
自動從文本中提取概念和關鍵詞(第一部分:傳統方法)
已發表: 2022-02-22在 Oncrawl 的研發部門,我們越來越希望增強您網頁的語義內容。 使用機器學習模型進行自然語言處理 (NLP),我們可以詳細比較您的網頁內容、創建自動摘要、完善或更正您的文章標籤、根據您的Google Search Console數據優化內容等。
在之前的文章中,我們談到了從 HTML 頁面中提取文本內容。 這一次,我們想談談從文本中自動提取關鍵字。 本主題將分為兩篇文章:
- 第一個將通過幾個具體示例介紹上下文和所謂的“傳統”方法
- 即將推出的第二個將處理基於轉換器和評估方法的更多語義方法,以便對這些不同的方法進行基準測試
語境
除了標題或摘要之外,還有什麼比使用幾個關鍵字更好的方法來識別文本、科學論文或網頁的內容。 這是識別更長文本的主題和概念的簡單且非常有效的方法。 這也是對一系列文本進行分類的好方法:識別它們並按關鍵字對它們進行分組。 提供科學文章的網站(例如 PubMed 或 arxiv.org)可以根據這些關鍵字提供類別和建議。
關鍵字對於索引非常大的文檔和信息檢索也非常有用,這是搜索引擎眾所周知的專業領域
缺少關鍵詞是科學文章自動分類中經常出現的問題[1]:許多文章沒有指定關鍵詞。 因此,必須找到從文本中自動提取概念和關鍵字的方法。 為了評估一組自動提取的關鍵字的相關性,數據集通常會將算法提取的關鍵字與幾個人提取的關鍵字進行比較。
可以想像,這是搜索引擎在對網頁進行分類時所共有的問題。 更好地理解關鍵字提取的自動化過程可以更好地理解為什麼網頁定位於這樣或這樣的關鍵字。 它還可以揭示語義差距,使其無法為您定位的關鍵字排名。
顯然有幾種方法可以從文本或段落中提取關鍵字。 在第一篇文章中,我們將描述所謂的“經典”方法。
[電子書] 數據 SEO:下一次大冒險
 閱讀電子書
閱讀電子書約束
然而,我們在選擇算法時有一些限制和先決條件:
- 該方法必須能夠從單個文檔中提取關鍵字。 有些方法需要完整的語料庫,即數百甚至數千個文檔。 儘管搜索引擎可以使用這些方法,但它們對單個文檔沒有用處。
- 我們處於無監督機器學習的情況。 我們手頭沒有帶註釋數據的法語、英語或其他語言的數據集。 換句話說,我們沒有數千個已經提取關鍵字的文檔。
- 該方法必須獨立於文檔的域/詞法域。 我們希望能夠從任何類型的文檔中提取關鍵字:新聞文章、網頁等。請注意,一些已經為每個文檔提取了關鍵字的數據集通常是領域特定的醫學、計算機科學等。
- 一些方法基於詞性標註模型,即 NLP 模型通過語法類型識別句子中單詞的能力:動詞、名詞、限定詞。 確定作為名詞而不是限定詞的關鍵字的重要性顯然是相關的。 但是,根據語言的不同,POS 標記模型有時質量非常不均衡。
關於傳統方法
我們區分了所謂的“傳統”方法和最近使用 NLP(自然語言處理)技術的方法,例如詞嵌入和上下文嵌入。 這個主題將在以後的文章中介紹。 但首先,讓我們回到經典方法,我們區分其中兩種:
- 統計方法
- 圖法
統計方法將主要依賴於詞頻及其共現。 我們從簡單的假設開始構建啟發式並提取重要詞:一個非常頻繁的詞,一系列出現多次的連續詞等。基於圖的方法將構建一個圖,其中每個節點可以對應一個詞,一組單詞或句子。 那麼每條弧線都可以表示同時觀察這些詞的概率(或頻率)。
這裡有一些方法:
- 基於統計
- 特遣部隊
- 耙
- 雅克
- 基於圖
- 文本排名
- 主題排名
- 單排
給出的所有示例都使用來自此網頁的文本:Jazz au Tresor : John Coltrane – Impressions Graz 1962。
