
爬網、索引和 Python:所有你需要知道的
已發表: 2021-05-31我想從一個非常簡單的等式開始這篇文章:如果您的頁面沒有被抓取,它們將永遠不會被索引,因此,您的 SEO 性能將永遠受到影響(並且很糟糕)。
因此,SEO 需要努力找到使他們的網站可抓取的最佳方法,並向 Google 提供他們最重要的頁面,以使它們被編入索引並開始通過它們獲取流量。
值得慶幸的是,我們有許多資源可以幫助我們提高網站的可抓取性,例如 Screaming Frog、Oncrawl 或 Python。 我將向您展示 Python 如何幫助您分析和提高您的爬取友好性和索引指標。 大多數情況下,這些改進也會推動更好的排名、更高的 SERP 可見性,並最終讓更多的用戶登陸您的網站。
1. 使用 Python 請求索引
1.1。 對於谷歌
可以通過多種方式為 Google 請求索引,但遺憾的是,我對其中任何一種都不太信服。 我將引導您了解三種不同的選擇及其優缺點:
- Selenium 和 Google Search Console:從我的角度來看,在對其和其他選項進行測試之後,這是最有效的解決方案。 但是,經過多次嘗試後,可能會有一個驗證碼彈出窗口將其破壞。
- ping 站點地圖:這肯定有助於使站點地圖按請求進行爬網,但對特定 URL 沒有幫助,例如在新頁面已添加到網站的情況下。
- Google Indexing API:除了廣播公司和工作平台網站外,它不是很可靠。 它有助於提高抓取速度,但不能索引特定的 URL。
在對每種方法進行快速概述之後,讓我們一一深入研究它們。
1.1.1。 Selenium 和谷歌搜索控制台
本質上,我們將在第一個解決方案中做的是從帶有 Selenium 的瀏覽器訪問 Google Search Console,並複制我們將手動遵循的相同過程,以使用 Google Search Console 提交許多用於索引的 URL,但以自動化方式。
注意:不要過度使用此方法,僅在其內容已更新或頁面全新時才提交頁面以供索引。
使用 Selenium 登錄 Google Search Console 的訣竅是首先訪問 OUATH Playground,正如我在本文中解釋的如何自動下載 GSC 抓取統計報告。
#我們導入這些模塊
進口時間
從硒導入網絡驅動程序
從 webdriver_manager.chrome 導入 ChromeDriverManager
從 selenium.webdriver.common.keys 導入密鑰
#我們安裝我們的 Selenium 驅動程序
驅動程序 = webdriver.Chrome(ChromeDriverManager().install())
#我們訪問 OUATH 遊樂場帳戶以登錄 Google 服務
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
#在使用 Xpath 選擇元素並引入我們的電子郵件地址之前,我們稍等片刻以確保渲染完成。
時間.sleep(10)
form1=driver.find_element_by_xpath('//*[@]')
form1.send_keys("<您的電子郵件地址>")
form1.send_keys(Keys.ENTER)
#這裡也是,我們稍等片刻,然後我們介紹我們的密碼。
時間.sleep(10)
form2=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
form2.send_keys("<你的密碼>")
form2.send_keys(Keys.ENTER)
之後,我們可以訪問我們的 Google Search Console URL:
