
如何使用 AWS 將機器學習解決方案添加到您的業務中
已發表: 2020-05-13機器學習不斷發展,並在全球經濟中發揮著巨大的作用,因為它允許對大部分數據進行快速和自動分析。
為了讓機器學習技術更接近程序員,亞馬遜目前在其 AWS 平台上提供了 10 多種機器學習和人工智能服務。 借助這些服務,您可以以簡單的方式開始構建模型,從而將您的業務提升到一個新的水平。
這些服務中的大多數都是完全託管的,這意味著要使用它們,您不需要任何機器學習經驗,因為這些工具利用預先訓練的模型來處理數據。 根據您的業務問題,您可以從計算機視覺、自然語言處理、建議和預測等領域的預訓練 ML 服務中進行選擇。 下圖顯示了機器學習解決方案工作流程,以及您可以在每個階段使用的 AWS 工具。
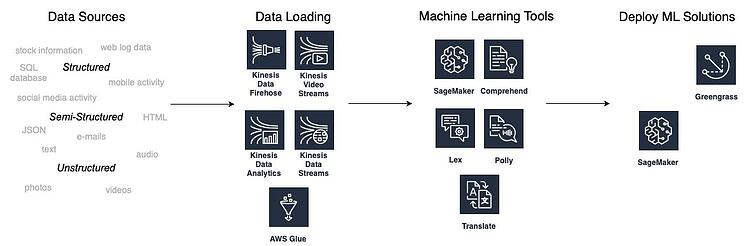
如何通過 AWS 將機器學習應用到業務中
首先:收集數據
創建 ML 解決方案最重要的元素是數據。 有 3 種類型的數據:結構化、半結構化和非結構化。
- 結構化數據的元素是可尋址的,並且可以存儲在關係數據庫中。 這種類型的數據有一個預定義的模式。 結構化數據的一個示例是具有數字和字符串(文本)數據的關係數據庫。
- 半結構化數據集不駐留在關係數據庫中,但它們仍然具有一些預定義的元素(模式),使它們更易於分析。 半結構化數據文件類型的示例是 XML、HTML、RDF 或 JSON。
- 非結構化數據就是其他一切。 這種數據類型沒有預定義的結構,它們通常存儲為一組文件。 最流行的非結構化數據示例是文本文檔、照片、視頻和音頻文件以及應用程序日誌。
數據加載——什麼是 Kinesis?
AWS Kinesis服務攝取可以從各種來源(例如 Web 和移動應用程序)連續生成的數據。 它是一種實時數據流服務,可以非常快速地捕獲千兆字節的數據。 Kinesis提供以下工具:
- Kinesis Video Streaming – 一種可以幫助您將視頻從設備流式傳輸到 AWS 的工具
- Kinesis Data Streaming – 一種可幫助您收集 IT 日誌、網站點擊或金融交易等數據的工具
- Kinesis Data Firehose – 一種將流式數據加載到數據存儲(例如 S3、Redshift)或分析工具中的工具
- Kinesis Data Analytics – 一種使用 SQL 或 Java 實時處理流數據的工具
數據加載——什麼是膠水?
另一項可以幫助加載數據的 AWS 服務是由 Apache Spark 管理的Glue 。 它是一種提取、轉換和加載工具 (ETL),可用於在用於分析之前準備數據。 Glue 可以處理結構化和半結構化數據。
Glue 的元素是數據目錄、ETL 引擎和調度程序。 Glue 數據目錄是該工具最重要的部分。 它保存有關給定數據的元數據,這些元數據由遍歷數據源並檢測其架構的爬蟲自動發現。
ETL 引擎可以生成 Python 和 Scala 代碼,以供非編程用戶在 ETL 過程中使用。 它還可以使用用戶提供的代碼處理數據。 調度程序可以監控作業、運行任務,並根據某些事件(例如在每週一的特定時間,或者當另一個任務完成或失敗時)觸發它們。
其次:選擇正確的機器學習工具
在我們收集到所需的數據後,我們可以開始構建我們的 ML 解決方案。 AWS 提供了一些機器學習工具,可以處理各種類型的數據。
現在讓我們來看看這些工具中的每一個,並介紹它們在商業中可能的主要應用領域。
什麼是 SageMaker?
SageMaker對機器學習開發人員和數據科學家最有用。 該服務是一個完整的解決方案,可幫助您輕鬆地將機器學習模型從概念轉變為生產。 Amazon SageMaker 擁有一套豐富的工具(Ground Truth、Notebooks、Experiments、Debugger、Model Monitor、Neo),可以幫助標記數據、構建、優化、訓練、測試和部署模型。
為給定問題手動找到正確的算法通常需要數小時的訓練和測試。 SageMaker 有一個 AutoPilot 選項,它使用 50 種不同的預訓練 ML 模型來自動找到適合手頭案例的最佳 ML 模型。 開發人員可以使用該解決方案快速找到基線模型。
什麼是個性化?
