57 個常見的 A/B 測試錯誤以及如何避免它們
已發表: 2021-06-15
您是否正在運行 A/B 測試,但不確定它們是否正常工作?
您想了解 A/B 測試時的常見錯誤,以免在失敗的廣告系列上浪費寶貴的時間嗎?
嗯,好消息! 在本文中,我們將向您介紹我們看到的 57 個常見(有時不常見)的 A/B 測試錯誤,因此您可以避開它們或意識到它們何時發生并快速修復它們。
我們將這些分為 3 個關鍵部分:
- 開始測試前的錯誤,
- 測試過程中可能出現的問題,
- 測試完成後您可能會犯的錯誤。
你可以簡單地通讀一下,看看你是否自己做這些。
請記住:
每一次失敗都是寶貴的一課,無論是在測試中還是在設置錯誤中。 關鍵是向他們學習!
所以讓我們潛入...
- 甚至在您運行測試之前就可能犯的常見 A/B 測試錯誤
- #1。 在測試之前推送一些東西!
- #2。 沒有運行實際的 A/B 測試
- #3。 不測試以查看該工具是否有效
- #4。 使用低質量工具和內容閃爍
- #5。 沒有測試質量保證
- #6。 新的治療/變化是否有效?
- #7。 不遵循假設,只是測試任何舊事物
- #8。 有一個不可檢驗的假設
- #9。 沒有提前為你的測試設定一個明確的目標
- #10。 專注於表面指標
- #11。 只用量化數據形成測試思路
- #12。 複製你的競爭對手
- #13。 僅測試“行業最佳實踐”
- #14。 當高影響大獎勵/低懸的果實可用時,首先關注小影響任務
- #15。 一次測試多個事物,但不知道是哪個更改導致了結果
- #16。 未運行適當的預測試分析
- #17。 錯誤標記測試
- #18。 對錯誤的 URL 運行測試
- #19。 為您的測試添加任意顯示規則
- #20。 為您的目標測試錯誤的流量
- #21。 未能將回訪者排除在測試中並扭曲結果
- #22。 不從測試中刪除您的 IP
- #23。 不分割控制組變量(網絡效應)
- #24。 在季節性活動或主要站點/平台活動期間運行測試
- #25。 無視文化差異
- #26。 同時運行多個連接的活動
- #27。 不等的流量權重
- 您在測試期間可能犯的常見 A/B 測試錯誤
- #28。 沒有運行足夠長的時間來獲得準確的結果
- #29。 直升機監控/窺視
- #30。 不跟踪用戶反饋(如果測試影響直接、立即的操作,則尤其重要)
- #31。 在測試中進行更改
- #32。 在測試中更改流量分配百分比或刪除表現不佳的人
- #33。 當您有準確的結果時不停止測試
- #34。 在情感上投入到失去變化中
- #35。 運行測試時間過長並且跟踪下降
- #36。 不使用允許您停止/實施測試的工具!
- 測試完成後可能犯的常見 A/B 測試錯誤
- #37。 一考就放棄!
- #38。 在測試所有版本之前放棄一個好的假設
- #39。 一直期待巨大的勝利
- #40。 測試後不檢查有效性
- #41。 未正確讀取結果
- #42。 不按細分查看結果
- #43。 不從結果中學習
- #44。 接受失敗者
- #45。 不對結果採取行動
- #46。 不迭代和改進勝利
- #47。 不分享其他領域或部門的獲獎結果
- #48。 不在其他部門測試這些變化
- #49。 單頁迭代過多
- #50。 測試不夠!
- #51。 不記錄測試
- #52。 忘記誤報,不仔細檢查大型提升活動
- #53。 不跟踪下線結果
- #54。 未能考慮首要性和新穎性效應,這可能會使治療結果產生偏差
- #55。 運行考慮期變化
- #56。 X 次後不再重新測試
- #57。 只測試路徑而不測試產品
- 結論
甚至在您運行測試之前就可能犯的常見 A/B 測試錯誤
#1。 在測試之前推送一些東西!
您可能有一個很棒的新頁面或網站設計,並且您真的很想在沒有測試的情況下將其上線。
等一下!
