
什麼是 CTR 曲線以及如何用 Python 計算它?
已發表: 2022-03-22CTR 曲線,或者換句話說基於位置的有機點擊率,是顯示搜索引擎結果頁面 (SERP) 上有多少藍色鏈接根據其位置獲得 CTR 的數據。 例如,大多數時候,SERP 中的第一個藍色鏈接獲得的點擊率最高。
在本教程結束時,您將能夠根據其目錄計算您網站的 CTR 曲線,或根據 CTR 查詢計算自然 CTR。 我的 Python 代碼的輸出是一個描述站點 CTR 曲線的有見地的箱形圖和條形圖。
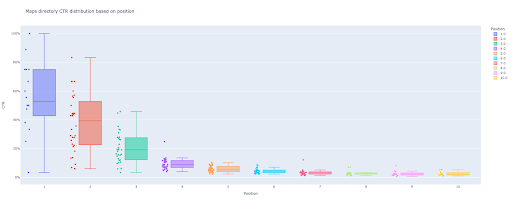
如果您是初學者並且不知道 CTR 的定義,我將在下一節中詳細解釋。
什麼是自然點擊率或自然點擊率?
點擊率來自於將自然點擊次數劃分為展示次數。 例如,如果 100 人搜索“蘋果”,30 人點擊第一個結果,則第一個結果的 CTR 為 30 / 100 * 100 = 30%。
這意味著從每 100 次搜索中,您可以獲得 30% 的搜索。 請務必記住,Google Search Console (GSC) 中的展示次數並非基於您的網站鏈接在搜索者視口中的外觀。 如果結果出現在搜索者 SERP 上,則每次搜索都會獲得一次展示。
CTR曲線的用途是什麼?
搜索引擎優化的重要主題之一是自然流量預測。 為了提高某些關鍵字的排名,我們需要分配成千上萬的美元來獲得更多的份額。 但公司營銷層面的問題通常是:“我們分配這筆預算是否具有成本效益?”。
此外,除了 SEO 項目的預算分配主題外,我們還需要估計我們未來的自然流量增加或減少。 例如,如果我們看到我們的一個競爭對手試圖在我們的 SERP 排名位置上取代我們,這將花費我們多少錢?
在這種情況或許多其他情況下,我們需要我們網站的 CTR 曲線。
為什麼我們不使用 CTR 曲線研究並使用我們的數據?
簡單地說,在 SERP 中沒有任何其他網站具有您的網站特徵。
不同行業和不同 SERP 功能的 CTR 曲線有很多研究,但是當您有數據時,為什麼您的網站不計算 CTR 而不是依賴第三方來源?
讓我們開始這樣做吧。
使用 Python 計算 CTR 曲線:入門
在深入了解Google基於位置的點擊率計算過程之前,您需要了解基本的Python語法,並對常見的Python庫(如Pandas)有基本的了解。 這將幫助您更好地理解代碼並以您的方式對其進行自定義。
此外,對於這個過程,我更喜歡使用 Jupyter notebook 。
為了根據位置計算有機點擊率,我們需要使用這些 Python 庫:
- 熊貓
- 情節
- 萬花筒
此外,我們將使用這些 Python 標準庫:
- 操作系統
- json
正如我所說,我們將探索兩種不同的計算 CTR 曲線的方法。 兩種方法的一些步驟是相同的:導入 Python 包、創建繪圖圖像輸出文件夾和設置輸出繪圖大小。
# 為我們的流程導入所需的庫 導入操作系統 導入json 將熊貓導入為 pd 將 plotly.express 導入為 px 將 plotly.io 導入為 pio 進口萬花筒
在這裡,我們創建一個輸出文件夾來保存我們的繪圖圖像。
# 創建繪圖圖像輸出文件夾
如果不是 os.path.exists('./output plot images'):
os.mkdir('./輸出繪圖圖像')
您可以更改下面輸出繪圖圖像的高度和寬度。
# 設置輸出繪圖圖像的寬度和高度 pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
讓我們從第一種基於查詢 CTR 的方法開始。
第一種方法:根據查詢CTR計算整個網站或特定URL屬性的CTR曲線
首先,我們需要獲取所有查詢及其點擊率、平均排名和展示次數。 我更喜歡使用過去一個月的一整月數據。
為此,我從 Google Data Studio 中的 GSC 網站印像數據源獲取查詢數據。 或者,您可以以任何您喜歡的方式獲取此數據,例如 GSC API 或“搜索表格分析”Google 表格插件。 這樣,如果您的博客或產品頁面具有專用的 URL 屬性,您可以將它們用作 GDS 中的數據源。
1. 從 Google Data Studio (GDS) 獲取查詢數據
去做這個:
- 創建報告並向其中添加表格圖表
- 將您的網站“網站印象”數據源添加到報告中
- 維度選擇“query”,metric選擇“ctr”、“average position”和“'impression”
- 通過創建過濾器過濾掉包含品牌名稱的查詢(包含品牌的查詢會有更高的點擊率,這會降低我們數據的準確性)
- 右鍵單擊表,然後單擊導出
- 將輸出另存為 CSV