driver.get('https://search.google.com/search-console?resource_id=your_domain')
時間.sleep(5)
box=driver.find_element_by_xpath('/html/body/div[7]/div[2]/header/div[2]/div[2]/div[2]/form/div/div/div/div/div /div[1]/輸入[2]')
box.send_keys("your_URL")
box.send_keys(Keys.ENTER)
時間.sleep(5)
indexation = driver.find_element_by_xpath("/html/body/div[7]/c-wiz[2]/div/div[3]/span/div/div[2]/span/div[2]/div/div /div[1]/span/div[2]/div/c-wiz[2]/div[3]/span/div/span/span/div/span/span[1]")
indexation.click()
時間.sleep(120)
不幸的是,正如介紹中所解釋的,似乎在多次請求之後,它開始需要一個拼圖驗證碼才能繼續索引請求。 由於自動化方法無法解決驗證碼,這是阻礙該解決方案的因素。
1.1.2。 ping 站點地圖
可以使用 ping 方法將站點地圖 URL 提交給 Google。 基本上,您只需向以下端點發出請求,將您的站點地圖 URL 作為參數引入:
http://www.google.com/ping?sitemap=URL/of/file
正如我在本文中解釋的那樣,這可以通過 Python 和請求非常容易地自動化。
導入 urllib.request url = "http://www.google.com/ping?sitemap=https://www.example.com/sitemap.xml" 響應 = urllib.request.urlopen(url)
1.1.3。 谷歌索引 API
Google Indexing API 可以是提高抓取速度的一個很好的解決方案,但通常它不是一種讓您的內容被索引的非常有效的方法,因為它只應該在您的網站在 VideoObject 中嵌入 JobPosting 或 BroadcastEvent 時使用。 但是,如果您想嘗試一下並自己進行測試,您可以按照以下步驟操作。
首先,要開始使用此 API,您需要轉到 Google Cloud Console,創建一個項目和一個服務帳戶憑據。 之後,您將需要從庫中啟用索引 API,並將使用服務帳戶憑據提供的電子郵件帳戶添加為 Google Search Console 上的財產所有者。 您可能需要使用舊版 Google Search Console 才能將此電子郵件地址添加為業主。
按照前面的步驟操作後,您將能夠通過使用下一段代碼開始使用此 API 請求索引和取消索引:
從 oauth2client.service_account 導入 ServiceAccountCredentials
導入 httplib2
範圍= [“https://www.googleapis.com/auth/indexing”]
ENDPOINT = "https://indexing.googleapis.com/v3/urlNotifications:publish"
client_secrets = "path_to_your_credentials.json"
憑據 = ServiceAccountCredentials.from_json_keyfile_name(client_secrets, scopes=SCOPES)