首先運行一個快速測試,看看它是如何工作的。 您不想在沒有獲得一些數據的情況下推動徹底的變革,否則您可能會失去銷售和轉化。
有時,這種新變化可能會導致性能大幅下降。 所以先給它一個快速測試。
#2。 沒有運行實際的 A/B 測試
A/B 測試通過將單個流量源運行到控制頁面和該頁面的變體來工作。 目標是確定您實施的更改是否使受眾更好地轉換並採取行動。
問題是,為了確保這個測試是可控的和公平的,我們需要使用特定的參數來運行這個測試。 我們需要在同一時間段內查看活動的相同流量來源,這樣我們就沒有任何外部因素影響一個測試而不影響另一個測試。
有些人犯了按順序運行測試的錯誤。 他們將當前頁面運行 X 時間,然後新版本運行 X 時間,然後測量差異。
這些結果並不完全準確,因為在這些測試窗口期間可能發生了許多事情。 您可能會獲得大量新流量,舉辦活動,導致 2 個頁面的受眾和結果大相徑庭。
因此,請確保您正在運行實際的 A/B 測試,在該測試中,您在 2 個版本之間分配流量並同時測試它們。
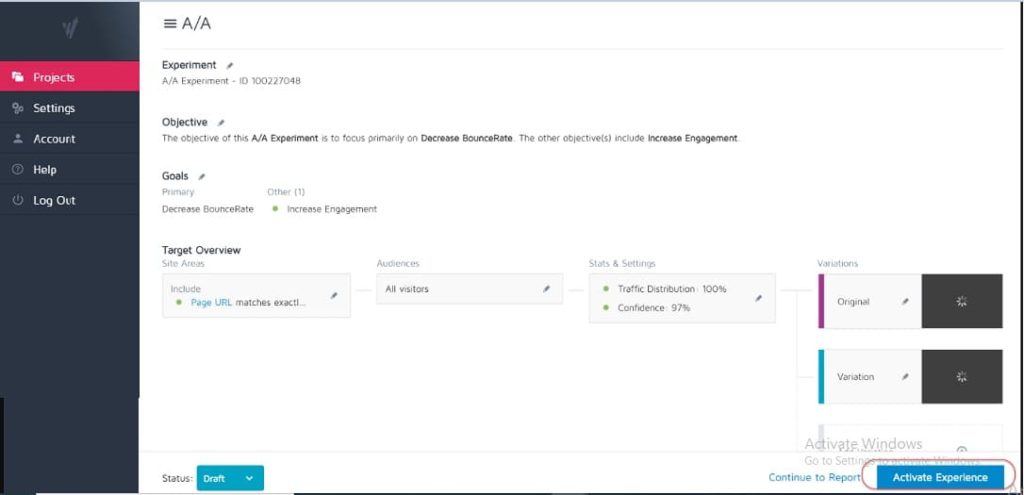
#3。 不測試以查看該工具是否有效
沒有測試工具是 100% 準確的。 剛開始時您可以做的最好的事情是運行 A/A 測試以查看您的工具的精確度。
如何? 只需運行一個測試,在單個頁面之間以 50:50 的比例分配流量。 (確保它是您的受眾可以轉換的頁面,以便您可以衡量特定結果。)
為什麼?
因為你的兩組觀眾看到的是完全相同的頁面,所以測試雙方的轉換結果應該是相同的,對吧?
好吧,有時它們不是,這意味著您的工具可能設置不正確。 因此,請在運行任何廣告系列之前檢查您的測試工具。
#4。 使用低質量工具和內容閃爍
有些工具不如其他工具好。 他們做這項工作,但在交通負荷或“眨眼”和閃爍下掙扎。

這實際上會導致您的測試失敗,即使您有一個潛在的獲勝變體。
假設您要拆分測試頁面上的圖像。 控制頁面加載正常,但新測試圖像和原始圖像之間的變化僅在幾分之一秒內閃爍。 (或者也許每次用戶上下滾動頁面時。)
這可能會分散注意力並導致信任問題,從而降低您的轉化率。
事實上,您的新圖像在理論上甚至可以更好地轉換,但工具閃爍會降低結果,使您對該圖像的測試不准確。
確保您有足夠好的工具進行測試。
(這是一個非常重要的用戶體驗因素,以至於谷歌目前正在調整他們對沒有閃爍或移動元素的網站的排名)。
#5。 沒有測試質量保證
一個超級簡單的錯誤,但你檢查過一切正常嗎?
- 你經歷過銷售過程嗎?
- 有其他人嗎? (在未緩存的設備上,因為有時瀏覽器中保存的內容與頁面的外觀不同。)
- 頁面加載正常嗎? 他們慢嗎? 設計是否混亂?
- 所有按鈕都有效嗎?
- 收入跟踪是否有效?
- 您是否檢查過該頁面是否可以在多個設備上運行?
- 如果出現問題,您是否有錯誤報告?
在您開始為任何廣告系列投放流量之前,這一切都值得一試。
獲取我們的 A/B 測試質量保證清單。 這是一個可填寫的 PDF,您每次對測試進行 QA 時都需要返回。
#6。 新的治療/變化是否有效?
同樣,在運行測試之前,您是否已經完成並測試了您的新變體是否有效?
這可能是 QA 測試中被忽視的一部分,但活動通常會在按鈕損壞、舊鏈接等情況下運行。 先檢查,再測試。
#7。 不遵循假設,只是測試任何舊事物
有些人只是在沒有真正考慮過的情況下測試任何東西。
他們對更改有了想法並想對其進行測試,但沒有真正分析頁面當前的轉換方式,甚至沒有真正分析他們正在測試的更改為什麼會產生影響。 (可能是他們降低了轉化率但甚至不知道,因為他們還沒有跟踪基線結果)。
形成一個關於問題所在、原因以及如何解決問題的假設將對您的測試程序產生巨大影響。

#8。 有一個不可檢驗的假設
並非所有假設都是正確的。 這可以。 事實上,這個詞的字面意思是“我有一個基於 X 信息的想法,我認為 Y 可能發生在 Z 情況下”。
但是您需要一個可測試的假設,這意味著可以通過測試來證明或反駁它。 可檢驗的假設將創新付諸實踐並促進積極的實驗。 它們可能導致成功(在這種情況下你的預感是正確的)或失敗——表明你一直都是錯的。 但他們會給你洞察力。 這可能意味著您的測試需要更好地執行,您的數據不正確/讀取錯誤,或者您發現了一些不起作用的東西,這通常可以讓您深入了解可能工作得更好的新測試。
#9。 沒有提前為你的測試設定一個明確的目標
一旦有了假設,您就可以使用它與您想要實現的特定結果保持一致。
有時人們只是運行一個活動,看看有什麼變化,但如果你清楚地知道你想看到哪個特定元素,你肯定會獲得更多的潛在客戶/轉化或銷售。
(這也阻止了你看到一個重要元素的下降,但認為測試是勝利,因為它“獲得了更多的份額”。)
說到這個……
#10。 專注於表面指標
您的測試應始終與 Guardrail 指標或直接影響您的銷售的某些元素相關聯。 如果有更多潛在客戶,那麼您應該知道潛在客戶的價值以及提高轉化率的價值。
同時,通常應該避免與或驅動可衡量結果無關的指標。 更多的 Facebook 喜歡並不一定意味著更多的銷售。 刪除那些社交分享按鈕,然後看看您獲得了多少潛在客戶。 警惕虛榮指標並記住,僅僅因為修復了一個洩漏並不意味著其他地方也沒有另一個洩漏!