Personalize是一種機器學習服務,可幫助構建推薦系統。 Personalize 可以處理來自應用程序的活動流,例如點擊、頁面瀏覽、購買,並使用它們來創建個性化推薦。 您還可以使用有關用戶的其他信息,例如年齡或地理位置。 通過簡短的 API 調用可以簡化在應用程序中顯示推薦結果。 多年來,Amazon.com 對 Personalize 中的機器學習技術進行了改進。

什麼是領悟?
Comprehend是一項自然語言處理 (NLP) 服務,它使用機器學習從非結構化文本數據中提取有價值的見解。 該服務應用情感分析、詞性提取和標記化來檢測文本的關鍵特徵。 理解有助於理解給定文本的積極或消極程度。
Comprehend 有一個額外的工具:Amazon Comprehend Medical,專門用於醫療行業。 Amazon Comprehend Medical 可以分析醫療文檔(如患者的醫療記錄、臨床記錄)並提取有關藥物、劑量和頻率的信息。 Comprehend 是一項完全託管的服務。
什麼是預測?
Forecast使用機器學習來構建時間序列預測模型。 它可以將歷史時間序列數據與其他變量(您認為這些變量可能會影響預測)結合起來構建預測模型。 此亞馬遜解決方案適用於預測股票價格或客戶產品需求等價值。 預測也是一項完全託管的服務,可以根據業務需求進行擴展。
什麼是萊克斯?
Lex使用自動語音識別 (ASR) 將語音轉換為文本,並使用自然語言理解 (NLU) 來識別文本的意圖。 該解決方案使用戶能夠構建對話機器人。
例如,您可以使用 Lex 作為手動客戶支持的替代品,它會自動回答客戶查詢。 Amazon Lex 使用與 Amazon Alexa(亞馬遜的虛擬助手 AI)相同的深度學習技術。
什麼是波莉?
Polly是一種雲服務,它使用深度學習算法將文本轉換為逼真的語音。 它目前支持 29 種語言的 60 種男性和女性聲音,包括日語、漢語、韓語和阿拉伯語。 Polly 還可以處理時間、日期、單位、分數和縮寫。 該解決方案允許用戶創建可以說話的應用程序。
什麼是欺詐檢測器?
Fraud Detector是一項 AWS 服務,可幫助識別欺詐性在線活動,例如付款欺詐或虛假賬戶。 該服務是完全託管的,因此只需單擊幾下即可創建欺詐檢測模型。
什麼是文本?
Textract是一種可以自動從掃描文檔中讀取數據的服務。 Textract 可以在幾個小時內處理數百萬頁,並且可以幫助自動化文檔工作流程。 該服務在處理貸款申請或醫療文件等文件時很有用。
什麼是翻譯?
Translate是一種 AWS 機器學習服務,可用於執行語言到語言的文本翻譯。 與傳統的統計算法相比,它使用深度學習模型來提供更準確、更自然的翻譯。 Translate 支持 54 種語言(包括南非荷蘭語、保加利亞語、愛沙尼亞語)和 2,804 種語言對。
什麼是識別?
Rekognition是一種計算機視覺服務,可以識別圖像和電影中的對象、人物和文本。 Rekognition 能夠識別和比較面部,分析它們並識別一些面部特徵,如嘴巴、鼻子或眼睛。
Rekognition 有一個模塊可以自動檢測面部圖像中的快樂、悲傷或驚訝等情緒。 它還可以執行用戶面部驗證,通過將實時圖像與存儲的參考圖像進行比較來確認用戶的身份。
第三:部署機器學習解決方案
部署模型最廣泛使用的方法是 SageMaker 服務,您可以通過以下兩種方式之一使用它:
- 使用 SageMaker 託管服務設置 HTTPS 端點。 在此解決方案中,客戶端應用程序向 HTTPS 端點發送請求,以從部署的模型中獲取預測。 要使用此解決方案,您必須將其與 Docker 映像一起提供。 如果需要部署多個模型,也可以使用多模型端點。
- 使用 SageMaker 批量轉換,它可以幫助您獲得整個數據集的預測。 要使用批量轉換部署模型,您需要一個 S3 存儲桶來存儲模型、數據集和預測。
部署替代方案是使用AWS IoT Greengrass 。 該服務將 AWS 擴展到物聯網 (IoT) 設備。 使用這項服務,設備可以收集、過濾、處理數據,即使沒有云連接,它們也可以運行 Lambda 函數、Docker 容器並基於 ML 模型執行預測。 當連接到互聯網時,Greengrass 會將所有數據與雲服務同步。
概括
如您所見,Amazon Web Service 提供了一套豐富的工具,可以幫助您為您的業務創建有影響力的機器學習解決方案。 借助 ML AWS 工具,您可以向應用程序添加新功能,例如人臉檢測、聊天機器人、語音識別、社交媒體內容的情緒分析。 AWS 每隔幾個月就會根據新的用例添加新的 ML 服務,這使其成為創建 AI 解決方案的增長最快的平台之一。
使用 Miquido 開發麵向未來的機器學習解決方案!