
Breadcrumb SEO、Python 3 和 Oncrawl:走向自動化!
已發表: 2021-04-14讓我們學習如何使用 OnCrawl 和 Python 3 自動創建基於麵包屑的分割。
Oncrawl 中的分段是什麼?
Oncrawl 使用分段將一組頁面分成組。 這使得分析抓取報告、日誌分析和其他交叉分析報告中的數據變得非常容易,這些報告將抓取數據與穀歌分析、谷歌搜索控制台、AT Internet、Adobe Analytics 或 Majestic 用於反向鏈接。
為什麼創建細分很重要?
爬網完成後,創建自定義細分是最重要的事情。 這使您可以從最適合您的站點及其結構的角度閱讀分析。
有很多方法可以分割您網站的頁面,並且沒有正確或錯誤的方法。 例如,可以根據 URL 結構跟踪您網站的結構。
例如,這種 URL “ https://www.mydomain.com/news/canada/politics ”,很容易被分割成這樣:
- 一個用來隔離主頁的組
- 所有新聞的群組
- 加拿大目錄的子組
- 政治目錄的子組
如您所見,可以為您的細分創建多達 3 個深度級別。 這使您可以專注於 SEO 分析中的某些組或子組,而無需切換細分。
如何創建基本細分?
您應該知道 Oncrawl 自己負責創建第一個分段。 這基於 URL 中遇到的“第一個路徑”或第一個目錄。
這使您可以在爬網完成後立即進行分析。
可能是這種細分沒有反映您網站的結構,或者您想從不同的角度分析事物。
因此,您將使用我們所說的 OQL(代表 Oncrawl 查詢語言)創建一個新的分段。 它有點像 SQL,只是更簡單、更直觀: 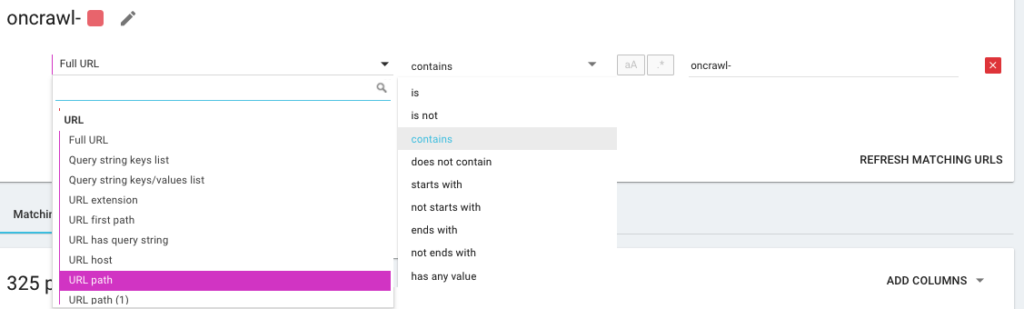
也可以盡可能精確地使用 AND/OR 條件運算符: 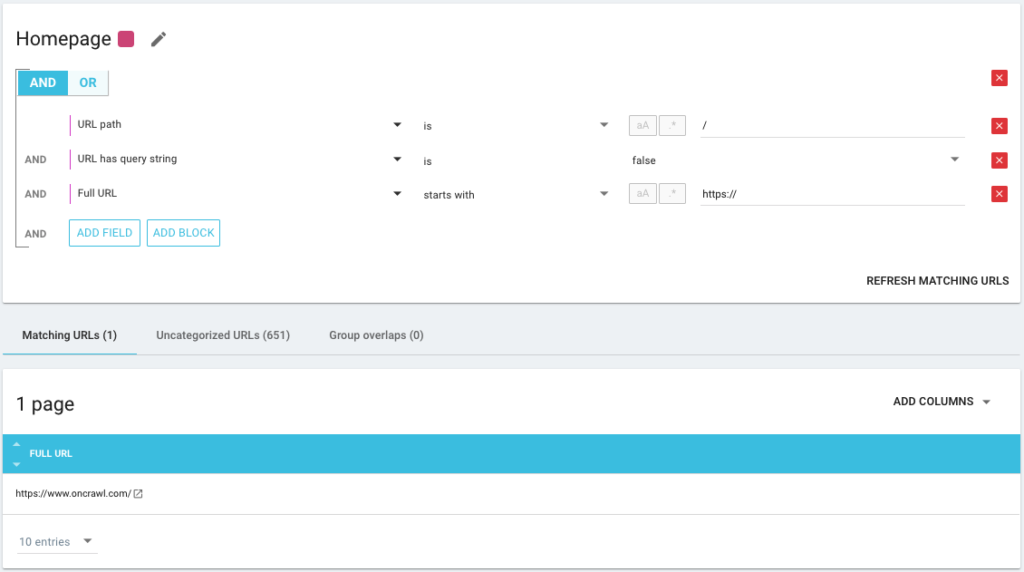
使用不同的方法分割我的頁面
使用其他 KPI
基於 URL 的分段很好,但如果我們還可以結合其他 KPI 就更完美了,例如對以/car-rental/開頭且 H1 具有“汽車租賃機構”表達的 URL 和另一個 H1 所在的組進行分組“公用事業租賃公司”,這可能嗎?
