
什么是词向量以及结构化标记如何增强它们
已发表: 2021-07-28你如何定义词向量? 在这篇文章中,我将向您介绍词向量的概念。 我们将讨论不同类型的词嵌入,更重要的是,词向量是如何工作的。 然后,我们将能够看到词向量对 SEO 的影响,这将引导我们了解结构化数据的 Schema.org 标记如何帮助您利用 SEO 中的词向量。
如果您想了解有关这些主题的更多信息,请继续阅读这篇文章。
让我们潜入水中。
什么是词向量?
词向量(也称为词嵌入)是一种词表示,它允许具有相似含义的词具有相等的表示。
简单来说:词向量是特定词的向量表示。
根据维基百科:
它是自然语言处理 (NLP) 中用于表示用于文本分析的单词的一种技术,通常作为一个实值向量,对单词的含义进行编码,以便在向量空间中接近的单词可能具有相似的含义。
下面的例子将帮助我们更好地理解这一点:
看看这些类似的句子:
祝你有美好的一天。 祝你有美好的一天。
它们几乎没有不同的含义。 如果我们构建一个详尽的词汇表(我们称之为 V),它将有 V = {Have, a, good, great, day} 组合所有单词。 我们可以对这个词进行如下编码。
一个词的向量表示可以是一个one-hot 编码向量,其中 1 表示词存在的位置,0 表示其余部分
有 = [1,0,0,0,0]
a=[0,1,0,0,0]
好=[0,0,1,0,0]
伟大的=[0,0,0,1,0]
天=[0,0,0,0,1]
假设我们的词汇表只有五个词:King、Queen、Man、Women 和 Child。 我们可以将单词编码为:
国王 = [1,0,0,0,0]
皇后 = [0,1,0,0,0]
人 = [0,0,1,00]
女人 = [0,0,0,1,0]
孩子 = [0,0,0,0,1]
词嵌入的类型(词向量)
Word Embedding 就是这样一种技术,其中向量表示文本。 以下是一些比较流行的词嵌入类型:
- 基于频率的嵌入
- 基于预测的嵌入
我们不会在这里深入探讨基于频率的嵌入和基于预测的嵌入,但您可能会发现以下指南有助于理解两者:
对词嵌入的直观理解以及用于从文本创建特征的词袋 (BOW) 和 TF-IDF 快速介绍
WORD2Vec简介
虽然基于频率的嵌入已经流行起来,但在理解单词的上下文方面仍然存在空白,并且在单词表示方面受到限制。
基于预测的嵌入 (WORD2Vec) 由 Google 的 Tomas Mikolov 领导的一组研究人员于 2013 年创建、获得专利并被引入 NLP 社区。
根据维基百科,word2vec 算法使用神经网络模型从大量文本语料库(大型结构化文本集)中学习单词关联。
一旦经过训练,这样的模型就可以检测同义词或为部分句子建议额外的词。 例如,使用 Word2Vec,您可以轻松创建这样的结果:国王 - 男人 + 女人 = 女王,这被认为是一个近乎神奇的结果。
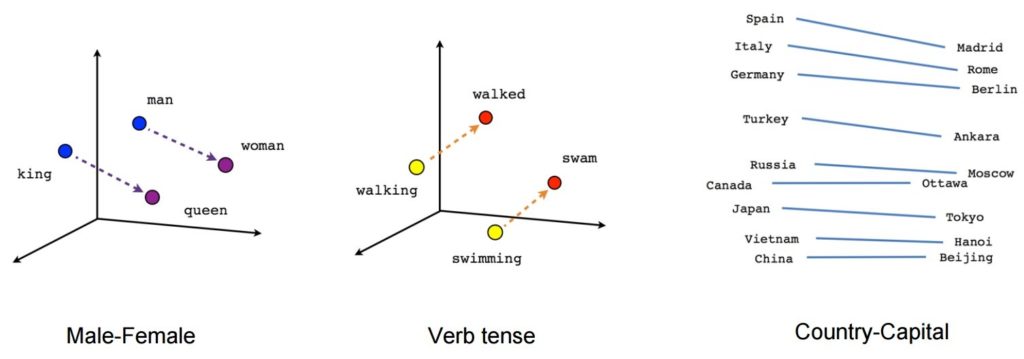 图片来源:张量流
图片来源:张量流
