
如何在 Oncrawl 之外使用 Oncrawl 數據回答複雜的數據問題
已發表: 2022-01-04Oncrawl 對於企業 SEO 的優勢之一是可以完全訪問您的原始數據。 無論您是將 SEO 數據連接到 BI 還是數據科學工作流程,執行您自己的分析,還是在您的組織的數據安全準則範圍內工作,原始 SEO 和網站審計數據都可以用於多種用途。
今天我們將看看如何使用 Oncrawl 數據來回答複雜的數據問題。
什麼是複雜數據問題?
複雜數據問題是無法通過簡單的數據庫查找來回答的問題,但需要數據處理才能獲得答案。
以下是 SEO 經常遇到的一些“複雜”數據問題的常見示例:
- 創建指向頁面的所有鏈接列表,這些頁面重定向到具有 404 狀態的其他頁面
- 基於非 URL 指標創建一個包含所有鏈接及其錨文本的列表,這些鏈接指向一個分段中的頁面
如何在 Oncrawl 中回答複雜的數據問題
Oncrawl 的數據結構旨在允許幾乎所有站點近乎實時地查找數據。 這涉及將不同類型的數據存儲在不同的數據集中,以確保在界面中將查找時間保持在最低限度。 例如,我們將與 URL 相關的所有數據存儲在一個數據集中:響應代碼、傳出鏈接的數量、存在的結構化數據的類型、字數、自然訪問的數量……我們將與鏈接相關的所有數據存儲在一個單獨的數據集中:鏈接目標、鏈接來源、錨文本……
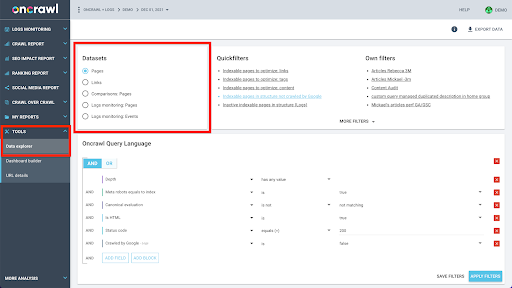
加入這些數據集在計算上很複雜,並且在 Oncrawl 應用程序的界面中並不總是支持。 當您有興趣查找需要過濾一個數據集以便在另一個數據集中查找的內容時,我們建議您自行處理原始數據。
由於您可以使用所有 Oncrawl 數據,因此有很多方法可以連接數據集和表達複雜的查詢。
在本文中,我們將使用 Google Cloud 和 BigQuery 來研究其中之一,這適用於我們的許多客戶在檢查具有大量頁面的網站的數據時遇到的非常大的數據集。
你需要什麼
要遵循我們將在本文中討論的方法,您需要訪問以下工具:
- 爬行
- Oncrawl 的大數據導出 API
- 谷歌云存儲
- 大查詢
- 用於將數據從 Oncrawl 傳輸到 BigQuery 的 Python 腳本(我們將在本文中構建它。)
在開始之前,您需要在 Oncrawl 中訪問已完成的爬網報告。
如何在 Google BigQuery 中利用 Oncrawl 數據
今天這篇文章的計劃如下:
- 首先,我們將確保將 Google Cloud Storage 設置為從 Oncrawl 接收數據。
- 接下來,我們將使用 Python 腳本運行 Oncrawl 的大數據導出,以將數據從給定的爬網導出到 Google Cloud Storage 存儲桶。 我們將導出兩個數據集:頁面和鏈接。
- 完成後,我們將在 Google BigQuery 中創建一個數據集。 然後,我們將從 BigQuery 數據集中的兩個導出中的每一個創建一個表。
- 最後,我們將嘗試查詢單個數據集,然後將兩個數據集放在一起以找到復雜問題的答案。
在 Google Cloud 中設置以接收 Oncrawl 數據
要在專用的沙盒環境中運行本指南,我們建議您創建一個新的 Google Cloud 項目,以將其與您現有的正在進行的項目隔離開來。
讓我們從 Google Cloud 的家開始。
在您的 Google Cloud 主頁上,您可以訪問除 Cloud Storage 之外的許多內容。 我們對 Google Cloud Platform 的雲存儲層中提供的 Cloud Storage 存儲分區感興趣: 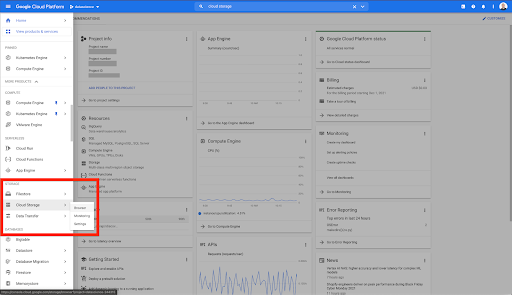
您還可以通過 https://console.cloud.google.com/storage/browser 直接訪問 Cloud Storage 瀏覽器。
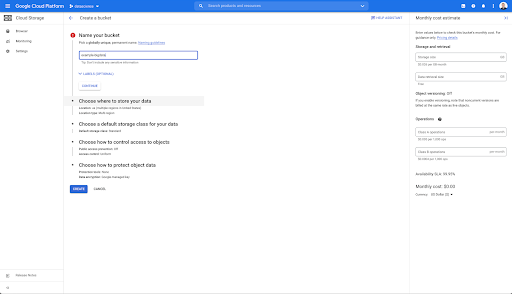
然後,您需要創建一個 Cloud Storage 存儲桶,並授予正確的權限,以便允許 Oncrawl 的服務帳戶在您選擇的前綴下寫入其中。
Google Cloud Storage 存儲桶將用作臨時存儲,用於保存從 Oncrawl 導出的大數據,然後再將它們加載到 Google BigQuery 中。