是的,有可能! 在創建細分期間,您可以使用我們使用的所有 KPI,不僅來自爬蟲的 KPI,還有來自連接器的 KPI。 這使得細分的創建非常強大,並允許您擁有完全不同的分析角度!
例如,借助 Google Search Console 連接器,我喜歡使用 URL 的平均位置創建分段。
通過這種方式,我可以輕鬆識別結構深處仍在執行的 URL,或者靠近我的主頁的位於 Google 第 2 頁上的 URL。
我可以查看這些頁面是否有重複的內容、一個空的標題標籤、是否接收到足夠的鏈接……我還可以查看 Googlebot 在這些頁面上的行為。 爬行頻率是好是壞? 簡而言之,它可以幫助我確定優先級並做出對我的 SEO 和 ROI 產生真正影響的決策。
抓取數據³
 學到更多
學到更多使用數據攝取
如果您不熟悉我們的數據攝取功能,我邀請您先閱讀有關該主題的這篇文章。 這是另一個非常強大的工具,允許您將外部數據源添加到 Oncrawl。
例如,您可以添加來自 SEMrush、Ahrefs、Babbar.tech 的數據……優點是您可以根據從這些工具中獲取的指標對頁面進行分組,並根據您感興趣的數據進行分析,即使它不是原生於 Oncrawl。
最近,我與一家全球酒店集團合作。 他們使用內部評分方法來了解酒店記錄是否填寫正確,是否有圖像、視頻、內容等……他們確定完成百分比,我們用它來交叉分析爬網和日誌文件數據。
結果讓我們知道 Googlebot 是否在正確填充的頁面上花費更多時間,知道分數超過 90% 的某些頁面是否太深,沒有收到足夠的鏈接……得分,頁面獲得的訪問次數越多,Google 探索的次數越多,它們在 Google SERP 中的位置就越好。 鼓勵酒店經營者填寫酒店清單的不可阻擋的論據!
