
XML 站点地图:优化的关键建议
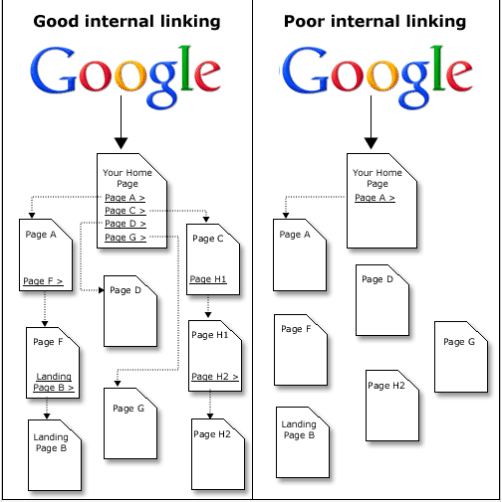
已发表: 2021-03-26您网站上的 Sitemap.xml 可以作为您希望 Google bot 索引的页面的良好导航。 即使您没有良好的内部链接,它也可以帮助您更快地找到主页。
在本文中,我们将针对 XML 站点地图的优化提出各种建议,以及这样做的好处。
功能和优势
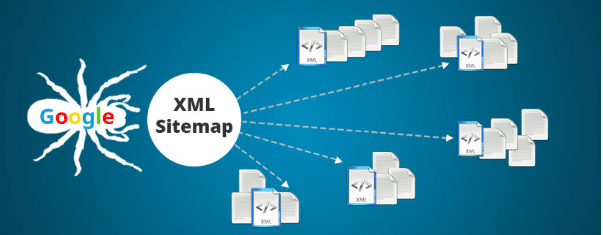
让机器人更容易工作,并允许获取您网站上不容易找到的页面和链接的“报告”。
一些 SEO 的好处如下:
- 更快的索引 - 搜索引擎会更快地找到新页面,因此在搜索结果中索引和显示网站的过程会更快。 这里的特殊之处在于它还可以帮助您进行去索引(更多信息在这里);
- 更好地索引内部页面——搜索引擎可以找到在抓取网站时没有找到的页面。 但这并不一定意味着它们都会被索引。
- 监控索引页面。 结合 Google Search Console,您可以找出哪些 URL 包含在 Google 索引的 XML Sitemap 中。
XML 站点地图重要吗?
对于以下站点很重要:
- 没有良好的结构或没有良好的内部链接分布;
- 有很多页面——XML 站点地图帮助搜索引擎找到新的或更新的页面;
- 不要有很多入站链接——这将是查找页面的好方法。
要求和格式
Google 支持多种站点地图格式。 所有格式和标准都可以在这个地址找到:https://www.sitemaps.org/index.html。
所有格式都将站点地图限制为 50MB(未压缩)和 50,000 个地址。 如果您有更大的文件或更多地址,则需要创建一个包含所有地图的索引文件(在下面的文章中描述)。
主要建议如下:
- 文件必须使用 UTF-8 编码;
- 它必须以一个打开的标签开始,并以一个关闭的标签结束,例如……。 ;
- 在标签中指定标准协议;
- 每个 URL 条目的主标记;
- 在标签中指定以协议(https或http)开头的URL,必须参与主标签才能保存。
XML 站点地图的其他可选属性
Google 不会在其网站上使用该属性。 所有其他属性都可用,但这取决于它们是否会被反映。 因此,请记住,Google 不会非常重视这些标签。 他们是:
- – 表示最后一次文件更改的日期。 必须是 W3C 日期时间格式;
- – 页面可能更新的频率。 此值提供有关搜索引擎的一般信息。 有效值可以是始终、每小时、每天、每周、每月、每年、从不。
应该记住,这个标签的值更多地被认为是一个提示而不是一个命令。 机器人看到这些信息并将其考虑在内,但最终会自行决定是否使用它,这取决于许多其他因素。
