
SEO日誌文件分析介紹
已發表: 2021-05-17日誌分析是分析搜索引擎如何讀取我們網站的最徹底的方法。 SEO、數字營銷人員和網絡分析專家每天都使用顯示流量、用戶行為和轉化圖表的工具。 SEO 通常會嘗試了解 Google 如何通過 Google Search Console 抓取他們的網站。
那麼……為什麼 SEO 應該分析其他工具來檢查搜索引擎是否正確讀取了網站? 好的,讓我們從基礎開始。
什麼是日誌文件?
日誌文件是服務器 Web 為網站上機器人或用戶請求的每個資源寫入一行的文件。 每行包含有關請求的數據,其中可能包括:
調用方 IP、日期、所需資源(頁面、.css、.js、……)、用戶代理、響應時間……
一行看起來像這樣:
66.249.**.** - - [13/Apr/2021:00:07:31 +0200] "GET /***/x_*** HTTP/1.1" 200 40960 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "www.***.it" "-"
可抓取性和可更新性
每個頁面都有三種基本的 SEO 狀態:
- 可抓取
- 可轉位
- 可排序的
從日誌分析的角度來看,我們知道一個頁面,為了被索引,必須被機器人讀取。 同樣,必須重新抓取已被搜索引擎索引的內容,以便在搜索引擎的索引中進行更新。
不幸的是,在 Google Search Console 中,我們沒有這個級別的詳細信息:我們可以檢查 Googlebot 在過去三個月內閱讀了網站上的頁面的次數以及網絡服務器的響應速度。
我們如何檢查機器人是否已閱讀頁面? 當然,通過使用日誌文件和日誌文件分析器。
為什麼 SEO 需要分析日誌文件?
日誌文件分析允許 SEO(以及系統管理員)了解:
- 機器人讀取的內容
- 機器人多久閱讀一次
- 就花費的時間(毫秒)而言,爬網的成本是多少
日誌分析工具可以通過按“路徑”、文件類型或響應時間對信息進行分組來分析日誌。 一個出色的日誌分析工具還允許我們將從日誌文件中獲取的信息與其他數據源(如 Google Search Console(點擊次數、展示次數、平均排名)或 Google Analytics)相結合。
Oncrawl 日誌分析器
 學到更多
學到更多在日誌文件中查找什麼?
日誌文件中的主要重要信息之一是日誌文件中沒有的信息。 真的,我不是在開玩笑。 了解為什麼頁面未編入索引或未更新到其最新版本的第一步是檢查機器人(例如 Googlebot)是否已閱讀它。
在此之後,如果頁面經常更新,檢查機器人讀取頁面或站點部分的頻率可能很重要。
下一步是檢查機器人最常閱讀哪些頁面。 通過跟踪它們,您可以檢查這些頁面是否:
- 值得經常閱讀
- 或者經常被閱讀,因為頁面上的某些東西會導致不斷的、失控的變化
例如,幾個月前,我工作的一個網站在一個奇怪的 URL 上出現了非常高的 bot 閱讀頻率。 機器人發現這個頁面來自一個由 JS 腳本創建的 URL,並且這個頁面被標記了一些調試值,這些值在每次頁面加載時都會改變……在這個發現之後,一個好的 SEO 肯定可以找到正確的解決方案來解決這個問題爬行預算漏洞。
抓取預算
抓取預算? 它是什麼? 每個站點都有與搜索引擎及其機器人相關的隱喻預算。 是的:Google 為您的網站設置了一種預算。 這不會記錄在任何地方,但您可以通過兩種方式“計算”它:
- 檢查 Google Search Console 抓取統計報告
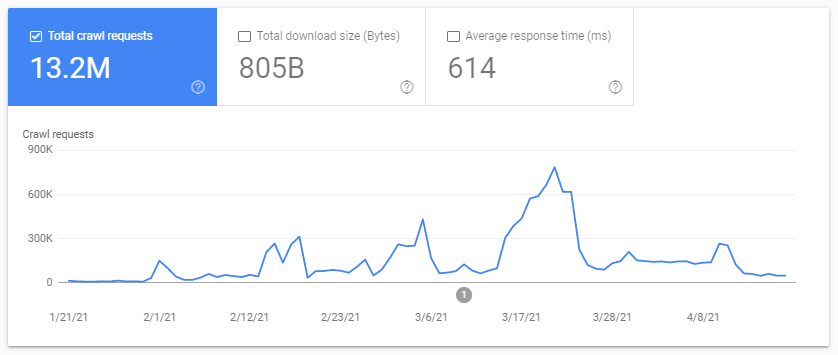
- 檢查日誌文件,通過包含“Googlebot”的用戶代理對它們進行 grepping(過濾)(如果您確保這些用戶代理與正確的 Google IP 匹配,您將獲得最佳結果…… )
當網站更新有趣的內容、定期更新內容或網站收到良好的反向鏈接時,抓取預算會增加。
如何在您的網站上花費抓取預算可以通過以下方式管理:
- 內部鏈接(也關注/nofollow!)