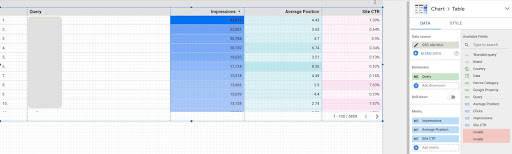
2. 加載我們的數據並根據它們的位置標記查詢
為了操作下載的 CSV,我們將使用 Pandas。
我們項目文件夾結構的最佳實踐是有一個“數據”文件夾,我們在其中保存所有數據。
在這裡,為了教程的流暢性,我沒有這樣做。
query_df = pd.read_csv('./downloaded_data.csv')
然後我們根據查詢的位置標記查詢。 我創建了一個“for”循環來標記位置 1 到 10。
例如,如果查詢的平均位置是 2.2 或 2.9,它將被標記為“2”。 通過操縱平均位置範圍,您可以達到您想要的精度。
對於範圍內的 i (1, 11):
query_df.loc[(query_df['平均位置'] >= i) & (
query_df['平均位置'] < i + 1), '位置標籤'] = i
現在,我們將根據查詢的位置對查詢進行分組。 這有助於我們在接下來的步驟中以更好的方式操作每個位置查詢數據。
query_grouped_df = query_df.groupby(['位置標籤'])
3. 根據數據過濾查詢以進行 CTR 曲線計算
計算 CTR 曲線的最簡單方法是使用所有查詢數據並進行計算。 然而; 不要忘記考慮那些在您的數據中位置 2 有一次展示的查詢。
根據我的經驗,這些查詢會對最終結果產生很大影響。 但最好的方法是自己嘗試。 根據數據集,這可能會改變。
在我們開始這一步之前,我們需要為我們的條形圖輸出創建一個列表,並為存儲我們操作的查詢創建一個 DataFrame。
# 創建一個 DataFrame 用於存儲 'query_df' 操作數據 modified_df = pd.DataFrame() # 為我們的條形圖保存每個位置平均值的列表 mean_ctr_list = []
然後,我們遍歷query_grouped_df組,並將基於展示次數的前 20% 查詢附加到modified_df數據幀。
如果僅根據展示次數最多的前 20% 的查詢計算 CTR 對您來說不是最好的,您可以更改它。
為此,您可以通過操作.quantile(q=your_optimal_number, interpolation='lower')]來增加或減少它,並且your_optimal_number必須介於 0 到 1 之間。
例如,如果您想獲得前 30% 的查詢, your_optimal_num是 1 和 0.3 (0.7) 之間的差值。
對於範圍內的 i (1, 11):
# 一個 try-except 用於處理目錄中某些位置沒有任何數據的情況
嘗試:
tmp_df = query_grouped_df.get_group(i)[query_grouped_df.get_group(i)['impressions'] >= query_grouped_df.get_group(i)['impressions']
.quantile(q=0.8, 插值='lower')]
mean_ctr_list.append(tmp_df['ctr'].mean())
modified_df = modified_df.append(tmp_df, ignore_index=True)
除了 KeyError:
mean_ctr_list.append(0)
# 刪除 'tmp_df' DataFrame 以減少內存使用
刪除 [tmp_df]
4.繪製箱線圖
這一步是我們一直在等待的。 要繪製繪圖,我們可以使用 Matplotlib、seaborn 作為 Matplotlib 的包裝器或 Plotly。
就個人而言,我認為使用 Plotly 最適合喜歡探索數據的營銷人員。
與 Mathplotlib 相比,Plotly 非常易於使用,只需幾行代碼,您就可以繪製出漂亮的繪圖。
# 1. 箱線圖
box_fig = px.box(modified_df, x='位置標籤', y='網站點擊率', title='根據位置查詢點擊率分佈',
points='all', color='position label', labels={'position label': 'Position', 'Site CTR': 'CTR'})
# 顯示所有十個 x 軸刻度
box_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# 將 y 軸刻度格式更改為百分比
box_fig.update_yaxes(tickformat=".0%")
# 將繪圖保存到“輸出繪圖圖像”目錄
box_fig.write_image('./output plot images/Query box plot CTR curve.png')
