
控制抓取和索引:Robots.txt 和標籤的 SEO 指南
已發表: 2019-02-19優化抓取預算和阻止索引頁面中的機器人是許多 SEO 熟悉的概念。 但魔鬼在細節中。 尤其是近年來最佳實踐發生了顯著變化。
對 robots.txt 文件或機器人標籤的一個小改動可能會對您的網站產生巨大影響。 為了確保對您的網站產生積極的影響,今天我們將深入研究:
優化抓取預算
什麼是 Robots.txt 文件
什麼是元機器人標籤
什麼是 X 機器人標籤
機器人指令和 SEO
最佳實踐機器人清單
優化抓取預算
搜索引擎蜘蛛對它可以和想要在您的網站上抓取多少頁面有一個“允許”。 這被稱為“抓取預算”。
在 Google Search Console (GSC)“抓取統計”報告中查找您網站的抓取預算。 請注意,GSC 是 12 個機器人的集合,它們並不都專門用於 SEO。 它還收集作為 SEA 機器人的 AdWords 或 AdSense 機器人。 因此,此工具可讓您了解全局爬網預算,但不能了解其確切的重新分配。
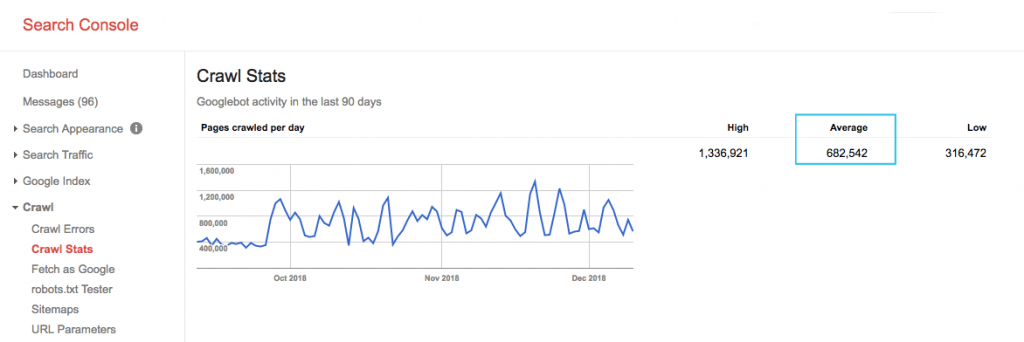
為了使該數字更具可操作性,請將每天抓取的平均頁面數除以您網站上的可抓取頁面總數 - 您可以向開發人員詢問數字或運行無限制的網站抓取工具。 這將為您提供一個預期的抓取比率,供您開始優化。
想要更深入? 通過分析您網站的服務器日誌文件,更詳細地了解 Googlebot 的活動情況,例如訪問了哪些網頁,以及其他抓取工具的統計信息。
優化抓取預算的方法有很多,但一個簡單的起點是查看 GSC“覆蓋率”報告以了解 Google 當前的抓取和索引行為。
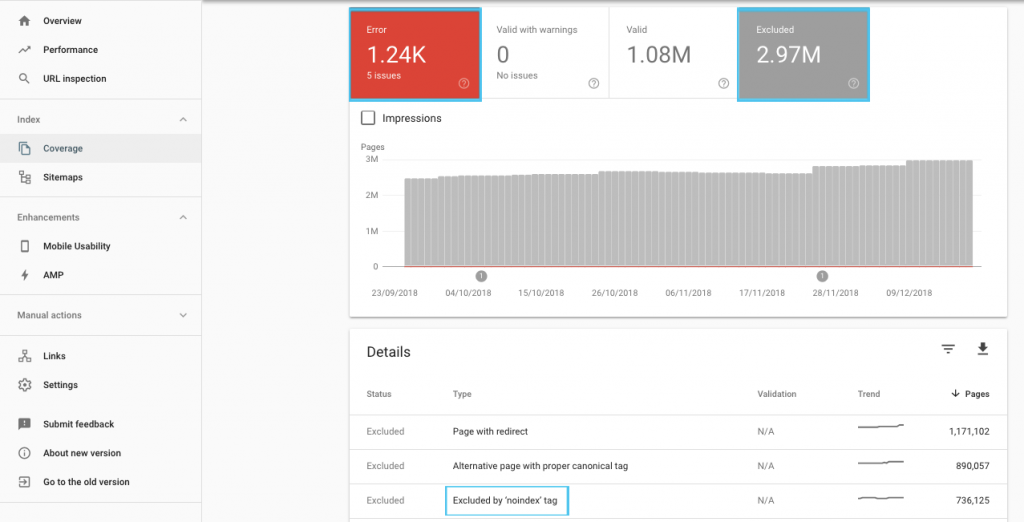
如果您看到諸如“提交的 URL 標記為 'noindex'”或“提交的 URL 被 robots.txt 阻止”之類的錯誤,請與您的開發人員一起修復它們。 對於任何機器人排除項,請調查它們以了解它們是否從 SEO 角度具有戰略意義。
一般來說,搜索引擎優化的目標應該是盡量減少對機器人的爬行限制。 改進您網站的架構以使 URL 對搜索引擎有用且可訪問是最佳策略。
谷歌自己指出,“一個可靠的信息架構可能比專注於抓取優先級更有效地利用資源”。
話雖如此,了解 robots.txt 文件和機器人標籤可以做什麼來指導抓取、索引和鏈接資產的傳遞是有益的。 更重要的是,何時以及如何最好地利用它進行現代 SEO。
[案例研究] 管理 Google 的機器人抓取
 閱讀案例研究
閱讀案例研究什麼是 Robots.txt 文件
在搜索引擎抓取任何頁面之前,它會檢查 robots.txt。 該文件告訴機器人他們有權訪問哪些 URL 路徑。 但這些條目只是指令,而不是命令。
Robots.txt不能像防火牆或密碼保護一樣可靠地阻止抓取。 它相當於未上鎖的門上的“請不要進入”標誌。