根據 SEO 麵包屑跟踪創建細分
這是本文的主題,所以讓我們進入問題的核心。 如果 URL 的結構沒有將頁面附加到某個目錄,則有時很難對站點的頁面進行分段。 這通常是電子商務網站的情況,其中產品頁面都位於根目錄。 因此,不可能從 URL 中知道頁面屬於哪個組。
為了將頁面組合在一起,我們必須找到一種方法來識別它們所屬的組。 因此,我們有了檢索每個 URL 的麵包屑 seo 跟踪的想法,並使用 Oncrawl 提供的 Scraper 功能根據麵包屑 seo 中的值對它們進行分類。
使用 Oncrawl 進行 SEO 麵包屑抓取
正如我們在上面看到的,我們將設置一個抓取規則來檢索麵包屑路徑。 大多數時候它很簡單,因為我們可以去檢索一個div中的信息,然後每個級別的字段都在ul和li列表: 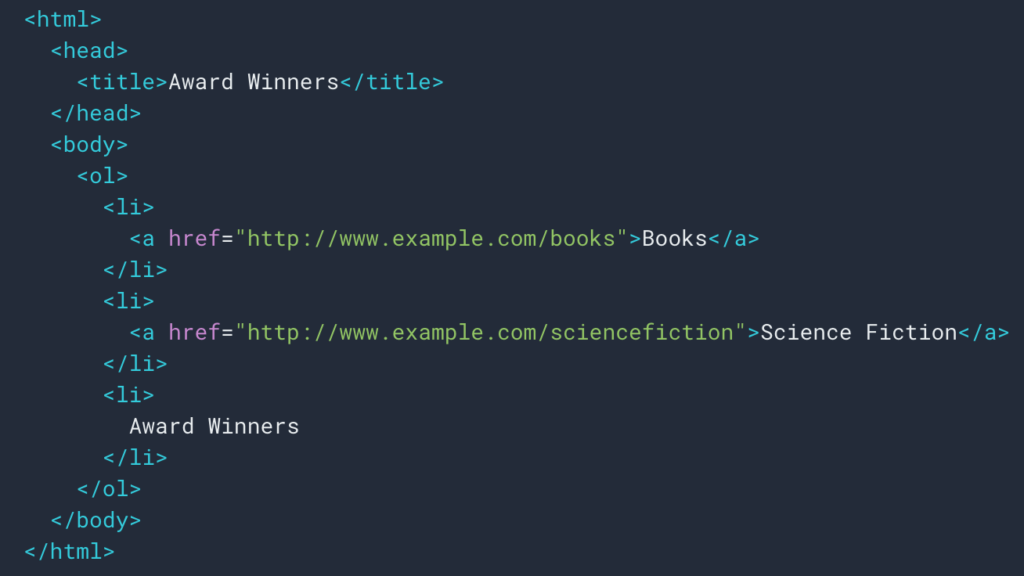
由於結構化數據類型麵包屑,有時我們也可以輕鬆檢索信息。 因此,很容易檢索每個位置的“名稱”字段的值。 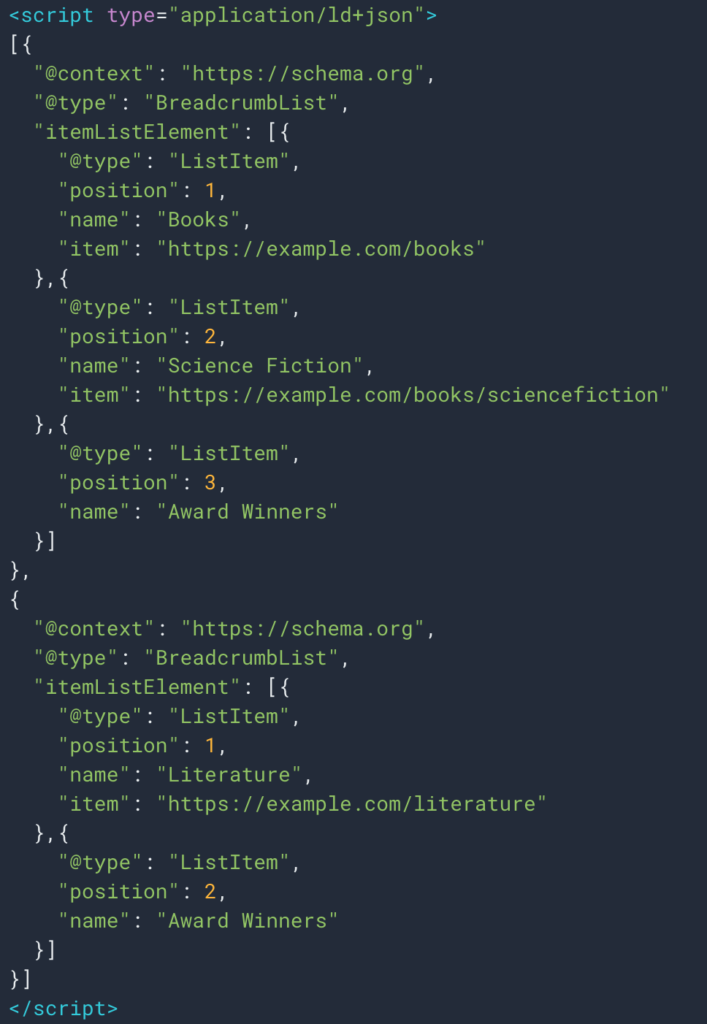
這是我使用的抓取規則的示例: 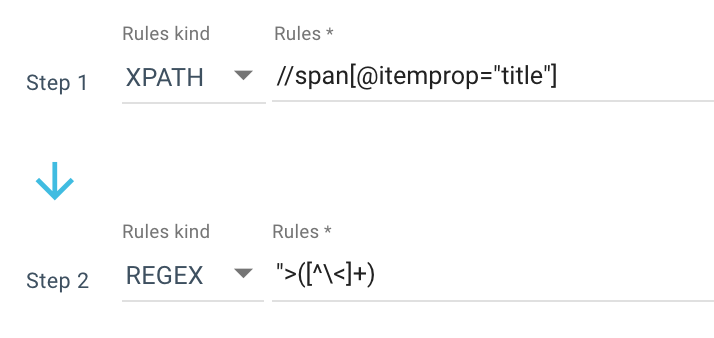
或者這條規則: //li[contains(@class, "current-menu-ancestor") or contains(@class, "current-menu-parent") or contains(@class, "current-menu-item")]/a/text()
所以我用 Xpath 獲得了所有span itemprop=”title” ,然後使用正則表達式提取“>之後不是>字符的所有內容。 如果您想了解更多關於 Regex 的信息,我建議您閱讀有關該主題的這篇文章和我們的 Regex 備忘單。
我得到幾個這樣的值作為輸出: 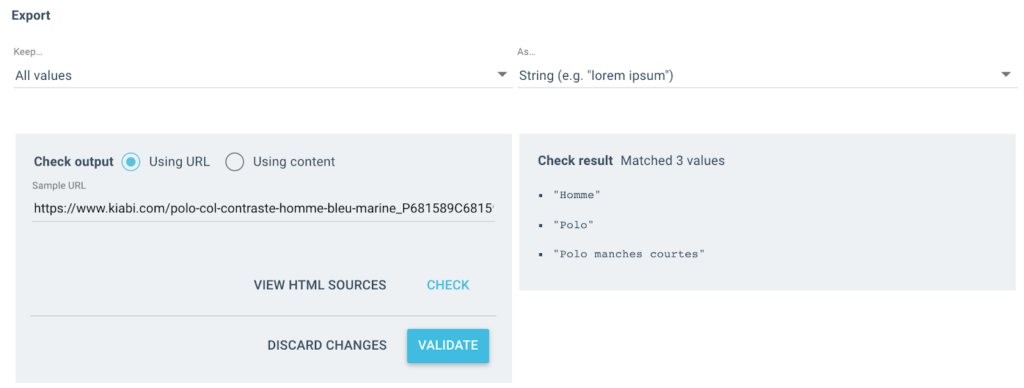
對於測試的 URL,我將有一個包含 3 個值的“麵包屑”字段:

- 男人
- Polo衫
- 短袖馬球