只需這四行,您就可以獲得漂亮的箱線圖並開始探索您的數據。
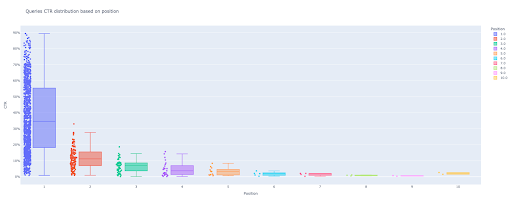
如果要與此列交互,請在新單元格中運行:
box_fig.show()
現在,您在輸出中有一個有吸引力的交互式箱線圖。
當您將鼠標懸停在輸出單元格中的交互式繪圖上時,您感興趣的重要數字是每個位置的“人”。
這顯示了每個位置的平均點擊率。 正如您所記得的,由於平均重要性,我們創建了一個包含每個位置的平均值的列表。 接下來,我們將繼續下一步,根據每個位置的平均值繪製條形圖。
5.繪製條形圖
就像箱線圖一樣,繪製條形圖非常容易。 您可以通過修改px.bar()的title參數來更改圖表的title 。
# 2. 條形圖
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title='查詢基於位置的平均點擊率分佈',
標籤={'x': '位置', 'y': '點擊率'}, text_auto=True)
# 顯示所有十個 x 軸刻度
bar_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# 將 y 軸刻度格式更改為百分比
bar_fig.update_yaxes(tickformat='.0%')
# 將繪圖保存到“輸出繪圖圖像”目錄
bar_fig.write_image('./output plot images/Queries bar plot CTR curve.png')
在輸出中,我們得到這個圖:
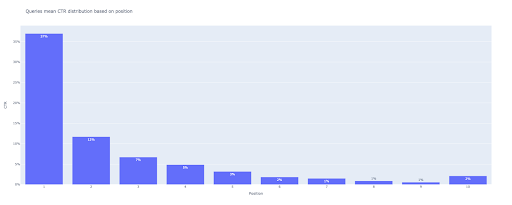
與箱線圖一樣,您可以通過運行bar_fig.show()與此圖進行交互。
而已! 只需幾行代碼,我們就可以根據查詢數據的位置獲得自然點擊率。
如果您的每個子域或目錄都有一個 URL 屬性,則可以獲取這些 URL 屬性查詢併計算它們的 CTR 曲線。
[案例研究] 通過日誌文件分析提高排名、自然訪問量和銷售額
 閱讀案例研究
閱讀案例研究第二種方法:根據每個目錄的著陸頁 URL 計算 CTR 曲線
在第一種方法中,我們根據查詢 CTR 計算了自然 CTR,但使用這種方法,我們獲取了所有著陸頁數據,然後計算我們選擇的目錄的 CTR 曲線。
我喜歡這種方式。 如您所知,我們產品頁面的點擊率與我們的博客文章或其他頁面的點擊率大不相同。 每個目錄都有基於位置的自己的點擊率。
以更高級的方式,您可以對每個目錄頁面進行分類,並根據一組頁面的位置獲得 Google 的自然點擊率。

1.獲取登陸頁面數據
與第一種方法一樣,有多種方法可以獲取 Google Search Console (GSC) 數據。 在這種方法中,我更喜歡從 GSC API Explorer 獲取登錄頁面數據:https://developers.google.com/webmaster-tools/v1/searchanalytics/query。
對於這種方法所需的內容,GDS 不提供可靠的登錄頁面數據。 此外,您可以使用“搜索表格分析”Google 表格插件。
請注意,Google API Explorer 非常適合那些數據頁數少於 25K 的網站。 對於較大的站點,您可以獲取部分登錄頁面數據並將它們連接在一起,編寫帶有“for”循環的 Python 腳本以從 GSC 中獲取所有數據,或使用第三方工具。
要從 Google API Explorer 獲取數據:
- 導航到“搜索分析:查詢”GSC API 文檔頁面:https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- 使用頁面右側的 API Explorer
- 在“siteUrl”字段中,插入您的 URL 屬性地址,例如
https://www.example.com。 此外,您可以按如下方式插入域屬性sc-domain:example.com - 在“請求正文”字段中添加
startDate和endDate。 我更喜歡獲取上個月的數據。 這些值的格式是YYYY-MM-DD - 添加
dimension並將其值設置為page - 創建一個“dimensionFilterGroups”並過濾掉帶有品牌變體名稱的查詢(用您的品牌名稱 RegExp 替換
brand_variation_names) - 添加
rawLimit並將其設置為 25000 - 最後按下“執行”按鈕
您還可以復制並粘貼下面的請求正文:
{
"開始日期": "2022-01-01",
"endDate": "2022-02-01",
“方面”: [