在這個存儲桶中,我還創建了兩個文件夾:“links”和“pages”: 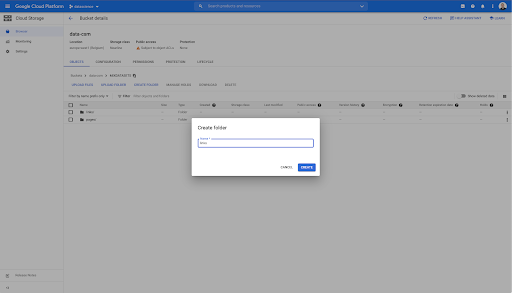
從 Oncrawl 導出數據集
現在我們已經設置了要保存數據的空間,我們需要從 Oncrawl 中導出它。 使用 Oncrawl 導出到 Google Cloud Storage 存儲桶特別容易,因為我們可以以正確的格式導出數據,並將其直接保存到存儲桶中。 這消除了任何額外的步驟。
創建 API 密鑰
從 Oncrawl 以 Parquet 格式導出 BigQuery 的數據將需要使用 API 密鑰以編程方式代表 Oncrawl 帳戶的所有者對 API 進行操作。 Oncrawl 應用程序允許用戶創建命名的 API 密鑰,以便您的帳戶始終井井有條且乾淨整潔。 API 密鑰還與不同的權限(範圍)相關聯,以便您可以管理密鑰及其用途。
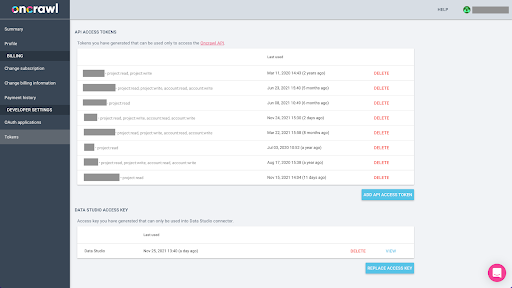
讓我們將新密鑰命名為“知識會話密鑰”。 大數據導出功能需要帳戶中的寫入權限,因為我們正在創建數據導出。 要執行此操作,我們需要對項目具有讀取權限以及對帳戶具有讀寫權限。
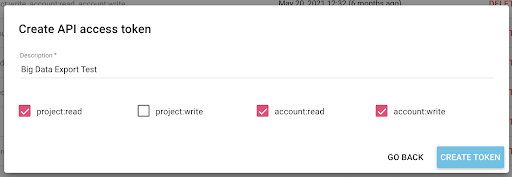
現在我們有了一個新的 API 密鑰,我將把它複製到我的剪貼板。
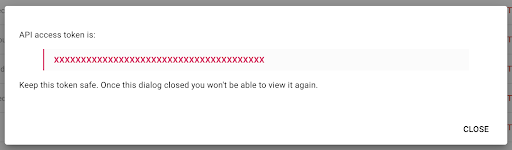
請注意,出於安全原因,您只能複制一次密鑰。 如果您忘記複製密鑰,則需要刪除該密鑰並創建一個新密鑰。
創建你的 Python 腳本
我為此構建了一個 Google Colab 筆記本,但我將分享下面的代碼,以便您可以創建自己的工具或自己的筆記本。
1. 將您的 API 密鑰存儲在全局變量中
首先,我們引導環境並在名為“Oncrawl Token”的全局變量中聲明 API 密鑰。 然後,我們為剩下的實驗做準備:
#@title 訪問 Oncrawl API
#@markdown 在下方提供您的 API 令牌以允許此筆記本訪問您的 Oncrawl 數據:
# 你的 ONCRAWL API 代幣
ONCRAWL_TOKEN = "" #@param {type:"string"}
!pip 安裝監獄
從 IPython.display 導入 clear_output
清除輸出()
print('全部加載完畢。') 
2. 創建一個下拉列表以選擇您要使用的 Oncrawl 項目
然後,使用該鍵,我們希望能夠通過獲取項目列表並從該列表中創建一個下拉小部件來選擇我們想要玩的項目。 通過運行第二個代碼塊,執行以下步驟:
- 我們將調用 Oncrawl API 以使用剛剛提交的 API 密鑰獲取帳戶上的項目列表。
- 從 API 響應中獲得項目列表後,我們使用項目名稱和項目的起始 URL 將其格式化為列表。
- 我們存儲響應中提供的項目 ID。
- 我們構建一個下拉菜單並將其顯示在代碼塊下方。
#@title 通過選擇對應的Oncrawl項目選擇要分析的網站
導入請求
進口監獄
將 ipywidgets 導入為小部件
導入json
# 獲取項目列表
response = requests.get("https://app.oncrawl.com/api/v2/projects?limit={limit}&sort={sort}".format(
限制=1000,
排序='名稱:asc'
),
headers={ '授權': '承載'+ONCRAWL_TOKEN }
)
json_res = response.json()
#prepare 下拉菜單讓用戶選擇一個項目
項目 = []
對於 json_res['projects'] 中的項目:
projects.append(('{} - {}'.format(item['name'], item['start_url']), item['id']))
輸出 = 小部件。輸出()
dropdown_ purpose = widgets.Dropdown(options = projects, description="Project: ")
def dropdown_project_eventhandler(更改):
output.clear_output()
輸出:
展示(項目)
dropdown_purpose.observe(dropdown_project_eventhandler, names='value')
