
使用者體驗的新時代:改進人工智慧產品的設計方法
已發表: 2024-01-18一年前,在 ChatGPT 出現之前,人工智慧 (AI) 和機器學習 (ML) 是專家和資料科學家的神秘工具,他們的團隊擁有豐富的利基經驗和專業領域知識。 現在,情況不同了。
您閱讀本文的原因可能是您的公司決定使用 OpenAI 的 GPT 或其他 LLM(大型語言模型)在您的產品中建立生成式 AI 功能。 如果是這種情況,您可能會感到興奮(「製作一個很棒的新功能是如此容易!」)或不知所措(「為什麼我每次都會得到不同的輸出以及如何讓它做我想要的事情? )或者也許你兩者都有感覺!
使用人工智慧可能是一個新的挑戰,但它並不需要令人生畏。 這篇文章將我多年來設計「傳統」ML 方法的經驗提煉為一組簡單的問題,以幫助您在開始 AI 設計時充滿信心地前進。
一種不同的使用者體驗設計
首先,了解一些有關 AI UX 設計與您習慣的設計有何不同的背景知識。 (注意:在這篇文章中我將交替使用 AI 和 ML。)您可能熟悉 Jesse James Garrett 的 UX 設計的 5 層模型。
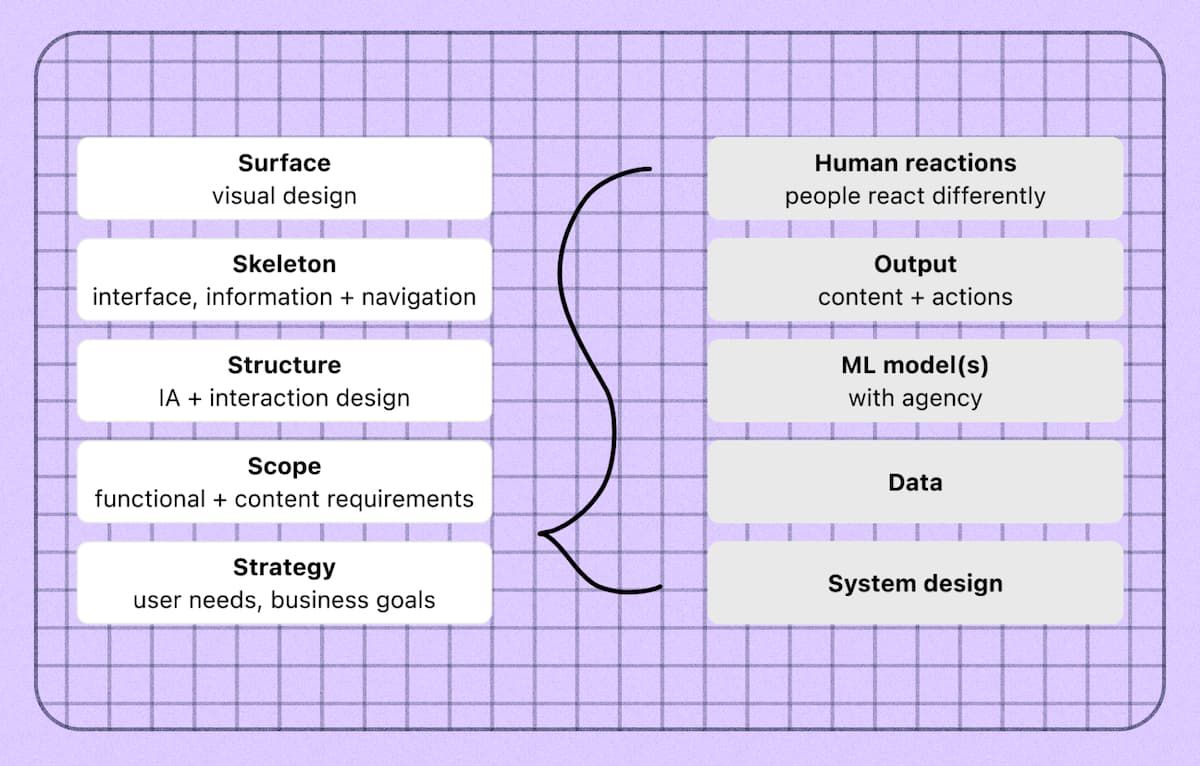
Jesse James Garrett 的使用者體驗要素圖
Garrett 的模型適用於確定性系統,但沒有捕捉機器學習專案的額外元素,這些元素將影響下游的使用者體驗考慮因素。 使用機器學習意味著在模型中、策略層及其周圍添加許多附加層。 現在,除了您習慣的設計之外,您還需要更深入地了解:
- 系統是如何建構的。
- 您的功能可以使用哪些數據,它包含哪些內容,它的品質和可靠性如何。
- 您將使用的機器學習模型及其優點和缺點。
- 您的功能將產生的輸出、它們將如何變化以及它們何時失敗。
- 人們對此功能的反應可能與您預期或想要的不同。
不要問自己“我們該怎麼做?” 在回答一個已知的、範圍內的問題時,您可能會問自己:“我們可以這樣做嗎?”