- [king] – [man] + [woman] ~= [queen] (另一种思考方式是 [king] – [queen] 只编码 [monarch] 的性别部分)
- [walking] – [swimming] + [swam] ~= [walked](或 [swam] – [swimming] 只是编码动词的“过去时”)
- [马德里] – [西班牙] + [法国] ~= [巴黎](或 [马德里] – [西班牙] ~= [巴黎] – [法国] 大概大致是“首都”)
资料来源:Brainslab Digital
我知道这有点技术性,但 Stitch Fix 整理了一篇关于语义关系和词向量的精彩文章。
Word2Vec 算法不是一个单一的算法,而是两种技术的组合,它使用一些人工智能方法来连接人类理解和机器理解。 这种技术对于“解决”许多“NLP”问题至关重要。
这两种技术是:
- – CBOW(连续词袋)或 CBOW 模型
- – 跳过语法模型。
两者都是浅层神经网络,可为单词提供概率,并且已被证明在单词比较和单词类比等任务中很有帮助。
词向量和 word2vecs 的工作原理
Word Vector 是 Google 开发的 AI 模型,它可以帮助我们解决非常复杂的 NLP 任务。
“词向量模型有一个你应该知道的核心目标:
它是一种算法,可以帮助谷歌检测单词之间的语义关系。”
每个单词都被编码在一个向量中(以多维表示的数字)以匹配出现在相似上下文中的单词向量。 因此,为文本形成了一个密集向量。
这些向量模型基于思想和语言的等价性、相似性或相关性将语义相似的短语映射到附近的点
[案例研究] 通过页面 SEO 推动新市场的增长
 阅读案例研究
阅读案例研究Word2Vec- 它是如何工作的?
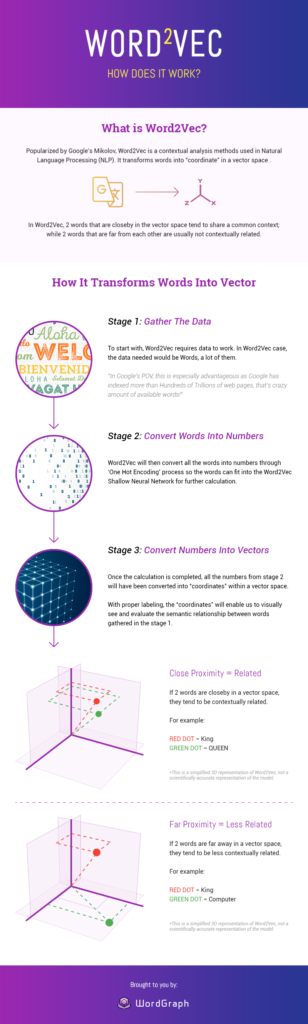
图片来源:Seopressor
Word2Vec 的优缺点
我们已经看到 Word2vec 是一种非常有效的生成分布相似度的技术。 我在这里列出了它的一些其他优点:
- 理解 Word2vec 的概念并不难。 Word2Vec 并不复杂,以至于您不知道幕后发生了什么。
- Word2Vec 的架构非常强大且易于使用。 与其他技术相比,它的训练速度很快。
- 训练在这里几乎是完全自动化的,因此不再需要人工标记的数据。
- 该技术适用于小型和大型数据集。 因此,它是一个易于缩放的模型。
- 如果您了解这些概念,则可以轻松复制整个概念和算法。
- 它非常好地捕获了语义相似性。
- 准确且计算效率高
- 由于这种方法是无监督的,因此在工作量方面非常节省时间。
Word2Vec 的挑战
Word2vec 概念非常有效,但您可能会发现有几点有点挑战性。 以下是一些最常见的挑战。
- 在为您的数据集开发 word2vec 模型时,调试可能是一项重大挑战,因为 word2vec 模型易于开发但难以调试。
- 它不处理歧义。 因此,对于具有多种含义的单词,Embedding 将反映这些含义在向量空间中的平均值。
- 无法处理未知或 OOV 词:word2vec 的最大问题是无法处理未知或词汇外 (OOV) 词。
词向量:搜索引擎优化的游戏规则改变者?