“頁”
],
“維度過濾器組”:[
{
“過濾器”:[
{
“維度”:“查詢”,
"表達式": "brand_variation_names",
“操作員”:“EXCLUDING_REGEX”
}
]
}
],
“行限制”:25000
}
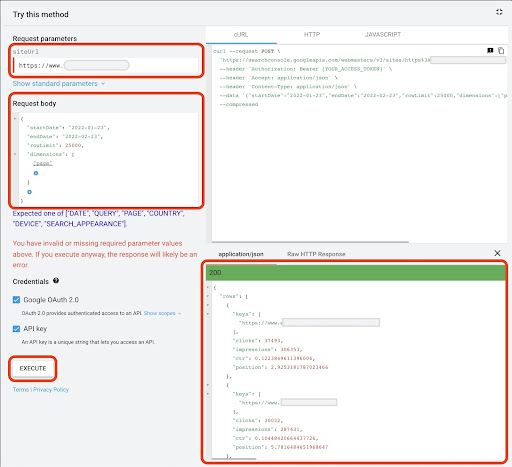
請求執行後,我們需要保存它。 由於響應格式的原因,我們需要創建一個 JSON 文件,複製所有 JSON 響應,並使用downloaded_data.json的_data.json 文件名保存它。
如果您的網站很小,例如 SASS 公司網站,並且您的目標網頁數據少於 1000 頁,您可以輕鬆地在 GSC 中設置日期,並將“PAGES”選項卡的目標網頁數據導出為 CSV 文件。
2.加載登陸頁面數據
在本教程中,我假設您從 Google API Explorer 獲取數據並將其保存在 JSON 文件中。 為了加載這些數據,我們必須運行以下代碼:
# 為下載的數據創建一個DataFrame
使用 open('./downloaded_data.json') 作為 json_file:
著陸數據 = json.loads(json_file.read())['rows']
Landings_df = pd.DataFrame(landings_data)
此外,我們需要更改列名以賦予其更多含義,並應用一個函數直接在“著陸頁”列中獲取著陸頁 URL。
# 將“keys”列重命名為“landing page”列,並將“landing page”列表轉換為 URL
Landings_df.rename(columns={'keys': '登陸頁面'}, inplace=True)
登陸_df['登陸頁'] = 登陸_df['登陸頁'].apply(lambda x: x[0])
3.獲取所有登陸頁面根目錄
首先,我們需要定義我們的站點名稱。
# 在引號之間定義您的站點名稱。 例如,“https://www.example.com/”或“http://mydomain.com/” 站點名稱 = ''
然後我們在登錄頁面 URL 上運行一個函數來獲取它們的根目錄並在輸出中查看它們以選擇它們。
# 獲取每個登陸頁面(URL)目錄
登陸_df['目錄'] = 登陸_df['登陸頁面'].str.extract(pat=f'((?<={site_name})[^/]+)')
# 為了獲取輸出中的所有目錄,我們需要操作 Pandas 選項
pd.set_option("display.max_rows", 無)
# 網站目錄
登陸_df['目錄'].value_counts()
然後,我們選擇需要獲取哪些目錄的點擊率曲線。
將目錄插入important_directories變量中。
例如, product,tag,product-category,mag 。 用逗號分隔目錄值。
重要目錄 = ''
important_directories = important_directories.split(',')
4. 標記和分組登陸頁面
與查詢一樣,我們也根據著陸頁的平均位置標記著陸頁。
# 標記著陸頁位置
對於範圍內的 i (1, 11):
Landings_df.loc[(landings_df['位置'] >= i) & (
Landings_df['位置'] < i + 1), '位置標籤'] = i
然後,我們根據著陸頁的“目錄”對著陸頁進行分組。
# 根據“目錄”值對登錄頁面進行分組 登陸_grouped_df = 登陸_df.groupby(['目錄'])
5. 為我們的目錄生成箱形圖和條形圖
在之前的方法中,我們沒有使用函數來生成繪圖。 然而; 為了自動計算不同著陸頁的點擊率曲線,我們需要定義一個函數。
# 創建和保存每個目錄圖表的功能
def each_dir_plot(dir_df, key):
# 根據“位置標籤”值對目錄登錄頁面進行分組
dir_grouped_df = dir_df.groupby(['位置標籤'])
# 創建一個用於存儲 'dir_grouped_df' 操作數據的 DataFrame
modified_df = pd.DataFrame()
# 為我們的條形圖保存每個位置平均值的列表
mean_ctr_list = []
'''
循環遍歷 'query_grouped_df' 組並將基於展示次數的前 20% 查詢附加到 'modified_df' DataFrame。
如果僅根據展示次數最多的前 20% 的查詢計算 CTR 對您來說不是最好的,您可以更改它。