以下是 Ben Labay 的實驗項目常見護欄指標列表:
#11。 只用量化數據形成測試思路
使用定量數據來獲取想法很棒,但也存在一些缺陷。 特別是如果我們使用的唯一數據來自我們的分析。
為什麼?
我們可以從我們的數據中知道有 X 人沒有點擊,但我們可能不知道為什麼。
- 按鈕是否在頁面下方太低?
- 不清楚嗎?
- 它與觀眾想要的一致嗎?
- 它甚至工作嗎?
最好的測試人員也會傾聽他們的聽眾。 他們找出他們需要什麼,是什麼推動他們前進,是什麼阻礙了他們,然後用它來製定新的想法、測試和書面副本。
有時,您的用戶會因信任問題和自我懷疑而受阻。 其他時候,它的清晰度和破損的形式或糟糕的設計。 關鍵是這些是定量數據無法始終告訴您的事情,因此請始終詢問您的聽眾並使用它來幫助您進行計劃。
#12。 複製你的競爭對手
準備好秘密了嗎?
很多時候,您的競爭對手只是隨心所欲。 除非他們有長期開展提升活動的人,否則他們可能只是在嘗試一些東西,看看什麼是有效的,有時沒有使用任何數據來表達他們的想法。
即便如此,對他們有用的東西,也可能對你不起作用。 所以,是的,用它們來激發靈感,但不要將你的測試想法限制在你看到它們所做的事情上。 你甚至可以走出你的行業尋找靈感,看看它是否會引發一些假設。
#13。 僅測試“行業最佳實踐”
同樣,對一個人有用的東西並不總是對另一個人有用。
例如,滑塊圖像通常具有糟糕的性能,但在某些網站上,它們實際上可以推動更多的轉化。 測試一切。 你沒有什麼可失去的,也沒有什麼可得到的。
#14。 當高影響大獎勵/低懸的果實可用時,首先關注小影響任務
我們都可能因專注於細節而感到內疚。 我們可能有一個想要更好地執行並測試佈局設計和圖像甚至按鈕顏色的頁面。 (我個人有一個處於第 5 次迭代的銷售頁面。)
問題是,現在可能有更重要的頁面供您測試。
最重要的是優先考慮影響:
- 這個頁面會直接影響銷售嗎?
- 銷售過程中是否還有其他頁面表現不佳?
如果是這樣,請首先關注那些。
銷售頁面上 1% 的提升是很棒的,但是讓他們到達那裡的頁面上 20% 的提升可能更重要。 (特別是如果該特定頁面是您失去大部分觀眾的地方。)
有時我們不僅在尋找更多的提升,而是為了解決一些瓶頸問題。
測試和改進最大的影響,最低的掛果優先。 這就是代理機構所做的,這就是為什麼他們執行與內部團隊相同數量的測試,但具有更高的投資回報率。 代理機構在相同數量的測試中獲得的勝利增加了 21%!
#15。 一次測試多個事物,但不知道是哪個更改導致了結果
一次更改多項內容並重新設計整個頁面的激進測試並沒有錯。
事實上,這些徹底的重新設計有時會對您的投資回報率產生最大的影響,即使您是一個低流量的網站,尤其是當您處於平穩狀態並且似乎無法獲得更多提升時。
但請記住,並不是每個 A/B 測試都應該針對這樣的徹底改變。 99% 的時間我們只是在測試單個事物的變化,比如
- 新頭條
- 新圖像
- 相同內容的新佈局
- 新定價等
進行單元素測試時的關鍵就是這樣。 讓你的測試只改變一個元素,這樣你就可以看到是什麼造成了改變並從中學習。 改變太多,你不知道什麼有效。
#16。 未運行適當的預測試分析
您的測試組中有足夠的訪客嗎? 測試甚至值得你花時間嗎?
算一算! 在運行測試之前確保您有足夠的流量 - 否則只會浪費時間和金錢。 許多測試由於流量不足或靈敏度低(或兩者兼而有之)而失敗。
執行測試前分析以確定您的實驗的樣本量和最小可檢測效應。 像 Convert's 這樣的 A/B 測試意義計算器會告訴你測試的樣本量和 MDE,這將幫助你決定是否值得運行。 您還可以使用此信息來確定測試應該運行多長時間以及在得出測試成功與否之前您不想錯過的提升幅度。
#17。 錯誤標記測試
一個超級簡單的錯誤,但它確實發生了。 您錯誤地標記測試,然後得到錯誤的結果。 變體獲勝,但它被命名為控制,然後你永遠不會實現勝利並留在失敗者身邊!