禮貌的爬蟲,比如各大搜索引擎,一般都會聽從指令。 惡意爬蟲,如電子郵件抓取工具、垃圾郵件機器人、惡意軟件和掃描網站漏洞的蜘蛛,通常不會引起注意。
更重要的是,它是一個公開的文件。 任何人都可以看到您的指令。
不要使用您的 robots.txt 文件來:
- 隱藏敏感信息。 使用密碼保護。
- 阻止訪問您的登台和/或開發站點。 使用服務器端身份驗證。
- 明確阻止敵對爬蟲。 使用 IP 阻止或用戶代理阻止(也就是使用 .htaccess 文件中的規則或 CloudFlare 等工具來阻止特定的爬蟲訪問)。
每個網站都應該有一個有效的 robots.txt 文件,其中至少包含一個指令分組。 沒有一個,默認情況下所有機器人都被授予完全訪問權限——因此每個頁面都被視為可抓取的。 即使這是您的意圖,最好使用 robots.txt 文件向所有利益相關者說明這一點。 另外,如果沒有,您的服務器日誌將充滿對 robots.txt 的失敗請求。
robots.txt 文件的結構
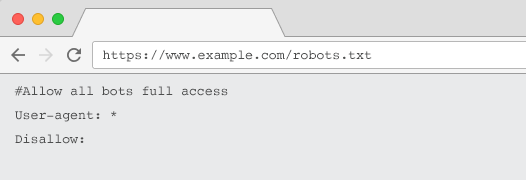
要被爬蟲確認,您的 robots.txt 必須:
- 是一個名為“robots.txt”的文本文件。 文件名區分大小寫。 “Robots.TXT”或其他變體將不起作用。
- 位於您的規範域和子域(如果相關)的頂級目錄中。 例如,要控制對 https://www.example.com 下所有 URL 的抓取,robots.txt 文件必須位於 https://www.example.com/robots.txt 和 subdomain.example.com 位於subdomain.example.com/robots.txt。
- 返回 200 OK 的 HTTP 狀態。
- 使用有效的 robots.txt 語法 – 使用 Google Search Console robots.txt 測試工具進行檢查。
robots.txt 文件由指令分組組成。 參賽作品主要包括:
- 1.用戶代理:解決各種爬蟲。 您可以為所有機器人設置一個組,也可以使用組來命名特定的搜索引擎。
- 2. Disallow:指定不被上述用戶代理抓取的文件或目錄。 每個塊可以有一個或多個這樣的行。
有關用戶代理名稱的完整列表和更多指令示例,請查看 Yoast 上的 robots.txt 指南。
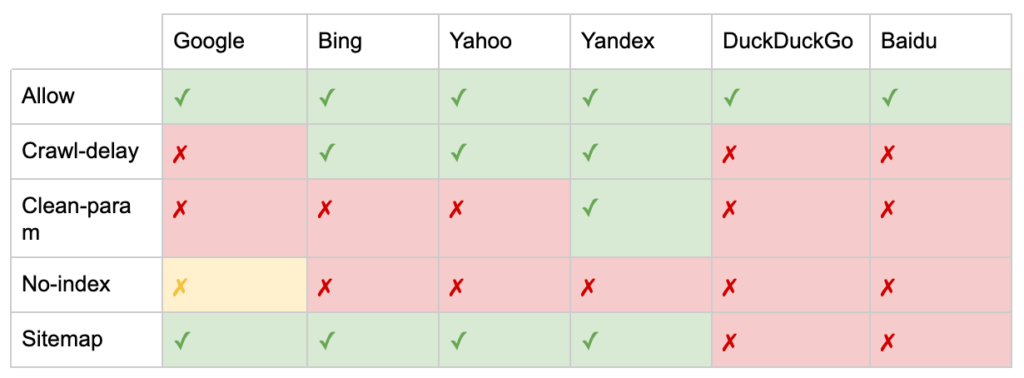
除了“User-agent”和“Disallow”指令之外,還有一些非標準指令:
- 允許:為父目錄指定禁止指令的例外。
- Crawl-delay:通過告訴機器人在訪問頁面之前等待多少秒來限制重型爬蟲。 如果您獲得的自然會話很少,則 crawl-delay 可以節省服務器帶寬。 但只有當爬蟲主動導致服務器負載問題時,我才會投入精力。 Google 不承認此命令,在 Google Search Console 中提供了限制抓取速度的選項。