統計方法
我們將向您介紹 Rake 和 Yake 兩種方法。 在 SEO 環境中,您可能聽說過 TF-IDF 方法。 但由於它需要一個文檔語料庫,我們將不在這里處理它。
耙
RAKE 代表快速自動關鍵字提取。 這個方法在 Python 中有幾個實現,包括 rake-nltk。 每個關鍵詞的得分,也稱為關鍵短語,因為它包含幾個詞,它基於兩個元素:詞的頻率和它們共現的總和。 每個關鍵短語的構成非常簡單,它包括:
- 將文本切割成句子
- 將每個句子切成關鍵詞
在下面的句子中,我們將採用標點符號或停用詞分隔的所有詞組:
就在之前,Coltrane 正在帶領一個五重奏組,Eric Dolphy 在他身邊,而 Reggie Workman 則負責低音提琴。
這可能會導致以下關鍵詞:
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" 。
請注意,停用詞是一系列非常常見的詞,例如“ the ”、“ in ”、“and” or “ it ”。 由於經典方法通常基於單詞出現頻率的計算,因此仔細選擇停用詞很重要。 大多數時候,我們不希望在我們的關鍵詞提案中出現>"to" 、 "the" or "of" 之類的詞。 事實上,這些停用詞與特定的詞彙領域無關,因此與“ jazz ”或“ saxophone ”等詞的相關性要低得多。
一旦我們分離出幾個候選關鍵詞,我們就會根據單詞的頻率和共現給它們打分。 分數越高,關鍵詞應該越相關。
讓我們快速嘗試一下關於 John Coltrane 的文章中的文字。
# rake 的 python 片段 從 rake_nltk 導入耙子 # 假設你已經在 'text' 變量中找到了文章 耙子=耙子(停用詞=FRENCH_STOPWORDS,最大長度=4) rake.extract_keywords_from_text(文本) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
以下是前 5 個關鍵詞:

“奧地利國家公共廣播電台”、“抒情山峰更天堂”、“格拉茨有兩個特點”、“約翰·科爾特蘭次中音薩克斯風”、“唯一錄音版”
這種方法有一些缺點。 第一個是停用詞選擇的重要性,因為它們用於將句子拆分為候選關鍵詞。 二是當keyphrases太長時,往往會因為出現的詞共現而得分較高。 為了限制關鍵短語的長度,我們使用max_length=4設置方法。
雅克
YAKE 代表又一個關鍵字提取器。 此方法基於以下文章 YAKE! 從 2020 年開始,使用多個本地特徵從單個文檔中提取關鍵字。這是一種比 RAKE 更新的方法,RAKE 的作者提出了在 Github 上可用的 Python 實現。
對於 RAKE,我們將依賴詞頻和共現。 作者還將添加一些有趣的啟發式方法:
- 我們將區分小寫單詞和大寫單詞(第一個字母或整個單詞)。 我們將在這裡假設以大寫字母開頭的單詞(句首除外)比其他單詞更相關:人名、城市、國家、品牌。 這是所有大寫單詞的相同原則。
- 每個候選關鍵詞的得分將取決於它在文本中的位置。 如果候選關鍵詞出現在文本的開頭,則它們的得分將高於出現在末尾的得分。 例如,新聞文章經常在文章開頭提到重要的概念。
# yake 的 python 片段 從 yake 導入 KeywordExtractor 作為 Yake yake = Yake(lan="fr", 停用詞=FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords(文本)
與 RAKE 一樣,以下是前 5 個結果:
