
基於 AWS 服務的商業智能管道 – 案例研究
已發表: 2019-05-16近年來,我們看到人們對大數據分析越來越感興趣。 高管、經理和其他業務利益相關者使用商業智能 (BI) 來做出明智的決策。 它使他們能夠立即分析關鍵信息,並不僅根據他們的直覺,而且根據他們可以從客戶的真實行為中學到什麼來做出決策。
當您決定創建一個有效且信息豐富的 BI 解決方案時,您的開發團隊需要做的第一步就是規劃數據管道架構。 有幾種基於雲的工具可用於構建這樣的管道,沒有一種解決方案對所有企業都是最好的。 在決定特定選項之前,您應該考慮您當前的技術堆棧、工具定價以及開發人員的技能組合。 在本文中,我將展示一個使用 AWS 工具構建的架構,該架構已成功部署為 Timesheets 應用程序的一部分。
架構概述
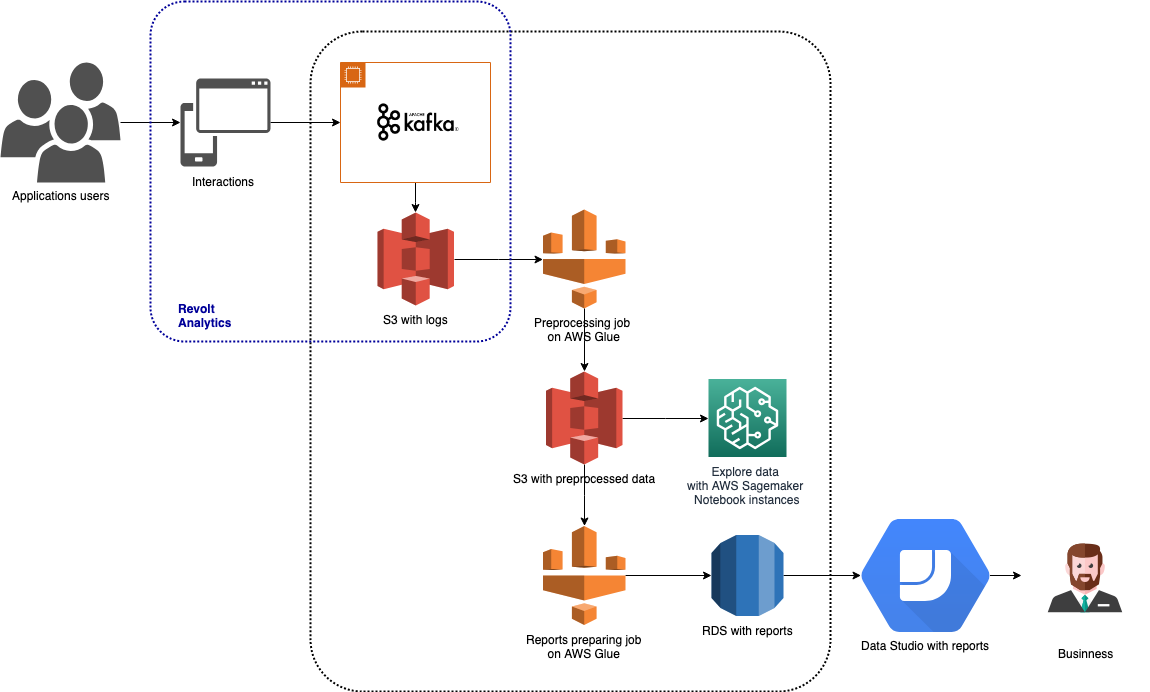
Timesheets 是一種跟踪和報告員工時間的工具。 它可以通過網絡、iOS、Android 和桌面應用程序、與 Hangouts 和 Slack 集成的聊天機器人以及 Google Assistant 上的操作來使用。 由於有許多類型的應用程序可用,因此也有許多不同的數據需要跟踪。 數據通過 Revolt Analytics 收集,存儲在 Amazon S3 中,並使用 AWS Glue 和 Amazon SageMaker 進行處理。 分析結果存儲在 Amazon RDS 中,並用於在 Google Data Studio 中構建可視化報告。 該架構如上圖所示。
在以下段落中,我將簡要介紹此架構中使用的每個大數據工具。
反抗分析
Revolt Analytics 是 Miquido 開發的一種工具,用於跟踪和分析來自所有類型應用程序的數據。 為了簡化客戶端系統中的 Revolt 實現,已經構建了 iOS、Android、JavaScript、Go、Python 和 Java SDK。 Revolt 的關鍵特性之一是它的性能:所有事件都以數據包的形式排隊、存儲和發送,從而確保它們能夠快速有效地傳遞。 Revolt 使應用程序所有者能夠識別用戶並跟踪他們在應用程序中的行為。 這使我們能夠構建帶來價值的機器學習模型,例如完全個性化的推薦系統和流失預測模型,以及基於用戶行為的客戶分析。 Revolt 還提供了會話化功能。 有關應用程序中用戶路徑和行為的知識可以幫助您了解客戶的目標和需求。
Revolt 可以安裝在您選擇的任何基礎設施上。 這種方法使您可以完全控製成本和跟踪事件。 在本文介紹的 Timesheets 案例中,它是基於 AWS 基礎設施構建的。 由於對數據存儲的完全訪問權限,產品所有者可以輕鬆深入了解他們的應用程序並在其他系統中使用該數據。
Revolt SDK 被添加到 Timesheets 系統的每個組件中,其中包括:
- Android 和 iOS 應用程序(使用 Flutter 構建)
- 桌面應用程序(使用 Electron 構建)
- Web 應用程序(用 React 編寫)
- 後端(用 Golang 編寫)
- 環聊和 Slack 在線聊天
- 對 Google 助理的操作
