
使用 OnCrawl 的 5 個省時技巧
已發表: 2017-06-21如何利用高級 OnCrawl 功能來提高日常 SEO 監控的效率。
OnCrawl 是一款功能強大的 SEO 工具,可幫助您監控和優化搜索引擎對電子商務網站、在線發布商或應用程序的可見性。 該工具是圍繞一個簡單的原則構建的:幫助流量經理在分析過程和日常 SEO 項目管理中節省時間。
除了作為現場審計工具,它基於一個結合所有網站數據的 API 支持的 SaaS 平台,也是一個日誌分析器,可以簡化從日誌服務器文件中提取和分析數據。
OnCrawl 的可能性相當廣泛,但需要掌握。 在本文中,我們將分享 5 個節省時間的技巧,供您日常使用我們的 SEO 爬蟲和日誌分析器。
1# 如何對 HTTP 和 HTTPS url 進行分類
HTTPS 遷移是 SEO 領域的熱門話題。 為了完美地處理這個關鍵步驟,精確地跟踪兩種協議上的機器人行為非常重要。
經驗表明,機器人需要或多或少的時間才能完全從 HTTP 切換到 HTTPS。 平均而言,這種轉變需要幾週或幾個月的時間,具體取決於與網站質量和遷移相關的外部和內部因素。
為了準確了解您的抓取預算受到嚴重影響的過渡階段,監控機器人點擊率是明智之舉。 因此有必要分析服務器日誌。 作為普通用戶,該機器人會在他提出的每個頁面、資源和請求上留下標記。 您的日誌擁有傳遞這些調用的端口。 因此,您可以驗證 HTTPS 網站的遷移質量。
設置專用 http vs https 頁面組的方法
在您的高級項目主頁上,您可以在右上角找到一個“設置”按鈕。 然後,選擇“配置頁面組”菜單。 在這裡,創建一個新的“創建組集”並將其命名為“HTTP vs HTTPS”。
為了訪問您的日誌,選擇“我想在日誌監控和交叉分析儀表板上使用此集”選項很重要。
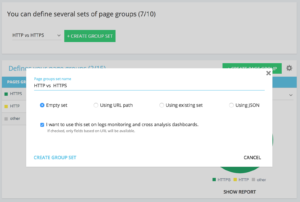
- HTTPS:“完整網址”/“開頭”/https
- HTTP : “完整 url”/“不以開頭”/https
保存後,您將訪問 HTTPS 遷移的視圖(如果您在日誌行中添加了請求端口。您可以查看我們的指南。)
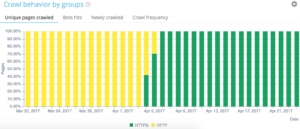
我們的快速過濾器可以在數據資源管理器中找到。 它們旨在簡化對一些重要 SEO 指標的訪問,例如指向 404、500 或 301/302 的鏈接,頁面太慢或太差等。
以下是完整列表:
- 404 錯誤
- 5xx 錯誤
- 活動頁面
- Google 未抓取的活動頁面
- Google 遇到的狀態代碼不同於 200 的活動頁面
- 規範不匹配
- 未設置規範
- 可索引頁面
- 沒有可索引的頁面
- 孤立的活動頁面
- 孤立頁面
- Google 抓取的頁面
- Google 和 OnCrawl 抓取的頁面
- 結構中的頁面未被 Google 抓取
- 指向 3xx 錯誤的頁面
- 指向 4xx 錯誤的頁面
- 指向 5xx 錯誤的頁面
- h1 錯誤的頁面
- h2 不好的頁面
- 元描述錯誤的頁面
- 標題錯誤的頁面
- 存在 HTML 重複問題的頁面
- 鏈接少於 10 個的頁面
- 重定向 3xx
- 頁面太重
- 頁面太慢
但有時,這些 QuickFilters 並不能解決您的所有業務問題。 在這種情況下,您可以從其中一個開始,並通過在過濾器中添加片段並保存它們以在您連接到該工具時快速找到您的過濾器來創建您的“自己的過濾器”。
例如,從指向 4xx 的鏈接中,您可以選擇過濾具有空錨點的鏈接:“Anchor”/“is”/“”並保存該過濾器。 保存後,可以根據需要多次修改。
您現在可以直接訪問“Own”部分底部的“Select a Quickfilter”列表中的特定“Quickfilter”,如下面的屏幕截圖所示。
3#如何設置DataLayer相關的自定義字段?
例如,當您定義分析工具標籤時,您可以使用相關頁麵類型的細分。 該特定代碼非常有趣,可以將來自 OnCrawl 的數據與您的外部數據進行分割或交叉。
為了讓您為您的分析創建一個“關鍵列”,我們可以在抓取過程中提取這些代碼片段並將它們作為您項目的一種數據帶回來。
借助正則表達式或 XPath,“自定義字段”選項可以從源代碼頁中抓取任何元素。 這些語言有自己的定義和規則。 您可以在此處找到有關 XPath 的信息和有關 regex 的信息。
用例 1:從頁面源代碼中提取數據層數據
代碼分析:


解決方案:使用“正則表達式”:s.prop2=”([^”]+)”/提取:單值/字段格式:值

- 查找 s.prop2=” 字符串
- 刮掉所有不是“的字符(要提取的數據後面的第一個字符)
- 要提取的字符串可以在“結束”之前找到
爬取後,在數據資源管理器中,您將在 sProp2、sProp3 列或您的字段名稱中找到提取的數據:

使用 XPATH
代碼分析:
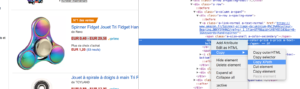
您只需要直接從 Chrome 代碼分析器中復制/粘貼要抓取的 Xpath 元素。 請注意,如果代碼是用 JavaScript 呈現的,您將需要設置一個自定義抓取項目。 Xpath 語言非常強大且難以操作,因此如果您需要幫助,請致電我們的專家。
用例 3:在接收階段測試分析標籤的存在
使用正則表達式
代碼分析:

解決方案:使用“正則表達式”:'_setAccount','UA-364863-11' / 提取:檢查是否存在
如果找到字符串,您將在 Data Explorer 中獲得“true”,反之則為“false”。
4# 如何可視化您網站各個部分的 Google 抓取頻率
抓取預算是任何 SEO 關注的核心。 它與“頁面重要性”概念和 Google 的抓取調度密切相關。 我們知道這些原則,自 2012 年以來在谷歌專利中引入,讓山景城社會優化專門用於網絡爬蟲的資源。
Google 不會在您網站的每個部分花費相同的精力。 它在您網站各個部分的抓取頻率可讓您準確了解您的網頁在 Google 眼中的重要性。
谷歌機器人會更多地抓取重要頁面,因為抓取預算與頁面排名技巧密切相關。
OnCrawl Advanced 項目讓您在“日誌監控”/“Crawl Behavior”/“Crawl Behavior By Group”部分原生查看爬取預算。
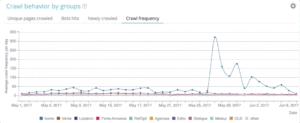
可以看到“首頁”組的爬取頻率最高。 這很正常,因為谷歌一直在尋找新文章,而且它們通常都列在主頁上。 頁面重要性理念與 Google Freshness 概念密切相關。 您的主頁是確定您的 Google 抓取預算優先級的最重要的頁面。 然後,針對深度和流行度將優化傳播到其他頁面。
然而,很難看到頻率差異。 因此,您需要單擊要刪除的組(通過單擊圖例)並查看顯示的數據。
5# 如何在遷移後從 URL 列表中測試狀態代碼
當您想從一組 URL 中快速測試狀態代碼時,可以修改新爬網的設置:
- 添加所有起始 URL(“添加起始 URL”按鈕)
- 將最大深度定義為 1
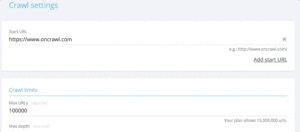
此自定義爬網將返回有關此 url 集的定性數據。
您將能夠檢查重定向是否設置良好,或者隨著時間的推移跟踪狀態代碼的演變。 想想定期抓取的好處,您將能夠自動關注舊網址。
您為什麼不通過我們的 API 創建一個自動化儀表板,並在這些方面創建自動化測試監控。
我們希望這些技巧可以幫助您提高使用 OnCrawl 的效率。 我們還有許多高級技巧要向您展示。 例如,請在 Twitter 上與我們分享您的#oncrawlhacks,我們很高興我們的用戶可以像使用我們的工具一樣獲得樂趣。