顯示(下拉目的) 從這創建的下拉菜單中,您可以看到 API 密鑰有權訪問的項目的完整列表。 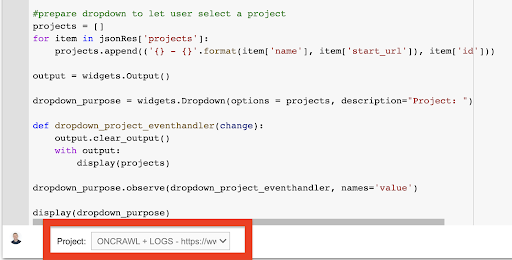
出於今天演示的目的,我們使用的是基於 Oncrawl 網站的演示項目。
3. 創建一個下拉列表以在您要使用的項目中選擇爬網配置文件
接下來,我們將決定使用哪個爬網配置文件。 我們想在這個項目中選擇一個爬網配置文件。 演示項目有很多不同的爬取配置: 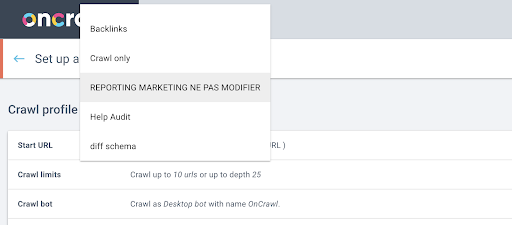
在本例中,我們正在查看 Oncrawl 團隊經常用於實驗的項目,因此我將選擇營銷團隊使用的爬網配置文件來監控 Oncrawl 網站的性能。 由於這應該是最穩定的爬取配置文件,因此它是今天實驗的不錯選擇。
為了獲取爬取配置文件,我們將使用 Oncrawl API 來請求項目中每個爬取配置文件中的最後一次爬取:
- 我們準備查詢給定項目的 Oncrawl API。
- 我們將根據“創建於”日期按降序要求返回所有爬網。
導入請求
導入json
將 ipywidgets 導入為小部件
project_id = dropdown_ purpose.value
# 獲取項目詳情(包括項目中的所有爬取)
project = requests.get("https://app.oncrawl.com/api/v2/projects/{}".format(project_id),
params=dict(include_nested_resources=True, sort="created_at:desc"),
headers={ '授權': '承載'+ONCRAWL_TOKEN }).json()
# 按爬取配置文件分組爬取(爬取名稱)
crawls_by_config = {}
嘗試:
在項目中爬行['crawls']:
if crawl['status'] in ["done"]:
如果 crawl['crawl_config']['name'] 不在 crawls_by_config.keys() 中:
crawls_by_config[crawl['crawl_config']['name']] = {'crawl_ids' : [], 'is_crawl_archived' : False}
如果 len(crawls_by_config[crawl['crawl_config']['name']]['crawl_ids']) == 0:
crawls_by_config[crawl['crawl_config']['name']]['crawl_ids'].append(crawl['id'])
如果 crawl['status'] == "archived":
crawls_by_config[crawl['crawl_config']['name']]['is_crawl_archived'] = True
例外為 e:
raise Exception("error {} , {}".format(e, project))
# 為下拉選擇構建列表
list = [("{} ({})".format(k, len(v['crawl_ids'])), k) for k, v in crawls_by_config.items()]
dropdown_crawl_configs = widgets.Dropdown(options = list, description="抓取配置:")
def dropdown_cc_eventhandler(更改):
output.clear_output()
輸出:
顯示(crawls_by_config)
如果 len(crawls_by_config.values()) == 0:
print('在這個項目中沒有找到實時抓取')
dropdown_crawl_configs.observe(dropdown_cc_eventhandler, names='value')
顯示(dropdown_crawl_configs)運行此代碼時,Oncrawl API 將通過“created at”屬性的降序向我們響應爬取列表。
然後,由於我們只想關注已完成的爬網,因此我們將遍歷爬網列表。 對於狀態為“完成”的每一次爬網,我們將保存爬網配置文件的名稱並存儲爬網 ID。