- – 将 URL 优先于您网站上的其他 URL。 有效值范围为 0.0。 到 1.0。
在这里,应该记住,这个优先级是相对的,不是机器人的强制性条件,或者至少还没有被接受。 但是,如果您决定尝试一下,请使用以下指南:
- 0 – 0.3:过时的新闻,不再有效但在历史上有用的信息;
- 4 – 0.7:博客文章、页面类别、常见问题;
- 8 – 1.0:主页、产品页面、所有内容优化良好的页面。
以下示例显示了一个站点地图,其中仅包含一个 URL,并使用了所有以斜体书写的可选标签。
https://netpeak.bg
2018-09-15
每月
0.8
识别重要页面
添加高质量页面和优化良好的页面。 整体质量对于更好的排名非常重要。 这是谷歌的一个重要因素,它可以让你在竞争中获得优先权。
我们不想访问低质量的页面,谷歌机器人也不想。 如果您将其引导至数千个对用户无用且未得到很好优化的页面,则这只会对您造成伤害。 什么是高质量页面? 简而言之,这些页面是:
- 有足够的独特内容;
- 通过提示采取行动(评论、评论等)快速吸引用户;
- 包括图片、视频等;
- 不违反 Google 政策;
为索引打开的页面
爬取预算一般代表单位时间(天、周、月等)爬取的页面数。 因此,不建议不必要地浪费它。
不应将包含“Noindex”元标记的页面添加到站点地图中。 遵循逻辑顺序对一切都很重要。
有必要进行自动检查,并且不包括为索引而关闭的地址。
建议遵循以下说明:
- 如果页面 https://example.com/category/product 有元标记“noindex”,则不应包含在站点的 XML 映射中;

- 当通过 robots.txt 关闭页面以进行索引时,它不应包含在 XML 映射中:
不允许:/类别/产品
无索引:/类别/产品
- 如果通过 HTTP 标头中的 X-Robots-Tag 关闭页面以进行索引,则它也不应该包含在站点的 XML 映射中:
HTTP/1.1 200 正常
日期:格林威治标准时间 2010 年 5 月 25 日星期二 21:42:43
(……)
X-Robots-标签:noindex
(……)
页面的规范版本
通过具有相似内容的多个 URL 访问单个页面将被 Google 视为重复。
您必须使用“link rel canonical”属性来指示机器人哪个是“主”页面,应该对哪个页面进行爬网和索引。

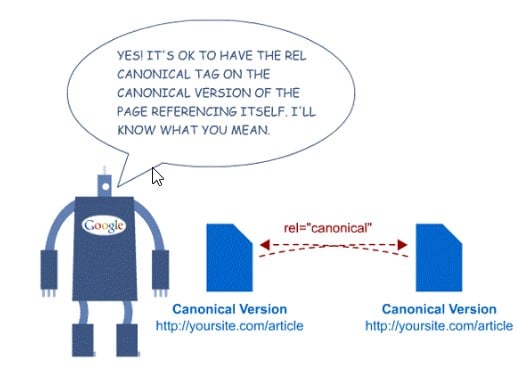
例如,如果页面 https://example.com/category/product-1 对 https://example.com/product 具有规范,则 http://example.com/category/product-1 不应参与XML 站点地图。