如果憑據為無或憑據。無效:
憑據 = tools.run_flow(流,存儲)
http = credentials.authorize(httplib2.Http())
list_urls = ["https://www.example.com", "https://www.example.com/test2/"]
對於範圍內的迭代(len(list_urls)):
內容='''{
'url': "'''+str(list_urls[iteration])+'''",
“類型”:“URL_UPDATED”
}'''
響應,內容 = http.request(ENDPOINT, method="POST", body=content)
打印(響應)
打印(內容)如果您想要求取消索引,您需要將請求類型從“URL_UPDATED”更改為“URL_DELETED”。 前一段代碼將打印來自 API 的響應以及通知時間及其狀態。 如果狀態為 200,則請求已成功發出。
1.2. 對於必應
很多時候,當我們談論 SEO 時,我們只會想到 Google,但我們不能忘記,在某些市場中還有其他主要的搜索引擎和/或其他搜索引擎,它們擁有可觀的市場份額,例如 Bing。
重要的是從一開始就提到 Bing 在 Bing Webmaster Tools 上已經有一個非常方便的功能,在大多數情況下,您可以每天請求提交多達 10,000 個 URL。 有時,您的每日配額可能低於 10,000 個 URL,但如果您認為需要更大的配額來滿足您的需求,您可以選擇請求增加配額。 您可以在此頁面上閱讀有關此內容的更多信息。
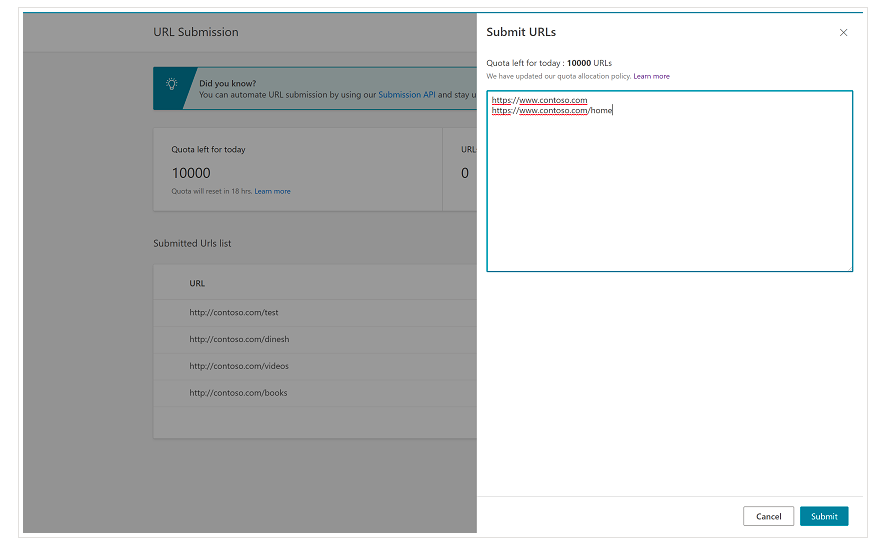
此功能對於批量提交 URL 確實非常方便,因為您只需要從 Bing 網站管理員工具的正常界面在 URL 提交工具中的不同行中引入您的 URL。
1.2.1。 必應索引 API
Bing Indexing API 可以與需要作為參數引入的 API 密鑰一起使用。 此 API 密鑰可以在 Bing 網站管理員工具上獲取,進入 API 訪問部分,然後生成 API 密鑰。
獲取 API 密鑰後,我們可以使用以下代碼來使用 API(您只需要添加 API 密鑰和站點 URL):
導入請求
list_urls = ["https://www.example.com", "https://www.example/test2/"]
對於 list_urls 中的 y:
url = 'https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=yourapikey'
myobj = '{"siteUrl":"https://www.example.com", "urlList":["'+ str(y) +'"]}'
headers = {'內容類型':'應用程序/json; 字符集=utf-8'}
x = requests.post(url, data=myobj, headers=headers)
打印(str(y)+“:”+str(x))這將在每次迭代時打印 URL 及其響應代碼。 與 Google Indexing API 相比,此 API 可用於任何類型的網站。
[案例研究] 通過提高 Googlebot 的網站可抓取性來提高知名度
 閱讀案例研究
閱讀案例研究2. 站點地圖分析、創建和上傳
眾所周知,站點地圖是非常有用的元素,可以為搜索引擎機器人提供我們希望它們抓取的 URL。 為了讓搜索引擎機器人知道我們的站點地圖在哪裡,它們應該被上傳到谷歌搜索控制台和必應網站管理員工具,並包含在 robots.txt 文件中以供其他機器人使用。