我們將按爬網配置文件最多保留一次爬網,這樣我們就不想暴露太多的爬網。
結果是從項目中的爬網配置文件列表創建的這個新下拉菜單。 我們會選擇我們想要的。 這將採取營銷團隊進行的最後一次爬網: 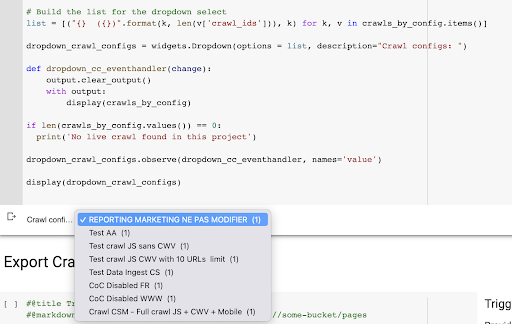
4. 用我們要使用的配置文件識別最後一次爬取
我們已經擁有與所選配置文件中的最後一次爬網關聯的爬網 ID。 它隱藏在“crawl_by_config”對象字典中。 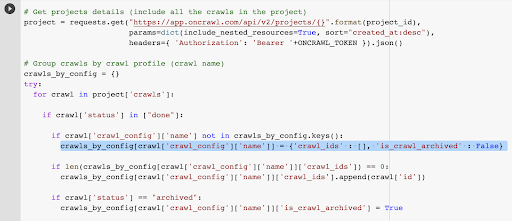
您可以在界面中輕鬆檢查:在此配置文件分析中查找最後完成的爬網。 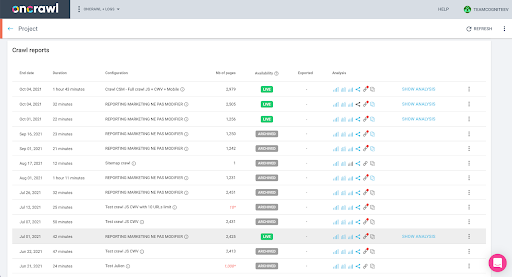
如果我們點擊查看分析,會看到爬取ID以E617結尾。 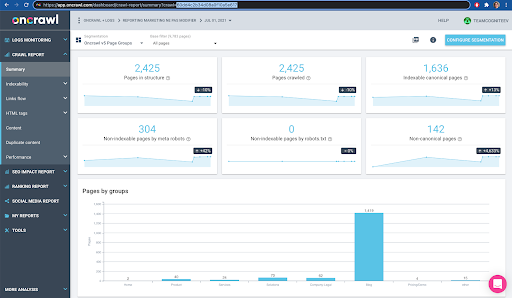
為了今天的演示,我們只記下爬網 ID。
當然,如果您已經知道自己在做什麼,您可以跳過我們剛剛介紹的步驟調用 Oncrawl API 以獲取項目列表和爬取配置文件的爬取列表:您已經從接口,這個 ID 就是你運行導出所需要的全部。
到目前為止,我們執行的步驟只是為了簡化獲取給定項目的給定爬網配置文件的最後一次爬網的過程,給定 API 密鑰可以訪問的內容。 如果您將此解決方案提供給其他用戶,或者您希望將其自動化,這可能會很有用。
5.導出爬取結果
現在,我們來看看導出命令:
#@title 觸發大數據導出
#@markdown 提供您的 GCS 存儲桶和前綴 gs://some-bucket/pages
# 你的 GCS 存儲桶
gcs_bucket = #@param {type:"string"}
gcs_prefix = #@param {type:"string"}
# 從給定項目/爬網配置文件中獲取最後一次爬網 ID
list_crawl_ids = crawls_by_config[dropdown_crawl_configs.value]['crawl_ids']
last_crawl_id = list_crawl_ids[0]
# 數據導出查詢的模板載荷
有效載荷 = {
“數據導出”:{
"data_type": '頁面',
“resource_id”:last_crawl_id,
“輸出格式”:“鑲木地板”,
“目標”:'gcs',
“目標參數”:{
“gcs_bucket”:gcs_bucket,
“gcs_prefix”:gcs_prefix
}
}
}
# 觸發導出
export = requests.post("https://app.oncrawl.com/api/v2/account/data_exports", json=payload, headers={ '授權': '承載'+ONCRAWL_TOKEN }).json()
# 顯示 API 響應
展示(出口)
# 存儲導出 ID 以供將來使用
export_id = 出口['data_export']['id']我們想要導出到我們之前設置的 Cloud Storage 存儲分區。
在其中,我們將導出最後一個爬網 ID 的頁面:
- 最後一個爬網 ID 是從爬網 ID 列表中獲得的,該列表存儲在“crawls_by_config”字典中的某個位置,該字典是在步驟 3 中創建的。
- 我們要在第4步中選擇下拉菜單對應的那個,所以我們使用下拉菜單的value屬性。
- 然後,我們提取 crawl_ID 屬性。 這是一個列表。 我們將保留列表中的前 50 項。 我們需要這樣做,因為在第 2 步中,您會記得,當我們創建 crawls_by_config 字典時,我們只為每個配置名稱存儲了一個爬網 ID。
我設置了輸入字段,以便輕鬆提供 Google Cloud Storage 存儲桶和前綴或文件夾,我們要在其中發送導出。 
為了演示的目的,今天,我們將寫入我已經設置的文件夾之一中的“混合數據集”文件夾。 當我們在 Google Cloud Storage 中設置存儲桶時,您會記得我為“鏈接”導出和“頁面”導出準備了文件夾。
對於第一次導出,我們希望使用 Parquet 文件格式將頁面導出到最後一個爬網 ID 的“pages”文件夾中。 
在下面的結果中,您將看到要發送到數據導出端點的有效負載,該端點是使用 API 密鑰請求大數據導出的端點:
# 數據導出查詢的模板載荷
有效載荷 = {