特別是如果您使用法學碩士,您可能會從解鎖全新功能的技術開始向後工作,並且您必須確定它們是否適合解決您知道的問題,甚至是您從未認為可以解決的問題前。 您可能需要比平常更高的水平思考 - 您可能想要合成大量資訊並呈現趨勢、模式和預測,而不是顯示資訊單元。
“您正在設計一個動態的機率系統,並且可以即時對輸入做出反應”
最重要的是,您不是設計一個按照您的指示執行操作的確定性系統,而是設計一個動態的概率系統,該系統對輸入實時做出反應- 其結果和行為有時會是意外或無法解釋的,權衡權衡可能是一項模糊的工作。 這就是我的五個關鍵問題發揮作用的地方 - 不是為您提供答案,而是幫助您在面對不確定性時採取下一步。 讓我們深入了解一下。
1. 如何確保良好的數據?
資料科學家喜歡說「垃圾進,垃圾出」。 如果你從糟糕的數據開始,通常不可能獲得良好的人工智慧功能。
例如,如果您正在建立一個根據一系列資訊來源(例如線上幫助中心的文章)產生答案的聊天機器人,那麼低品質的文章將導致聊天機器人的品質也較低。
當 Intercom 團隊在 2023 年初推出 Fin 時,我們意識到,許多客戶在開始使用 Fin 並發現其中存在或不存在或清晰的資訊之前,對其幫助內容的品質沒有準確的認識。他們的內容。 對有用的人工智慧功能的渴望可以成為團隊提高數據品質的絕佳動力。
那麼,什麼是好數據呢? 好的數據是:
- 準確:數據正確地反映了現實。 也就是說,如果我身高 1.7m,我的健康紀錄上就是這麼寫的。 沒有說我身高1.9m。
- 完整:數據包含所需的值。 如果我們需要測量身高來進行預測,那麼該數值就會出現在所有患者的健康記錄中。
- 一致:數據與其他數據不矛盾。 我們沒有兩個高度字段,一個表示 1.7m,另一個表示 1.9m。
- 新鮮:數據是最近且最新的。 如果您現在是成年人,您的健康記錄不應該反映您 10 歲時的身高 - 如果發生變化,記錄應該進行更改以反映它。
- 唯一:數據不重複。 我的醫生不應該為我保留兩份病歷,否則他們不知道哪一份是正確的。
擁有大量真正高品質的數據很少見,因此在開發人工智慧產品時,您可能必須進行品質/數量權衡。 您也許能夠手動創建較小的(但希望仍然具有代表性的樣本)數據,或者過濾掉舊的、不準確的數據以創建可靠的數據集。
嘗試在開始設計過程時準確地了解數據的質量,並製定改進計劃(如果一開始效果不佳)。
2. 您將如何調整您的設計流程?
與往常一樣,從低保真探索開始以確定您希望解決的問題的理想用戶體驗是有用的。 您可能永遠不會在生產中看到它,但這顆北極星可以幫助您和您的團隊保持一致,讓他們感到興奮,並提供一個具體的起點來研究它實際上的可行性。
“花一些時間了解系統如何工作、如何收集和使用數據以及您的設計是否捕獲了模型輸出中可能看到的差異”
一旦有了這些,就可以設計系統、數據和內容輸出了。 回到你的北極星並問「我的設計實際上可行嗎? 如果 X 或 Y 效果不佳,會有哪些變化?”