使用 Python,我們主要可以處理與站點地圖相關的三個不同方面:它們的分析、創建以及從 Google Search Console 上傳和刪除。
2.1。 使用 Python 導入和分析站點地圖
Advertools 是由 Elias Dabbas 創建的一個很棒的庫,可用於站點地圖導入以及許多其他 SEO 任務。 您只需使用以下命令即可將站點地圖導入數據框:
sitemap_to_df('https://example.com/robots.txt', recursive=False)
該庫支持常規 XML 站點地圖、新聞站點地圖和視頻站點地圖。
另一方面,如果您只對從站點地圖導入 URL 感興趣,您也可以使用庫請求和 BeautifulSoup。
導入請求
從 bs4 導入 BeautifulSoup
r = requests.get("https://www.example.com/your_sitemap.xml")
xml = r.text
湯 = BeautifulSoup(xml)
urls = soup.find_all("loc")
urls = [[x.text] for x in urls]
導入站點地圖後,您可以使用提取的 URL 並按照 Koray Tugberk 在本文中的說明執行內容分析。
2.2. 使用 Python 創建站點地圖
正如 JC Chouinard 在本文中所解釋的那樣,您還可以利用 Python 從 URL 列表中創建 sitemaps.xml。 這對於 URL 快速變化的非常動態的網站特別有用,並且與上面解釋的 ping 方法一起,它可以是一個很好的解決方案,為 Google 提供新的 URL 並讓它們快速被抓取和索引。
最近,Greg Bernhardt 還用 Streamlit 和 Python 創建了一個 APP 來生成站點地圖。
2.3. 從 Google Search Console 上傳和刪除站點地圖
Google Search Console 有一個 API,主要可用於兩種不同的方式:提取有關 Web 性能的數據和處理站點地圖。 在這篇文章中,我們將重點介紹上傳和刪除站點地圖的選項。
首先,從 Google Cloud Console 創建或使用現有項目以獲取 OUATH 憑據並啟用 Google Search Console 服務非常重要。 JC Chouinard 在本文中很好地解釋了使用 Python 訪問 Google Search Console API 所需遵循的步驟以及如何發出第一個請求。 基本上,我們可以完全利用他的代碼,但只有通過引入更改,在範圍內我們將添加“https://www.googleapis.com/auth/webmasters”而不是“https://www.googleapis.com” /auth/webmasters.readonly”,因為我們不僅會使用 API 來讀取站點地圖,還會使用它來上傳和刪除站點地圖。

一旦我們連接到 API,我們就可以開始使用它,並使用下一段代碼列出我們 Google Search Console 屬性中的所有站點地圖:
對於已驗證站點 URL 中的站點 URL:
打印(site_url)
# 檢索提交的站點地圖列表
站點地圖 = webmasters_service.sitemaps().list(siteUrl=site_url).execute()
如果站點地圖中有“站點地圖”:
sitemap_urls = [s['path'] for s in sitemaps['sitemap']]
打印 (" " + "\n ".join(sitemap_urls))
對於特定的站點地圖,我們可以執行三個任務,我們將在下一節中詳細說明:上傳、刪除和請求信息。