- 無索引/規範
- robots.txt(小心:這會“阻止”用戶代理)
殭屍頁面
對我來說,“殭屍頁面”是在相當長的一段時間內沒有任何自然流量或機器人訪問但有指向它們的內部鏈接的所有頁面。
這種類型的頁面可能會使用過多的抓取預算,並且由於內部鏈接可能會獲得不必要的頁面排名。 這種情況可以解決:
- 如果這些頁面對訪問該站點的用戶有用,我們可以將它們設置為 noindex 並將指向它們的內部鏈接設置為 nofollow (或使用 disallow robots.txt,但要小心... )
- 如果這些頁面對訪問該站點的用戶沒有用,我們可以刪除它們(並返回狀態碼 410 或 404)並刪除所有內部鏈接。
使用 Oncrawl,我們可以根據以下內容創建“殭屍報告”:
- GSC 展示次數
- GSC 點擊次數
- GA 會議
我們還可以使用日誌事件來發現殭屍頁面:例如,我們可以定義一個 0 事件過濾器。 最簡單的方法之一是創建分段。 在下面的示例中,我使用以下條件過濾所有頁面:沒有 Googlebot 命中但具有 Inrank(這意味著這些頁面具有指向它們的內部鏈接)。 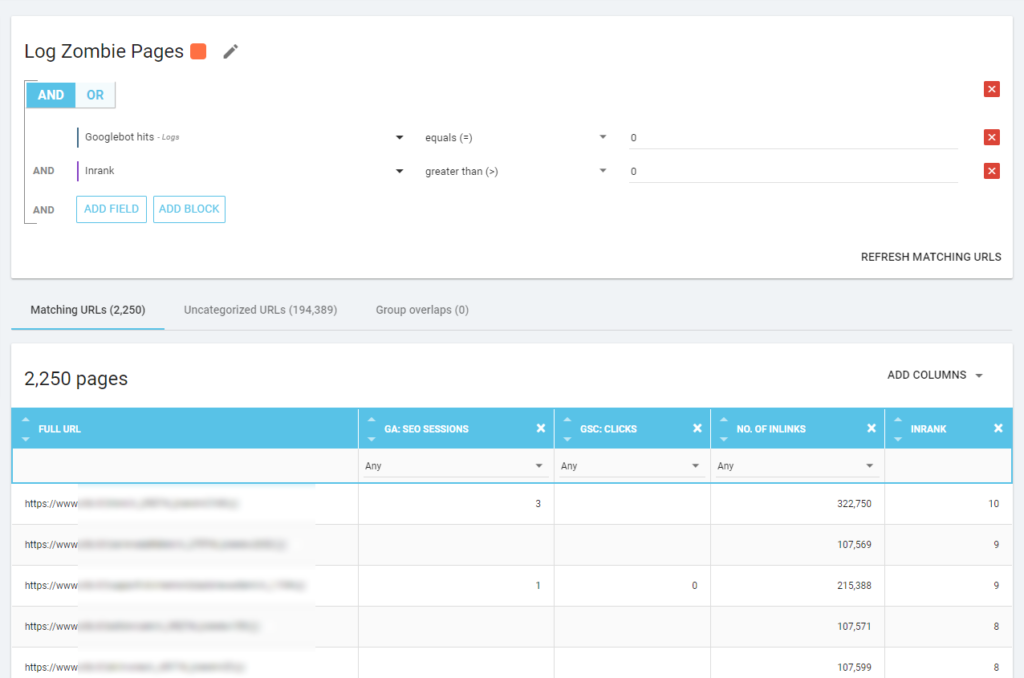
因此,現在我們可以在所有 Oncrawl 報告中使用此分段。 這讓我們可以從任何圖形中獲得洞察力,例如:有多少“日誌殭屍頁面”返回 200 狀態碼? 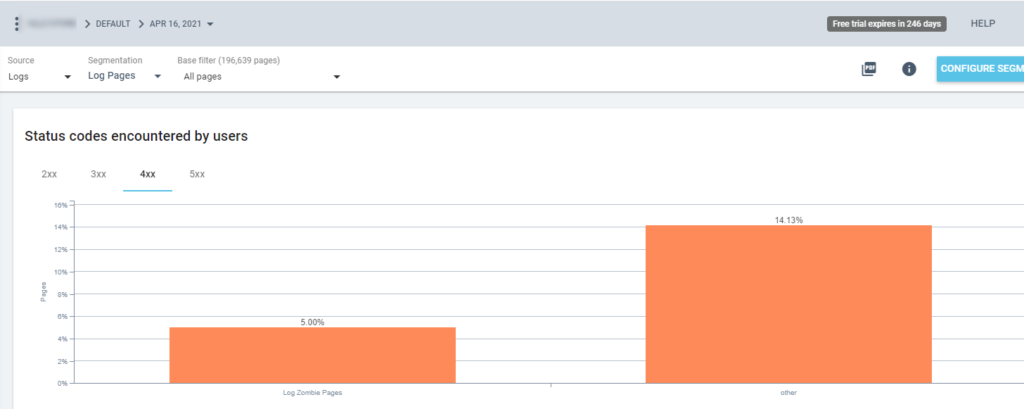
孤立頁面
對我來說,值得仔細查看的“孤兒頁面”是所有在重要指標(GA Session、GSC Impression、Log hits...)上具有高價值且沒有任何內部鏈接指向它們以共享頁面排名的頁面並指出頁面重要性。
與“殭屍頁面”一樣,要創建基於日誌的報告,最好的方法是創建新的細分。 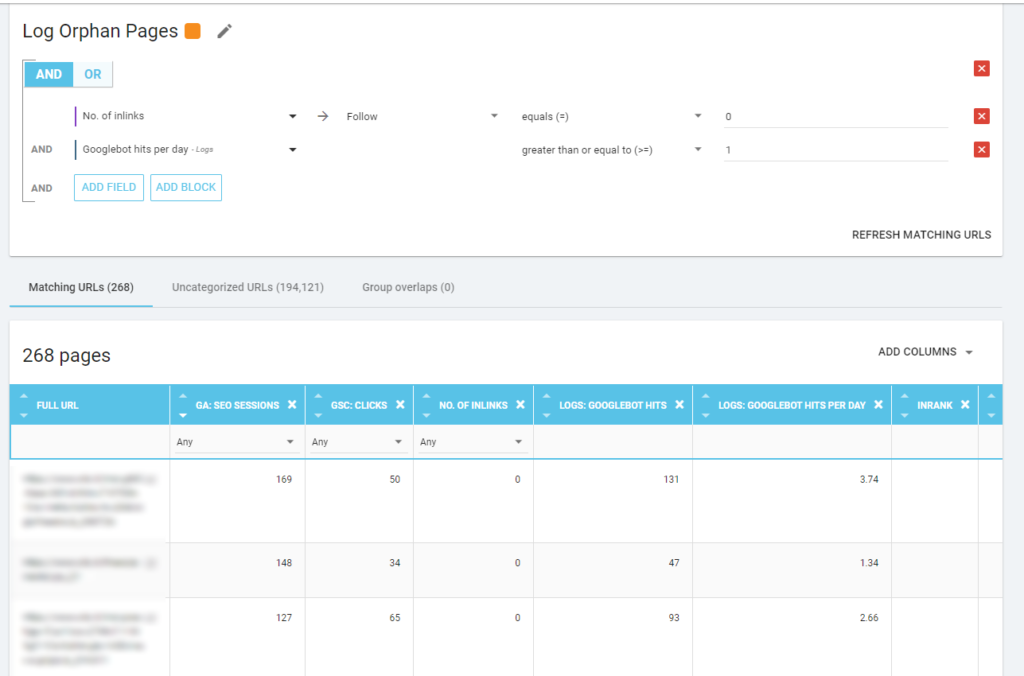
哇,有很多頁面有會話和點擊,沒有鏈接!
