
語義網絡對 SEO 的重要性:使用查詢和文檔模板創建語義內容網絡 - 案例研究
已發表: 2022-01-11語義網絡與知識庫的概念相關聯,該知識庫可以表示具有關係連接的事物的真實世界信息。 一個知識庫可以有數千種關係類型,涉及數十億個實體和數万億個事實。 語義網絡可以從具有諸如重量、大小、類型、氣味或顏色等相互特徵的任何現實世界中創建。 語義網絡和語義網之間的關係是由語義搜索引擎和優化創建的。
語義網絡用於語義解析、詞義消歧、WordNet 創建、圖論、自然語言處理、理解和生成。 通過提供語義內容網絡,語義網絡的觀點可以在語義搜索引擎優化中使用。
在這個 SEO 案例研究中,將基於 Query、Document、Intent 模板和它們背後的實體屬性對來解釋兩個不同的網站,使用兩種不同的方法,具有相同的視角。
通過了解搜索引擎如何表示知識以及它們如何擴展其知識表示,我能夠利用它來產生令人難以置信的排名結果。 了解基本概念後,我將解釋我如何將它們應用於兩個不同的網站,然後我將詳細介紹我使用的方法。
語義網絡如何幫助您的網站排名?
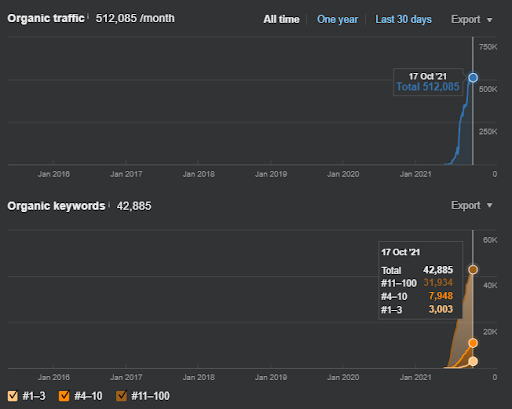
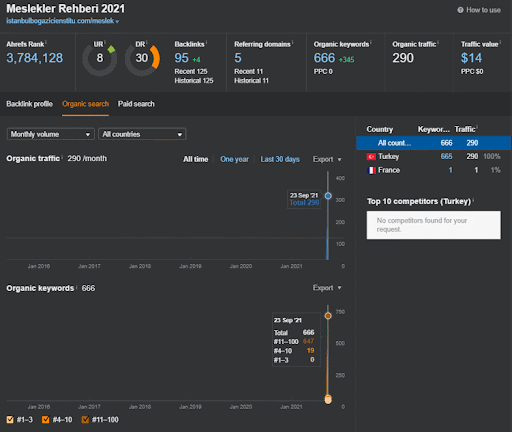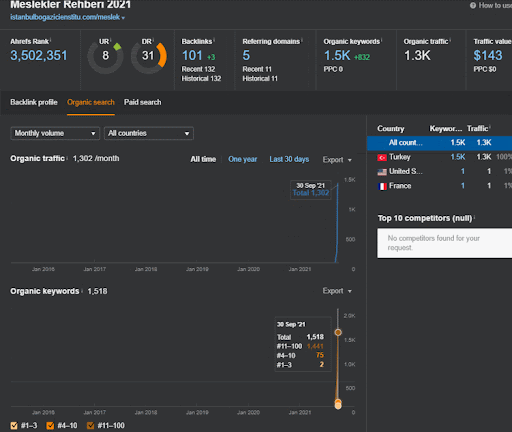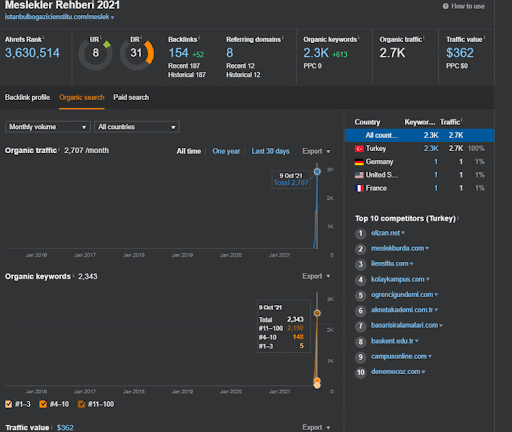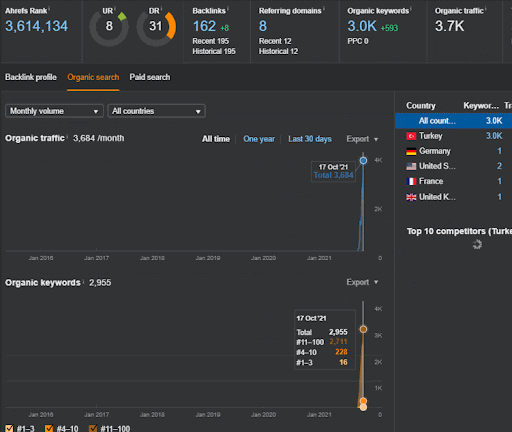
下面,您將找到項目 I 的整體原始結果。
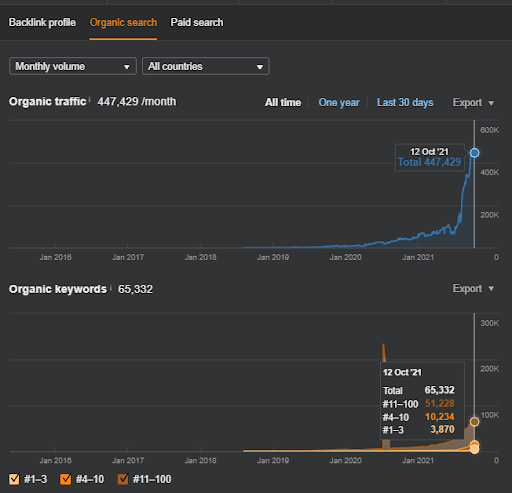
項目一的結果是 IstanbulBogaziciEnstitu.com。 為了證明“語義網絡”可以用於帶有查詢和文檔模板的 SEO,我將演示來自 Project One 的兩個不同的內容網絡。 由於語義內容網絡二,項目一將在不久的將來取得更好的結果。 客戶端將負責推出第二個網絡,但我也會解釋它的邏輯。
17 天后,項目 I 的進展如下: 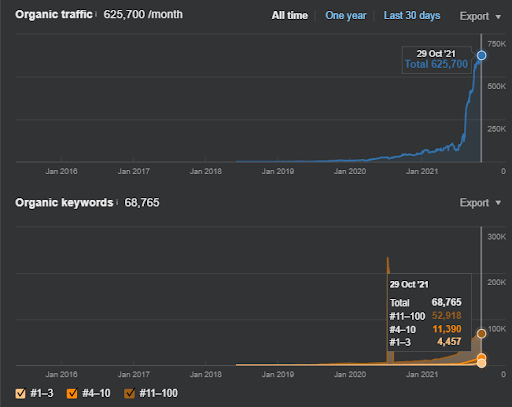
17天后,語義內容網絡的重新排名過程更加清晰。
語義內容網絡概念幫助我們理解查詢、搜索意圖、行為和文檔模闆對來自同一類型的實體的價值。 在這個以語義網絡為重點的 SEO 案例研究中,之前的主題權威和語義 SEO 案例研究將通過兩個使用圍繞相同實體類型的語義創建的內容網絡的新網站進行深化。
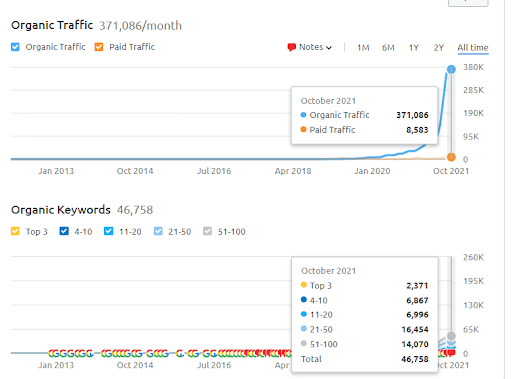
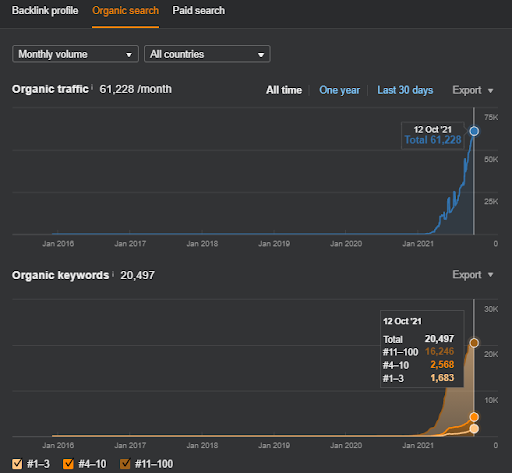
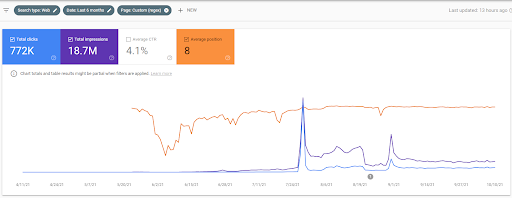
這是第一個項目的 SEMRush 圖形。 還必須提一下,這個網站已經失去了六月廣泛的核心算法更新,如果它不失去它的“Rankability”,結果會更好。 下一次廣泛的核心算法更新,擁有更好的話題權威性、覆蓋率和歷史數據,可以輕鬆恢復“Rankability”。
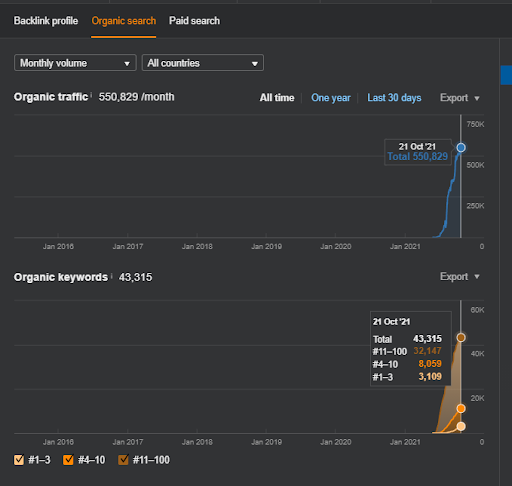
第二個項目的名稱是 Vizem.net。 與 Project One 不同的是,您可以看到 Vizem.net 的增長緩慢但穩定。 這是因為他們使用的語義內容網絡的觀點略有不同。 下面,您可以看到第二個項目的 Ahrefs 結果。
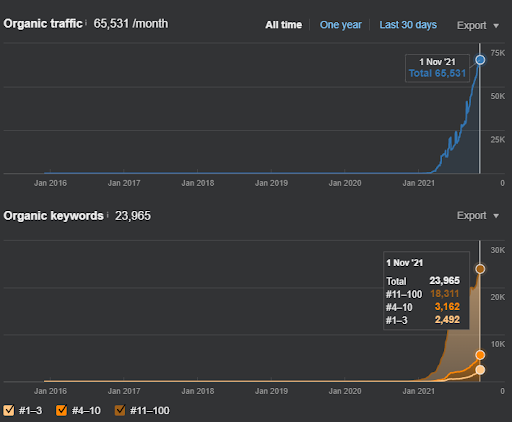
第二個項目的結果代表了一個“緩慢的重新排序過程”,逐漸提高了主題覆蓋率和權威性。 術語“重新排名”和“初始排名”將在與語義內容網絡相關的概念之後進行解釋。 如果您意識到圖形內部的“穩定性”,那是因為我已經停止在源中發布新內容。 而且,它會影響重新排名過程,正如您從前 3 個查詢計數的計數中所意識到的那樣。 “Momentum”和“Re-ranking”關係可以在基本概念的解釋之後找到。
下面,您可以找到 Vizem.net 的 SEMRush 結果。
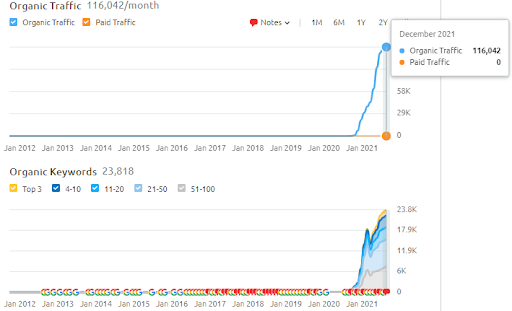
該網站的實際流量是 SEMRush 中所述數字的 3 倍。 您也可以在這些圖中實現相同的“穩定性”和“動量”概念。
在撰寫主題權威 SEO 案例研究時,我感謝 Bill Slawski 教育了我的觀點。 我也在語義內容網絡 SEO 案例研究中重複一遍。 要理解“重新排名”和“初始排名”的概念,應該閱讀“搜索引擎可能重新排名搜索結果的方式”。
