
真實性、Dalle-2 和 Midjourney 以及我們對 AI 生成的圖像和藝術的迷戀
已發表: 2022-08-04這篇文章是關於像 Dalle-2 和 Midjourney 這樣的平台背後的技術,以及為什麼創造者 Open AI 應該給你錢——而不是向你收費……
互聯網上越來越多的人將 Dalle-2 和 Open AI 命名為騙局。 原因是 Dalle-2 現在突然變成了一種貨幣化服務,如果你使用超過 beta 限制的平台,你需要購買積分。
DALLE 2 只是眾多新平台之一,可讓您訪問 AI 生成的內容,並聲稱您可以將其用於商業目的。 其他平台包括 Midjourney、Jasper Art、Nightcafe、Starry AI 和 Craiyon。 在這篇博文中,我們將重點關注 Dalle 2,但在涉及法律挑戰和問題時,它們幾乎是相同的。
在我們看來,詐騙是一個非常嚴厲的說法,但是在使用其他人創建的數據(照片、視頻、註釋、圖像上的人等)然後開始將其賣回給同一個人時存在一個明顯的問題。
我們中的許多人可能會忽略這個問題,因為我們只是對新技術著迷。 完全可以理解的東西。
然而,儘管說到底 DALL-E 2 只是一台先進的模式識別機,但它的輸出並不是中性的,而且模式也不是來自新鮮空氣。
它們基於大量數據,其中需要提出多個法律問題。 作為您生成的圖像的潛在用戶,對您很重要的問題。
 由 DALLE-2 創建的圖像
由 DALLE-2 創建的圖像
人工智能模型無法與人類相提並論
在開始考慮將 DALL-E 2 圖像用於商業目的之前,您應該先閱讀 Engadget 中的這篇精彩文章。
在 Engadget 文章中,他們指出了另一件非常重要的事情。 也就是說,DALL-E 2 和 OpenAI 並沒有放棄將用戶使用 DALL-E 創建的圖像商業化的權利。 基本上意味著您可以生成圖像,然後他們將商業出售給其他人。
這表明意圖與有時使用的類比非常不同,其中 DALLE-2 發起人將其與閱讀知名作者作品的學生進行比較。 在這個例子中,學生可以學習作者的風格和模式,然後發現它們適用於其他環境並在那裡重新使用它們。
然而,這並不是關於人類大腦使用創造性記憶來創造新的創造性作品。 這是關於模式識別機器重複使用並在某些情況下複製圖像中的訓練數據,然後使用甚至商業銷售。 這只是兩個不同的世界——無論是隱喻還是字面意義上的。
 來自現實世界的真實照片
來自現實世界的真實照片
JumpStory 的真實性承諾
這篇文章是為那些想要更深入地了解這種新的人工智能圖像生成技術是如何工作的人準備的。 但在我們開始之前,請簡單介紹一下為什麼 JumpStory 目前沒有構建類似的機器。
當然,我們多次被問到這個問題。 尤其是考慮到我們公司已經在使用人工智能,而且我們可以訪問數百萬張真實圖像。
然而,這對我們來說不是技術討論,而是倫理討論。 導致我們的真實性承諾的討論。
我們從根本上反對人工智能生成的圖像成為常態而非例外的未來。 稱我們為守舊派,但我們相信真實世界是美麗的。
我們很自豪我們的照片和視頻以不同的形狀和大小描繪了真實的人類。 我們不反對使用人工智能,但我們認為不應該用它來生成虛假的人或現實。
合成介質和 DALL-E 2 等技術表面上可能很吸引人,但它們也帶來了真正的風險。 他們冒著模糊真假界限的風險,這將對人類之間的信任構成根本威脅。
這就是為什麼 JumpStory 不使用人工智能來生成假圖像,而是使用人工智能來識別哪些圖像是原創的、真實的,當然還有合法的商業用途。
這些是您使用我們的服務找到的圖像,我們將我們的方法命名為“真實智能”。
了解如何生成 AI 圖像
關於 JumpStory 和 DALL-E 2 的法律問題,現在已經足夠了。 讓我們看看 AI 圖像是如何在 DALLE-2、Imagen、Crayion(以前稱為 Dall-E Mini)、Midjourney 等平台上生成的……使用 DALLE-2 作為目前最受宣傳的例子。

首先,DALLE-2 可以執行不同類型的任務,但我們將在這篇博文中專注於圖像生成任務。
它的工作原理是將文本提示輸入到文本編碼器中。 該編碼器經過訓練以將提示映射到表示空間。 之後,所謂的先驗模型將編碼文本映射到相應的圖像編碼,該圖像編碼捕獲文本編碼提示的語義信息。
(如果這已經變得有點怪異了,我很抱歉,但它會變得更糟)
圖像編碼器的最後一步是生成圖像,將編碼器接收到的語義信息可視化。 這是 Open AI 等機器的基礎知識。
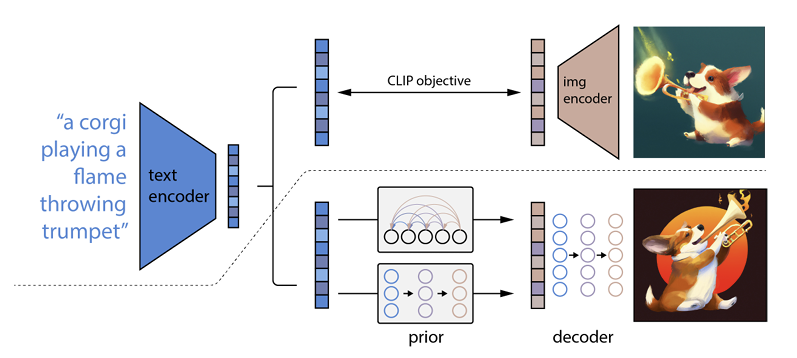
文字與視覺的關係
DALL-E 2 和類似技術通常被稱為文本到圖像生成器。 原因是它們能夠接收文本輸入並提供圖像輸出。
舉個例子,這是“一位宇航員以安迪·沃霍爾 (Andy Warhol) 的風格騎馬:

