主頁或登陸頁面重新設計屬於此類別。 發現測試是創新測試的一種形式。 按鈕顏色測試與創新測試完全相反。
一個創新的測試應該讓你或你的利益相關者有點不舒服(但請記住,實驗的美妙之處在於它們的持續時間有限,並限制了你的缺點)。
CXL 舉了一個他們為客戶運行的創新測試的例子:
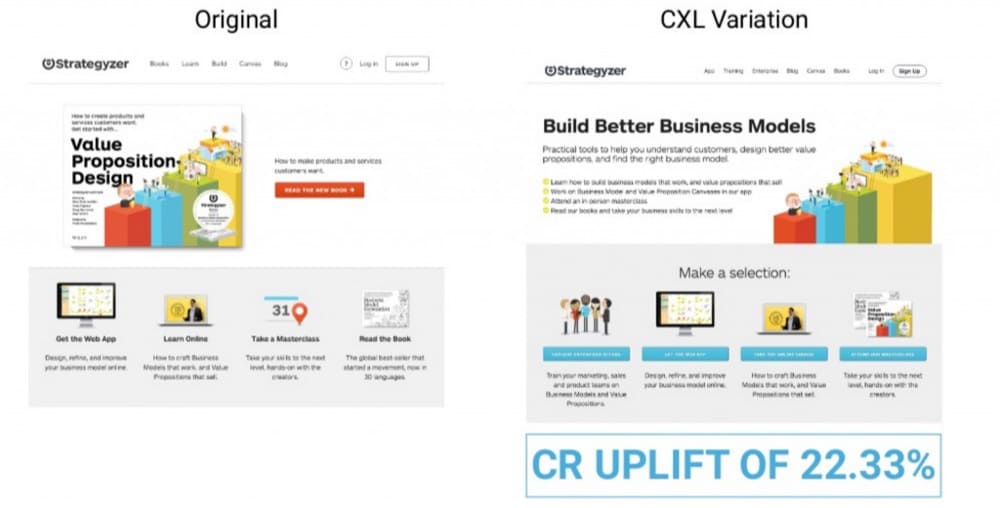
用例:大搖大擺,找到一個新的“山”來攀登。 總結幾個假設並徹底改變體驗。
14. 非劣效性檢驗

非劣效性測試用於確定新治療是否不比標準治療差。
非劣效性測試的目標是表明新療法至少與標準療法一樣有效。
為什麼要進行這樣的測試?
很多原因。 我能想到的最好的一個是,如果你有一個在其他方面“更好”的變體(維護成本更低,更符合品牌標準等),但你想確保它不會損害你的核心業務KPI。
或者從醫學臨床試驗的角度來看,想像一種藥物的開發成本是常用藥物的 1/10。 只要它的性能不比現有藥物*差*,它的可負擔性就意味著它是一個更好的推廣選擇。
我運行這些的另一個原因是,如果這種處理方式受到高管或利益相關者的青睞。 討厭打破它,但僅僅因為我們可以作為實驗專業人士訪問數據並不意味著我們避免了偏見思維和人類政治的混亂。
我很高興偶爾接受 HiPPO 提交的測試,並通過非劣效性測試等較低的確定性閾值來運行它。 只要它不會弄亂*我的* KPI,推出它就沒有壞處,並且它贏得了政治支持。
用例:限制另一個維度(成本高、利益相關者偏好、用戶體驗、品牌等)的實驗的缺點。
15. 功能標誌

特性標誌是一種軟件開發技術,允許您打開或關閉某些特性或功能,並在生產中測試新特性。
在不涉及大量技術細節的情況下,它們允許您在生產中測試功能或將它們緩慢推出給較小的用戶子集,同時保持快速縮減或在功能不起作用時終止功能的能力。
在許多方面,它們是一種質量保證方法。 但話又說回來,在很多方面,A/B 測試也是如此。
術語“功能標誌”在某種程度上是一個總稱,包括許多相關的“切換”功能,如金絲雀發布、生產測試、持續開發、回滾和功能門。
用例:在將新代碼部署到生產環境之前測試新功能或體驗。
16.準實驗
最後,最複雜、最廣泛、最難定義的實驗類別:準實驗。
當不可能將用戶隨機分配到測試組時,通常會使用準實驗。
例如,如果您正在測試網站上的新功能,您可以運行 A/B 測試、功能標誌,甚至是個性化臂。
但是,如果您想測試一堆 SEO 更改並查看它們對流量的影響怎麼辦? 或者更進一步,它們對博客轉化的影響? 如果要測試戶外廣告牌的效果怎麼辦?
在數量驚人的情況下,即使不是不可能,也很難建立一個組織嚴密、真正受控的實驗。
在這些情況下,我們會設計準實驗來利用我們所擁有的。
在 SEO 變化的情況下,我們可以使用因果影響等工具來量化時間序列的變化。 特別是如果我們根據頁面或其他可識別的維度來控制我們的實驗,這將為我們提供一個很好的縱向想法,即我們的干預是否有效。
在廣播或廣告牌廣告的情況下,我們可以嘗試選擇具有代表性的地理位置,並使用類似的貝葉斯統計來量化一段時間內的影響。
這是一個複雜的話題,所以我將鏈接到兩個很好的資源:
- Netflix 如何進行準實驗
- Shopify 如何進行準實驗
用例:在隨機對照試驗不可行或不可行時量化影響。
結論
我希望這能讓您相信 A/B 測試遠遠超出了更改標題或 CTA 按鈕以優化轉化率。
當您擴大實驗可以完成的範圍時,您會意識到這是一個令人難以置信的學習工具。
我們可以在著陸頁上繪製有影響力的元素,確定元素的最佳組合,找出新的和改進的用戶頁面路徑,開發新的功能和體驗,而不會冒技術債務或糟糕的用戶體驗的風險,甚至測試新的營銷渠道在我們的網站之外或在我們的產品之外進行干預。