總是仔細檢查!
#18。 對錯誤的 URL 運行測試
另一個簡單的錯誤。 頁面 URL 輸入錯誤,或者測試正在運行到您進行更改的“測試站點”,而不是實時版本。
它對您來說可能看起來不錯,但實際上不會為您的觀眾加載。
#19。 為您的測試添加任意顯示規則
同樣,你需要用你的治療來測試一件事,而不是別的。
如果是圖像,則測試圖像。 其他一切都應該相同,包括人們可以看到兩個頁面的時間!
一些工具允許您測試一天中的不同時間,以了解流量在不同時間範圍內的表現。 如果您想查看最佳流量何時出現在您的網站上,這很有幫助,但如果頁面被誰看到它們並且有不同的變化,則沒有幫助。
例如,我們自己的博客流量在周末下降(就像大多數商業博客一樣)。
想像一下,如果我們在控制頁面上的周一至週三運行測試,然後在治療中顯示來自周五至週日的流量? 測試的流量要低得多,而且結果可能會有所不同。
#20。 為您的目標測試錯誤的流量
理想情況下,在運行測試時,您希望確保只測試一部分受眾。 通常,它是新的自然訪問者,看看他們第一次在您的網站上的反應如何。

有時您可能想要測試重複訪問者、電子郵件訂閱者甚至付費流量。 訣竅是一次只測試其中一個,這樣您就可以準確表示該組在該頁面上的表現。
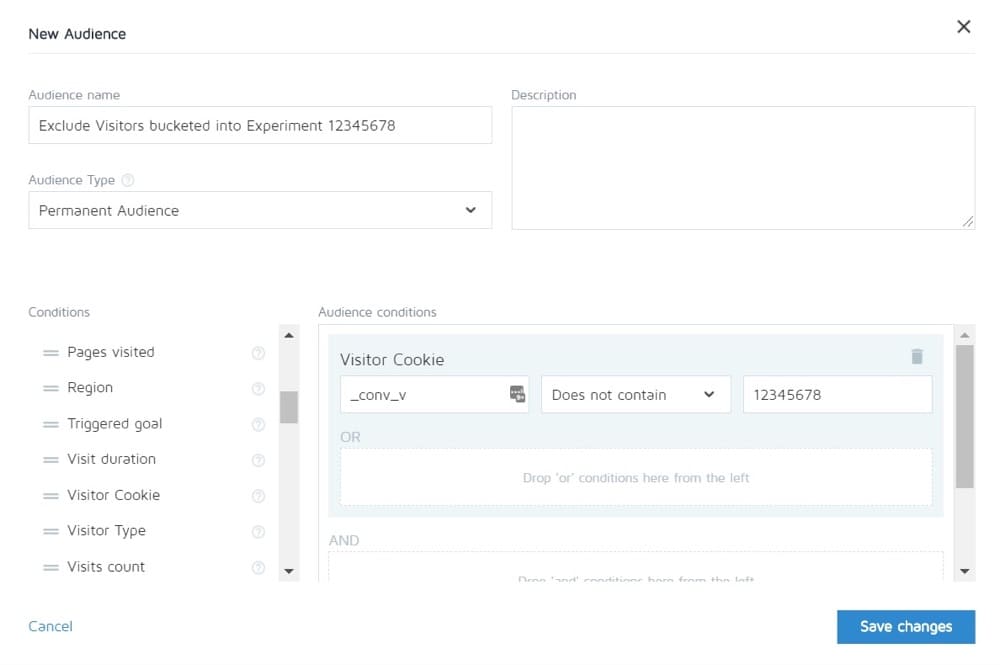
設置測試時,請選擇您要使用的受眾,並刪除任何可能污染結果的其他受眾,例如回訪者。
#21。 未能將回訪者排除在測試中並扭曲結果
我們稱之為樣本污染。
基本上,如果訪問者看到您網站的頁面,返回並看到您的變體,那麼他們的反應將與他們只看到其中一個時截然不同。
僅僅因為這些額外的交互,他們可能會感到困惑、反彈,甚至轉換得更高。
問題是,它會導致您的數據受到污染且準確性降低。 理想情況下,您希望使用一種工具來隨機化他們看到的頁面,然後始終向他們顯示相同的版本,直到測試結束。
#22。 不從測試中刪除您的 IP
說到樣本污染,這是污染數據的另一種方式(無論如何,這是一種很好的分析實踐)。
確保從您的分析和測試工具中阻止您和您員工的 IP 地址。 您最不希望的事情是您或團隊成員在頁面上“簽到”並在您的測試中被標記。
#23。 不分割控制組變量(網絡效應)
另一種很少見但可能發生的污染選擇,尤其是如果您有一個面向受眾的網絡。
這是一個例子。
假設您有一個平台可以讓您的觀眾進行交流。 也許是 Facebook 頁面或評論部分,但每個人都可以訪問它。
在這種情況下,您可能讓人們看到一個頁面而其他人看到一個變化,但他們都在同一個社交網絡上。 這實際上會扭曲您的數據,因為它們會影響彼此的選擇以及與頁面的交互。 在測試新功能以防止網絡效應問題時,Linkedin 一直在對其受眾進行細分。
理想情況下,您希望分離 2 個測試組之間的通信,直到測試完成。
#24。 在季節性活動或主要站點/平台活動期間運行測試
除非您正在測試季節性事件,否則您永遠不想在假期或任何其他重大事件(例如特殊銷售或世界事件發生)期間運行測試活動。
有時你無能為力。 您將進行一次測試運行,而 Google 只是實施了新的核心更新,並在廣告系列中期*咳嗽*弄亂了您的流量來源。
最好的辦法就是在一切都結束後重新運行。
#25。 無視文化差異
您可能有一個頁面的目標,但同時也在運行一個全球廣告系列,其中包含以不同語言和不同國家/地區顯示的多種變體。
在運行測試時,您需要考慮到這一點。 可以全局進行一些更改,例如簡單的佈局轉換或添加信任信號等。
其他時候,您需要考慮文化差異點。 人們如何看待佈局、他們如何查看圖像以及頁面上的頭像。
Netflix 使用他們所有節目的縮略圖來做到這一點,測試可能吸引不同觀眾的不同元素(取而代之的是該國著名的特定演員)。

在一個國家/地區獲得點擊的內容在其他國家/地區可能會大不相同。 你不知道,直到你測試!