導入json
隨機導入
導入請求
# 認證
# 兩種方式,使用 x-oncrawl-token 可以從瀏覽器獲取請求標頭
# 或者在這裡使用 api 令牌:https://app.oncrawl.com/account/tokens
API_ACCESS_TOKEN = ' '
# 在有麵包屑自定義字段的地方設置爬取id
爬行_
# 更新分割中你不想得到的禁止麵包屑項
FORBIDDEN_BREADCRUMB_ITEMS = ('Accueil',)
FORBIDDEN_BREADCRUMB_ITEMS_LIST = [
v.strip()
對於 FORBIDDEN_BREADCRUMB_ITEMS.split(',') 中的 v
]
定義隨機顏色():
random_number = random.randint(0, 16777215)
hex_number = str(hex(random_number))
hex_number = hex_number[2:].ljust(6, '0')
返回 f'#{hex_number}'
def value_to_group(值):
返回 {
“顏色”:隨機顏色(),
“名稱”:值,
'oql': {'or': [{'field': ['custom_Breadcrumb', 'equals', value]}]}
}
def walk_dict(字典,級別=0):
回复 = {
“圖標”:“儀表板”,
“轉座”:錯誤,
“名稱”:“麵包屑”
}現在已經定義了規則,我可以啟動我的爬網,Oncrawl 將自動檢索麵包屑值並將它們與每個爬網的 URL 相關聯。
使用 Python 自動創建多級分割
現在我已經有了每個 URL 的所有 SEO 麵包屑值,我們將在 Google Colab 中使用seo 自動化 python腳本來自動創建與 Oncrawl 兼容的分段。
對於腳本本身,我們使用 3 個庫,它們是:
- json(生成我們用 Json 編寫的分段)
- CSV
- 隨機(為每組生成十六進制顏色代碼)
腳本啟動後,它會自動負責在您的項目中創建分段! 