您应该执行自动检查,因为流程的自动化肯定会给您带来更少的麻烦并节省您进行手动检查的时间。
返回 200 OK 的页面
包括返回 200 OK 响应的地址。 进行自动检查并且不包括返回 200 OK 以外的响应的地址(例如 404、301 等)非常重要。
例如,如果页面 https://example.com/product 返回的响应不是 200 OK,则它不应参与站点地图。

您可以使用以下工具进行检查:https://soft.galinov.com/ 进行检查。
来自分页的页面
不必在 sitemap.xml 中绝对包含所有页面。 如果描述正确,该机器人足够聪明,可以从相关类别的第一页导航。 建议执行以下操作:
- 仅包括类别的主页;
- 用 rel = next / rel = prev 标记页面,以便机器人可以看到它们之间的连接;
- 分页的每一页都应该有自己的规范指南,而不是主页,因为如果反过来,这意味着你告诉机器人“我有 5,000 个产品和 20 个页面并不重要,他们和第一个一样。”
例如,页面 https://example.com/category/page-2 不应参与地图。 在这里你可以找到谷歌的官方意见,以及他们的建议:
最小化文件大小
2016 年,Google 和 Bing 将文件大小从 10MB 增加到 50MB,但保持站点地图尽可能小仍然是一个好习惯。

当然,这没什么好担心的,但是如果您的站点地图包含超过 50,000 个 URL 或大小超过 50MB,则应该将其分解为更多的 XML 地图。 在这种情况下,应在单独的站点地图索引文件中描述对所有 XML 地图的引用。
什么是 XML 站点地图索引文件
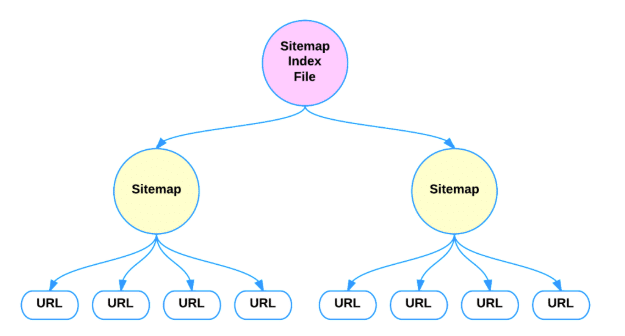
您可以提交多个 Sitemap 文件,但每个文件必须符合上述规则。 如果需要,您可以根据需要使用 gzip 压缩文件以减小其大小。
索引文件的 XML 格式与正常的站点地图格式非常相似。 它必须包含:
- 打开和关闭标签为 ;
- 每个站点地图的条目,其主要 XML 属性为;
- 标记到主要属性。
还包括推荐的属性。
注意:站点地图索引文件只能列出同一站点上的地图。 例如:
https://example.com/sitemap_index.xml 可能包含位于 https://example.com 的地图,但不包含位于 https://www.saitprimer.com 或 https://www.example.com 的地图
与所有其他文件一样,索引文件必须使用 UTF-8 编码。
以下示例显示了列出两个地图的站点地图索引:
http://www.example.com/sitemap1.xml.gz