#26。 同時運行多個連接的活動
很容易興奮並想要一次運行多個測試。
請記住:您可以同時對銷售過程中的相似點運行多個測試,但不要對漏斗中的多個連接點運行多個測試。
這就是我的意思。
您可以同時在每個潛在客戶生成頁面上輕鬆運行測試。
但是,您不希望同時測試潛在客戶頁面、銷售頁面和結帳頁面,因為這會在您的測試過程中引入許多不同的元素,需要大量的流量和轉化才能獲得任何有用的洞察力。
不僅如此,每個元素都會對下一頁產生不同的影響,有好有壞。 除非您每周有成千上萬的訪問者,否則您可能很難獲得準確的結果。
因此,請耐心等待,一次只測試一個階段或過程中未連接的頁面。
邊注:
Convert 允許您將一個實驗中的人排除在其他實驗之外。 所以理論上你可以測試整個銷售週期,然後只看到其他頁面的控制。
#27。 不等的流量權重
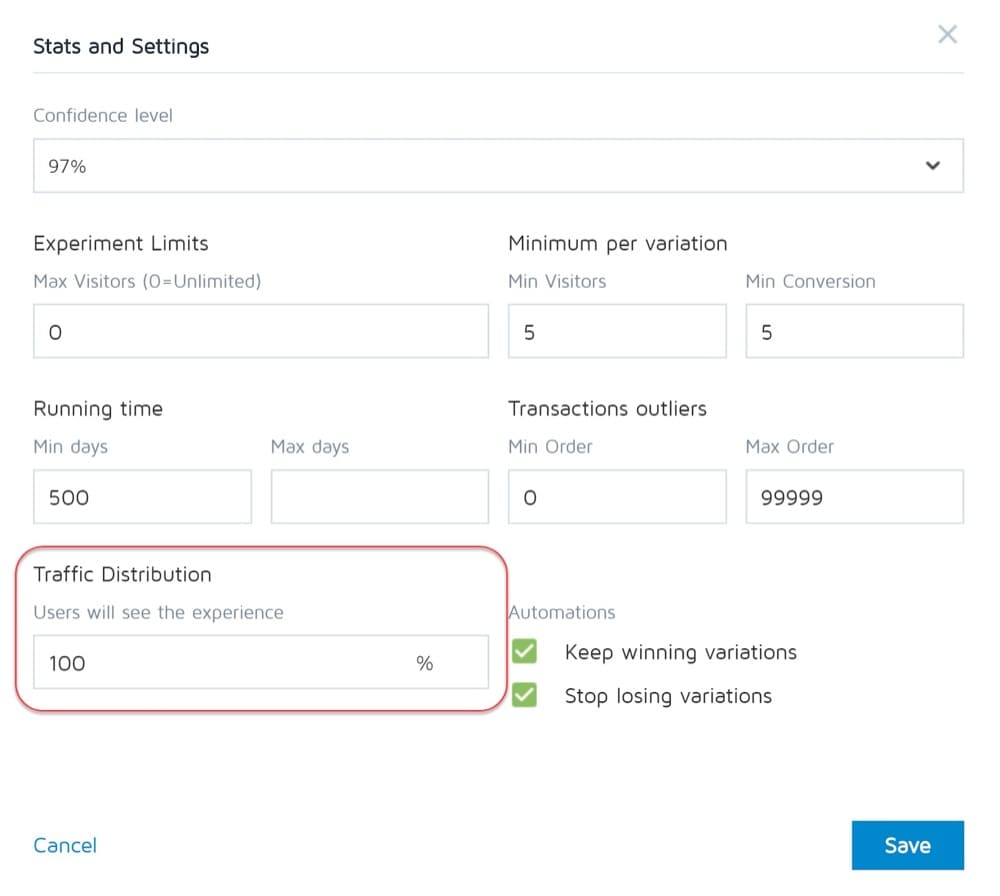
無論您運行的是 A/B、A/B/n 還是多變量測試,都沒有關係。 您需要為每個版本分配相等的流量,以便獲得準確的測量結果。
從一開始就將它們設置為相等。 大多數工具都允許您執行此操作。
您在測試期間可能犯的常見 A/B 測試錯誤
#28。 沒有運行足夠長的時間來獲得準確的結果
當您想要測試並獲得準確的結果時,需要考慮 3 個重要因素:
- 統計學意義,
- 銷售週期,以及
- 樣本量。
所以讓我們分解一下。
大多數人在他們的測試工具告訴他們一個結果比另一個結果更好並且結果具有統計意義時結束測試,即如果測試繼續像這樣執行,那麼這就是絕對的贏家。
問題是您有時只需少量流量即可快速點擊“stat sig”。 隨機地,所有轉換都發生在一個頁面上,而沒有發生在另一頁上。
不過不會一直這樣。 可能是測試啟動了,這是發薪日,那天你得到了一大筆銷售額。
這就是為什麼我們需要考慮銷售週期。 銷售和流量可能會根據一周中的某一天或一個月而波動。 為了更準確地表示測試的運行情況,理想情況下需要運行 2 到 4 週。
最後,您有樣本量。
如果您運行測試一個月,那麼您可能會獲得足夠的流量來獲得準確的結果。 太少了,測試就無法給你一個信心水平,它會按應有的方式執行。
所以根據經驗,
- 獲得 95% 的置信度。
- 跑一個月。
- 提前確定您需要的樣本量,並且在測試成功之前不要停止測試,或者您會得到一些驚人的結果,毫無疑問地證明您有贏家。
#29。 直升機監控/窺視
Peeking 是一個術語,用於描述測試人員何時查看他們的測試以了解其執行情況。
理想情況下,我們永遠不想在運行後查看我們的測試,並且在它完成一個完整的周期、具有正確的樣本量並且達到統計顯著性之前,我們永遠不會對其做出決定。
但是……如果測試沒有運行怎麼辦?