2021 年 3 月 18 日,Oncrawl、RankSense 和 Holistic SEO & Digital 發布了 Python SEO 和數據科學網絡研討會。 在網絡研討會中,已記錄 SERP 以動畫化結果差異。 可以看出,搜索引擎會以相似的頻率改變某些來源的排名。
在我繼續之前,我知道這是一篇很長的文章。 但是,實際上這是對高度複雜的 SEO 方法的簡要說明。 語義內容網絡在設計時需要太多的思考,需要對客戶、作者進行數月的教育,以及入職培訓。 因此,在本文中,我想重點介紹具有最佳可執行簡要建議和重要 Google 以及其他搜索引擎專利、研究論文的概念的定義以及它們自己的概念。 在長版(基本上是一本書)中,我專注於語義內容網絡的“初始排名”和“重新排名”。
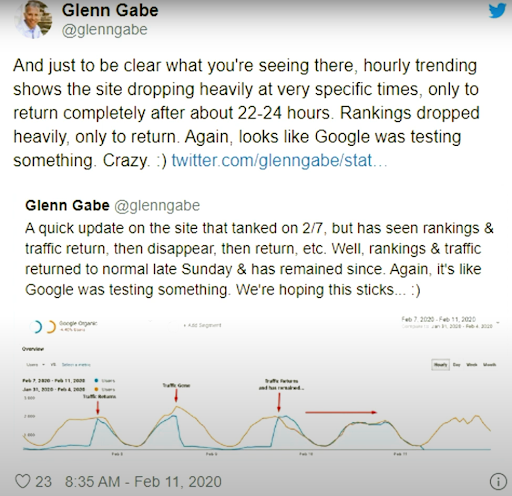
從 2020 年 2 月 11 日起,Glenn Gabe 為搜索引擎視覺上的重新排名和測試方法提供了一個很好的例子。
如果您想了解更多信息,請閱讀“初始排名和重新排名對 SEO 的重要性”。
為了深入研究 SEO 案例研究的真實數據,理解語義內容網絡的概念應該從搜索引擎理解 - 通信的角度來處理。
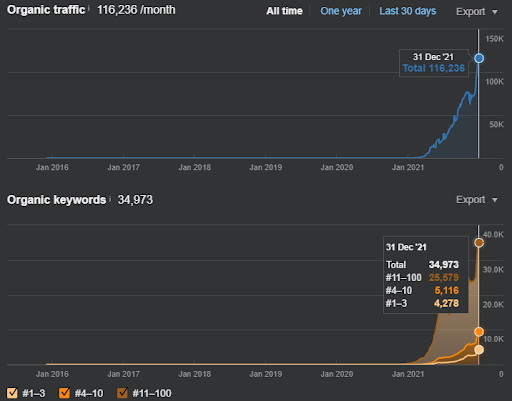
作為 Vizem.net 的重新排名示例,更新的情況可以在上面看到。 在 SEO 案例研究的未來部分中,將會有更多關於 Google 用於 SEO 的 Re-ranking Algorithms 的解釋。
什麼是語義網絡?
語義網絡可用於連接和分析物聯網。 它有助於識別技術市場中的潛在買家,或者僅用於關鍵字網絡創建和聚類的共詞分析。 語義網絡可用於支持導航和揭示關係結構,或一件事對另一件事的相對重要性。 語義網絡具有以下組件:
- 詞彙語義:了解哪些詞和概念與哪些其他詞和概念相關聯,有什麼區別。
- 結構組件:通過什麼信息了解哪個節點連接到哪個邊。
- 語義成分:事實的定義。
- 程序部分:有助於在組件之間建立進一步的連接。
由於語義網絡是多用途的,NLP 算法也可以用於非常多樣化的目的,例如幫助識別複雜的健康問題。 相同的語義網絡結構可以在多個其他區域中實現,只要這些其他區域之間具有語義關係即可。
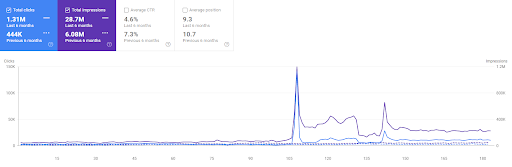
第一個項目最近 6 個月的比較。
什麼是知識庫?
知識庫是具有機器可讀形式分類的信息庫。 知識庫可以用作百科全書,可以根據查詢進行縮小和深化。 基於命題、事實抽取和信息抽取可以形成知識庫。 語義網絡和知識庫之間的關係是語義網絡中的所有內容在提取事實的同時都會放入知識庫中。
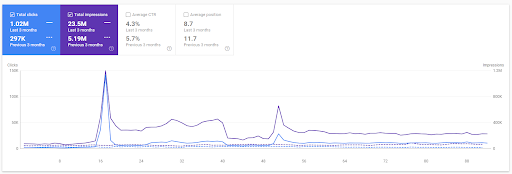
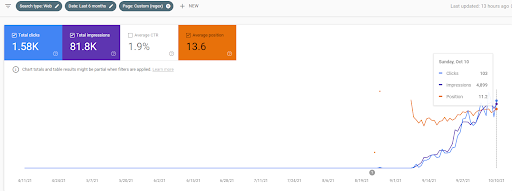
第一個項目最近3個月的比較
什麼是語義內容網絡?
語義內容網絡表示基於語義網絡組件和理解準備的內容網絡。 語義內容網絡可以包括來自同一組的一個或多個實體的多個屬性,以便為知識庫提供更詳細的信息。
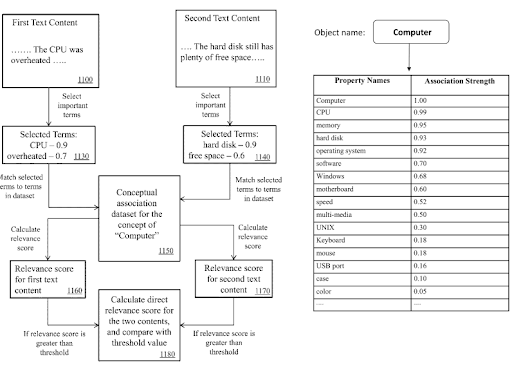
在語義內容網絡中,知識域術語和三元組可用於表示文檔的主要目的和可能的鄰域內容片段。
搜索引擎可以將其自己的知識庫與可以從網站內容生成的知識庫進行比較。 如果網站對不同的上下文層具有較高的準確性和全面性,搜索引擎可以從網站的內容中改進自己的知識庫。 如果搜索引擎從開放網絡上的另一個來源改進和擴展了自己的知識庫,這就是高水平的基於知識的信任的信號。
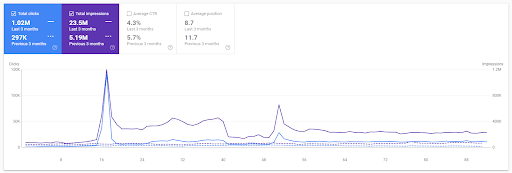
基於第一個項目的最近 3 個月的同比比較。
什麼是基於知識的信任?
基於知識的信任側重於基於“信息準確性”而不是“PageRank”的開放網絡。 它是一種類似於 RankMerge 的算法。 基於知識的信任包括三元組、事實提取、準確性檢查和通過消除文本歧義來理解文本。 基於不同但相關的上下文層,可以通過提供在文章中具有強連接組件的語義內容網絡來獲得基於知識的信任。
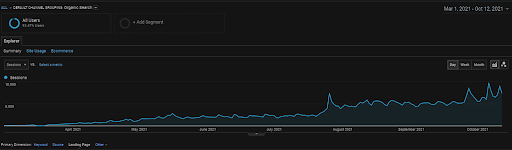
過去 6 個月來自 GA 的 Vizem.net 有機會議。
下面,您將看到 Luna Dong 的基於知識的信任演示的示例。 它顯示了搜索引擎如何專注於“內部排名因素”而不是外部排名因素。 它解釋說,高 PageRank 本身並不能代表內容的高質量和準確性。 因此,擁有 KBT(基於知識的信任)很重要。
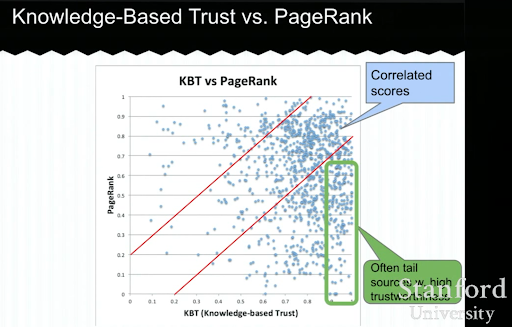
非常感謝 Arnout Hellemans 在私人 SEO 聊天期間與我分享了這次教育講座。 如果您想了解更多關於基於知識的信任:斯坦福研討會 - 知識庫和基於知識的信任
什麼是上下文覆蓋?