花一些時間了解系統如何運作、如何收集和使用資料以及您的設計是否捕捉了模型輸出中可能看到的差異。 對人工智慧來說,糟糕的輸出就是糟糕的體驗。 在聊天機器人的範例中,這可能看起來像是一個沒有提供足夠細節的答案,回答了一個離題的問題,或者在應該澄清問題的時候沒有澄清問題。
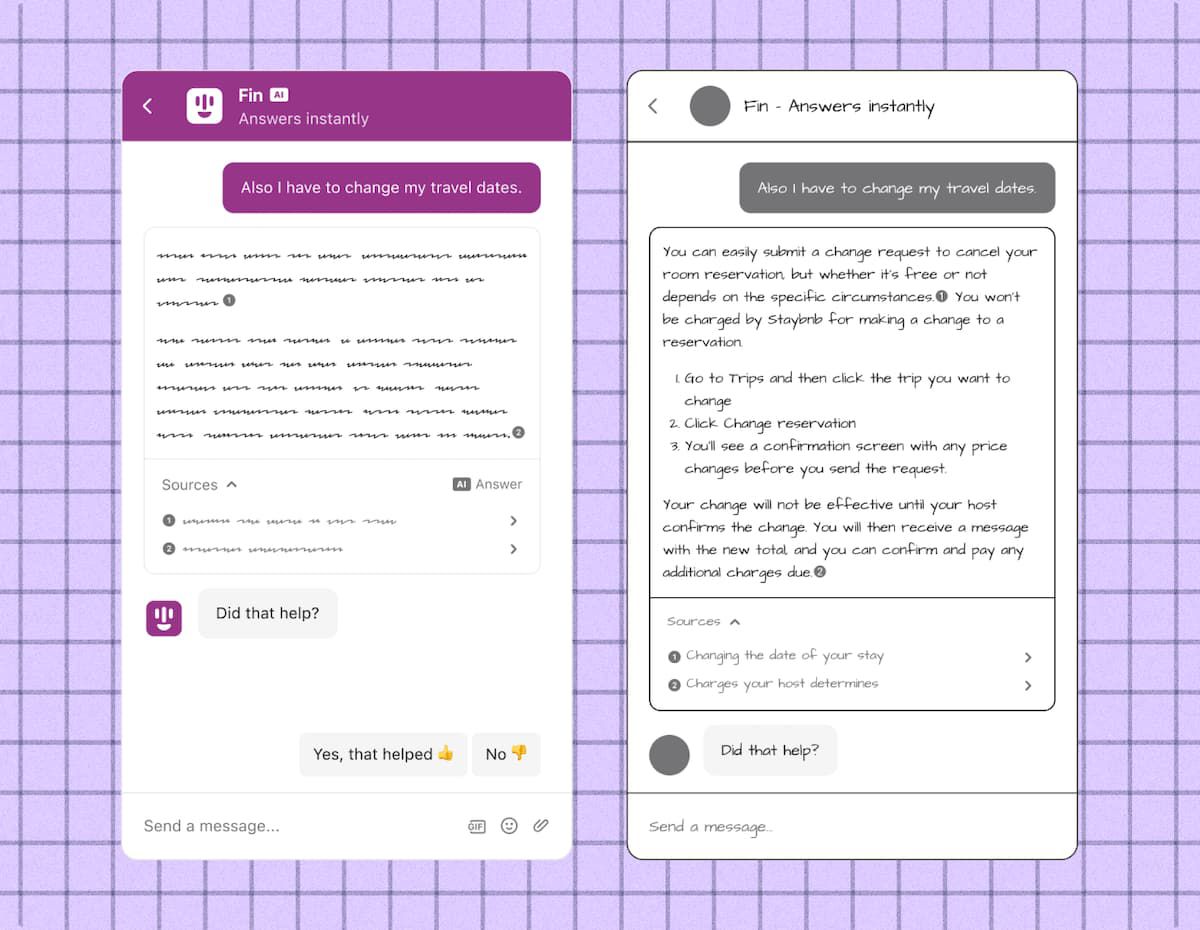
 如何顯示人工智慧聊天機器人輸出的兩個範例
如何顯示人工智慧聊天機器人輸出的兩個範例
在上圖中,左側的範例與我們在開發Fin 聊天機器人時看到的許多早期輸出類似,這些輸出很準確,但資訊量不大或有用,因為它們引用了原始文章,而不是內聯說明答案。 設計可以幫助您獲得右側的範例,該範例具有更完整的答案以及清晰的步驟和格式。
不要將輸出的內容留給工程師-應該設計它的體驗。 如果您正在開發基於法學碩士的產品,這意味著您應該嘗試即時工程,並就輸出的形狀和範圍形成自己的觀點。
您還需要考慮如何針對一組新的潛在錯誤狀態、風險和限制進行設計:
錯誤狀態
- 冷啟動問題:客戶第一次使用您的功能時可能只有很少或沒有數據。 他們如何從一開始就獲得價值?
- 沒有預測:系統沒有答案。 然後會發生什麼事?
- 錯誤的預測:系統給的輸出很差。 用戶會知道這是錯的嗎? 他們能修好嗎?