2.3.1。 上傳站點地圖
要使用 Python 上傳站點地圖,我們只需要指定站點 URL 和站點地圖路徑並運行以下代碼:
網站 = '您的 GSC 財產' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().submit(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.2. 刪除站點地圖
硬幣的另一面是當我們想要刪除站點地圖時。 我們還可以使用 Python 使用“刪除”方法而不是“提交”方法從 Google Search Console 中刪除站點地圖。
網站 = '您的 GSC 財產' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().delete(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.3。 從站點地圖請求信息
最後,我們還可以使用“get”方法從站點地圖請求信息。
網站 = '您的 GSC 財產' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().get(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
這將返回 JSON 格式的響應,例如: 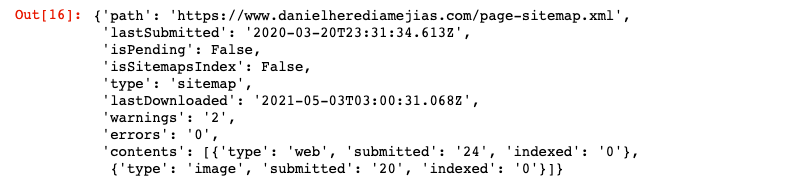
3. 內部鏈接分析和機會
擁有適當的內部鏈接結構對於促進搜索引擎機器人抓取您的網站非常有幫助。 通過審核許多具有非常複雜的技術設置的網站,我遇到的一些主要問題是:
- 通過點擊事件引入的鏈接:簡而言之,Googlebot 不會點擊按鈕,因此如果您的鏈接是通過點擊事件插入的,Googlebot 將無法跟踪它們。
- 客戶端渲染鏈接:儘管 Googlebot 和其他搜索引擎在執行 JavaScript 方面變得越來越好,但這對他們來說仍然是相當具有挑戰性的,因此最好在服務器端渲染這些鏈接並將它們提供為原始 HTML 以搜索引擎機器人比期望它們執行 JavaScript 腳本。
- 登錄和/或年齡限制彈出窗口:登錄彈出窗口和年齡限制可以防止搜索引擎機器人抓取這些“障礙”背後的內容。
- Nofollow 屬性過度使用:使用許多指向有價值的內部頁面的 nofollow 屬性將阻止搜索引擎機器人抓取它們。
- Noindex 和 follow:從技術上講,noindex 和 follow 指令的組合應該讓搜索引擎機器人抓取該頁面上的鏈接。 但是,Googlebot 似乎會在一段時間後停止使用 noindex 指令抓取這些頁面。
使用 Python,我們可以分析我們的內部鏈接結構,並在批量模式下找到新的內部鏈接機會。
3.1。 使用 Python 進行內部鏈接分析
幾個月前,我寫了一篇關於如何使用 Python 和庫 Networkx 來創建圖形,以非常直觀的方式顯示內部鏈接結構的文章:
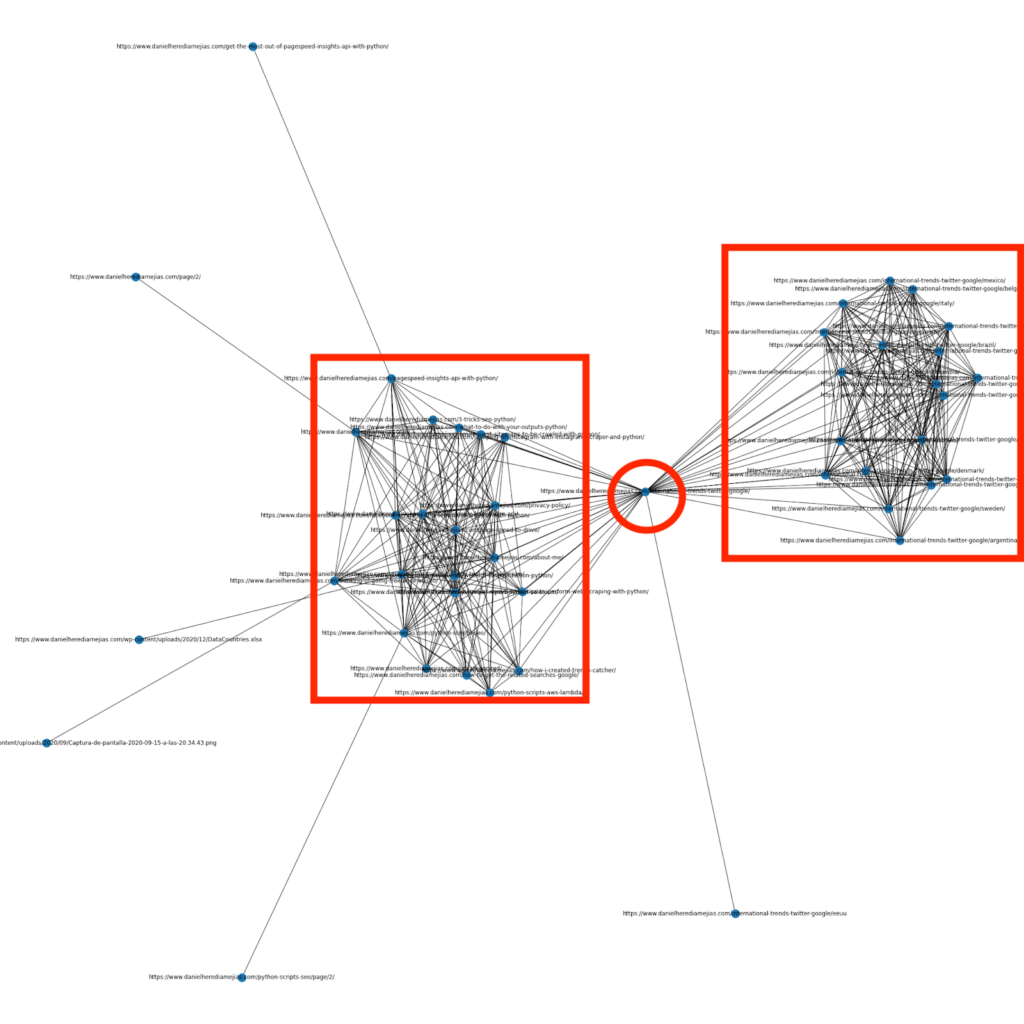
這與您可以從 Screaming Frog 獲得的內容非常相似,但使用 Python 進行此類分析的優勢在於,基本上您可以選擇要包含在這些圖表中的數據並控制大多數圖表元素,例如作為顏色、節點大小甚至是您想要添加的頁面。
3.2. 使用 Python 尋找新的內部鏈接機會
除了分析站點結構外,您還可以利用 Python 通過提供許多關鍵字和 URL 並遍歷這些 URL 來查找新的內部鏈接機會,以在其內容片段中搜索提供的術語。
這可以很好地與 Semrush 或 Ahrefs 導出一起使用,以便從一些已經為關鍵字排名的頁面中找到強大的上下文內部鏈接,因此已經具有某種類型的權限。