- clean-param:避免重新爬取動態參數生成的重複內容。
- 無索引:旨在控制索引而不使用任何爬網預算。 谷歌不再正式支持它。 雖然有證據表明它可能仍會產生影響,但它並不可靠,也不被約翰·穆勒等專家推薦。
@maxxeight @google @DeepCrawl 我真的會避免在那裡使用 noindex 。
——??? 約翰 ???? (@JohnMu)2015 年 9 月 1 日
- 站點地圖:提交 XML 站點地圖的最佳方式是通過 Google 搜索控制台和其他搜索引擎的網站管理員工具。 但是,在 robots.txt 文件的基礎上添加站點地圖指令有助於其他可能不提供提交選項的爬蟲。
robots.txt 對 SEO 的限制
我們已經知道 robots.txt 無法阻止所有機器人的抓取。 同樣,禁止爬蟲從一個頁面並不會阻止它被包含在搜索引擎結果頁面 (SERP) 中。
如果被阻止的頁面有其他強大的排名信號,Google 可能會認為它與在搜索結果中顯示相關。 儘管沒有爬取頁面。
由於 Google 不知道該 URL 的內容,因此搜索結果如下所示:

要明確阻止頁面出現在 SERP 中,您需要使用“noindex”機器人元標記或 X-Robots-Tag HTTP 標頭。
在這種情況下,不要禁止robots.txt 中的頁面,因為必須抓取該頁面才能看到並遵守“noindex”標籤。 如果 URL 被阻止,則所有 robots 標籤都無效。
更重要的是,如果一個頁面已經積累了大量的入站鏈接,但谷歌被 robots.txt 阻止了這些頁面的抓取,而這些鏈接是谷歌已知的,那麼鏈接資產就會丟失。
什麼是元機器人標籤
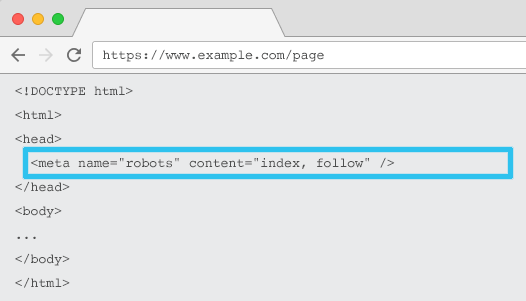
放置在每個 URL 的 HTML 中,meta name="robots" 告訴爬蟲是否以及如何“索引”內容以及是否“關注”(即爬取)所有頁面鏈接,傳遞鏈接權益。
使用通用元名稱 =“robots”,該指令適用於所有爬蟲。 您還可以指定特定的用戶代理。 例如,元名稱=“googlebot”。 但是很少需要使用多個元機器人標籤來為特定的蜘蛛設置指令。
使用元機器人標籤時有兩個重要的考慮因素:
- 與 robots.txt 類似,元標記是指令,而不是命令,因此可能會被某些機器人忽略。
- robots nofollow 指令僅適用於該頁面上的鏈接。 爬蟲可能會在沒有 nofollow 的情況下跟踪來自另一個頁面或網站的鏈接。 因此,機器人可能仍會到達並索引您不需要的頁面。
以下是所有元機器人標籤指令的列表:
- index:告訴搜索引擎在搜索結果中顯示此頁面。 如果沒有指定指令,這是默認狀態。
- noindex:告訴搜索引擎不要在搜索結果中顯示此頁面。