Contextual Coverage 和 Topical Coverage 不一樣,Knowledge Domain 和 Contextual Domain 不一樣。 上下文覆蓋表示概念的處理角度。 一個概念可以根據它與其他事物的相互點來處理。 例如,如果實體是一個國家,則可以處理其對環境危機的立場。 如果從同樣的角度處理其他國家,這意味著我們正在覆蓋一個上下文域。

谷歌搜索引擎隨著時間的推移建立其研究論文和專利。 上節的右引號是“上下文向量”的屬性,而左節是“短語分類”的屬性。 有趣的是,連例子都一樣,都是“數碼相機”。
這些組合的深化細節和子部分代表了上下文域中的上下文層。 每個實體,無論它是否被命名,都有許多上下文域。 因此,谷歌提取了更多的上下文域,用戶每年搜索更長的查詢。 當開發自然語言處理和自然語言理解時,查詢和文檔在細節和上下文方面一起擴展。
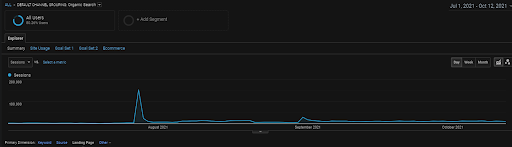
BogaziciEnstitu 項目過去 4 個月的 GA 有機會議圖形。 由於項目的“歷史數據獲取階段”,增加的細節並不清楚被視為線性。
上下文覆蓋可以通過“上下文限定符”來理解。 上下文限定詞可以是形容詞、副詞或任何其他介詞,例如以“for、in、at、 during、while”開頭的短語。 以下與實體相關的問題在上下文域方面並不相同:
- 對失眠的孩子最有用的水果是什麼?
- 對患有焦慮症的孩子最有用的水果是什麼?
以下與實體相關的問題在上下文層方面並不相同:
- 6歲以上嚴重失眠的孩子吃什麼水果最有用?
- 6歲以下低水平焦慮的孩子吃什麼水果最有用?
以下與實體相關的問題在知識領域方面並不相同:
- 對6歲以上嚴重失眠的孩子最有用的書是什麼?
- 對 6 歲以下低水平焦慮的孩子最有用的遊戲是什麼?
但是所有這些問題都可以在同一個語義內容網絡中,因為它們都是關於相同的“概念”和具有相似搜索活動的“興趣區域”,以及與搜索相關的現實世界活動。
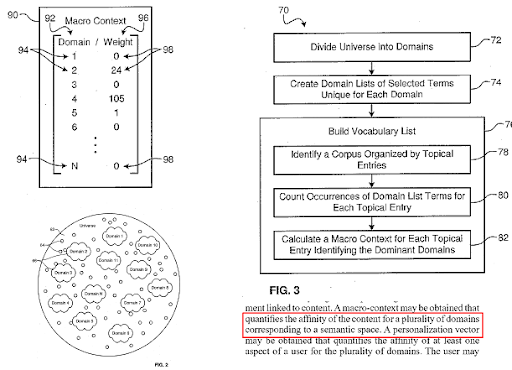
搜索引擎將網絡劃分為不同的知識域,同時計算源、網頁和網頁部分的宏觀和微觀上下文得分。
我知道我對你有很多新概念,由於這是本文的簡短版本,我無法在這裡談論所有內容,但在未來的語義 SEO 課程中,我將處理這些事情,例如“搜索活動”和“搜索相關的真實世界活動”之間的區別。
讓我們繼續討論更具體的事情。
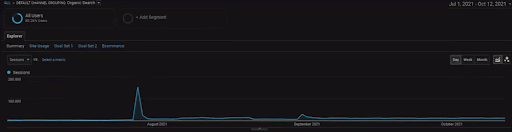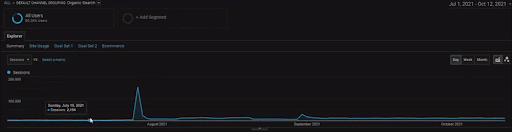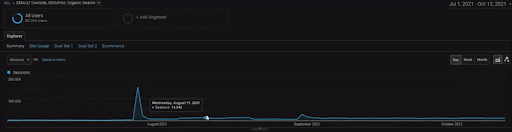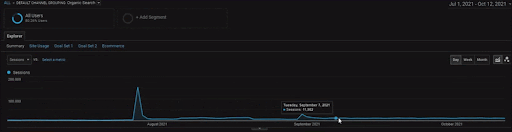
要顯示 BogaziciEnstitu 項目的詳細信息,您可以查看交互式圖像版本。 在歷史數據源事件之後,該項目對搜索引擎的測試和重新排名過程更加清晰。
MuM 與語義內容網絡有什麼關係?
使用統一轉換器或多任務統一模型進行多任務學習訓練語言模型來評估視覺輸入以及文本。 它能夠在理解的同時生成文本。 此外,MuM 與語言無關,換句話說,語義 SEO 取決於語言技能,但不限於語言。 由於實體沒有語言並且含義是通用的,因此 MuM 將來自多種語言和多種上下文的信息利用到一個單一的知識庫中。
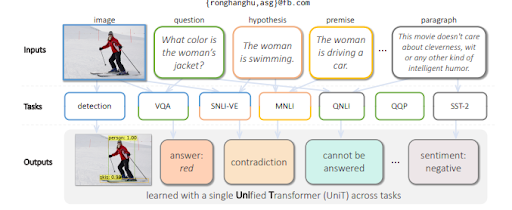
為了從視覺中回答問題,MuM 根據圖像中檢測到的對像生成問題。 在不久的將來,也將能夠生成與音頻和視頻相關的問題。
MuM 使用不同的域進行對象檢測和自然語言理解,並帶有一個轉換器編碼器-解碼器結構。 每個輸入都來自開放網絡的不同區域,而所有輸入都由單個共享解碼器進行評估。 下面,您將能夠從研究論文中看到更多示例。
需要注意的是,MuM 可以比 BERT 強 1000 倍,但 BERT 仍然在 MuM 的文本編碼器中使用。 MuM 的主要優點是它可以直接用於視覺和音頻,這就是為什麼它可以被稱為“多任務”模型的原因。 第二個優點是它直接消除了所有語言障礙。 第三個優點是它能夠將所有東西連接到另一個東西,而不需要額外的中介。 第四個優點是 MuM 也可以生成文本,這與 BERT 不同。
MuM、知識庫、語義網絡和上下文覆蓋之間的聯繫是搜索引擎能夠通過上下文限定符及其與可能的知識域的組合找到更多的上下文域。 因此,由適當的主題圖和源上下文形成的結構良好的語義內容網絡可以與主題權威一起提高知識庫信任度。
源的上下文是什麼?
源的上下文代表兩件事。 來源的中央搜索互聯網,以及可以通過相關搜索活動完成的中央搜索活動。 對於電子商務網站,源上下文是購買特定產品或特定類型的產品。 如果它是一個旅遊網站,則來源的上下文是從另一個地方轉到不同類型的食物、風景或只是商業的地方。 基於源的上下文,語義內容網絡設計和主題地圖將需要進一步配置。 這需要選擇主題圖中的中心部分,以及主題圖中的補充部分。
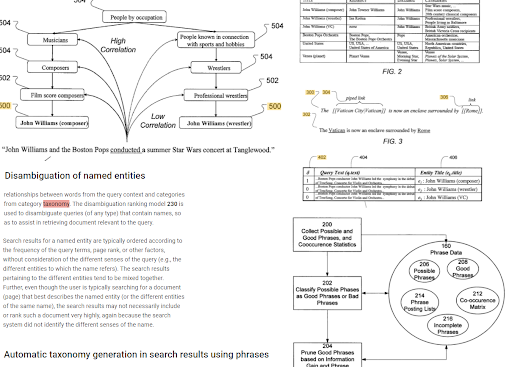
基於短語的索引和麵向實體的搜索理解基於語義相互連接。 上面,可以一起看到“命名實體消歧”和“使用短語在搜索結果中自動生成分類法”以確定“上下文”。 好的短語和主題的獨特但相關的信息將有助於更好的初始和重新排名。
同樣,其中一些概念,“主題圖配置”,“語義內容網絡設計”尚未定義,這不是合適的地方。 但是,相關搜索活動已與規範搜索意圖以及這些規範搜索意圖的代表性短語一起進行了解釋。
以語義網絡為重點的 SEO 案例研究的背景
基於上述概念,我使用語義網絡創建了一個 SEO 案例研究。 我們將查看我在本文開頭提到的兩個網站項目並檢查結果,以及我如何實施語義網絡來生成它們。
為了讓您了解這些網絡的強大程度,下面列出了以語義網絡為重點的 SEO 案例研究的 SEO 相關結果。
- 語義網絡理解是創建適當主題圖的必要條件。
- 對於這兩個項目,沒有使用技術 SEO 來隔離語義 SEO 的影響。
- 出於同樣的原因,不使用頁面速度優化。
- 不使用設計和 WUX(網站用戶體驗)優化。
- 不使用反向鏈接(外部參考和 PageRank 流)。
- 這兩個品牌都沒有歷史數據。 Vizem.net 是全新的,BogaziciEnstitusu 的歷史更悠久,但低於實際公司。
- 不使用 OnPage SEO 或其他垂直領域的 SEO。
- 這兩個品牌的服務器都比之前的主題權威案例研究示例更好。