Revolt 為 Timesheets 管理員提供有關應用程序客戶使用的設備(例如設備品牌、型號)和系統(例如操作系統版本、語言、時區)的知識。 此外,它還會發送與用戶在應用程序中的活動相關的各種自定義事件。 因此,管理員可以分析用戶行為,並更好地了解他們的目標和期望。 他們還可以驗證實現的功能的可用性,並評估這些功能是否符合產品負責人關於如何使用它們的假設。

AWS 膠水
AWS Glue 是一項 ETL(提取、轉換和加載)服務,可幫助為分析任務準備數據。 它在 Apache Spark 無服務器環境中運行 ETL 作業。 通常,它由以下三個要素組成:
- 爬蟲定義——爬蟲用於掃描各種存儲庫和源中的數據,對其進行分類,從中提取模式信息,並將有關它們的元數據存儲在數據目錄中。 例如,它可以掃描存儲在 Amazon S3 上 JSON 文件中的日誌,並將其架構信息存儲在數據目錄中。
- 作業腳本– AWS Glue 作業將數據轉換為所需的格式。 AWS Glue 可以自動生成腳本來加載、清理和轉換您的數據。 您還可以提供自己用 Python 或 Scala 編寫的 Apache Spark 腳本,以運行所需的轉換。 它們可能包括處理空值、會話化、聚合等任務。
- 觸發器——爬蟲和作業可以按需運行,也可以設置為在指定觸發器發生時啟動。 觸發器可以是基於時間的計劃或事件(例如,指定作業的成功執行)。 此選項使您能夠輕鬆管理報告中的數據新鮮度。
在我們的 Timesheets 架構中,這部分管道呈現如下:
- 基於時間的觸發器啟動預處理作業,該作業執行數據清理、分配適合會話的事件日誌併計算初始聚合。 此作業的結果數據存儲在 AWS S3 上。
- 第二個觸發器設置為在預處理作業完成並成功執行後運行。 此觸發器啟動一項準備數據的作業,這些數據直接用於產品負責人分析的報告中。
- 第二個作業的結果存儲在 AWS RDS 數據庫中。 這使得它們可以在 Google Data Studio、PowerBI 或 Tableau 等商業智能工具中輕鬆訪問和使用。
AWS SageMaker
Amazon SageMaker 提供用於構建、訓練和部署機器學習模型的模塊。
它允許以任何規模訓練和調整模型,並支持使用 AWS 提供的高性能算法。 儘管如此,您也可以在提供適當的 docker 映像後使用自定義算法。 AWS SageMaker 還通過比較不同模型參數集的指標的可配置作業來簡化超參數調整。
在 Timesheets 中,SageMaker Notebook Instances 幫助我們探索數據、測試 ETL 腳本並準備可視化圖表的原型,以在 BI 工具中用於創建報告。 該解決方案支持並改進了數據科學家的協作,因為它確保他們在相同的開發環境中工作。 此外,這有助於確保沒有敏感數據(可能是筆記本單元輸出的一部分)存儲在 AWS 基礎設施之外,因為筆記本只存儲在 AWS S3 存儲桶中,並且不需要 git 存儲庫來在同事之間共享工作.
包起來
決定使用哪些大數據和機器學習工具對於為商業智能解決方案設計管道架構至關重要。 這種選擇會對系統功能、成本以及將來添加新功能的難易程度產生重大影響。 AWS 工具當然值得考慮,但您應該選擇適合您當前技術堆棧和開發團隊技能的技術。
利用我們在構建面向未來的解決方案方面的經驗並聯繫我們!