- follow:告訴搜索引擎關注該頁面上的所有鏈接並傳遞權益,即使該頁面沒有被索引。 如果沒有指定指令,這是默認狀態。
- nofollow:告訴搜索引擎不要關注此頁面上的任何鏈接或傳遞股權。
- all:相當於“索引,跟隨”。
- none:相當於“noindex, nofollow”。
- noimageindex:告訴搜索引擎不要索引此頁面上的任何圖像。
- noarchive:告訴搜索引擎不要在搜索結果中顯示此頁面的緩存鏈接。
- nocache:與 noarchive 相同,但僅由 Internet Explorer 和 Firefox 使用。
- nosnippet:告訴搜索引擎不要在搜索結果中顯示此頁面的元描述或視頻預覽。
- notranslate:告訴搜索引擎不要在搜索結果中提供此頁面的翻譯。
- 不可用後:告訴搜索引擎在指定日期後不再索引此頁面。
- noodp:現在已棄用,它曾經阻止搜索引擎在搜索結果中使用來自 DMOZ 的頁面描述。
- noydir:現在已棄用,它曾經阻止 Yahoo 在搜索結果中使用 Yahoo 目錄中的頁面描述。
- noyaca:阻止 Yandex 在搜索結果中使用來自 Yandex 目錄的頁面描述。
正如 Yoast 所記錄的那樣,並非所有搜索引擎都支持所有機器人元標記,或者甚至清楚它們支持和不支持的內容。

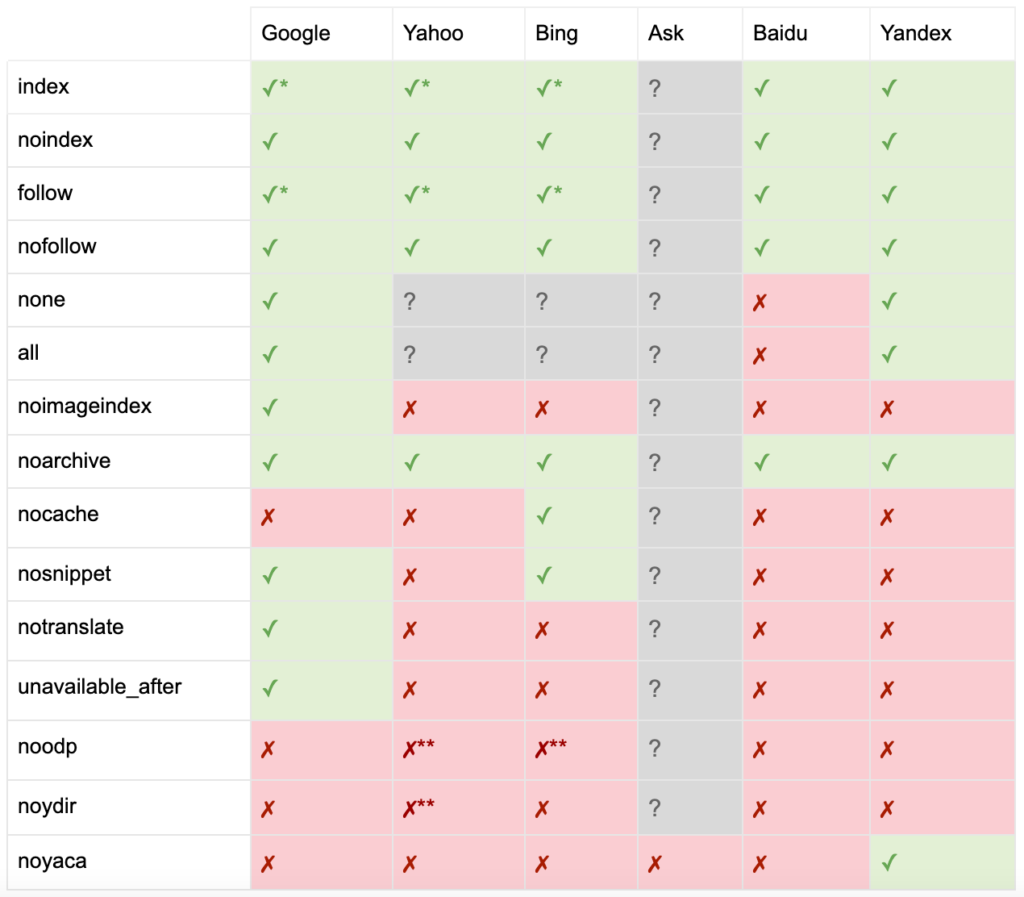
* 大多數搜索引擎對此沒有具體的文檔,但它假設支持排除參數(例如,nofollow)意味著支持積極的等價物(例如,follow)。
** 雖然 noodp 和 noydir 屬性可能仍被“支持”,但目錄不再存在,並且這些值很可能什麼都不做。
通常,機器人標籤將設置為“索引,關注”。 一些 SEO 認為在 HTML 中添加這個標籤是多餘的,因為它是默認的。 相反的論點是,明確的指令規範可能有助於避免任何人為混淆。
請注意:帶有“noindex”標籤的 URL 被抓取的頻率會降低,如果它存在很長時間,最終會導致 Google 不關注該頁面的鏈接。
很難找到一個用例來“nofollow”帶有元機器人標籤的頁面上的所有鏈接。 使用 rel=”nofollow” 鏈接屬性在單個鏈接上添加“nofollow”更為常見。 例如,您可能需要考慮向用戶生成的評論或付費鏈接添加 rel=”nofollow” 屬性。
對於不涉及基本索引和遵循行為(例如緩存、圖像索引和片段處理等)的機器人標籤指令,甚至更少有 SEO 用例。
元機器人標籤的挑戰在於它們不能用於非 HTML 文件,例如圖像、視頻或 PDF 文檔。 這是您可以求助於 X-Robots-Tags 的地方。
什麼是 X 機器人標籤
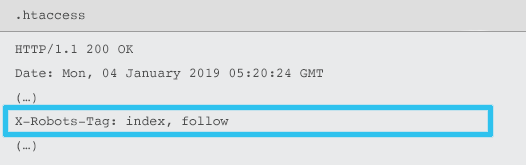
X-Robots-Tag 由服務器使用 .htaccess 和 httpd.conf 文件作為給定 URL 的 HTTP 響應標頭的元素發送。