這個以語義網絡為中心的 SEO 案例研究將幫助那些希望通過兩種不同的方法和概念來改善語義 SEO 視角的人,這些方法和概念專注於兩個不同的網站。
項目二:Vizem.net 專注於簽證申請流程。 在編寫、發布甚至啟動這些項目之前,我已經多次向我的其他客戶或合作夥伴展示這兩個網站。 而且,Vizem.net 最近開始了其“主題權威”之旅。
基於語義網絡案例研究的 SEO已經編寫了兩個不同的版本。 如果您想閱讀所有相關專利、研究論文和深入詳細的檢查、從搜索引擎的角度進行的解釋,同時進一步了解搜索引擎的決策樹,您可以閱讀 Initial-ranking and Re-ranking SEO 的重要性超過 30.000 字的案例研究文章。 如果你對SEO沒有足夠的理論知識和歷史背景,可以繼續閱讀執行摘要。
下面,您可以看到 SEMRush 的第二個項目 (Vizem.net) 圖形。
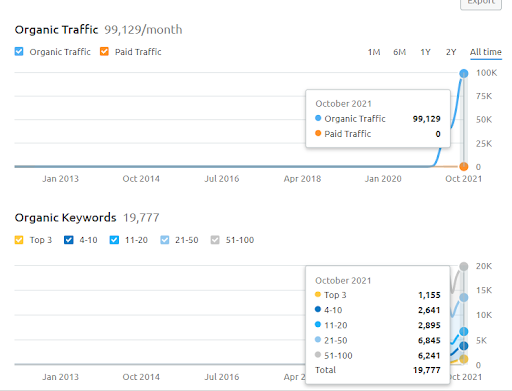
第二個網站的 SEMRush 圖形。 Vizem.net 是一個全新的來源,針對具有高度根深蒂固的競爭對手的行業,例如“簽證申請”。 特別是,由於土耳其的最新事件,該行業的競爭水平正在增加。 因此,使用語義網絡視角來創建內容網絡是很有用的。
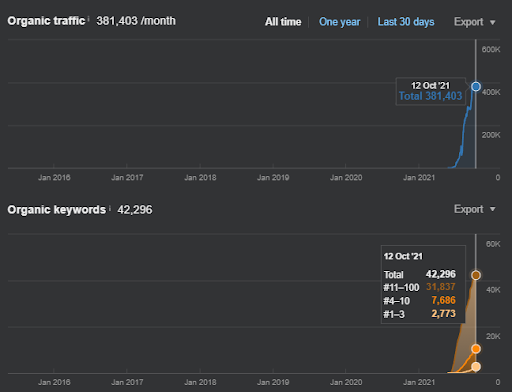
第一個項目:Istanbul Bogazici Enstitusu:3 個月內有機點擊增加 600%——利用歷史數據和初始排名
IstanbulBogazici Enstitusu 是我執行過的最難的 SEO 案例研究之一,不是因為搜索引擎,而是因為人和我的健康問題。 因此,我離開了項目,沒有發布第三個語義內容網絡,它旨在完成基於源上下文的語義關係。 即使它沒有知識領域術語和正確實施的上下文短語,它也配置了足夠水平的語義連接和準確性,如果第三個內容網絡是,則可以實現每月超過 300 萬次會話的整體有機搜索性能未來發布,也說明了第二語義內容網絡的影響越來越大。
下面,您將看到過去 12 個月在 GSC 上的 IstanbulBogazici Enstitusu 不斷變化的圖形。 該項目於 2021 年 5 月以適當的方式啟動,並通過發布兩個語義內容網絡於 2021 年 9 月結束。
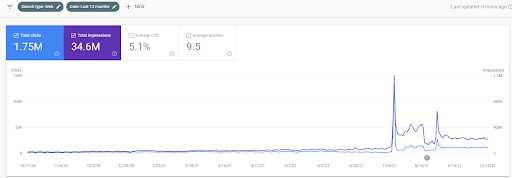
下面你可以看到更詳細的版本。 從每天 1400 次點擊到 140000 次點擊,然後在自然搜索性能中可以看到每天 10.000 次以上的常規點擊
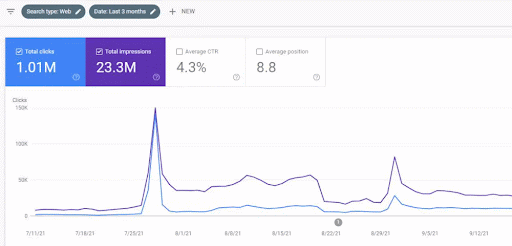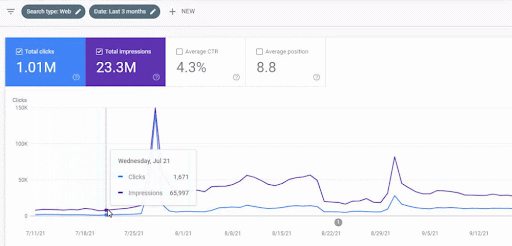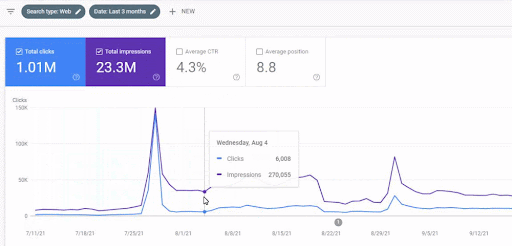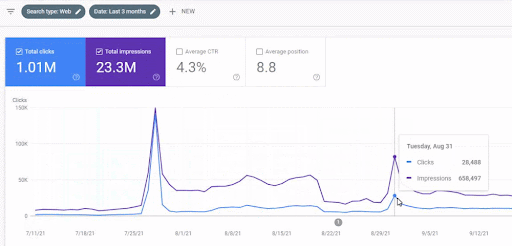
首個內容網絡上線後的流量增長見下圖。
此屏幕截圖顯示了第一個語義內容網絡的第 4 個月。
從圖中可以看出,整個網站的整體流量一直受到專注於“教育分支”的第一語義內容網絡的主導和影響。 我通過這個網站啟動的第二個內容網絡可以在下面的 Google Search Console 中看到。 下面的截圖來自第二語義內容網絡的第 16 天。
文章中使用了初始排名和重新排名,因為它們在測試源之前定義了排名算法的階段及其類型和目的,並在 SERP 中定義了來自源的網頁,用於更重要的流行查詢.
第一個項目的第一個語義內容網絡專注於什麼?
“語義內容網絡”使用知識庫中的語義網絡來解釋知識庫內事物之間的主要、次要和三次關係。 因此,創建語義內容網絡需要基於源上下文設計下一個語義內容網絡,這是網站的主要功能。 在這種情況下,第一個語義內容網絡專注於“大學部門、教育分支以及特定組織和分支內大學教育的必需品”。
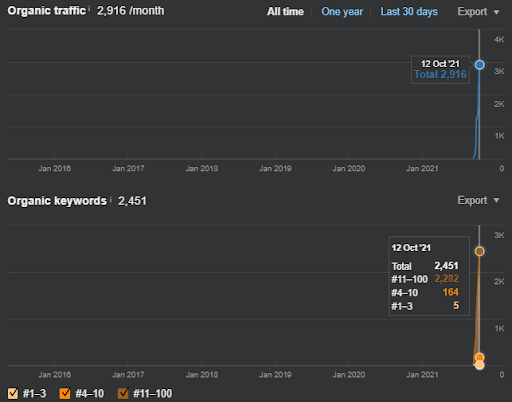
下面,您將找到 First Semantic Content Network 的 Ahrefs 圖形。
這是上一個屏幕截圖的五天后。
“根:istanbulbogazinstitu.com/bolum”,在第一個初始排名階段之後,重新排名過程更加高效和富有成效。
您可以看到以下四天后的版本,以支持“重新排名”的性質。
第一個項目的第二個語義內容網絡專注於什麼?
第二個語義內容網絡側重於職業、工作、技能以及這些技能或常規的必要教育。 基於第一語義內容網絡,已經支持第二語義內容網絡。 並且,根據“查詢模板-意圖模板”,創建了另外兩個不同的語義子內容網絡,並放置在“關係連接”中,同時連接到上層相似的層級。
我知道這些部分對您來說很複雜,因為您還沒有看到以下內容的定義。
- 語義內容網絡
- 源上下文
- 語義子內容網絡
- 知識庫
- 關係連接
- 初始排名
- 重新排名
- 上下文覆蓋
- 比較排名
- 事實提取
在解釋了第二個網站之後,這些概念和句子就會更容易理解。
Vizem.net:6 個月內每天從 0 到 9.000 次以上的每日點擊次數——利用上下文覆蓋率進行比較排名
您可以查看過去 12 個月的 Vizem.net 圖表。 對於這個項目,由於 Covid-19,我們遇到了很多經濟問題,因為投資者來自健身房行業。 因此,我可以看出經濟問題減緩了項目的速度,並導致“重新排序過程”出現一些延遲。
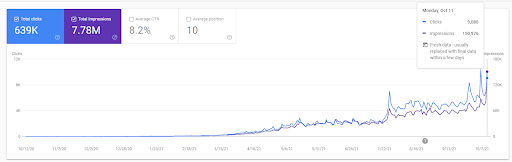
要了解初始排名並進一步重新排名,您可以使用下圖。
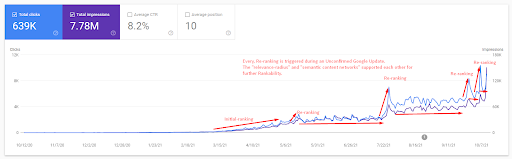
上圖中與初始排名和重新排名相關的一些定義可以在下面找到。
- 在未經證實的谷歌更新期間,排名大幅躍升。 一些測試給出了一些精選片段,人們也提出了問題。
- Google 的一些測試刪除了 FS 和 PAA 收入。
- 每次,兩次重新排名過程之間的時間線都更短。
- 重新排序過程每次都提高了源的 Rankability。
- 源總是在擴展查詢集群的同時提高其相關半徑。
作為一個註釋,我可以在下面留下一句話。
如果搜索引擎索引您的網頁,這並不意味著搜索引擎理解該網頁。 索引的發生比理解更快,而且大多數時候,搜索引擎“最初”對帶有預測的網頁進行排名。 理解之後,就會發生“重新排序”。 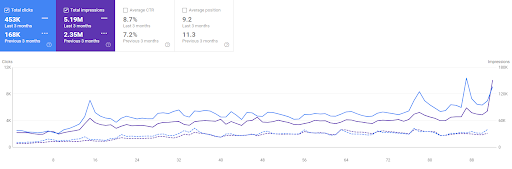
Vizem.net 最近 3 個月的比較
Vizem.net 的語義內容網絡如何?