分析中的數據預覽
現在我們的分割已經創建,可以使用基於我的麵包屑跟踪的分割視圖訪問不同的分析。 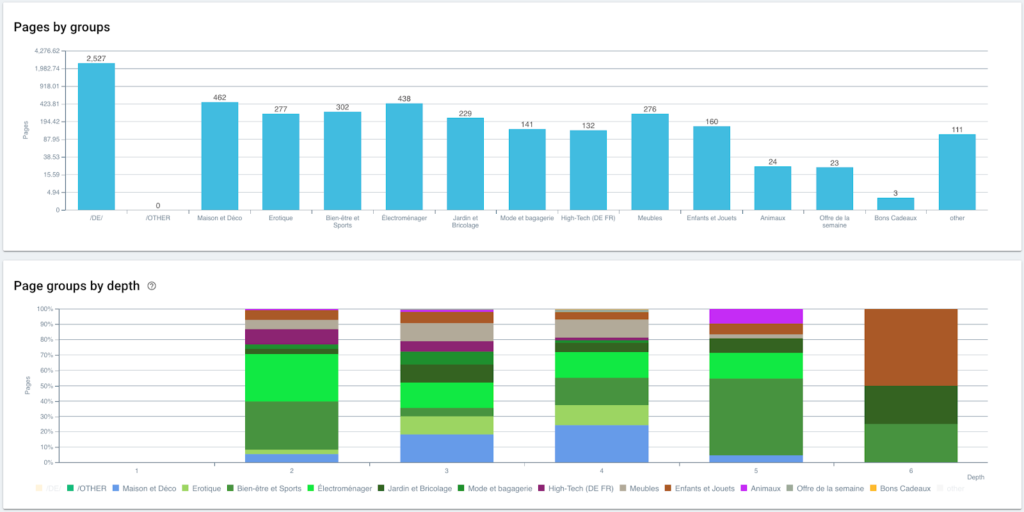
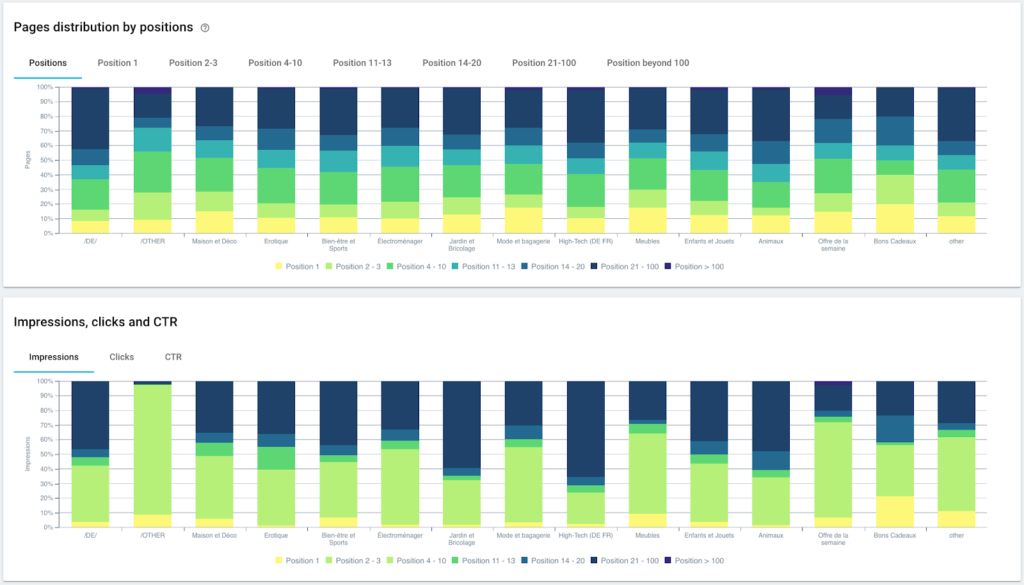
按組和深度分佈頁面
排名表現(GSC)
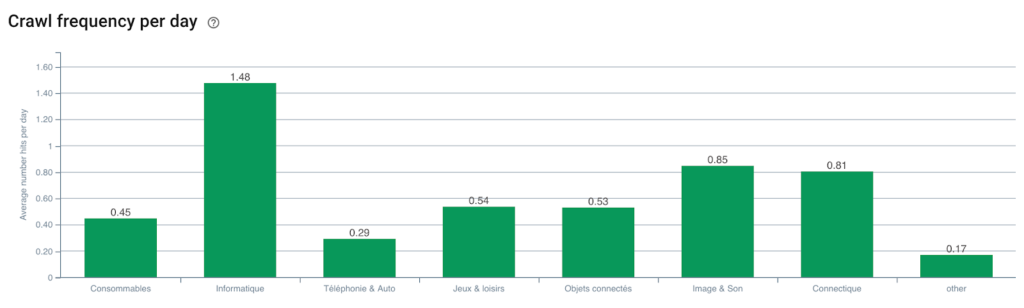
Googlebot 抓取頻率
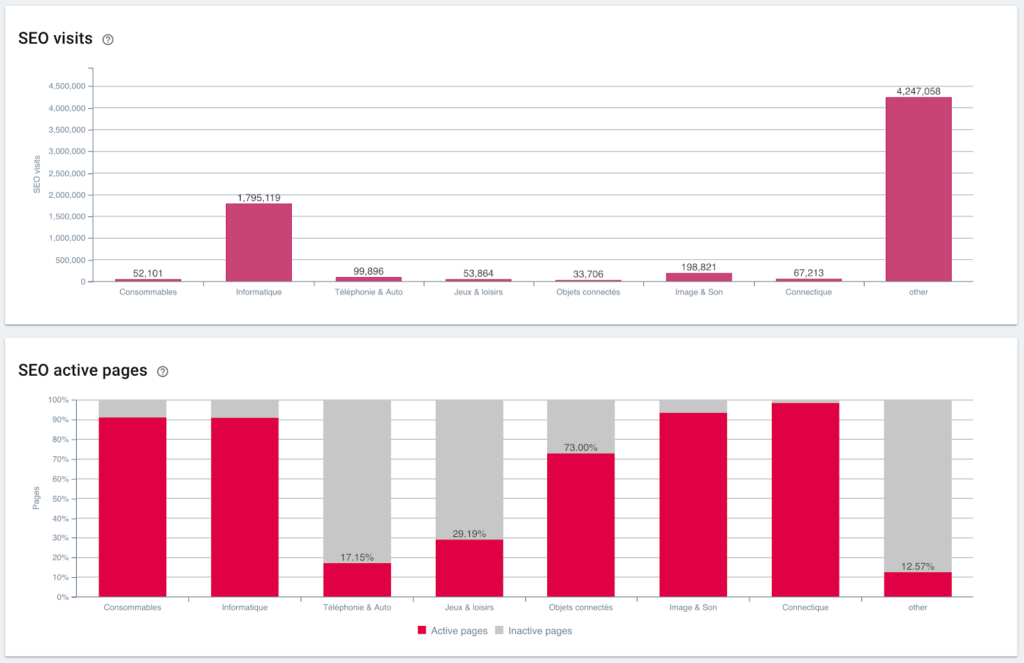
SEO訪問和活躍頁面比率
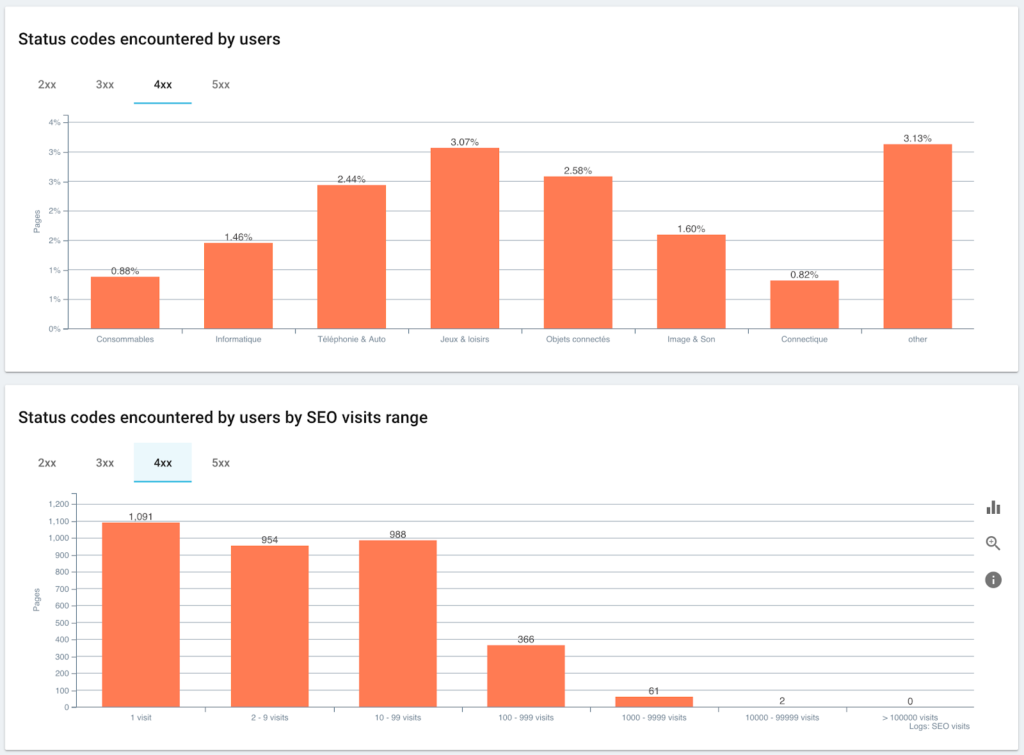