在查看基於“零關注鏈接”的報告時,請注意抓取狀態:Oncrawl 是能夠抓取所有網站,還是只能抓取幾頁? 您可以在項目的主頁上看到: 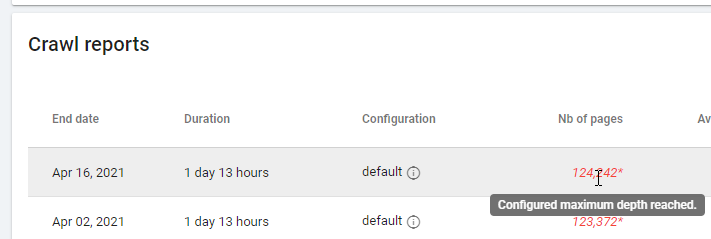
如果已達到最大深度:

- 檢查您的爬網配置
- 檢查您的網站結構
日誌文件和 Oncrawl
Oncrawl 在其默認儀表板中提供什麼?
實時日誌
此儀表闆對於檢查有關機器人如何讀取您的站點的關鍵信息非常有用,只要機器人訪問該站點並且在完全處理來自日誌文件的信息之前。 為了充分利用它,我建議經常上傳日誌文件:您可以通過 FTP、Amazon S3 等連接器進行上傳,也可以通過 Web 界面手動上傳。
第一個圖表顯示了您的網站被閱讀的頻率,以及被哪個機器人閱讀。 在您可以在下面看到的示例中,我們可以檢查桌面訪問與移動訪問。 在這種情況下,我們將僅為 Googlebot 過濾的日誌文件發送到 Oncrawl: 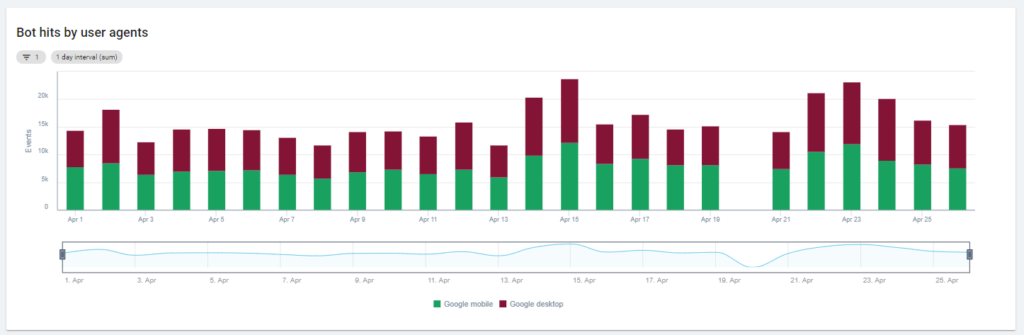
有趣的是,移動閱讀量仍然很高:這是否正常? 這取決於... 我們正在分析的網站仍處於“移動優先索引”中,但它不是一個完全響應的網站:它是一個動態服務網站(正如 Google 所說),Google 仍然檢查兩個版本!
另一個有趣的圖表是“Bot hits by page group”。 默認情況下,Oncrawl 基於 URL 路徑創建組。 但是我們可以手動設置組,以便將最有意義的 URL 分組在一起進行分析。 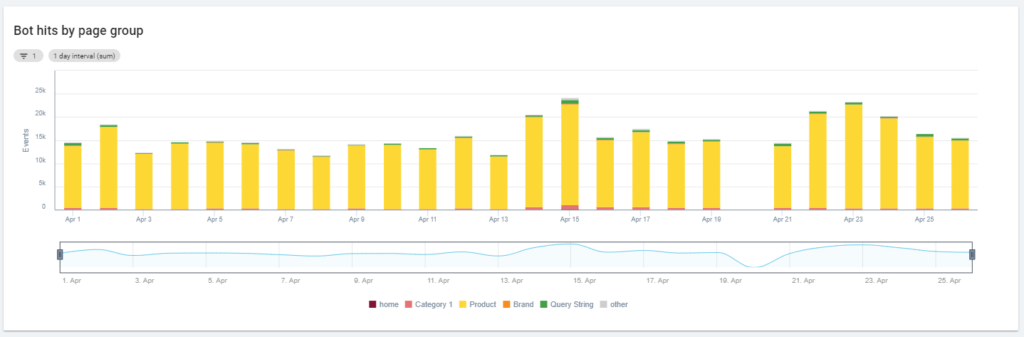
如您所見,黃色獲勝! 它表示帶有產品路徑的 URL,因此它產生如此高的影響是正常的,特別是因為我們有 Google 付費購物廣告系列。
而且……是的,我們剛剛確認 Google 使用標準 Googlebot 來檢查與商家 Feed 相關的產品狀態!