“數據導出”:{
"data_type": '頁面',
“resource_id”:last_crawl_id,
“輸出格式”:“鑲木地板”,
“目標”:'gcs',
“目標參數”:{
“gcs_bucket”:gcs_bucket,
“gcs_prefix”:gcs_prefix
}
}
}
這包含幾個元素,包括您要導出的數據集的類型。 您可以導出頁面數據集、鏈接數據集、集群數據集或結構化數據數據集。 如果您不知道可以做什麼,您可以在此處輸入錯誤,當您調用 API 時,您將收到一條消息,指出數據類型的選擇必須是頁面或鏈接或集群或結構化數據。 消息如下所示:
{'fields': [{'message': '不是一個有效的選擇。 必須是“page”、“link”、“cluster”、“structured_data”之一。',
“名稱”:“數據類型”,
'類型':'invalid_choice'}],
'類型':'invalid_request_parameters'}
出於今天實驗的目的,我們將分別導出頁面數據集和鏈接數據集。

讓我們從頁面數據集開始。 當我運行這個代碼塊時,我打印了 API 調用的輸出,如下所示:
{'data_export': {'data_type': '頁面',
'export_failure_reason':無,
'id': 'XXXXXXXXXXXXXX',
'輸出格式':'鑲木地板',
“輸出格式參數”:無,
'output_row_count':無,
'output_size_in_bytes: 1634460016000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'狀態':'請求',
'目標':'gcs',
'target_parameters': {'gcs_bucket': 'data-cms',
'gcs_prefix': 'MIXDATASETS/pages/'}}}
這使我可以看到已請求導出。
如果我們想檢查導出的狀態,這很簡單。 使用我們在此代碼塊末尾保存的導出 ID,我們可以隨時通過以下 API 調用請求導出狀態:
# 出口狀況
export_status = requests.get("https://app.oncrawl.com/api/v2/account/data_exports/{}".format(export_id), headers={ '授權': '承載'+ONCRAWL_TOKEN }).json ()
顯示(出口狀態)
這將指示狀態作為返回的 JSON 對象的一部分:
{'data_export': {'data_type': '頁面',
'export_failure_reason':無,
'id': 'XXXXXXXXXXXXXX',
'輸出格式':'鑲木地板',
“輸出格式參數”:無,
'output_row_count':無,
'output_size_in_bytes':無,
'requested_at':1638350549000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'狀態':'出口',
'目標':'gcs',
'target_parameters': {'gcs_bucket': 'data-csm',
'gcs_prefix': 'MIXDATASETS/pages/'}}} 導出完成後( 'status': 'DONE' ),我們可以返回 Google Cloud Storage。
如果我們查看存儲桶,然後進入“鏈接”文件夾,這裡還沒有任何內容,因為我們導出了頁面。 
但是,當我們查看“pages”文件夾時,我們可以看到導出成功。 我們有一個 Parquet 文件: 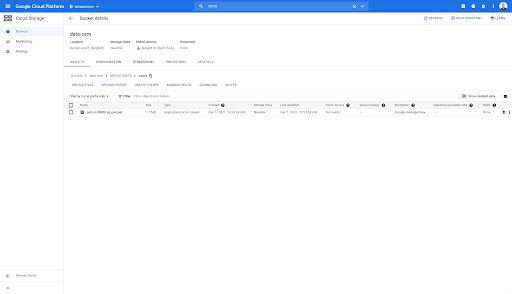
在此階段,頁面數據集已準備好導入 BigQuery,但首先我們將重複上述步驟以獲取鏈接的 Parquet 文件:
- 確保設置鏈接前綴。
- 選擇“鏈接”數據類型。
- 再次運行此代碼塊以請求第二次導出。

這將在“links”文件夾中生成一個 Parquet 文件。
創建 BigQuery 數據集
在導出運行時,我們可以繼續前進並開始在 BigQuery 中創建數據集,並將 Parquet 文件導入單獨的表中。 然後我們將把這些表連接在一起。