您可以在此處閱讀有關此方法的更多信息。
4. 網站速度、5xx 和軟錯誤頁面
正如 Google 在此頁面上關於抓取預算對 Google 的意義所述,讓您的網站更快可以改善用戶體驗並提高抓取速度。 另一方面,還有其他可能影響抓取預算的因素,例如軟錯誤頁面、低質量內容和現場重複內容。
4.1。 頁面速度和 Python
4.2.1 用 Python 分析你的網站速度
Page Speed Insights API 非常有用,可以分析您的網站在頁面速度方面的表現,並獲取有關許多不同頁面速度指標(近 50 個)以及 Core Web Vitals 的大量數據。
使用 Python 使用 Page Speed Insights 非常簡單,只需一個 API 密鑰和請求即可使用它。 例如:
導入 urllib.request, json url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=your_URL&strategy=mobile&locale=en&key=yourAPIKey" #注意,您可以插入帶有參數 URL 的 URL,如果您想獲取桌面數據,還可以修改設備參數。 響應 = urllib.request.urlopen(url) 數據 = json.loads(response.read())
此外,您還可以使用 Python 和 Lighthouse 評分計算器預測在進行請求的更改以提高頁面速度的情況下,您的整體性能得分會提高多少,如本文所述。
4.2.2 使用 Python 進行圖像優化和調整大小
與網站速度相關,Python 還可用於優化、壓縮和調整圖像大小,如 Koray Tugberk 和 Greg Bernhardt 撰寫的這些文章中所述:
- 通過 FTP 使用 Python 自動進行圖像壓縮。
- 使用 Python 批量調整圖像大小。
- 通過 Python 為 SEO 和 UX 優化圖像。
4.2. 使用 Python 提取 5xx 和其他響應代碼錯誤
5xx 響應代碼錯誤可能表明您的服務器速度不夠快,無法處理接收到的所有請求。 這會對您的抓取速度產生非常負面的影響,並且還會損害用戶體驗。
為了確保您的網站按預期運行,您可以使用 Python 和 Selenium 自動下載爬網統計報告,並且您可以密切關注您的日誌文件。
4.3. 使用 Python 提取軟錯誤頁面
最近,Jose Luis Hernando 發表了一篇文章以紀念 Hamlet Batista,介紹如何使用 Node.js 自動提取覆蓋率報告。 這可能是提取軟錯誤頁面甚至 5xx 響應錯誤的絕佳解決方案,這些錯誤可能會對您的抓取速度產生負面影響。
我們還可以使用 Python 複製相同的過程,以便僅在一個 Excel 選項卡中編譯 Google Search Console 提供的所有錯誤、有效但有警告、有效和排除的 URL。
首先,我們需要使用 Python 和 Selenium 登錄 Google Search Console,如本文前面所述。 之後,我們將選擇所有 URL 狀態框,每頁最多添加 100 行,我們將開始迭代 GSC 報告的所有類型的 URL 並下載每個 Excel 文件。
進口時間
從硒導入網絡驅動程序
從 webdriver_manager.chrome 導入 ChromeDriverManager
從 selenium.webdriver.common.keys 導入密鑰
驅動程序 = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
時間.sleep(5)