我記得對於我的許多客戶、朋友或秘密 SEO 小組,在會議期間,我已經通過說“它們會爆炸”來展示這兩個網站。 而且,在寫這篇文章時,我要告訴你:
觀看“istanbulbogazinstitu.com/meslek”語義內容網絡,因為它會爆炸。 而且,您可以找到我在撰寫本文之前發布的視頻,該視頻展示了季節性事件的“歷史數據”及其對初始和重新排名過程的影響。 你可以在下面看到它。
基於此,Vizem.net 的語義內容網絡與 IstanbulBogazici Enstitusu 不相似,因此,我沒有使用“主題覆蓋和歷史數據增加的強度級別”,我需要創建與某些相關的權限這些實體-屬性對的查詢背後的實體類型、它們的屬性和可能的操作。 Vizem.net 不僅有“教育大學分支”,也沒有其中的“職業和在線課程”。 它有“簽證申請國家”。 因此,創建足夠級別的主題權威需要隨著時間的推移與至少 190 個不同的語義內容網絡保持一致。
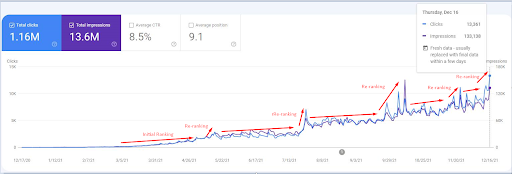
2021 年 12 月 18 日的截圖。可以看到展示次數和點擊次數的持續重新排名和增加。這是上一張截圖的 4 週後。
要查看重新排名事件,您可以比較展示語義 SEO 效果的自然搜索性能圖形的裸版。 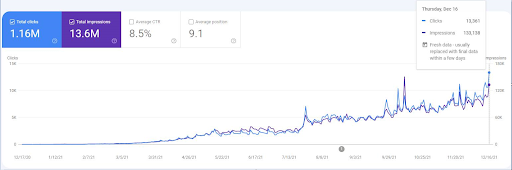
這 190 個不同的語義內容網絡是根據“國家”本身來塑造的,並將國家放在主題地圖的中心,並帶有每個可能的上下文層,以提高搜索活動覆蓋率。
SEMRush 的截圖顯示了他們對 Vizem.net 的看法,與其他行業參與者不同。
我還為 Vizem.net 發布了另一個視頻。 在這個視頻中,網站的最後情況並不存在,因此,我相信它也提供了今天和那天之間的一個很好的比較。
最後,在不相關的文章、網站段或來源中發布不相關的內容會降低 Web 實體與特定知識領域的整體相關性。 Vizem.net 將顯示其真正的價值,未來的 Rankability 會更好。
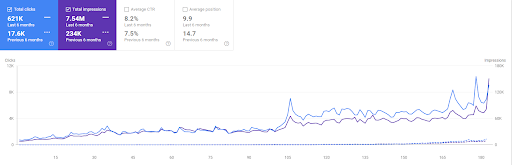
Vizem.net 最近 6 個月的比較。
在我繼續之前,我知道這是一篇很長的文章。 但是,實際上這是對高度複雜的 SEO 方法的簡要說明。 語義內容網絡在設計時需要太多的思考,需要對客戶、作者進行數月的教育,以及入職培訓。 因此,在本文中,我想重點介紹具有最佳可執行簡要建議和重要 Google 以及其他搜索引擎專利、研究論文的概念的定義以及它們自己的概念。 在長版(基本上是一本書)中,我專注於語義內容網絡的“初始排名”和“重新排名”。
如果您想了解更多信息,請閱讀“初始排名和重新排名對 SEO 的重要性”。
到現在為止,我們已經處理了下面的事情。
- 語義網絡
- 知識庫
- 語義內容網絡
- 基於知識的信任
- 上下文覆蓋
- 上下文域和層
- MuM 與語義內容網絡的相關性
- 來源的上下文
這些概念是為了了解語義內容網絡的功能,以及它們如何與主題地圖一起使用。 接下來的部分將是關於搜索引擎如何對語義內容網絡進行排名的最初和後來的修改。 在這種情況下,將處理以下內容。
- 初始排名
- 重新排名
- 查詢模板
- 文件模板
- 搜索意圖模板
- 您應該如何利用語義內容網絡
什麼是 SEO 的初始排名?
這是 SEO 的一個新術語和概念,但對於搜索引擎來說是一個舊術語和概念。 “以語義網絡為中心的 SEO 案例研究”的長版側重於基於查詢依賴、文檔依賴、源依賴算法和多項專利的排名算法。 預測信息檢索或預測排名算法試圖降低計算成本。 而且,即使索引在一天之內完成,理解一份文檔也可能需要幾個月甚至幾年的時間。 因此,計算初始排名是一種在降低成本的同時提高 SERP 質量的方法。 一些與搜索引擎相關的任務比其他任務具有更高的優先級,以保持索引的活躍、新鮮和足夠高的質量。

初始排名一詞出現在數以萬計不同的谷歌專利和研究論文中,因為它是搜索引擎構建者的經典觀點。 因此,在上面,您可以看到具有相同段落延續的不同專利文件,以及圍繞術語初始排名發生微小變化的術語。
初始排名表示文檔在被索引後立即在 SERP 上的排名。 文檔的初始排名代表總體權威,以及源與特定主題、查詢模板和搜索意圖的相關性。 就不同來源之間的初始排名而言,相同的內容可以有不同的排名。 在使用語義內容網絡查看源的整體質量和權限增加時,初始排名很重要。 如果語義內容網絡設計結構正確,每個新文檔都會增加其初始排名,同時減少索引延遲。
初始排名支持重新排名過程及其對源的效率。 並且,“來源的可排名性”應使用初始和重新排名這兩個術語進行處理。
您可以從項目 I 中觀看 Second Content Network 前 20 天的自然績效變化。
在這種情況下,每當 Vizem.net 發布一個新文檔,或者每當 IstanbulBogazici Enstitu 發布一個新的語義內容網絡時,初始排名都會比以前更好,而內容的索引速度更快。
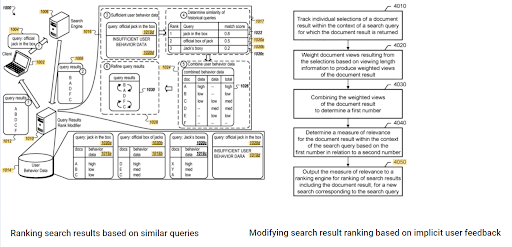
在這兩項互補的谷歌專利之間可以看出初始排名和歷史數據的重要性。 一種是基於隱式用戶反饋的初始文檔和重新排序文檔。 The other one is for doing the same if enough level of user data doesn't exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine's point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document's ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the IstanbulBogazici Enstitu in terms of the initial and re-ranking. 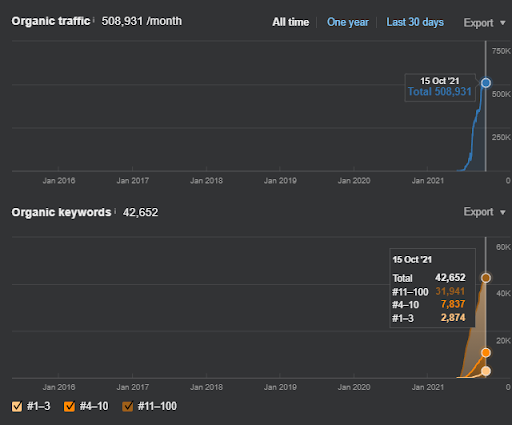
15 October 2021, performance of the first semantic content network of the IstanbulBogaziciEnstitusu which is the 124th day of the launch. 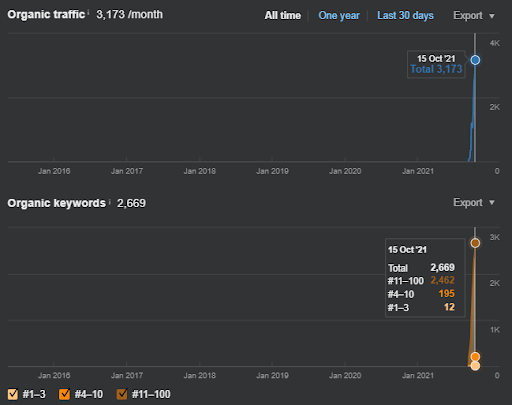
15 October 2021, performance of the Second Semantic Content Network of IstanbulBogazici Enstitu which is the 19th day of the launch. 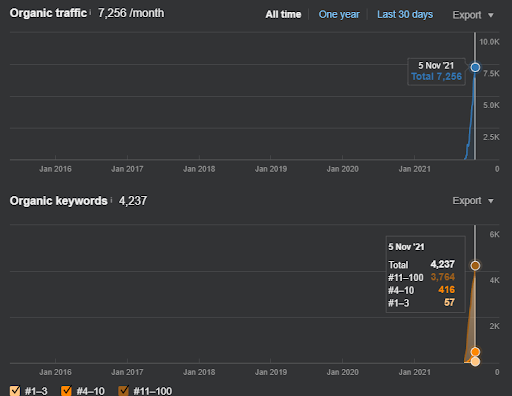
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”. 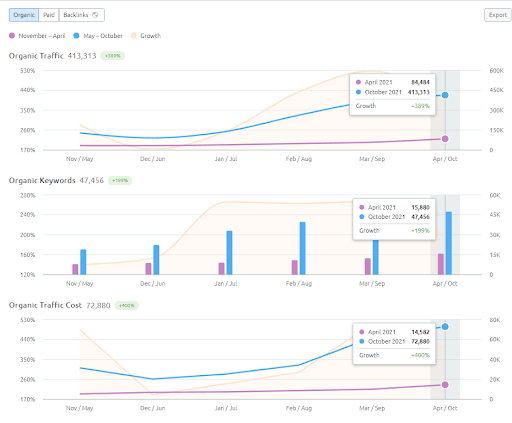
The 6 Months of Growth Comparison of the IstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source's context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction's validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.
In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months' for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.
Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.

The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
抓取數據³
 學到更多
學到更多What is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them. 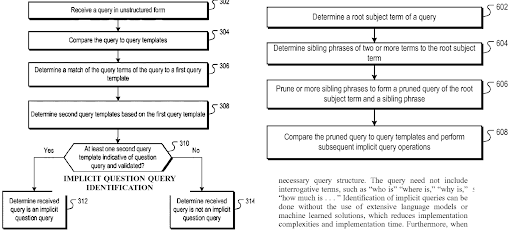
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.
In this context, a query template can be used for feeding the search engines' historical data for creating trust. Even if a search engine doesn't understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas. 
“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it. 
A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian , meaning that they are more influenced by the current page than their history of navigation. 
A section that explains how a search engine can use the document templates to see a user's interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”. 
A section from the “Are web users Markovian?” research paper.
對,他們是。 概率排名和降級相關性排名是語義搜索引擎的主要列,用於了解用戶並創建為可能性狀態準備的最佳可能最高質量的 SERP。 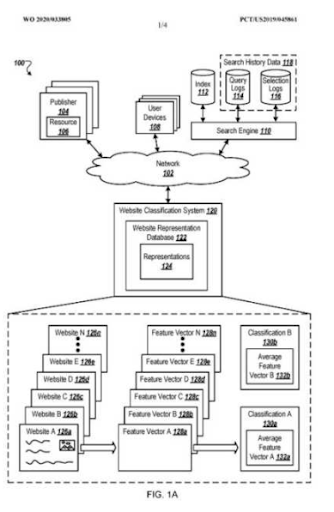
此前,為了讓“網站設計、外觀或色調”成為網站表示學習的一個論據,Bill Slawski 編寫了“網站表示向量”。
什麼是搜索意圖模板?