任何機器人元標記指令也可以指定為 X-Robots-Tag。 但是,X-Robots-Tag 在頂部提供了一些額外的靈活性和功能。
如果您想:
- 控制非 HTML 文件的機器人行為,而不是單獨的 HTML 文件。
- 控制頁面特定元素的索引,而不是整個頁面。
- 為頁面是否應被索引添加規則。 例如,如果作者發表的文章超過 5 篇,則將其個人資料頁面編入索引。
- 在站點範圍內應用索引並遵循指令,而不是特定於頁面。
- 使用正則表達式。
避免在同一頁面上同時使用元機器人和 x-robots-tag——這樣做是多餘的。
要查看 X-Robots-Tags,您可以使用 Google Search Console 中的“Fetch as Google”功能。
機器人指令和 SEO
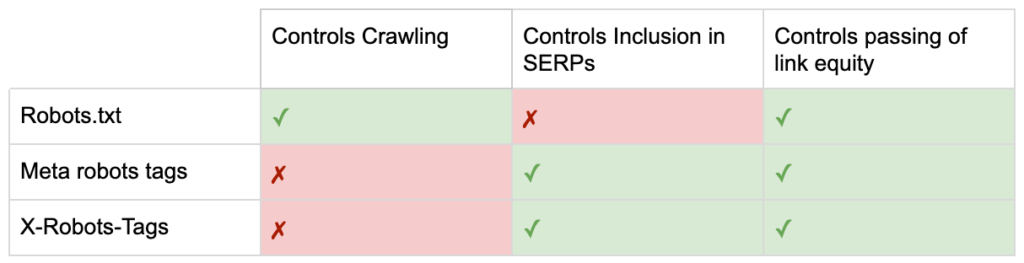
所以現在你知道三個機器人指令之間的區別了。
robots.txt 專注於節省抓取預算,但不會阻止頁面顯示在搜索結果中。 它充當您網站的第一個看門人,指示機器人在請求頁面之前不要訪問。
兩種類型的機器人標籤都專注於控制索引和鏈接資產的傳遞。 機器人元標記僅在頁面加載後才有效。 雖然 X-Robots-Tag 標頭提供更精細的控制,並且在服務器響應頁面請求後才有效。
有了這種理解,SEO 可以發展我們使用機器人指令來解決抓取和索引挑戰的方式。
阻止機器人以節省服務器帶寬
問題:分析您的日誌文件,您會看到許多用戶代理佔用了帶寬但幾乎沒有回報。
- SEO 爬蟲,例如 MJ12bot(來自 Majestic)或 Ahrefsbot(來自 Ahrefs)。
- 離線保存數字內容的工具,例如 Webcopier 或 Teleport。
- 與您的市場不相關的搜索引擎,例如百度蜘蛛或 Yandex。
次優解決方案:使用 robots.txt 阻止這些蜘蛛,因為它不能保證被兌現,而且是一個相當公開的聲明,可以為感興趣的各方提供競爭見解。
最佳實踐方法:用戶代理阻塞的更微妙的指令。 這可以通過不同的方式完成,但通常是通過編輯您的 .htaccess 文件以將任何不需要的蜘蛛請求重定向到 403 - 禁止頁面來完成。
使用抓取預算的內部站點搜索頁面
問題:在許多網站上,內部站點搜索結果頁面是在靜態 URL 上動態生成的,這會佔用爬網預算,並且如果被編入索引,可能會導致內容稀少或重複內容問題。
次優解決方案:禁止帶有 robots.txt 的目錄。 雖然這可以防止爬蟲陷阱,但它限制了您對關鍵客戶搜索的排名以及此類頁面傳遞鏈接資產的能力。
最佳實踐方法:將相關的大量查詢映射到現有的搜索引擎友好 URL。 例如,如果我搜索“samsung phone”,而不是為 /search/samsung-phone 創建一個新頁面,而是重定向到 /phones/samsung。