我們現在想做的是使用 Google Big Query,它是 Google Cloud Platform 的一部分。 您可以使用屏幕頂部的搜索欄,或直接訪問 https://console.cloud.google.com/bigquery。
為您的工作創建數據集
我們需要在 Google BigQuery 中創建一個數據集: 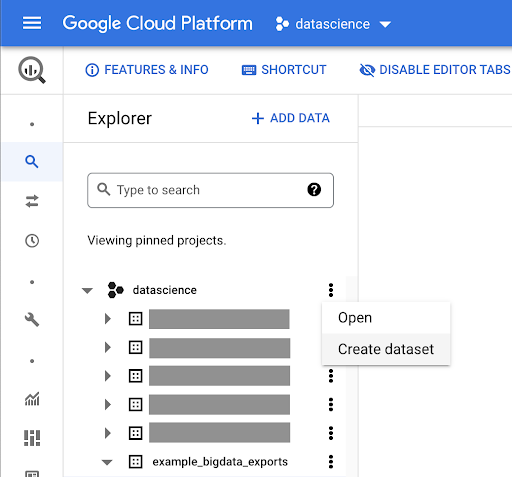
您需要為數據集提供名稱,並選擇存儲數據的位置。 這很重要,因為它將決定數據處理的位置,並且無法更改。 如果您的數據包含 GDPR 或其他隱私法所涵蓋的信息,這可能會產生影響。 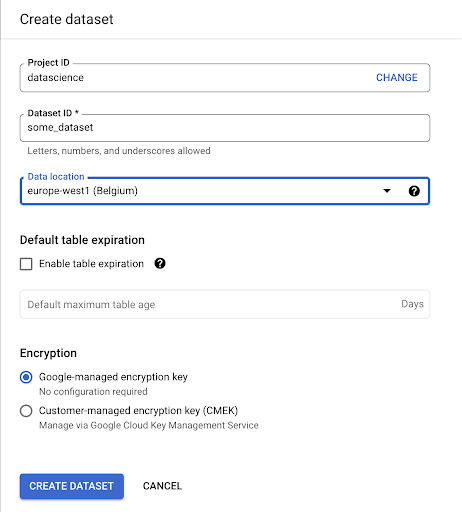
該數據集最初是空的。 當您打開它時,您將能夠創建表、共享數據集、複製、刪除等。
為您的數據創建表
我們將在這個數據集中創建一個表。 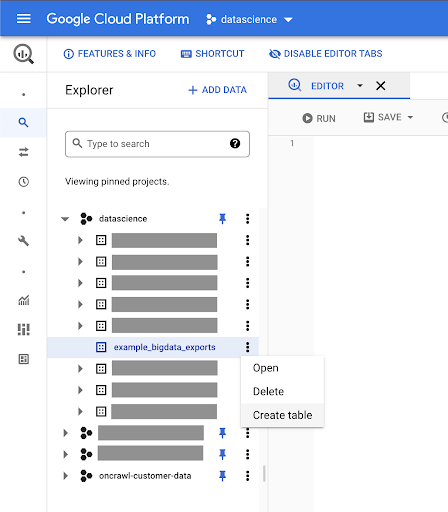
您可以創建一個空表,然後提供架構。 架構是表中列的定義。 您可以定義自己的架構,也可以瀏覽 Google Cloud Storage 以從文件中選擇架構。
我們將使用最後一個選項。 我們將導航到我們的存儲桶,然後導航到“頁面”文件夾。 讓我們選擇頁面文件。 只有一個文件,所以我們只能選擇一個,但如果導出生成了多個文件,我們可以選擇所有文件。 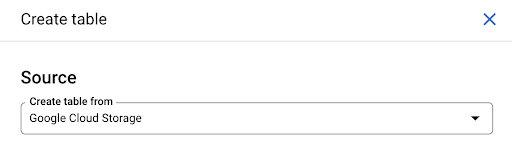
當我們選擇文件時,它會自動檢測它是 Parquet 文件格式。 我們要創建一個名為“pages”的表,並且模式將由源文件定義。 
當我們加載 Parquet 文件時,它嵌入了一個模式。 換句話說,我們正在創建的表的列的定義將從 Parquet 文件中已經存在的模式中推斷出來。 這實際上是魔法的一部分發生的地方。
讓我們繼續前進,簡單地從 Parquet 文件創建表。 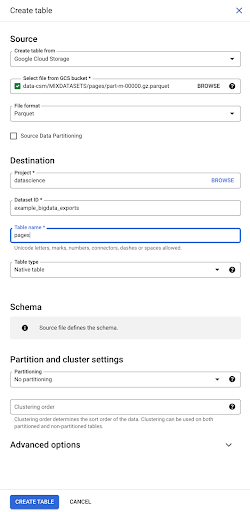
在左側邊欄中,我們現在可以看到數據集中出現了一個表格,這正是我們想要的:
因此,我們現在有了 pages 表的模式,其中包含從 Parquet 文件自動推斷的所有字段。 我們有 Inrank,頁面的深度,如果頁面是重定向等等等等: 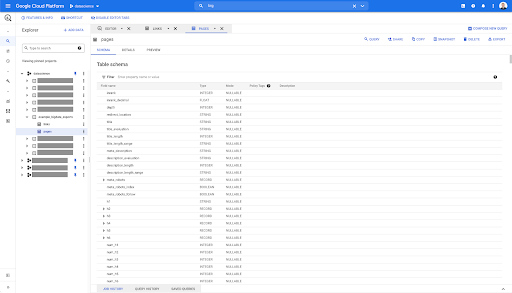
其中大部分字段與通過 Oncrawl Data Studio 連接器在 Data Studio 中提供的字段相同,並且與您在 Oncrawl 界面的 Data Explorer 中看到的字段相同。 
但是,存在一些差異。 當我們使用原始大數據導出時,您擁有所有原始數據。
- 在 Data Studio 中,一些字段被重命名,一些字段被隱藏,一些字段被添加,例如狀態。
- 在 Data Explorer 中,一些字段就是我們所說的“虛擬字段”,這意味著它們可能是一種通往底層字段的快捷方式。 Data Explorer 中可用的這些虛擬字段不會在模式中列出,但可以根據 Parquet 文件中可用的內容重新創建它們。
現在讓我們關閉此表並為鏈接再次執行此操作。
對於鏈接表,架構要小一些。 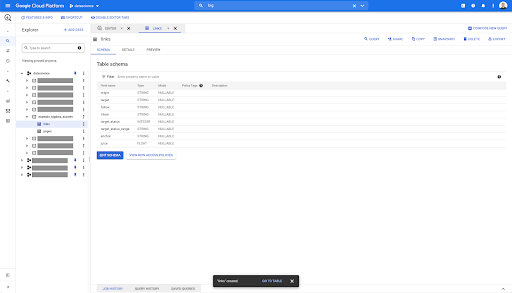
它僅包含以下字段:
- 鏈接的來源,
- 鏈接的目標,
- 跟隨屬性,
- 內部屬性,
- 目標狀態,
- 目標狀態的範圍,
- 錨文本,和
- 鏈接購買的果汁或股權。
在 BigQuery 中的任何表上,當您單擊預覽選項卡時,您可以在不查詢數據庫的情況下預覽該表: 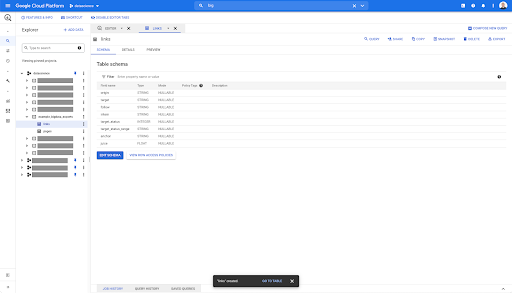
這使您可以快速查看其中的可用內容。 在上面鏈接表的預覽中,您可以預覽每一行和所有列。
在某些 Oncrawl 數據集中,您可能會看到一些跨越多行的行。 我沒有給你的例子,但如果是這種情況,那是因為某些字段包含值列表。 例如,在頁面上的 h2 標題列表中,單行將跨越 Big Query 中的多行。 如果我們看到一個例子,我們稍後會看。
創建您的查詢
如果您從未在 BigQuery 中創建過查詢,那麼現在是時候嘗試一下以熟悉它的工作原理了。 BigQuery 使用 SQL 來查找數據。
查詢的工作原理
作為一個例子,讓我們看看所有的 URL 和它們的排名……
選擇網址,排名...