搜索意圖模板可以由查詢模板背後的需求來表示。 查詢文檔模板可以基於意圖模板進行聯合。 擁有一個具有可能的“降級相關性排名”和“概率排名”理解的搜索意圖模板將有助於創建最佳的搜索活動和具有正確順序的搜索意圖覆蓋。 在創建語義內容網絡時,最重要的是根據源上下文調整document-query-intent模板,通過提高上下文覆蓋率來完成基於知識域的語義網絡,從而提高基於知識的信任度和話題權威性. 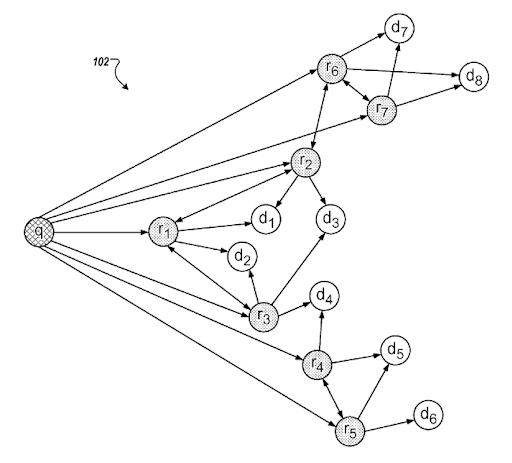
Google 的“Query Refinements based on Inferred Intent”一節。 它通過查詢集群和具有語義連接的意圖模板工作。 您可以在不同的短語分類級別上體驗它。
在繼續討論一些具體示例以及幫助您創建更好的語義內容網絡的建議之前,我必須告訴您,即使是這個 SEO 案例研究的簡單版本也需要高水平的搜索引擎理解和溝通技巧。 因此,即使我覺得我提供了高級信息,但我知道我將創建的語義 SEO 課程將向您展示更多更好的具體示例。 
同一專利解釋了不同“查詢路徑”和“上下文轉換”之間的正確聯繫。
關於利用語義內容網絡,您應該了解什麼?
要創建語義內容網絡,有時即使是簡單的語義內容簡介和設計也可能需要一個小時,如果您根據詞彙語義或實體和短語之間的關係類型放置所有相關細節。 同時使用多個角度,例如基於短語的索引,以及用於計算內容整體與上下文域的上下文相關性或基於各個子內容類型的相關性的詞向量或上下文向量,它需要高水平的語義搜索引擎理解。
因此,使用生成方法將使我在上面向您解釋的概念變得更容易,因為即使您準備好每個語義內容網絡部分,作者和作者也無法編寫它,或者內容管理者將無法遵循您的願景。 因此,在我以足夠生動、可審核的方式證明了這個概念之後,它可能會讓你一無所獲,並讓你像我對其中一些 SEO 案例研究項目所做的那樣離開一個項目。
下面的建議僅適用於對您有幫助的簡單可執行和簡短的步驟。
1. 不要使用來自每個語義內容網絡網絡的固定側邊欄鏈接
每個鏈接都應該有兩個超文本文檔之間的連接描述,就像網頁中的每個單詞一樣。 語義 HTML 使用可以幫助指定文檔在網頁上的位置和功能,同時幫助搜索引擎根據上下文對各個部分進行不同的加權。
在 Vizem.net 示例中,我沒有使用相同的側邊欄設計。 側邊欄沒有顯示最新的帖子或最關鍵的帖子。 側邊欄只顯示中心實體的屬性,它們不是固定的,它們是動態的。 換句話說,基於主題圖中的層次結構,語義內容網絡網絡即使在側邊欄中也會發生變化。 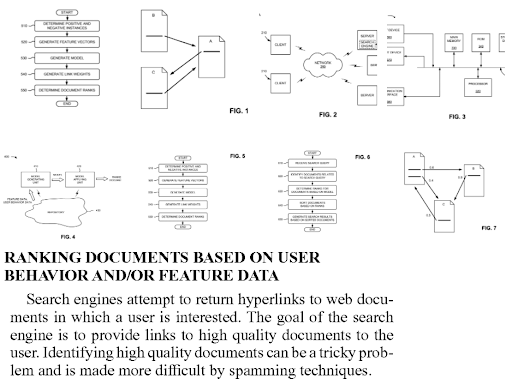
考慮合理的衝浪者和謹慎的衝浪者模型可以幫助 SEO 在不同的超文本文檔之間建立更好的相關性。
此外,鏈接以顯著性為準,流行度應遵循來自最佳可能連接的源上下文。 下面,您可以看到帶有調整後的語義 HTML 代碼的側邊欄部分。 
根據在用戶會話中處於活動狀態的文章的層次結構、選項卡、選項卡的順序、選項卡內的鏈接將發生變化。 上面的示例來自下面的麵包屑層次結構。 ![]()
2. 使用 PageRank 支持語義內容網絡
即使外部PageRank不是必須來自外部來源,如果您能夠使用它,您會意識到初始排名和重新排名會更好。 對於這兩個項目,我都沒有使用它們,但這一次,它不是目的。 對於 Vizem.net,存在經濟問題,我不想將預算花在數字公關和外展上。 對於伊斯坦布爾 BogaziciEnstitusu,我安排了幾個“本地互聯資源”來支持特定主題的資源的真實性,但由於預算和組織紀律問題,該公司再次無法實施。 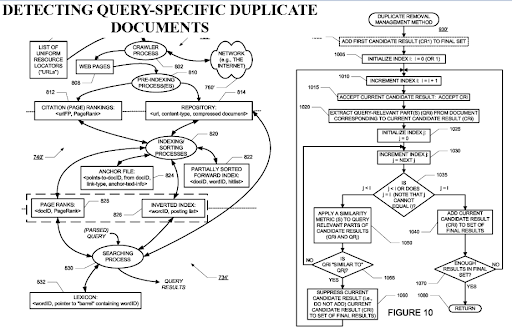
檢測特定於查詢的重複文檔是搜索引擎的一個重要觀點,因為 PageRank 可以幫助將文檔過濾為有價值的文檔,即使它是重複的。 由於高度組織化的語義內容網絡可以彼此相似,因此 PageRank 流和歷史數據很有用。
在為這些類型的語義內容網絡選擇外部 PageRank 流點時,請使用具有歷史數據的源。 就我而言,在我啟動和發布第一個語義內容網絡之前,我已經安排了這些 PageRank 端點。 這樣,我可以從直接競爭對手那裡獲取外部參考,但是當我發布語義內容網絡時,競爭對手放棄了鏈接源,因為他們看到了作為競爭對手的源的大量增加。
這種情況給我們帶來了第三個建議。 如果我們能夠使用來自外部參考的 PageRank 流,重新排名的過程會更快,初始排名也會更高。
3.為突出的語義內容網絡部分使用來自頁腳、頁眉和主要內容的不同錨文本
從搜索引擎的角度來看,錨文本或“鏈接文本”表示超文本文檔與另一個文檔的相關性。 根據PageRank的原始文檔,鏈接數與PageRank流量成正比。 但是,後來谷歌改變了這一點,以防止“鏈接填充”,並限制了實際上可以通過 PageRank 的鏈接。 基於此,開發了 TrustRank、Cautious Surfer、Hilltop Algorithm 或 Reasonable Surfer 模型。 
這是 BogaziciEnstitusu 的兩個不同語義內容網絡的兩個鏈接,但由於我沒有實施技術 SEO 或 UX 改進,您可以意識到按鈕設計的“便宜”。
根據谷歌的說法,同一個鏈接不能第二次將PageRank傳遞給另一個網頁,而PageRank只能從第一個鏈接傳遞。 並且,在PageRank算法的原始形式中,超文本文檔可以鏈接自身以提高其PageRank,或者可以使用301重定向來獲取鏈接目標文檔的PageRank。 這兩種情況都創建了舊的黑帽技術,例如將網頁臨時重定向到另一個網頁,以獲取其 PageRank。 這是從 SEO 能夠從 Google Search Console 或 SERP 查看網頁的 PageRank 的日子開始的。 後來,谷歌開始通過每次重定向來抑制 PageRank,而 Danny Sullivan 解釋說 301 重定向將完全通過 PageRank。 除了所有這些變化之外,重要的是即使第二個鏈接沒有通過 PageRank,它仍然通過了鏈接文本的相關性。 
語義內容網絡的突出部分已根據“中間查詢細化”從主頁鏈接,其中包括“動詞、謂詞”或“搜索者的活動”。
因此,語義內容網絡的突出部分應該從頁眉和頁腳菜單與更高的分類部分鏈接,並且鏈接文本應該彼此不同。 在這些示例中,我使用了帶有突出但短鏈接文本的頁眉鏈接,而我將頁腳示例保留了更長的時間。 
“網絡爬蟲系統中的錨標記索引”的一部分,它總結了錨文本和註釋文本在查詢集群和網頁集群中定位網頁的重要性。
如果語義內容網絡部分過於突出,無法正確傳遞 PageRank 和爬網優先級,我已將最重要的部分與適當的鏈接文本鏈接起來,並且解釋性段落包含具有相關 N-Gram 的不同變體的突出屬性。 
這是 Vizem.net 主頁上的第二個鏈接區域,它位於手風琴後面,重點關注查詢中的國家/地區,並鏈接語義內容網絡的中間部分。
注意:在錨文本周圍,始終使用有計劃的“註釋文本”來提高鏈接目的的準確性。
4.限制鏈接數限制和匹配桌面和移動鏈接和主要內容
這兩個項目都被限制為每個網頁的內部鏈接少於 150 個。 在語義 HTML 的幫助下,鏈接的位置和鏈接的功能對爬蟲來說是很清楚的。 IstanbulBogazici Enstitusu 每個網頁有 450 多個鏈接,其中一些是自鏈接(從同一頁面到同一頁面的鏈接)。 最糟糕的是,這些鏈接中有一半不存在於內容的移動版本中。 
URL Keep Score、Crawl Score 和其他類型的分數可用於確定鏈接在內部 URL Map 中的顯著性,並且不同層內的文檔標識標籤可用於根據與查詢無關的相關性分數對索引進行排序。
由於谷歌使用僅移動索引,如果內容不存在於移動版本中,它將被忽略,並且不用於相關性評估和排名目的。 因此,移動和桌面內容已被配置為相互匹配。 即使谷歌容忍桌面和移動版本之間的內容不匹配,它仍然使搜索引擎更難理解和排名網頁。 
搜索引擎可以為網站生成站點地圖,如果鏈接和 URL 元數據在用戶代理或時間線之間不匹配,則可以循環重新生成該站點地圖。 因此,保持爬行路徑短、爬行隊列簡短和內部鏈接一致很重要。