要更改它,您可以通過操作 '.quantile(q=your_optimal_number, interpolation='lower')]' 來增加或減少它。
“you_optimal_number”必須介於 0 到 1 之間。
例如,如果您想獲得前 30% 的查詢,'your_optimal_num' 是 1 和 0.3 (0.7) 之間的差值。
'''
對於範圍內的 i (1, 11):
# 一個 try-except 用於處理目錄中某些位置沒有任何數據的情況
嘗試:
tmp_df = dir_grouped_df.get_group(i)[dir_grouped_df.get_group(i)['impressions'] >= dir_grouped_df.get_group(i)['impressions']
.quantile(q=0.8, 插值='lower')]
mean_ctr_list.append(tmp_df['ctr'].mean())
modified_df = modified_df.append(tmp_df, ignore_index=True)
除了 KeyError:
mean_ctr_list.append(0)
# 1. 箱線圖
box_fig = px.box(modified_df, x='位置標籤', y='ctr', title=f'{key}目錄CTR分佈基於位置',
points='all', color='position label', labels={'position label': 'Position', 'ctr': 'CTR'})
# 顯示所有十個 x 軸刻度
box_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# 將 y 軸刻度格式更改為百分比
box_fig.update_yaxes(tickformat=".0%")
# 將繪圖保存到“輸出繪圖圖像”目錄
box_fig.write_image(f'./output plot images/{key}目錄-Box plot CTR curve.png')
# 2. 條形圖
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title=f'{key} 目錄基於位置的平均點擊率分佈',
標籤={'x': '位置', 'y': '點擊率'}, text_auto=True)
# 顯示所有十個 x 軸刻度
bar_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# 將 y 軸刻度格式更改為百分比
bar_fig.update_yaxes(tickformat='.0%')
# 將繪圖保存到“輸出繪圖圖像”目錄
bar_fig.write_image(f'./output plot images/{key}目錄-條形圖點擊率曲線.png')
在定義了上述函數之後,我們需要一個“for”循環來遍歷我們想要獲取其 CTR 曲線的目錄數據。
# 遍歷目錄並執行 'each_dir_plot' 函數
對於鍵,landings_grouped_df 中的項目:
如果在重要目錄中鍵入:
each_dir_plot(項目,鍵)
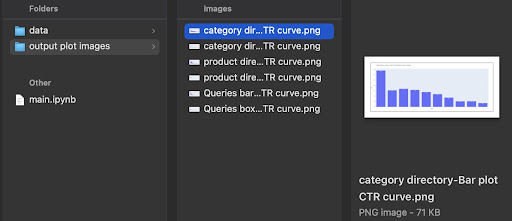
在輸出中,我們在output plot images文件夾中獲取繪圖。
進階提示!
您還可以使用查詢登錄頁面計算不同目錄的 CTR 曲線。 通過對功能進行一些更改,您可以根據其登錄頁面目錄對查詢進行分組。
您可以使用下面的請求正文在 API Explorer 中發出 API 請求(不要忘記 25000 行限制):
{
"開始日期": "2022-01-01",
"endDate": "2022-02-01",
“方面”: [
“詢問”,
“頁”
],
“維度過濾器組”:[
{
“過濾器”:[
{
“維度”:“查詢”,
"表達式": "brand_variation_names",
“操作員”:“EXCLUDING_REGEX”
}
]
}
],
“行限制”:25000
}
使用 Python 自定義 CTR 曲線計算的技巧
為了獲得更準確的數據來計算 CTR 曲線,我們需要使用第三方工具。
例如,除了知道哪些查詢具有特色片段外,您還可以探索更多 SERP 功能。 此外,如果您使用第三方工具,您可以根據 SERP 功能獲取具有該查詢的著陸頁排名的查詢對。
然後,使用其根(父)目錄標記登錄頁面,根據目錄值對查詢進行分組,考慮 SERP 功能,最後根據位置對查詢進行分組。 對於 CTR 數據,您可以將 GSC 中的 CTR 值合併到其對等查詢中。