從頁面數據集...
選擇 url,inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` ...
頁面的狀態碼是 200…
選擇 url,inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 ...
並且只保留前 10 個結果:
選擇 url,inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 10
當我們運行這個查詢時,我們將獲得狀態碼為 200 的頁面列表的前 10 行。
可以修改這些屬性中的任何一個。 f 我想要 1000 行而不是 10 行,我可以設置 1000 行:
選擇 url,inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 1000
如果我想排序,我可以用“order-by”來做到這一點:這將給我所有按 Inrank 降序排序的行。
選擇 url,inrank FROM `datascience-oncrawl.example_bigdata_exports.links` ORDER BY inrank DESC LIMIT 1000
這是我的第一個查詢。 如果需要,我可以保存它,這將使我能夠在以後重用此查詢: 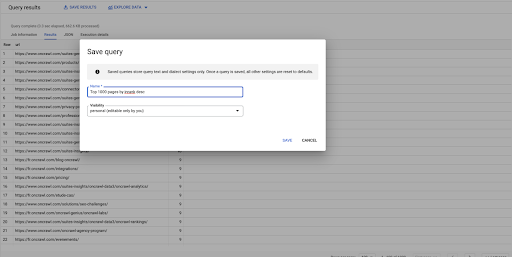
使用查詢回答簡單問題:列出所有指向 301 狀態頁面的內部鏈接
現在我們知道瞭如何編寫查詢,讓我們回到最初的問題。
我們想回答數據問題,無論是簡單的還是複雜的。 讓我們從一個簡單的問題開始,例如“指向具有 301(重定向)狀態的頁面的所有內部鏈接是什麼,我在哪裡可以找到它們?”
創建新查詢
我們將從探索它是如何工作的開始。
我想要來自“鏈接”數據庫的以下元素的列:
- 起源
- 目標
- 目標狀態碼
從 `datascience-oncrawl.example_bigdata_exports.links` 中選擇來源、目標、目標狀態
我只想將這些限制為內部鏈接,但假設我不記得列的名稱或指示鏈接是內部鏈接還是外部鏈接的值。 我可以去架構查找它,並使用預覽來查看值: 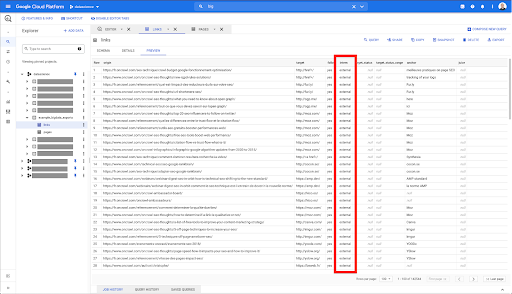
這告訴我該列名為“intern”,值的可能範圍是“external”或“internal”。
在我的查詢中,我想指定“intern 在哪裡”,並且現在將結果限制為前 100 個:
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE 'internal' LIMIT 100
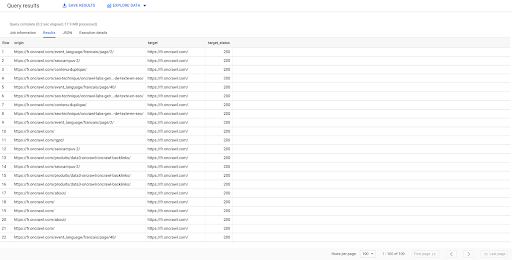
上面的結果顯示了鏈接列表及其目標狀態。 我們只有內部鏈接,我們有 100 個,如查詢中所指定。
如果我們只想有指向該點的內部鏈接到重定向頁面,我們可以說“intern like internal and target status 等於 301”:
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE 'internal' AND target_status = 301
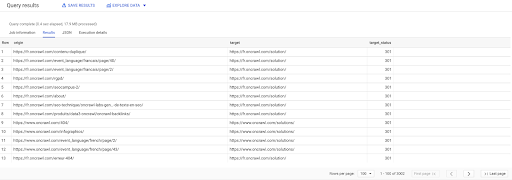
如果我們不知道其中有多少,我們可以運行這個新查詢,我們將看到有 3002 個目標狀態為 301 的內部鏈接。
加入表格:查找指向重定向頁面的鏈接的最終狀態代碼
在網站上,您通常有指向被重定向頁面的鏈接。 我們想知道他們被重定向到的頁面的狀態代碼(或最終目標 URL)。