2018-10-01T18:23:17+00:00
http://www.example.com/sitemap2.xml.gz
2017-01-01
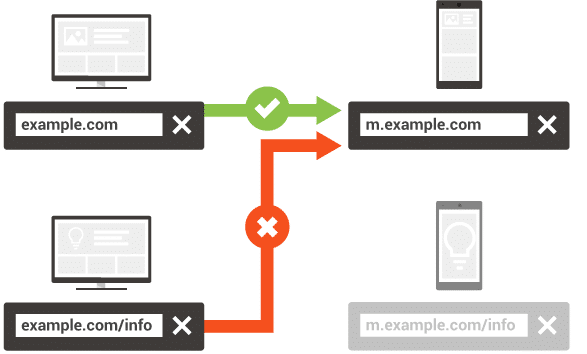
手机版说明
我们需要帮助 Google bot 找到我们的内容并了解桌面和移动页面之间的联系。 在 XML 站点地图中,必须为桌面版页面添加 rel = “alternate” 属性,如下所示:
xmlns:xhtml=”http://www.w3.org/1999/xhtml”>
http://www.example.com/page-1/
<xhtml:链接
相对=“替代”
媒体=“仅屏幕和(最大宽度:640px)”
href="http://m.example.com/page-1" />
请记住,每个桌面页面需要对应一个移动版本的页面。 例如,不建议通过 rel = “alternate” 将多个桌面页面链接到移动版本的一个页面,反之亦然。
您还必须检查重定向。 重要的是桌面页面对应移动版本中的相同内容,而不是重定向到另一个。 附加信息在这里。
机器人如何找到您的 XML 站点地图
当您完成该过程的所有自动化并将其上传到您的服务器(或通过插件生成)后,您需要留下一个线索,机器人可以在哪里找到它。
最好的方法是在您的 robots.txt 文件中包含指向它的链接。 这也称为 Sitemap Discovery,它是 Google、Bing 和 Yahoo 早在 2007 年推出的,旨在帮助他们的机器人找到 XML Sitemaps。
您所要做的就是包含地图或索引文件的完整路径。

地址的正确音译
Google 官方文档(构建并提交站点地图)强调所有数据值(包括 URL)必须仅包含 ASCII 字符。 它不能包含控制代码或特殊字符,例如 * 或 {}。
如果您网站的 URL 包含这些字符,当您尝试添加它时会收到错误消息。
将您的地图提交给 Google
您可以通过 Google Search Console 将您的站点地图提交给 Google。
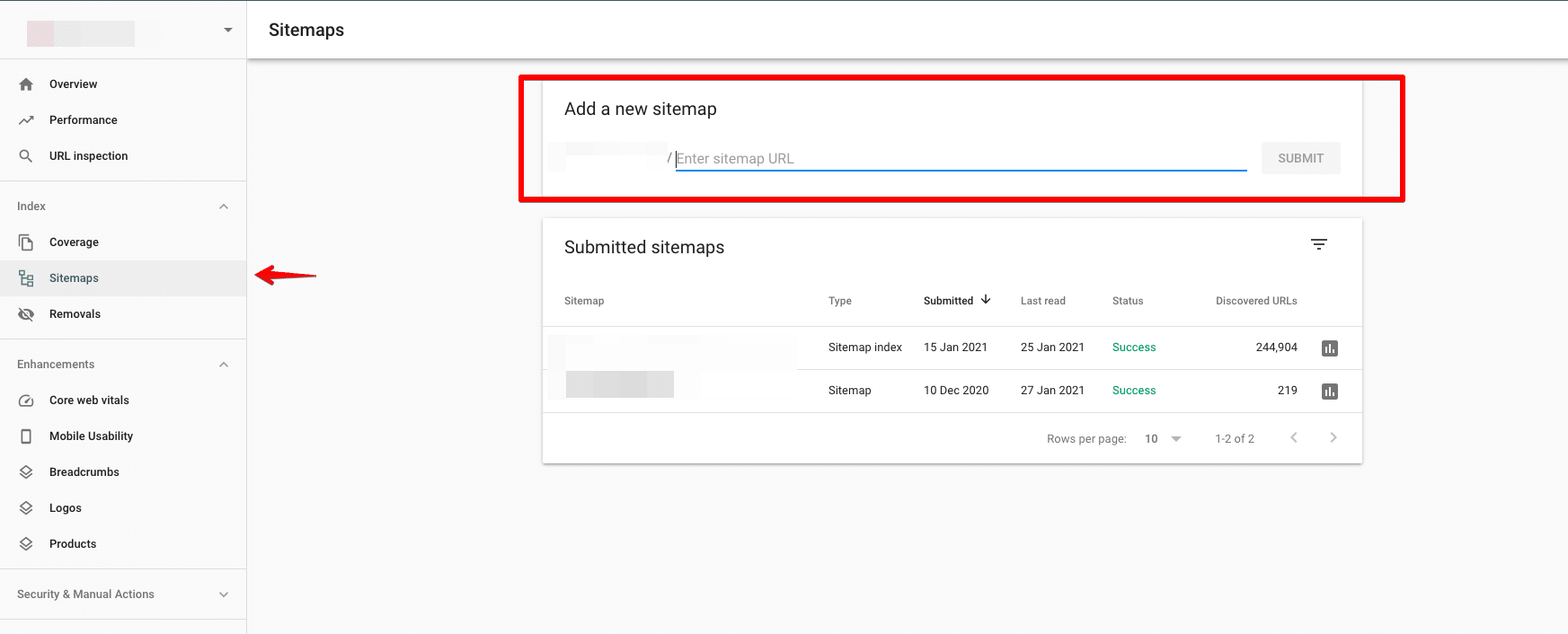
提交前检查是否有任何错误。 清除可能阻碍索引关键目标网页的任何错误非常重要。
理想情况下,索引页数应等于提交的页数。
结论
- 保持一致——如果页面被 robots.txt 或“noindex”阻止,最好不要出现在您的 XML 映射中。
- 自动化您的流程 - 上述所有建议都应可用于自动化,因为这将节省您的时间,帮助抓取预算保持优化,并为您省去很多麻烦。
- 如果您有一个非常大的网站,请使用具有不同地图的索引文件,这将节省您的服务器时间并涵盖您网站上的所有重要页面。