用戶遇到的狀態代碼與 SEO 會話
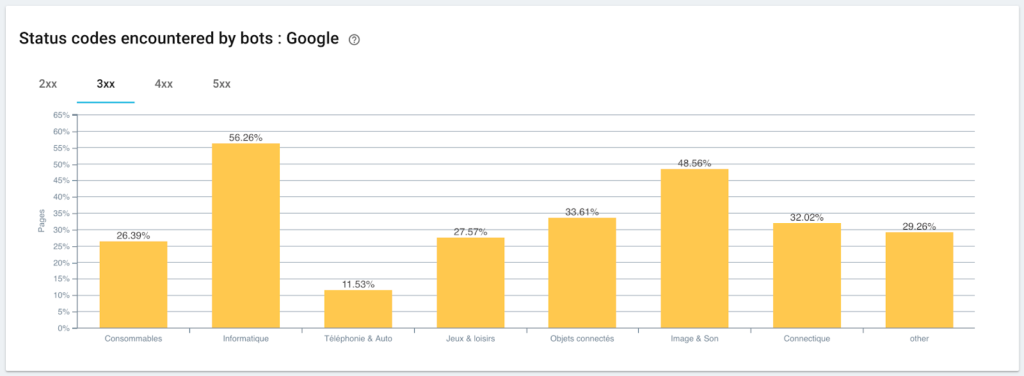
監控 Googlebot 遇到的狀態碼
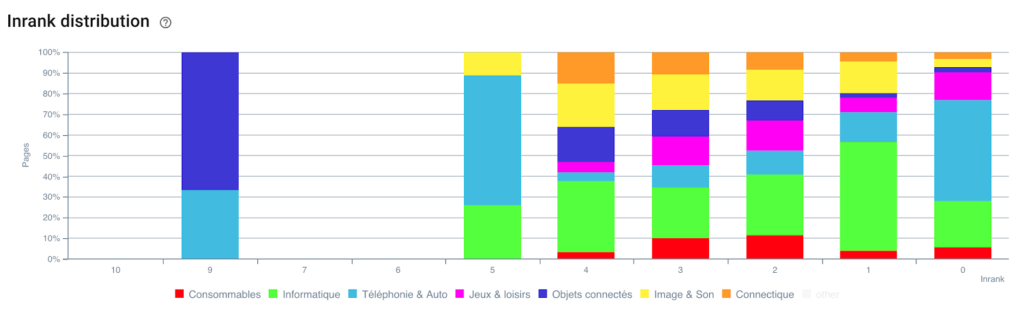
排名的分佈
在這裡,由於使用 Python 和 OnCrawl 的腳本,我們剛剛自動創建了一個分段。 現在所有頁面都根據麵包屑路徑分組,並且分為 3 個深度級別: 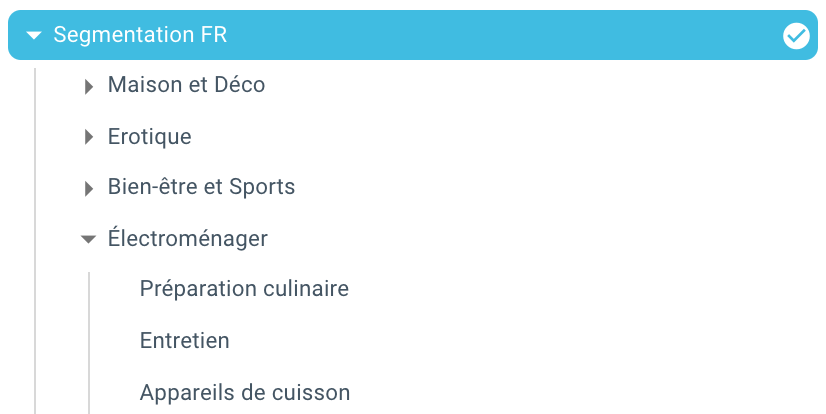