如果無法做到這一點,請創建基於參數的 URL。 然後,您可以輕鬆地指定是否希望在 Google Search Console 中抓取參數。
如果您確實允許抓取,請分析此類頁面的質量是否足夠高以進行排名。 如果沒有,請添加“noindex,follow”指令作為短期解決方案,同時制定如何提高結果質量以幫助 SEO 和用戶體驗的策略。
使用機器人阻止參數
問題:查詢字符串參數(例如由分面導航或跟踪生成的參數)因消耗爬網預算、創建重複的內容 URL 和拆分排名信號而臭名昭著。
次優解決方案:禁止使用 robots.txt 或“noindex”機器人元標記抓取參數,因為兩者(前者立即,後者在較長時期內)都會阻止鏈接資產的流動。
最佳實踐方法:確保每個參數都有明確的存在理由並實施排序規則,該規則僅使用一次鍵並防止空值。 將 rel=canonical 鏈接屬性添加到合適的參數頁面以結合排名能力。 然後在 Google Search Console 中配置所有參數,其中有更精細的選項來傳達抓取偏好。 有關更多詳細信息,請查看 Search Engine Journal 的參數處理指南。
阻止管理員或帳戶區域
問題:阻止搜索引擎抓取任何私人內容並將其編入索引。
次優解決方案:使用 robots.txt 阻止目錄,因為這不能保證將私有頁面排除在 SERP 之外。
最佳實踐方法:使用密碼保護來防止爬蟲訪問頁面,並在 HTTP 標頭中使用“noindex”指令。
阻止營銷登陸頁面和感謝頁面
問題:您通常需要排除不用於自然搜索的 URL,例如專用電子郵件或 CPC 活動登錄頁面。 同樣,您不希望尚未轉換的人通過 SERP 訪問您的感謝頁面。
次優解決方案:禁止帶有 robots.txt 的文件,因為這不會阻止鏈接包含在搜索結果中。
最佳實踐方法:使用“noindex”元標記。
管理現場重複內容
問題:某些網站出於用戶體驗原因需要特定內容的副本,例如頁面的打印機友好版本,但希望確保搜索引擎能夠識別規範頁面,而不是重複頁面。 在其他網站上,重複內容是由於糟糕的開發實踐造成的,例如在多個類別 URL 上呈現相同的商品進行銷售。
次優解決方案:禁止帶有 robots.txt 的 URL 將阻止重複頁面傳遞任何排名信號。 機器人的 Noindexing 最終會導致 Google 將鏈接也視為“nofollow”,這將防止重複頁面傳遞任何鏈接權益。
最佳實踐方法:如果重複內容沒有理由存在,則刪除源並 301 重定向到搜索引擎友好的 URL。 如果有存在的理由,添加一個 rel=canonical 鏈接屬性來鞏固排名信號。
可訪問帳戶相關頁面的精簡內容
問題:與帳戶相關的頁面,例如登錄、註冊、購物車、結帳或聯繫表格,通常內容較少,對搜索引擎幾乎沒有價值,但對用戶來說卻是必需的。
次優解決方案:禁止帶有 robots.txt 的文件,因為這不會阻止鏈接包含在搜索結果中。