searchBox=driver.find_element_by_xpath('//*[@]')
searchBox.send_keys("<你的郵箱地址>")
searchBox.send_keys(Keys.ENTER)
時間.sleep(5)
searchBox=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
searchBox.send_keys("<你的密碼>")
searchBox.send_keys(Keys.ENTER)
時間.sleep(5)
yourdomain = str(input("在此處插入您的 http 屬性或域。如果是域包括:'sc-domain':"))
driver.get('https://search.google.com/search-console/index?resource_https://search.google.com/search-console/index?resource_Tabla')
listvalues = [list_problems[x] for i in range(len(df1["URL"]))]
df1['Type'] = 列表值
list_results = df1.values.tolist()
別的:
df2 = pd.read_excel(yourdomain.replace("sc-domain:","").replace("/","_").replace(":","_") + "-Coverage-Drilldown-" + 今天 + " (" + str(x) + ").xlsx", 'Tabla')
listvalues = [list_problems[x] for i in range(len(df2["URL"]))]
df2['Type'] = 列表值
list_results = list_results + df2.values.tolist()
df = pd.DataFrame(list_results, columns= ["URL","TimeStamp", "Type"])
df.to_csv('<文件名>.csv', header=True, index=False, encoding = "utf-8")
最終輸出如下所示: 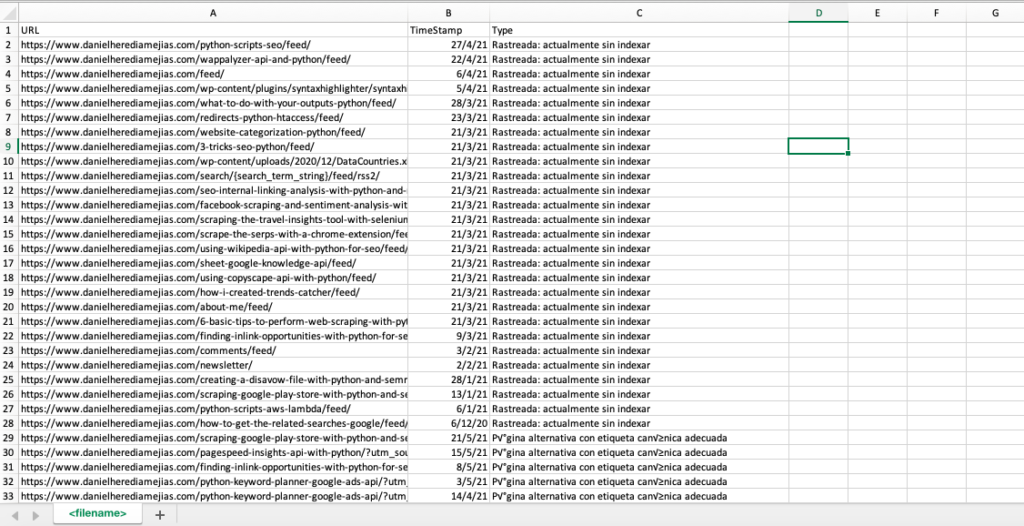
4.4. 使用 Python 進行日誌文件分析
除了 Google Search Console 的抓取統計報告中提供的數據外,您還可以使用 Python 分析您自己的文件,以獲取有關搜索引擎機器人如何抓取您的網站的更多信息。 如果您還沒有使用 SEO 日誌分析器,您可以閱讀 SEO Garden 的這篇文章,其中解釋了使用 Python 進行日誌分析。
[電子書] 利用 SEO 日誌分析的四個用例
免費下載5. 最終結論
我們已經看到,Python 可以成為以多種不同方式分析和改進我們網站的抓取和索引的重要資產。 我們還了解瞭如何通過自動化大多數需要數千小時時間的繁瑣和手動任務來讓生活變得更輕鬆。
我必須說,不幸的是,我並不完全相信谷歌目前提供的請求索引大量 URL 的解決方案,儘管我可以在某種程度上理解它對提供更好解決方案的恐懼:許多 SEO 可能傾向於過度使用它。
與此相反,Bing 提供了卓越而便捷的解決方案,可通過 API 甚至通過 Bing Webmaster Tools 上的普通界面請求 URL 索引。
由於 Google 索引 API 有改進的空間,因此其他元素(例如擁有可訪問和更新的站點地圖、內部鏈接、頁面速度、軟錯誤頁面以及重複和低質量的內容)變得更加重要,以確保您的網站已被正確抓取,並且您最重要的頁面已被編入索引。