“珍寶爵士”、“約翰·科爾特蘭”、“格拉茨印象”、“格拉茨”、“科爾特蘭”
儘管在某些關鍵短語中某些單詞有一些重複,但這種方法似乎很有趣。
圖法
這種方法與統計方法相差不遠,我們還將計算單詞共現。 與TextRank等一些方法名稱相關的Rank後綴是基於PageRank算法的原理,根據每個頁面的傳入和傳出鏈接計算每個頁面的流行度。
[電子書] 使用 Oncrawl 自動化 SEO
 閱讀電子書
閱讀電子書文本排名
該算法來自於 2004 年的論文 TextRank:Bringing Order into Texts,其原理與PageRank算法相同。 但是,我們不會用頁面和鏈接構建圖表,而是用單詞構建圖表。 每個單詞將根據它們的共現與其他單詞鏈接。
Python中有幾種實現。 在本文中,我將介紹 pytextrank。 我們將打破關於 POS 標記的限制之一。 實際上,在構建圖形時,我們不會將所有單詞都包含為節點。 只考慮動詞和名詞。 與以前使用停用詞過濾不相關候選詞的方法一樣,TextRank 算法使用語法類型的詞。
這是將由 algo 構建的圖的一部分的示例: 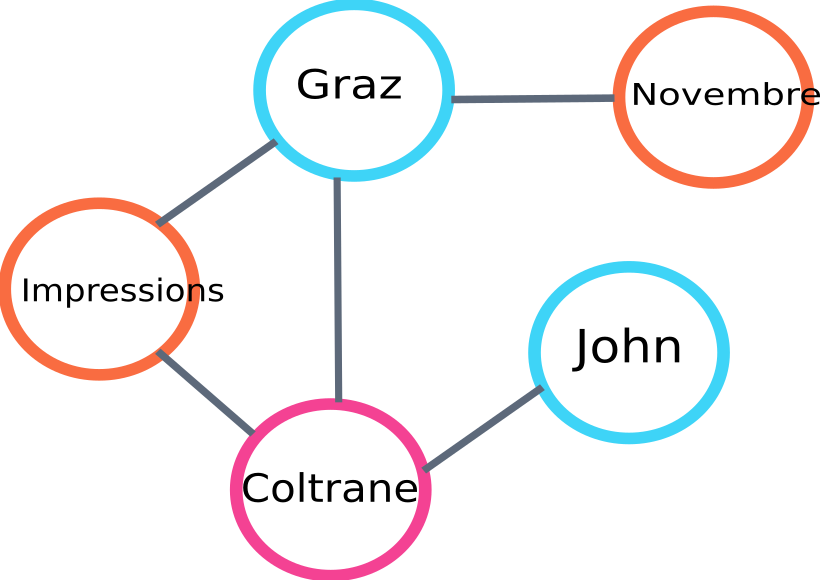
文本排名圖示例
這是一個在 Python 中使用的示例。 請注意,此實現使用 spaCy 庫的管道機制。 正是這個庫能夠進行 POS 標記。
# pytextrank 的 python 片段
進口空間
導入 pytextrank
# 加載一個法國模型
nlp = spacy.load("fr_core_news_sm")
# 將 pytextrank 添加到管道
nlp.add_pipe("textrank")
doc = nlp(文本)
textrank_keyphrases = doc._.phrases
以下是前 5 名的結果:
“哥本哈格”、“十一月”、“格拉茨印象”、“格拉茨”、“約翰·科爾特蘭”
除了提取關鍵短語,TextRank 還提取句子。 這對於製作所謂的“提取摘要”非常有用——本文將不涉及這一方面。
結論
在這裡測試的三種方法中,後兩種在我們看來似乎與本文的主題非常相關。 為了更好地比較這些方法,我們顯然必須在大量示例上評估這些不同的模型。 確實有衡量這些關鍵詞提取模型相關性的指標。
這些所謂的傳統模型生成的關鍵字列表為檢查您的頁面是否有針對性提供了極好的基礎。 此外,它們給出了搜索引擎如何理解和分類內容的初步近似值。
另一方面,其他使用預訓練 NLP 模型的方法(如 BERT)也可用於從文檔中提取概念。 與所謂的經典方法相反,這些方法通常可以更好地捕捉語義。
不同的評估方法、上下文嵌入和轉換器將在第二篇文章中介紹!
以下是使用提到的三種方法之一從本文中提取的關鍵字列表:
“方法”、“關鍵詞”、“關鍵詞”、“文本”、“提取的關鍵詞”、“自然語言處理”
參考書目
- [1] 在提供更多語言知識的情況下改進自動關鍵字提取,Anette Hulth,2003
- [2] 從單個文檔中自動提取關鍵字,Stuart Rose 等。 2010 年
- [3] 耶克! 使用多個局部特徵從單個文檔中提取關鍵字,Ricardo Campos 等。 2020 年
- [4] TextRank:為文本帶來秩序,Rada Mihalcea 等。 2004 年
開始您的 14 天免費試用
 開始試用
開始試用