在一個數據集中,您有關於鏈接的信息:原始頁面、目標頁面及其狀態代碼(如 301),但沒有重定向頁面指向的 URL。 另一方面,您擁有有關重定向及其最終目標的信息,但沒有找到指向它們的鏈接的原始頁面。
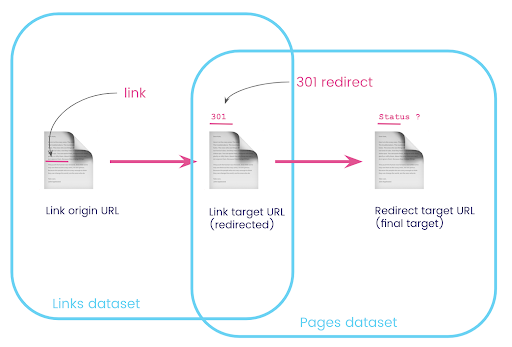
讓我們分解一下:
首先,我們需要指向重定向的鏈接。 讓我們把這個寫下來。 我們想要:
- 起源。
- 目標。 目標必須具有 301 狀態代碼。
- 重定向的最終目標。
換句話說,在鏈接數據集中,我們想要:
- 鏈接的由來
- 鏈接的目標
在 pages 數據集中,我們想要:
- 重定向的所有目標
- 重定向的最終目標
這會給我們一個類似的查詢:
從 `datascience-oncrawl.example_bigdata_exports.pages` 作為頁面 WHERE status_code = 301 或 status_code = 302 選擇 url、final_redirect_location、final_redirect_status
這應該給我等式的第一部分。
現在我需要所有鏈接到頁面的鏈接,這些鏈接是我剛剛創建的查詢的結果,為我的數據集使用別名,並將它們加入鏈接目標 URL 和頁面 URL。 這對應於本節開頭圖表中兩個數據集的重疊區域。
選擇 鏈接.原點, pages.url, pages.final_redirect_location, pages.final_redirect_status 從 `datascience-oncrawl.example_bigdata_exports.pages` AS 頁面 加入 `datascience-oncrawl.example_bigdata_exports.links` AS 鏈接 上 links.target = pages.url 在哪裡 pages.status_code = 301 或 pages.status_code = 302 訂購方式 原點 ASC
在查詢結果中,我可以重命名列以使事情更清楚,但是我已經可以看到我有一個來自第一列中的頁面的鏈接,該鏈接轉到第二列中的頁面,而第二列中的頁面又被重定向到第三列中的頁面。 在第四列,我有最終目標的狀態碼: 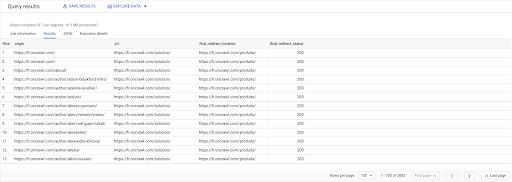
現在我可以知道哪些鏈接指向的重定向頁面無法解析為 200 頁。 例如,它們可能是 404,這為我提供了要更正的鏈接的優先級列表。
我們之前看到瞭如何保存查詢。 我們還可以保存結果,最多可以保存 16000 行結果: 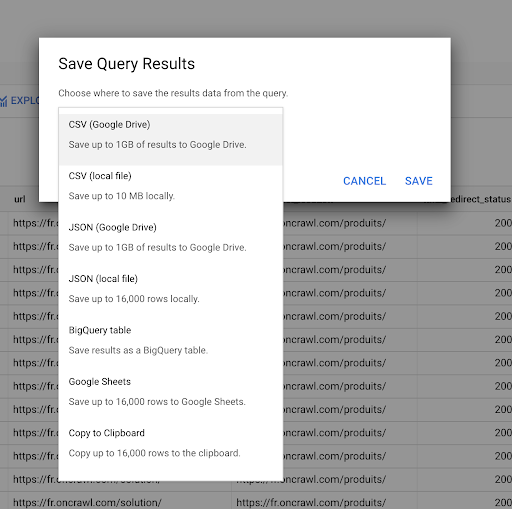
然後,我們可以以許多不同的方式使用這些結果。 這裡有一些例子:
- 我們可以在本地將其保存為 CSV 或 JSON 文件。
- 我們可以將其保存為 Google 表格電子表格並與團隊的其他成員共享。
- 我們也可以直接將其導出到 Data Studio。
數據作為戰略優勢
有了所有這些可能性,戰略性地使用複雜問題的答案很容易。 您可能已經有將 BigQuery 結果連接到 Data Studio 或其他數據可視化平台的經驗,或者您可能已經制定了將信息推送到工程團隊甚至商業智能或數據分析工作流程的流程。
如果您已將本文中的步驟作為流程的一部分包含在內,請記住您可以自動化 BigQuery 中的所有步驟:我們在本文中執行的所有操作也可以通過 BigQuery API 訪問。 這意味著它們可以作為腳本或自定義工具的一部分以編程方式運行。
無論您下一步做什麼,第一步始終是訪問原始 SEO 和網站數據。 我們相信這種對數據的訪問是技術分析中最重要的部分之一:使用 Oncrawl,您將始終可以完全訪問您的原始數據。
訪問數據還意味著您可以超越 Oncrawl 界面中的可能性,探索數據之間的所有關係,無論您提出的問題多麼複雜。