風險
- 誤報,例如天氣預報預測會下雨,但實際上並沒有下雨。 如果您的產品發生這種情況,會產生負面結果嗎?
- 誤報,例如天氣預報預測不會下雨,但卻下起了傾盆大雨。 如果您的功能發生這種情況,結果會如何?
- 現實世界的風險,例如機器學習輸出直接影響或影響人們的生活、生計和機會。 這些適用於您的產品嗎?
新的限制
- 使用者限制,例如關於系統如何運作的不正確的心理模型、對產品不切實際的期望或恐懼,或隨著時間的推移而自滿的可能性。
- 技術限制,例如 API 或儲存和運算成本、延遲、正常運行時間、資料可用性、資料隱私和安全性。 這些主要是您的工程師面臨的問題,但它們也可能對使用者體驗產生直接影響,因此您應該了解其局限性和可能性。
3. 當機器學習失敗時它將如何運作?
當,而不是如果。 如果您對人工智慧產品在生產中失敗的方式感到驚訝,那麼您事先沒有進行足夠的測試。 您的團隊應該在整個建置過程中測試您的產品和輸出,而不是等到您即將將功能交付給客戶時才測試。 嚴格的測試將使您清楚地了解您的產品如何以及何時可能出現故障,因此您可以建立使用者體驗來減輕這些故障。 以下是一些可以有效測試產品的方法。

從您的設計原型開始
盡可能使用真實數據製作原型。 「Lorem ipsum」是你的敵人——使用真實的例子來對你的產品進行壓力測試。 例如,在開發我們的人工智慧聊天機器人 Fin 時,使用真實的幫助中心文章作為來源材料來測試對真實客戶問題的答案的品質非常重要。
兩位設計師如何設計提供人工智慧生成答案的聊天機器人的範例
在此比較中,我們可以看到左側的彩色範例在視覺上更具吸引力,但沒有提供有關答案生成體驗品質的詳細資訊。 它具有較高的視覺保真度,但內容保真度較低。 右側的範例對於測試和驗證 AI 響應實際上具有良好的品質提供了更多信息,因為它具有很高的內容保真度。
設計師通常更熟悉視覺保真度範圍內的工作。 如果您正在針對 ML 進行設計,您應該致力於在內容保真度範圍內進行工作,直到您完全驗證輸出對於使用者來說具有足夠的品質。
色彩繽紛的 Fin 設計並不能幫助你判斷聊天機器人是否能很好地回答問題,以至於客戶會為此付費。 透過向客戶展示原型(無論多麼簡單),您將獲得更好的回饋,該原型向他們展示實際數據的真實輸出。
大規模測試
當您認為自己已經實現了一致的高品質輸出時,請進行回溯測試以在更大範圍內驗證您的輸出品質。 這意味著讓您的工程師返回並根據您知道或可以可靠地判斷輸出品質的更多歷史資料運行演算法。 您應該檢查輸出的品質和一致性,並發現任何意外情況。
將您的最小可行產品 (MVP) 作為測試
您的 MVP 或 beta 版本應該可以幫助您解決任何剩餘的問題並發現更多潛在的驚喜。 跳出框框思考您的 MVP – 您可以在產品中建立它,也可以只是一個電子表格。
“讓輸出發揮作用,然後圍繞它構建產品外殼”
例如,如果您正在建立一個功能,將多組文章聚集到主題區域中,然後定義主題,那麼您需要確保在建立完整的 UI 之前已經獲得了聚集。 如果您的叢集不好,您可能需要以不同的方式解決問題,或允許不同的互動來調整叢集大小。
您可能想要「建立」一個 MVP,它只是輸出和命名主題的電子表格,然後看看您的客戶是否發現您的做法有價值。 讓輸出發揮作用,然後圍繞它建立產品外殼。
啟動 MVP 時執行 A/B 測試
您需要衡量您的功能的正面或負面影響。 作為設計師,您可能不會負責設定此內容,但您應該設法了解結果。 這些指標是否顯示您的產品有價值? UI 或 UX 中是否有任何混雜因素,您可能需要根據您所看到的內容進行變更?
“您可以將產品使用情況的遙測數據與定性用戶反饋結合起來,以更好地了解用戶如何與您的功能互動以及他們從中獲得的價值”
在 Intercom AI 團隊中,每當我們發布具有足夠多交互量的新功能時,我們都會執行 A/B 測試,以便在幾週內確定統計顯著性。 不過,對於某些功能,您只是沒有足夠的數量- 在這種情況下,您可以使用產品使用情況的遙測數據與定性用戶反饋相結合,以更好地了解用戶如何與您的功能交互以及他們從中獲得的價值它。
4. 人類將如何融入這個系統?