爬行行為
此儀表板顯示與“實時日誌”類似的信息,但此信息已完全處理並按天、週或月匯總。 在這裡您可以設置一個日期時間段(開始/結束時間),該時間段可以隨時返回。 有兩個新圖表可以進一步進行日誌分析:
- 爬取行為:檢查已爬取頁面與新爬取頁面的比例
- 每天的抓取頻率
閱讀這些圖表的最佳方法是將結果與站點操作聯繫起來:
- 你移動頁面了嗎?
- 你更新了一些部分嗎?
- 你發布新內容了嗎?
搜索引擎優化影響
對於 SEO,監控優化的頁面是否被機器人讀取很重要。 正如我們所寫的“孤立頁面”,確保機器人讀取最重要/更新的頁面非常重要,以便搜索引擎可以使用最新的信息進行排名。
Oncrawl 使用“活動頁面”的概念來指示從搜索引擎接收自然流量的頁面。 從這個概念出發,它顯示了一些基本的數字,例如:
- 搜索引擎優化訪問
- SEO活動頁面
- SEO活躍率(活躍頁面佔所有爬取頁面的比例)
- Fresh Rank(機器人第一次閱讀頁面和第一次自然訪問之間的平均時間)
- 未抓取的活動頁面
- 新活動頁面
- 每天活躍頁面的抓取頻率
正如 Oncrawl 的理念一樣,只需單擊一下,我們就可以深入信息湖,按我們點擊的指標進行過濾! 例如:哪些是未爬取的活動頁面? 一鍵... 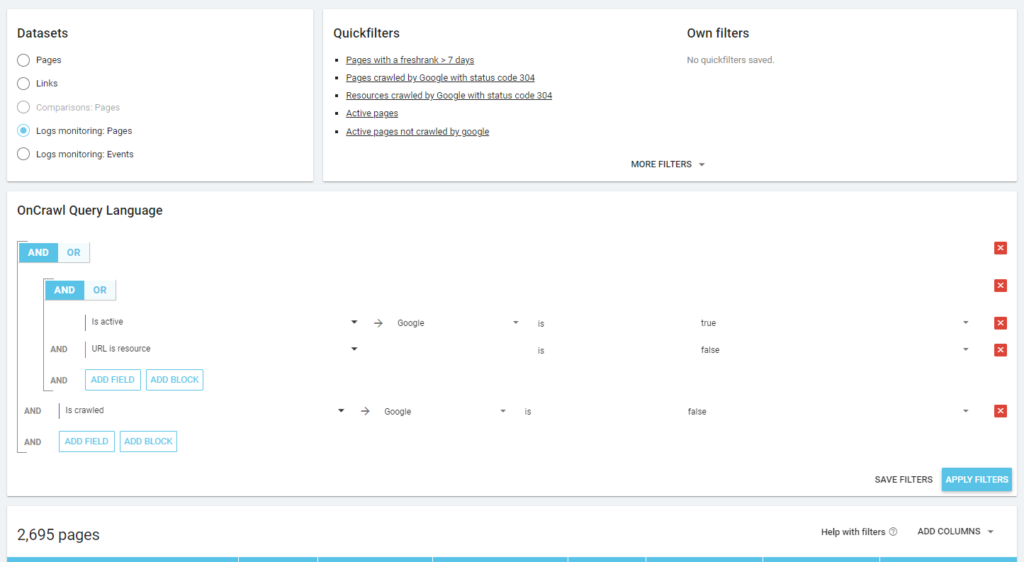
探索理智
最後一個儀表板允許我們檢查 bo 的抓取質量,或者更準確地說,檢查網站向搜索引擎展示自己的情況:
- 狀態碼分析
- 每日狀態碼分析
- 按頁組的狀態碼分析
- 響應時間分析
良好的 SEO 工作必須:
- 減少來自內部鏈接的 301 響應的數量
- 從內部鏈接中刪除 404/410 響應