如果有東西壞了怎麼辦?
好吧,在那種情況下,你真的不想等一個月才能看到它壞了,對吧? 這就是為什麼我總是在設置運行 24 小時後檢查測試是否在控制和變化中獲得結果。
如果我可以看到他們都在接收流量並獲得點擊/轉化,那麼我就走開,讓它做它的事情。 在測試完成之前,我不會做出任何決定。
#30。 不跟踪用戶反饋(如果測試影響直接、立即的操作,則尤其重要)
假設測試正在獲得點擊並且流量已分配,所以它*看起來*像是在工作,但突然你開始收到人們無法填寫銷售表格的報告。 (或者更好的是,您會收到一個自動警報,表明護欄指標已降至可接受的水平以下。)
好吧,那麼您的第一個想法應該是某些東西壞了。
並非總是如此。 您可能會從不與您的報價產生共鳴的受眾那裡獲得點擊,但以防萬一,檢查該表單是值得的。
如果它壞了,那麼修復它並重新啟動。
#31。 在測試中進行更改
從最後幾點可能已經很清楚了,但是一旦測試上線,我們就不想對測試進行任何更改。
當然,有些東西可能會損壞,但這是我們應該做出的唯一改變。 我們不會更改設計、複製或任何東西。
如果測試有效,讓它運行並讓數據決定什麼有效。
#32。 在測試中更改流量分配百分比或刪除表現不佳的人
就像我們不會更改正在測試的頁面一樣,我們也不會刪除任何變體或更改測試中的流量分佈。
為什麼?
假設您正在運行一個 A/B/n 測試,其中包含一個控件和 3 個變體。 你開始測試,一周後你調皮地偷看一眼,發現有兩個版本做得很好,一個做得很差。
現在很想關閉“丟失”的變體並在其他變體之間重新分配流量,對嗎? 哎呀……你甚至可能想把額外的 25% 的流量發送給表現最好的人,但不要這樣做。
為什麼?
這種重新分配不僅會影響測試性能,還會直接影響結果以及它們在報告工具上的顯示方式。
之前被分桶到已刪除變體的所有用戶都需要重新分配到一個變體,並且將在短時間內看到更改的網頁,這可能會影響他們的行為和後續選擇。
這就是為什麼您永遠不會在中途更改流量或關閉變化的原因。 (還有為什麼你不應該偷看!)
#33。 當您有準確的結果時不停止測試
有時您只是忘記停止測試!
它會繼續運行並將 50% 的受眾提供給較弱的頁面,並將 50% 提供給獲勝者。 哎呀!