在建立人工智慧產品時,您應該考慮產品使用生命週期的三個主要階段:
- 使用前設定該功能。 這可能包括選擇產品運作的自主等級、整理和過濾用於預測的資料以及設定存取控制。 這方面的一個例子是 SAE 國際自動駕駛汽車自動化框架,該框架概述了車輛可以自行做什麼,以及允許或需要多少人為幹預。
- 在功能運作時對其進行監控。 系統在運作時是否需要有人來保持其正常運作? 您是否需要批准步驟來確保品質? 這可能意味著在將人工智慧輸出發送給最終用戶之前進行操作檢查、手動指導或即時批准。 人工智慧文章寫作助理就是一個例子,它建議對草稿幫助文章進行編輯,作者必須在發布之前批准該文章。
- 啟動後評估該功能。 這通常意味著報告、提供回饋或採取行動回饋,以及管理資料隨時間的變化。 在此階段,使用者回顧自動化系統的執行情況,將其與歷史資料進行比較或查看品質並決定如何改進它(透過模型訓練、資料更新或其他方法)。 例如,一份報告詳細說明了最終用戶向您的 AI 聊天機器人提出了哪些問題、得到了哪些答复,以及您可以進行哪些更改以改進聊天機器人對未來問題的回答的建議。
您也可以使用這三個階段來幫助告知您的產品開發路線圖。 您可以擁有基於相同或非常相似的後端機器學習技術的多個產品和多個 UI,只需改變人類參與的位置即可。 人類在生命週期不同階段的參與可以徹底改變產品主張。
您也可以根據時間進行人工智慧產品設計:現在建立一些在某個時候可能需要人工的產品,但計劃在最終用戶習慣了輸出和品質後將其刪除或移至不同的階段的AI功能。
5. 您將如何建立使用者對系統的信任?
當你將人工智慧引入產品時,你就引入了一個具有在系統中發揮作用的代理的模型,而以前只有用戶自己擁有該代理。 這會增加客戶的風險和不確定性。 您的產品受到的審查等級將會提高,這是可以理解的,您需要贏得用戶的信任。
您可以嘗試透過以下幾種方式來做到這一點:
- 提供「暗啟動」或並行體驗,客戶可以比較輸出或查看輸出,而無需將其暴露給最終用戶。 可以將其視為您在流程早期進行的回溯測試的面向用戶的版本 - 這裡的重點是讓您的客戶對您的功能或產品將提供的輸出的範圍和品質充滿信心。 例如,當我們推出 Intercom 的 Fin AI 聊天機器人時,我們提供了一個頁面,讓客戶可以上傳並根據自己的資料測試機器人。
- 首先在人工監督下啟動此功能。 經過一段時間的良好性能後,您的客戶可能會相信它可以在沒有人工監控的情況下運作。
- 如果該功能不起作用,請輕鬆關閉該功能。 如果使用者不存在可能搞砸事情並且無法阻止它的風險,那麼使用者就可以更輕鬆地在他們的工作流程(尤其是業務工作流程)中採用人工智慧功能。
- 建立回饋機制,以便使用者可以報告不良結果,並且理想情況下讓您的系統根據這些報告採取行動以改善系統。 但是,請務必對回饋何時以及如何採取行動設定現實的期望,這樣客戶就不會期望立即得到改進。
- 建立強大的報告機制,幫助您的客戶了解人工智慧的表現以及他們從中獲得的投資報酬率。
根據您的產品,您可能需要嘗試其中多種方法,以鼓勵使用者獲得經驗並對您的產品感到滿意。
對人工智慧來說,耐心是一種美德
我希望這五個問題能幫助引導您進入快速發展的人工智慧產品開發新世界。 最後一項建議:推出產品時要有耐心。 啟動並運行機器學習功能並使其適應公司喜歡的工作方式可能需要付出巨大的努力,因此採用曲線可能與您預期的不同。
“建立一些人工智慧功能後,您將開始更好地了解特定客戶對新產品的反應”
客戶可能需要一些時間才能看到最高價值,或者他們才能說服利害關係人人工智慧值得付出成本並且應該更廣泛地向用戶推出。
即使客戶對您的功能非常感興趣,也可能仍然需要時間來實現它,要么是因為他們需要做清理資料等準備工作,要么是因為他們正在努力在啟動之前建立信任。 可能很難預測您應該期望什麼樣的採用,但是在您建立了一些人工智慧功能之後,您將開始更好地了解您的特定客戶對新發布的反應。