- 優化響應時間,因為 Googlebot 的抓取質量與響應時間直接相關:嘗試將您網站上的響應時間減少一半,您會看到(幾天后)抓取的頁面數量會翻倍。
日誌分析和 Oncrawl 的數據資源管理器的科學
到目前為止,我們已經看到了標準的 Oncrawl 報告以及如何使用它們通過分段和頁面組獲取自定義信息。
但是日誌分析的核心是了解如何發現錯誤。 通常,分析的起點是檢查峰值並將它們與流量和您的目標進行比較:
- 爬取次數最多的頁面
- 最少抓取的頁面
- 爬取次數最多的資源(不是頁面)
- 按文件類型抓取頻率
- 3xx / 4xx 狀態碼的影響
- 5xx 狀態碼的影響
- 爬取速度較慢的頁面
- …
你想更深入嗎? 好……您需要添加數據。 Oncrawl 提供了一個非常強大的工具,比如 Data Explorer。
正如您在之前的屏幕截圖中看到的(未抓取的活動頁面),您可以根據您的分析框架創建所有您想要的報告。
例如:
- 最糟糕的自然流量頁面,被機器人抓取很多
- 機器人抓取過多的最佳自然流量頁面
- 具有大量 SERP 印象的較慢頁面
- …
下面你可以看到我是如何檢查哪些是與 SEO 會話數量相關的最常被抓取的頁面: 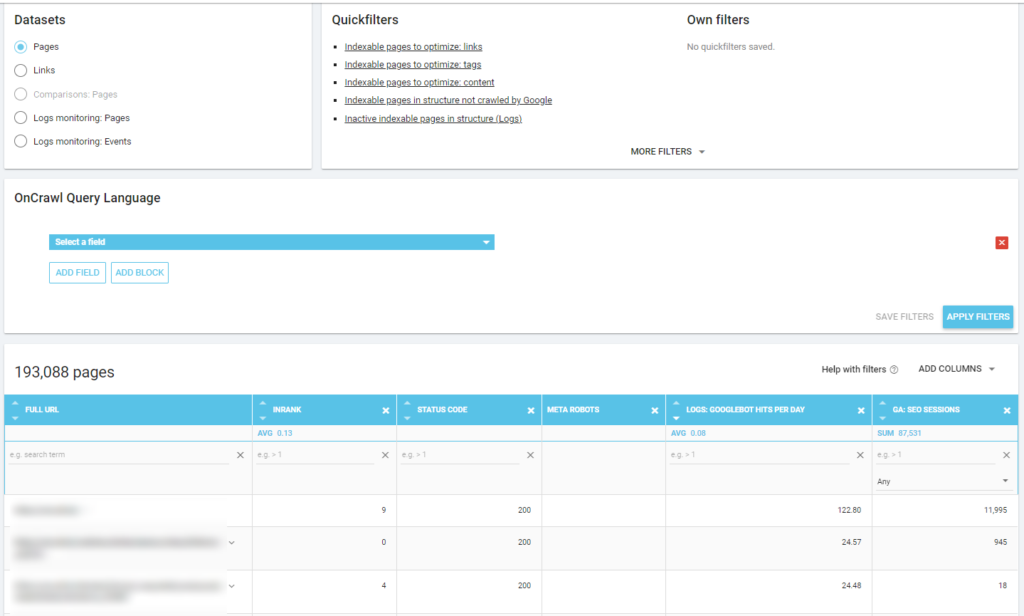
外賣
日誌分析並非嚴格的技術性:要以最好的方式進行,我們需要結合技術技能、SEO 技能和營銷技能。
很多時候,分析被排除在“搜索引擎優化清單”之外,因為我們的客戶無權訪問日誌文件,或者因為它可能是一項昂貴的分析。
現實情況是,日誌是真正檢查機器人在我們網站上的位置以及了解我們的服務器如何響應它們的唯一來源。
像 Oncrawl 這樣的工具可以大大降低技術要求:只需上傳日誌文件並開始分析它們!