幸運的是,可以設置轉換體驗等工具來停止活動,並在達到特定標準(如樣本量、統計信息、轉換和時間範圍)後自動顯示獲勝者。
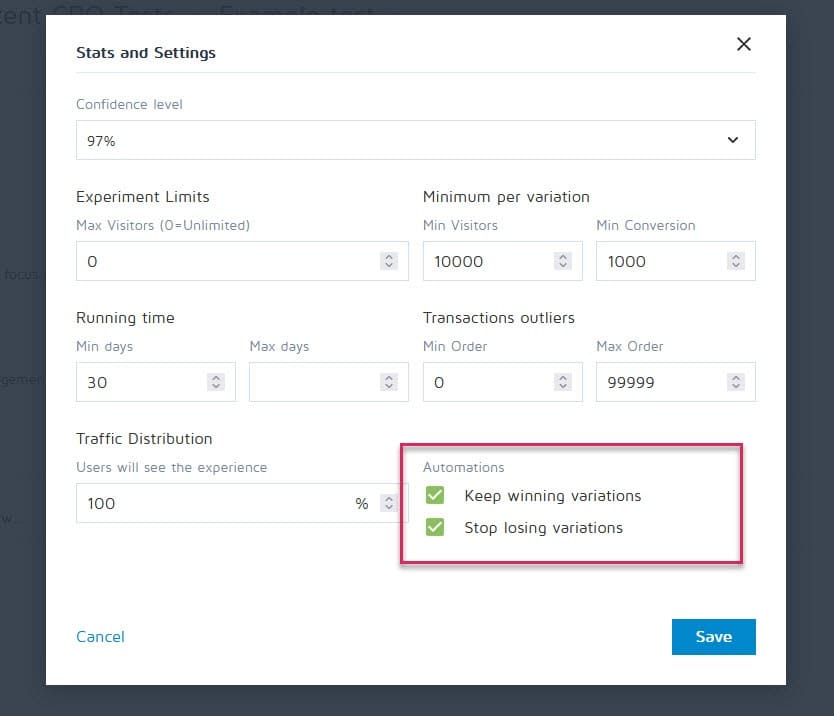
#34。 在情感上投入到失去變化中
作為測試人員,我們需要保持公正。 然而,有時,您可能有一個您喜歡的特定設計或想法,並且確信它應該獲勝,因此您不斷延長測試時間,看看它是否能領先。
把繃帶拉下來。
您可能有一個需要改進的好主意,但在結束當前測試之前您不能這樣做。
#35。 運行測試時間過長並且跟踪下降
這是另一個潛在的樣本污染問題。
如果您運行測試超過 4 週,您可能會看到用戶的 cookie 丟失。 這可能導致缺乏對事件的跟踪,但它們甚至可能再次返回並污染樣本數據。
#36。 不使用允許您停止/實施測試的工具!
另一個罕見的問題。
一些測試程序堅持創建硬編碼測試。 即開發人員和工程師從頭開始構建活動。
但是,當測試結束並且您需要等待同一位開發人員將其關閉並安裝獲勝的變體時,這並不是很好。 這不僅令人沮喪,而且會嚴重減慢您可以運行的測試數量,甚至會降低頁面在等待上線時的投資回報率。
測試完成後可能犯的常見 A/B 測試錯誤
#37。 一考就放棄!
10 個測試中有 9 個通常是失敗的。
這意味著您需要運行 10 次測試才能獲得獲勝者。 這需要努力,但總是值得的,所以不要在一場運動之後停下來!
#38。 在測試所有版本之前放棄一個好的假設
失敗可能僅僅意味著您的假設是正確的,但需要更好地執行。
嘗試新的方式、新的設計、新的佈局、新的圖像、新的頭像、新的語言。 你有這個想法,看看你是否可以更好地執行它。
CXL 花了 21 次迭代來改進客戶的頁面,但轉化率從 12.1% 提高到了 79.3%。
#39。 一直期待巨大的勝利
事實是,每 10 次或更多獲勝活動中,您可能只能獲得一次巨大的勝利。
還行吧。 我們不斷測試並不斷改進,因為隨著時間的推移,即使增加 1% 的化合物。 改進它並將其提高到 2%,您現在已經將效率提高了一倍。
哪種類型的測試產生最好的結果?
事實上,不同的實驗有不同的效果。 根據 Jakub Linowski 對 300 多次測試的研究,佈局實驗往往會產生更好的結果。
最難優化的屏幕類型是什麼? 同一項研究顯示它是結帳屏幕(25 次測試的中位數效果為 +0.4%)。
#40。 測試後不檢查有效性
這樣測試就結束了。 你跑了足夠長的時間,看到了結果,得到了 stat sig,但你能相信數據的準確性嗎?
可能是在測試過程中出現了問題。 檢查永遠不會有害。
#41。 未正確讀取結果
你的結果真正告訴你什麼? 未能正確閱讀它們很容易成為潛在的贏家,並且看起來像是徹底的失敗。
- 深入分析您的分析。
- 查看您擁有的任何定性數據。
什麼有效,什麼無效? 為什麼會這樣?
你越了解你的結果越好。
#42。 不按細分查看結果
潛得更深一點總是值得的。
例如,一個新的變體似乎轉化率很低,但在移動設備上,它的轉化率提高了 40%!
您只能通過將其細分為您的結果來找到它。 看看使用的設備和那裡的結果。 您可能會發現一些有價值的見解!
請注意您的分段大小的重要性。 您可能沒有足夠的流量到每個細分市場來完全信任它,但您始終可以運行僅限移動設備的測試(或任何渠道)並查看它的性能。
#43。 不從結果中學習
失敗的測試可以讓您深入了解需要進一步改進或進行更多研究的地方。 作為 CRO 最煩人的事情是看到拒絕從他們剛剛看到的東西中學習的客戶。 他們有數據但不使用它……
#44。 接受失敗者
或者更糟的是,他們接受了失敗的變化。
也許他們更喜歡這種設計,轉換率只有 1% 的差異,但隨著時間的推移,這些影響會復合。 拿走那些小胜利!
#45。 不對結果採取行動
又更糟了?
獲得勝利但不實施! 他們擁有數據,卻什麼也不做。 沒有變化,沒有洞察力,也沒有新的測試。
#46。 不迭代和改進勝利
有時你可以搭便車,但還有更多。 就像我們之前說的,每場胜利都會給你帶來兩位數的提升是非常罕見的。
But that doesn't mean that you can't get there by running new iterations and improvements and clawing your way up 1% at a time.
It all adds up so keep on improving!
#47. Not sharing winning findings in other areas or departments
One of the biggest things we see with hyper-successful/mature CRO teams is that they share their winnings and findings with other departments in the company.