來源:DALLE-2
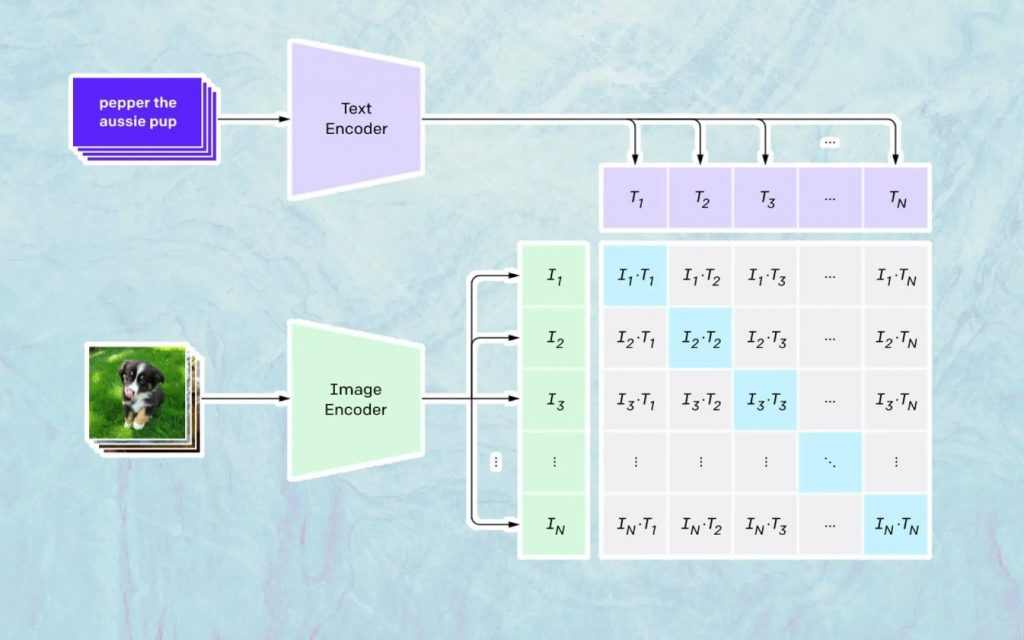
這裡發生的事情是基於 Open AI 的名為 CLIP 的模型。 CLIP 是“Contrastive Language-Image Pre-training”的縮寫,是一個非常複雜的模型,經過數百萬張圖像和字幕的訓練。
CLIP 特別擅長的是了解特定文本與特定圖像的關聯程度。 這裡的關鍵不是標題,而是某個標題與某個圖像的相關程度。
這種技術被命名為“對比”,CLIP 能夠做的就是從自然語言中學習語義。 CLIP 了解這一點的方法是通過一個過程,其目標是(現在引用技術文檔): “同時最大化 N 個正確編碼圖像/字幕對之間的餘弦相似度,並最小化 N 2 – N 個不正確編碼圖像之間的餘弦相似度/字幕對。”
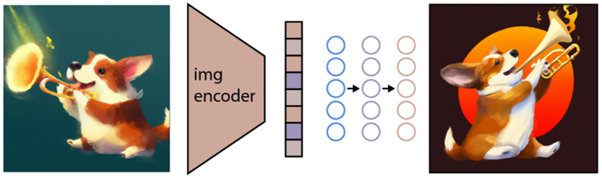
生成圖像
如上所述,CLIP 模型學習了一個表示空間,它可以在其中確定圖像和文本的編碼是如何相關的。
下一個任務是使用這個空間來生成圖像。 為此,Open AI 開發了另一個名為 GLIDE 的模型,該模型能夠使用來自 CLIP 的輸入,並使用擴散模型執行圖像生成。
簡單解釋一下什麼是擴散模型,它基本上是一個通過反轉漸進式噪聲過程來學習生成數據的模型。 抱歉,這現在變得非常技術性,所以引用 Open AI 文檔中的描述:
“噪聲過程被視為一個參數化的馬爾可夫鏈,它逐漸向圖像添加噪聲以破壞它,最終(漸近地)產生純高斯噪聲。 擴散模型學習沿著這條鏈向後導航,在一系列時間步長上逐漸消除噪聲以逆轉這一過程。”

如果您想更深入地了解這項技術,我們建議您閱讀 Ryan O'Connor 撰寫的這篇出色的文章。