最佳實踐方法:對於大多數網站,這些頁面的數量應該很少,您可能會看到實施機器人處理對 KPI 沒有影響。 如果您確實需要,最好使用“noindex”指令,除非有此類頁面的搜索查詢。
使用抓取預算標記頁面
問題:不受控制的標記會佔用爬網預算,並且通常會導致內容稀少問題。
次優解決方案:禁止使用 robots.txt 或添加“noindex”標籤,因為兩者都會阻礙 SEO 相關標籤的排名並(立即或最終)阻止鏈接資產的傳遞。
最佳實踐方法:評估每個當前標籤的價值。 如果數據顯示該頁面對搜索引擎或用戶幾乎沒有價值,則 301 重定向它們。 對於在剔除後倖存下來的頁面,努力改進頁面元素,使它們對用戶和機器人都有價值。
JavaScript & CSS 的爬取
問題:以前,機器人無法抓取 JavaScript 和其他富媒體內容。 這已經改變,現在強烈建議允許搜索引擎訪問 JS 和 CSS 文件,以便有選擇地呈現頁面。
次優解決方案:禁止帶有 robots.txt 的 JavaScript 和 CSS 文件以節省抓取預算可能會導致索引不佳並對排名產生負面影響。 例如,阻止搜索引擎訪問為廣告插頁式或重定向用戶提供服務的 JavaScript 可能會被視為偽裝。
最佳實踐方法:使用“以 Google 方式獲取”工具檢查任何呈現問題,或使用“已阻止資源”報告快速了解哪些資源被阻止,兩者都可在 Google Search Console 中找到。 如果任何可能阻止搜索引擎正確呈現頁面的資源被阻止,請刪除 robots.txt 禁止。
Oncrawl 搜索引擎優化爬蟲
 學到更多
學到更多最佳實踐機器人清單
網站因機器人控制錯誤而意外從 Google 中刪除的情況非常普遍。
儘管如此,當您知道如何使用機器人時,它可以成為您的 SEO 武器庫的強大補充。 請務必明智謹慎地進行。
為了提供幫助,這裡有一個快速清單:
- 使用密碼保護保護私人信息
- 使用服務器端身份驗證阻止對開發站點的訪問
- 限制佔用帶寬但通過用戶代理阻止提供很少價值的爬蟲
- 確保主域和任何子域在頂級目錄中有一個名為“robots.txt”的文本文件,該文件返回 200 代碼
- 確保 robots.txt 文件至少有一個包含用戶代理行和禁止行的塊
- 確保 robots.txt 文件至少有一個站點地圖行,作為最後一行輸入
- 在 GSC robots.txt 測試器中驗證 robots.txt 文件
- 確保每個可索引頁面都指定其機器人標籤指令
- 確保 robots.txt、機器人元標記、X-Robots-Tags、.htaccess 文件和 GSC 參數處理之間沒有矛盾或多餘的指令
- 修復 GSC 覆蓋率報告中的任何“提交的 URL 標記為 'noindex'”或“提交的 URL 被 robots.txt 阻止”錯誤
- 了解 GSC 覆蓋報告中任何與機器人相關的排除的原因
- 確保 GSC“被阻止的資源”報告中只顯示相關頁面
去檢查你的機器人處理,並確保你做對了。