This gives other departments insights into how they can also improve.
- Find some winning sales page copy? Preframe it in your adverts that get them to the page!
- Find a style of lead magnet that works great? Test it across the entire site.
#48. Not testing those changes in other departments
And that's the key here. Even if you share insights with other departments, you should still test to see how it works.
A style design that gives lift in one area might give a drop in others, so always test!
#49. Too much iteration on a single page
We call this hitting the 'local maximum'.
The page you're running tests on has plateaued and you just can't seem to get any more lift from it.
You can try radical redesigns, but what next?
Simply move onto another page in the sales process and improve on that. (Ironically this can actually prove to give a higher ROI anyway.)
Taking a sales page from a 10% to 11% conversion can be less important than taking the page that drives traffic to it from 2% to 5%, as you will essentially more than double the traffic on that previous page.
If in doubt, find the next most important test on your list and start improving there. You may even find it helps conversion on that stuck page anyway, simply by feeding better prospects to it.
#50. Not testing enough!
Tests take time and there's just only so many that we can run at once.
所以,我們能做些什麼?
Simply reduce the downtime between tests!
Complete a test, analyze the result, and either iterate or run a different test. (Ideally, have them queued up and ready to go).
This way you'll see a much higher return for your time investment.
#51. Not documenting tests
Another habit mature CRO teams have is creating an internal database of tests, which includes data about the page, the hypothesis, what worked, what didn't, the lift, etc.
Not only can you then learn from older tests, but it can also stop you from re-running a test by accident.
#52. Forgetting about false positives and not double-checking huge lift campaigns
Sometimes a result is just too good to be true. Either something was set up or recording wrong, or this just happens to be that 1 in 20 tests that gives a false positive.
所以,你可以做什麼?
Simply re-run the test, set a high confidence level, and make sure you run them for long enough.
#53. Not tracking downline results
When tracking your test results, it's also important to remember your end goal and track downline metrics before deciding on a winner.
A new variant might technically get fewer clicks through but drives more sales from the people who do click.
In this instance, this page would actually be more profitable to run, assuming the traffic that clicks continues to convert as well…
#54. Fail to account for primacy and novelty effects, which may bias the treatment results
Let's say you're not just targeting new visitors with a change, but all traffic.
We're still segmenting them so 50% see the original and 50% see the new version, but we're allowing past visitors into the campaign. This means people who've seen your site before, read your content, seen your calls to action, etc.
Also, for the duration of the campaign, they only see their specific test version.
When you make a new change, it can actually have a novelty effect on your past audience.
Maybe they see the same CTA all the time and now just ignore it, right? In this case, a new CTA button or design can actually see a lift from past visitors, not because they want it more now, but because it's new and interesting.
Sometimes, you might even get more clicks because the layout has changed and they're exploring the design.
Because of this, you will usually get an initial lift in response, but which dies back down over time.
The key when running your test is to segment the audience after and see if the new visitors are responding as well as the old ones.
If it's much lower, then it could be a novelty effect with the old users clicking around. If it's on a similar level, you might have a new winner on your hands.
Either way, let it run for the full cycle and balance out.
#55。 運行考慮期變化
測試時要考慮的另一件事是任何可能改變觀眾考慮期的變體。
我是什麼意思?
假設您通常不會立即獲得銷售。 潛在客戶可能處於 30 天甚至更長的銷售週期。
如果您正在測試直接影響他們考慮和購買時間的號召性用語,那將會扭曲您的結果。 一方面,您的控件可能會獲得銷售,但超出了測試期,因此您會錯過它們。
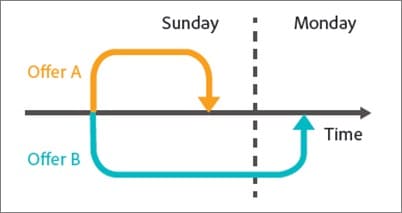
另一種情況是,如果你有一個提供交易的 CTA,一個讓他們現在想要採取行動的任何其他東西的價格點,那麼這幾乎總是會扭曲你的結果,使這個版本看起來轉換得更好。
請記住這一點,並在測試期間和之後仔細檢查您的分析以確保。
#56。 X 次後不再重新測試
這不是關於某個頁面或測試錯誤,而是更多關於測試理念。
是的,您可能有一個很棒的頁面,是的,您可能已經對其進行了 20 次迭代才能達到今天的水平。
問題是幾年後您可能需要再次檢查整個頁面。 環境變化,使用的語言和術語,產品可以調整。
隨時準備好回到舊的廣告系列並重新測試。 (擁有測試存儲庫的另一個原因很好。)
#57。 只測試路徑而不測試產品
幾乎我們所有人都專注於銷售路徑並為此進行測試。 但現實情況是,該產品還可以進行 A/B 測試和改進,甚至可以提供更高的提升。
想想 iPhone。

Apple 對其網站進行了測試並對其進行了改進,但產品的迭代和改進繼續推動著更多的提升。
現在,您可能沒有實體產品。 您可能有一個程序或數字報價,但是更多地了解您的受眾的需求並對其進行測試,然後將其帶回您的銷售頁面在提升方面可能是巨大的。
結論
所以你有它。 我們看到的 57 個常見和不常見的 A/B 測試錯誤以及如何避免它們。
您可以使用本指南來幫助您在未來的所有廣告系列中迴避這些問題。