除了不同網頁之間的鏈接外,網頁子部分的鏈接也與“內容表”和“URL片段”一起使用。 這些 URL 片段在正確命名時以網頁的特定子部分為目標,並且該特定部分已放入帶有 h2 的部分標記中。 借助帶有“頁內導航鏈接”的 URL Fragments,將用戶從 SERP 引導到網頁的特定部分更加容易,同時內容的底部部分更加突出以滿足背後的需求詢問。
5. 為您的 SEO 項目制定軍事級別的紀律
這完全是另一個話題,可以寫另一篇文章來定義軍事級別的紀律意味著什麼,或者為什麼它對 SEO 項目有用。 但是,我必須告訴你,在過去的兩個月裡,我已經培訓了很多 CEO,以及來自其他機構的 SEO 以及他們的團隊,看看我的課程設計是否會運作良好。
每當我看到成功,以及對我所進行的教育課程的高度把握時,就會有強烈的意志和毅力。 主要問題是語義搜索引擎優化比其他垂直搜索引擎優化要困難得多。 技術 SEO 是通用的,它甚至為每一步都編寫了指南。 OnPage SEO 或 WUX 和佈局設計可以通過數字測量進行跟踪。 說到語義,它是將基於復雜自適應系統工作的機器的視角與不了解機器如何工作的智人結合起來的實踐。
這種區別需要一個具體的基礎,應該從項目的第一天開始。 大多數時候,我使用以下規則。
- 內容設計和語義內容網絡對於作者或作者來說不必是合乎邏輯的。
- 內容管理員的任務是審核內容與內容設計的兼容性。
- 作者的任務是編寫包含高度準確性和詳細信息的相關信息的內容。
- 鏈接、定義、證據、比較、命題、參考應該用具體的例子,而不是絨毛。
- 每個不必要的詞都是對上下文和概念的稀釋。
當您閱讀時,它可能聽起來很容易實現,但並不那麼容易。 因此,我可以說我什至要解僱我自己的一些員工。 我很高興我沒有,至少現在是這樣。 在正常情況下,您會被問到很多問題,如果問題所有者不是 SEO 或公司所有者,請不要回答。 將您的精力保存到搜索引擎的數據存儲中,該存儲將存儲您的積極反饋,而不是對排名的多餘和不相關的反饋。
6. 擴展具有上下文相關性的來源
本節完全是關於了解 Google 對創建 MuM 的需求。 當您設計主題地圖時,它將包含許多語義內容網絡,這些網絡將提供更好的站點級知識庫。 因此,在發布這些子部分時,它們應該能夠連接到源的上下文,或者它可以改變搜索引擎如何看待源,並且網站的主題可以切換到另一個知識域。 例如,將概念和興趣領域周圍的事物與可能的行動聯繫起來,需要了解複雜含義之間的聯繫。 讓用戶、作者和機器同時了解這些連接是語義內容網絡創建的過程。 
為此,網站的每個新部分都應該能夠連接到主題地圖的中心部分。 這些上下文橋樑可以從 Google 自己的 LaMDA 設計和解釋中看出。
我遇到很多問題,例如“我應該寫另一個話題嗎”、“如果我有兩個不同的領域,會不會有害?”。 如果將所有這些子部分、網站段連接為強連接組件,這些語義內容網絡將相互支持以獲得更好的排名,而不是劃分品牌標識和兩個不同且不相關主題的主題權威。
7. 使用 Google Analytics 自定義細分創建實際流量和審計
實際流量連接到 RankMerge 的方式與基於知識的信任連接到 PageRank 的方式相同。 很快,我正在考慮寫另一篇題為“當 PageRank 撒謊……”的文章來解釋為什麼搜索引擎會試圖通過側信號影響 PageRank。 事實上,PageRank 並不是顯示來源權威、專業知識和可信度的明確信號。 它可以是排名的信號,也是一個因素,但不能單獨信任。 RankMerge 是將網站流量和 PageRank 以一種網站對搜索引擎有意義的方式結合起來的過程。 高 PageRank 和低流量可以表示“不受歡迎的流量”或“PageRank 操縱”。
因此,為了改進來源的歷史數據,我使用了季節性 SEO 事件,並增加了“品牌 + 通用術語”查詢。 直接流量和添加書籤的網頁隨著實際和真實流量的增加而增加。
這些類型的數據有助於搜索引擎信任它,因為它在 SERP 上的排名越來越高。
為了能夠審核來自語義內容網絡的這些實際流量,SEO 可以從 Google Analytics 創建一個自定義細分,以查看它們是如何作為直接流量而來的。 此外,可以創建自定義目標,例如創建從第一個語義內容網絡到第二個內容網絡的可能搜索旅程。 這是圍繞興趣、概念和可能的搜索相關動作構建語義網絡的概念證明。
下面,您將僅找到一個網頁示例,該網頁位於第一個語義內容網絡中,用於展示通過自然流量獲得的直接流量。 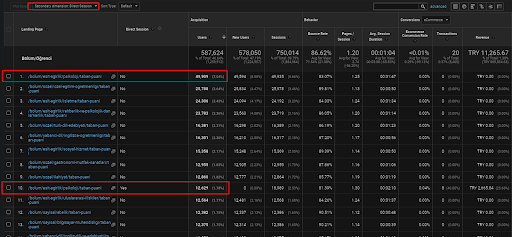
在過去 3 個月中,只有一個來自第一個語義內容網絡的網頁被 49.000 個自然用戶使用。 並且,12.900 額外的用戶是第一次通過自然搜索獲得的直接流量。 而且,這些用戶細分的會話/頁面指標和平均會話持續時間更高。
如前所述,搜索引擎可以對查詢、文檔、意圖、概念、興趣、操作進行聚類,還可以對用戶進行聚類。 如果一個用戶群在創造品牌價值的同時,通過將這些網頁添加到書籤、直接輸入地址欄、搜索通用術語和品牌名稱等方式留下了積極的反饋,則表明來源提高了其權威性,並且搜索引擎能夠識別來自 SERP、Chrome 和它自己的 DNS 地址的所有內容。 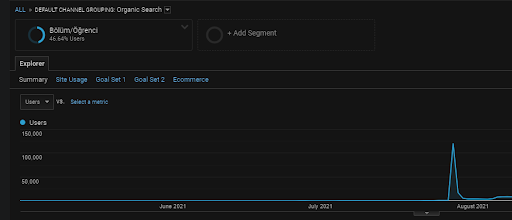
在上面,您可以看到 First Content Network 的用戶群。 您可以為每個具有自定義目標的語義內容網絡創建用戶細分,也可以為語義子內容網絡添加子用戶細分。
8. 支持基於搜索活動的帶有子部分的語義內容網絡
這部分也是關於實體屬性解析,以及另一個主題的分析。 但是,簡單地說,這些基於上下文域的實體的某些屬性應該放在較低的層次結構中,而不是放在較高的層次結構中。 在這種情況下,“Vizem.net”可以給出一個更好的例子,而對於 Bogazici Enstitusu,它可以通過“職業工資”和“大學考試分數”來展示。 這兩個突出的屬性已根據查詢和文檔模板放置到語義子內容網絡中。 
從搜索查詢中識別語義單元是谷歌的另一項專利,它將短語劃分為不同的語義類別,並根據文檔與查詢的所有變體的接近程度來聚合文檔的相關性。
在之前的 SEO 案例研究中,我沒有遵循這種類型的結構,而是根據“年表”和嚴格限制的內部鏈接創建了爬網路徑。 在這些文章中,主要內容放置的內部鏈接數量高於上一篇。
9. 在 URL 中使用主題詞
如果 Google 在沒有任何規範化信號的情況下遇到具有相同內容的兩個不同 URL,它會選擇較短的 URL 作為規範化 URL。 因為,短 URL 更容易解析、解析和請求。 當您擁有每天刷新數十億次的數万億網頁時,即使是 URL 中的字母也可以顯示網站的“成本/質量平衡”。 正如我之前所說,“檢索成本”應該低於“不檢索成本”。 如果您想被搜索引擎理解,您應該將“有序和互補的上下文信號”放到每個級別,包括 URL。 
通過證據聚合進行的“基於證據”排名的一部分。 它解釋瞭如何將答案與問題匹配。
在這種情況下,大多數時候,我在 URL 中使用一個單詞。 這些可以反映語義內容網絡的層次結構和結構。 有些人仍然認為 URL 中的“層數”會影響爬取頻率,在 2019 年之前,確實如此。 但是,只要內容有意義,並且滿足來自熱門或突出主題的用戶,就不會受到這種情況的影響。
為了演示它,您可以按照下面的示例進行操作。
- 根域/semantic-content-network-1/type-1/sub-content-network-part-for-type-1
- 根域/semantic-content-network-2/type-2/sub-content-network-part-for-type-2
這兩個語義內容網絡可以從同一層次結構中相互鏈接,並且它們也可以基於相關性來鏈接自己。 這裡還有更多我們可以討論的內容,例如“Entity Grouper Contents – Hub 類型內容”,但這是另一天的話題。
注意:計劃中的第三語義內容網絡也可以作為“概念分組內容網絡”處理。 而且,如果它發布,在第二語義內容網絡的作用下,整體有機流量每月可以超過 300 萬次會話。
10. 理解嵌套和連接的區別
作為一種實際的方法學差異,連接是基於上下文域將相似的事物相互連接,而嵌套是將具有相同目的的相似內容組合在一起。 這種聚類將幫助搜索引擎更快地找到彼此相似的內容,並為這些組創建源質量分數,或者這些基於語義網絡的嵌套內容將更容易。 
想像有如下兩條不同的爬網路徑。
- 爬取路徑 1:隨機遇到 URL,沒有模板、相似性和上下文相關性。