優點是我們現在可以監控每個頁面組和子組的不同 KPI(抓取、深度、內部鏈接、抓取預算、SEO 會話、SEO 訪問、排名表現、加載時間)。
Oncrawl 的 SEO 未來
您可能認為擁有這種“開箱即用”的功能很棒,但您不一定有時間做這一切。 好消息是,我們正在努力在不久的將來直接集成此功能。
這意味著您很快就可以通過簡單的點擊在任何報廢的字段或Data Ingest的字段上自動創建分段。 這將為您節省大量時間,同時允許您執行令人難以置信的橫截面 SEO 分析。
想像一下,能夠從頁面的源代碼中抓取任何數據或為每個 URL 集成任何 KPI。 你的想像力是唯一的限制!
例如,您可以檢索產品的銷售價格,並根據價格查看深度、Inrank、反向鏈接、抓取預算。
但我們也可以檢索您的媒體文章作者的姓名,看看誰表現最好,並應用最有效的寫作方法。
我們可以檢索您的產品的評論和評分,並查看最好的產品是否可以通過最少的點擊訪問、是否收到足夠的鏈接、是否有反向鏈接、是否被 Googlebot 很好地抓取等等……
我們可以整合您的業務數據,例如營業額、利潤、轉化率、您的 Google Ads 費用。
現在由您來想像如何交叉引用數據以擴展您的分析並做出正確的 SEO 決策。
您想測試麵包屑路徑上的自動分割嗎? 直接在 Oncrawl 中通過聊天框聯繫我們。
享受你的爬行!