- 抓取路徑 2:遇到即使從 URL 本身也有意義的 URL,具有基於上下文的模板、高度相似性和相關性。
如果即使從爬取路徑來看,內容是有意義的,那麼“初始排名”和“重新排名”會更好,這要歸功於“基於對搜索引擎的覆蓋理解的重新排名觸發”。
注意:以正確的方式使用帶有短語分類的內部鏈接對於嵌套和連接很重要。
這將我們帶到了最後兩個實用方法的簡要分享。 並且,這部分再次與高水平的紀律和組織充分性有關。 
Trystan Upstill 和 Steven D. Baker 的一項專利,用於識別 HTML 列表中同時出現的術語。 該專利的突出之處在於它顯示了單個 HTML 列表的值,以確定主題或短語分類法的一部分的同時出現的術語列表。
11.了解何時發布具有調整頻率的語義內容網絡
這在之前已經解釋過了,但是在其中一個 SEO 案例研究項目中,我在一天內發布了近 400 條內容。 說到另一個,我突然開始只發布 10-15 個內容,然後隨著時間的推移穩步增加速度,直到與 Covid 相關的經濟問題開始。
如果一個新的來源創建了一個新的語義內容網絡,在第一天發布它可能比你想像的要困難一些,檢查網頁上的所有內部鏈接、語法和信息並不是那麼容易。 但是,如果所有內容都來自一個主題和一個查詢模板,並且如果來源沒有關於該主題的任何歷史記錄,那麼發布大部分語義內容網絡具有更快的索引、理解和重新排名。
在我的情況下,還有一個具有季節性的歷史事件。 因此,我的目的是獲得足夠的平均排名,直到我能夠被搜索引擎針對特定實體和針對舊資源的搜索活動進行測試。 因此,我在季節性活動的 45 天前發布了第一個語義內容網絡,並進行了高水平的準備。
然後,您可以看到搜索引擎如何重複測試源,如下所示。 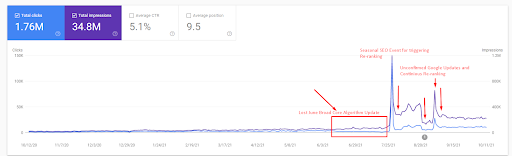
更詳細的解釋可以在下面找到。 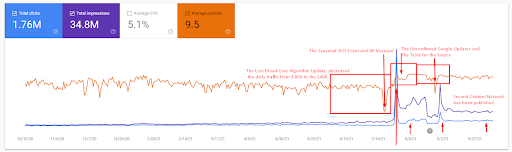
對於上面的屏幕截圖說明,可以在下面找到快速事實檢查。
- 廣泛的核心算法更新使網站的流量減少了 200% 以上。
- 該網站還丟失了超過 15,000 個查詢。
- 這影響了新語義內容網絡源的整體索引,因為在詳細的 SEO 案例研究文章中得到了更好的解釋。
- 多虧了季節性 SEO 事件,重新排名發生得更早,而在季節性 SEO 事件之後,搜索引擎在未經確認的更新期間根據實際流量對源的排名進行了規範化。
- 由於第一語義內容網絡和季節性事件而獲得的查詢和排名得到了保護,並進一步提高了。
- 第一個語義內容網絡也支持新的和第二個語義內容網絡。
查詢損失和平均排名損失也可以從下面的 Ahrefs 中看出。 您可以查看 2021 年 6 月 Google 廣泛核心算法更新 (GBCAU) 效果以及未確認更新的效果。 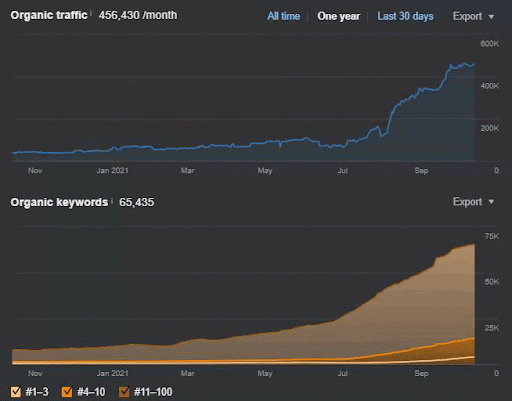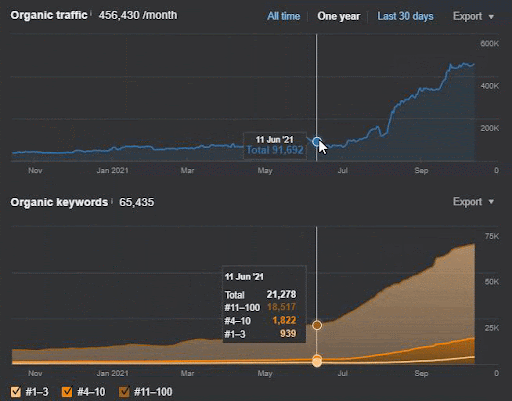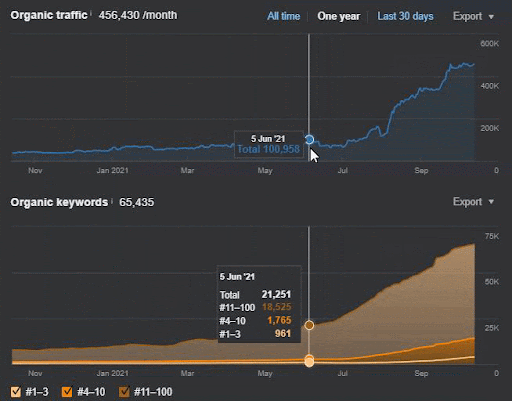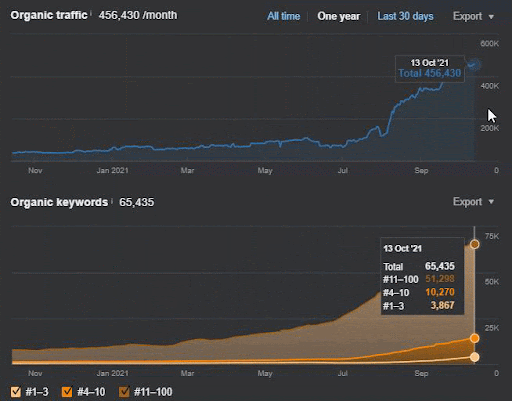
因此,使用具有多種可能策略的語義內容網絡是必要的。 即使 GCBAU 丟失了,由於與搜索引擎相關的其他因素,自然可以幫助 SEO。 因此,您可能會想像為什麼向作者或客戶解釋這些事情比技術 SEO 更難。 語義 SEO 不使用數值,它使用通過專利、研究論文、經驗和歷史公告來自搜索引擎理解的理論知識。
12.使用頁內句子優化以獲得更好的事實結構
老實說,即使是第 10 個列表也是一個全新的話題,甚至可能需要在這裡寫 20.000 個單詞。 但是,我將從一個簡單的例子開始。
- X 是 Y。
- Y 是 X。
對於上面的例句,您可以理解以下內容。
- 上面的句子不是重複的內容。
- 上述命題是重複的。
- 兩個句子之間的關係解釋是一樣的。
- 語義角色標籤是 100% 不同的。
- 命名實體識別輸出是 100% 相同的。
頁面內句子優化與問題生成算法和問答配對技術有關。 問題格式需要某種類型的句子。 某些類型的問題應該用某些類型的句子來回答。 內容格式、NER 和 Fact Extraction 都會受到句子結構優化的影響。 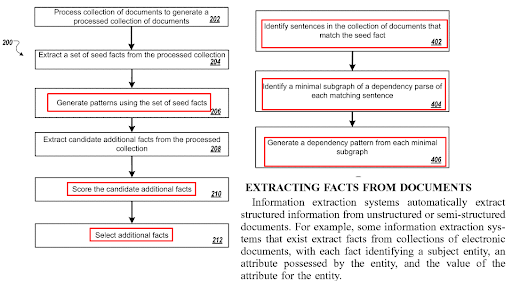
可以更快地提取和檢查三元組(一個對象,兩個主體)的準確性。 兩個相似的句子並不意味著它們是重複的,而是意味著它們在句子結構上彼此接近。 只要命題不同,對於不同的查詢-意圖對,在相似的文檔模板之間使用相似的句子是語義內容網絡創建的必要條件。 
具有適當模式的清晰句子結構有助於使文本片段彼此之間更加相關,同時幫助搜索引擎識別命名實體、主題、屬性以及它們彼此的值。
它還有助於查看文章的哪個部分可以做得更好,以及在 Topical Nets 中,您的內容在哪些類型的詞對、詞向量和意圖方面排名更好。 因為,如果可以在多個網頁上觀察到某些類型的問題的某些類型的句子結構,它將有助於具有無窮無盡的數據樣本和測試樣本的高級 SEO A/B 測試。 您可以創建多個頁內句子設計,以檢查搜索引擎如何提取事實以進行比較。 
說到提供事實,應該記住“知識庫”和Luna Dong。
13. 以精確和一致的方式提供真實世界的信息,而不是蓬鬆的意見
這裡的精度意味著能夠與數值或概念上的具體關係進行比較。 一致性意味著你保護你對特定命題的立場。 例如,不要對與 Y 相關的每個產品評論都說“X 產品最適合 Y”。不要在網站範圍內給出相互矛盾的主張。 而且,如果產品是最好的,它的證據是什麼? 材料,尺寸,還是顏色和氣味? 文本中的絨毛意味著您使用了不必要的過渡詞,或者不說出無法證明的事情,或者與事實相矛盾。
在某些示例支持的這些非定義指令的上下文中,您可以查看 Google 的語言模型之一,即 KeALM。
它用於使用數據到文本模型從數據庫生成文本,並用於檢查內容的準確性。 
KELM 是使用文本到數據方法的命題的準確性審計示例。
這也有點關於“三元組”和“未知實體的開放信息提取”的定義,但如您所知,這是一個簡短的版本,我想,我已經講得夠多了。 基本上,當您在您的網站上提供錯誤信息時,請確保 Google 能夠理解它以降低來源的基於知識的信任度。 在這裡,您可能還需要知道,由於您可以擴展知識庫,如果您有一個具有 PageRank 和知識庫信任的相關源,搜索引擎可以根據您的信息更改自己的知識庫具有高精度和獨特的三元組。
14. 理解實體的語義依賴樹
語義依賴樹意味著表示與其他實體的關係的屬性在它們之間具有層次依賴關係。 語義依賴樹可以通過檢查多個實體概況和角度來觀察,例如一個國家可以是一個組織的成員,而作為另一個實體,這個組織可以具有一些其他屬性,這些屬性可以歸因於具有推斷關係的連接國家。
下面,您將能夠直接從搜索引擎中看到一個簡單的示例。 
REALM 是一種使用語義依賴樹從模糊文本中提取信息的方法。
在開放網絡上,開放信息提取可以識別新的命名實體,並將這些相同的實體提取為與其他實體同時出現。 文章中的這些共現和相互屬性可以在實體之間分配上下文和候選關係類型。 基於實體的連接和類型,可以創建語義依賴樹。 同樣的邏輯也發生在詞彙語義上。 “男孩”這個詞有一些可能的含義和一些確切的其他含義。 例如,男孩是男性,並且可能是未婚的青少年。 它也可以在學生附近使用。 另一方面,“女王”一詞包括其他側面和確切的含義,例如“女性”和“擔任州長”。 因此,有一些東西要治理是一種自然的語義依賴樹層次結構,它可以指示某些類型的查詢模板,例如“Queen of ...”或“For Quen”。 These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together. 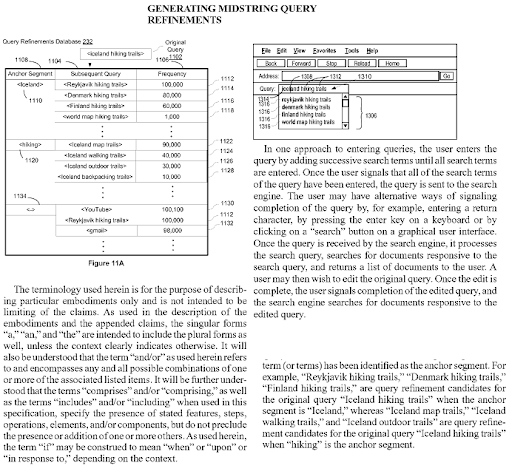
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network's connections to each other. Every midstring query refinement is a part of the topic's sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.