许多 SEO 专家认为 Word Vector 会影响网站在搜索引擎结果中的排名。
在过去五年中,谷歌推出了两项算法更新,明确关注内容质量和语言全面性。

让我们退后一步,谈谈更新:
蜂鸟
2013年,蜂鸟赋予搜索引擎语义分析能力。 通过在他们的算法中利用和结合语义理论,他们开辟了一条通往搜索世界的新道路。
谷歌蜂鸟是自 2010 年咖啡因以来搜索引擎的最大变化。它的名字来源于“精确和快速”。
根据 Search Engine Land 的说法,Hummingbird 更加关注查询中的每个单词,确保考虑到整个查询,而不仅仅是特定的单词。
Hummingbird 的主要目标是通过了解查询的上下文而不是返回特定关键字的结果来提供更好的结果。
“谷歌蜂鸟于 2013 年 9 月发布。”
RankBrain
2015 年,谷歌宣布了 RankBrain,这是一种结合人工智能 (AI) 的战略。
RankBrain 是一种算法,可帮助 Google 将复杂的搜索查询分解为更简单的查询。 RankBrain 将搜索查询从“人类”语言转换为 Google 可以轻松理解的语言。
谷歌于 2015 年 10 月 26 日在彭博社发表的一篇文章中确认了 RankBrain 的使用。
BERT
2019 年 10 月 21 日,BERT 开始在 Google 的搜索系统中推出
BERT 代表来自 Transformers 的双向编码器表示,这是一种基于神经网络的技术,被 Google 用于自然语言处理 (NLP) 的预训练。
简而言之,BERT 帮助计算机更像人类理解语言,这是谷歌引入 RankBrain 以来搜索领域最大的变化。
它不是 RankBrain 的替代品,而是一种用于理解内容和查询的附加方法。
谷歌在其排名系统中使用 BERT 作为补充。 RankBrain 算法对于某些查询仍然存在,并将继续存在。 但是当谷歌认为 BERT 可以更好地理解查询时,他们会使用它。
有关 BERT 的更多信息,请查看 Barry Schwartz 的这篇文章,以及 Dawn Anderson 的深入研究。
使用词向量对您的网站进行排名
我假设您已经创建并发布了独特的内容,即使经过一遍又一遍的润色,它也不会提高您的排名或流量。
你想知道为什么这会发生在你身上吗?
可能是因为您没有包含 Word Vector:Google 的 AI 模型。
- 第一步是为您的利基识别前 10 个 SERP 排名的词向量。
- 了解您的竞争对手使用的关键字以及您可能忽略的关键字。
通过应用利用先进的自然语言处理技术和机器学习框架的 Word2Vec,您将能够详细查看所有内容。
但如果您了解机器学习和 NLP 技术,这些都是可能的,但我们可以使用以下工具在内容中应用词向量:
WordGraph,世界上第一个词向量工具
该人工智能工具是使用用于自然语言处理的神经网络创建的,并使用机器学习进行训练。
WordGraph 基于人工智能分析您的内容并帮助您提高其与排名前 10 位网站的相关性。
它建议与您的主要关键字在数学和上下文相关的关键字。
就我个人而言,我将它与 BIQ 配对,这是一个强大的 SEO 工具,可以很好地与 WordGraph 配合使用。
将您的内容添加到 Biq 内置的内容智能工具。 它将向您显示页面上的 SEO 提示的完整列表,如果您想排名最高,您可以添加这些提示。
您可以在此示例中了解内容智能的工作原理。 这些列表将帮助您掌握页面 SEO 并使用可行的方法进行排名!
如何增强词向量:使用结构化数据标记
Schema 标记或结构化数据是一种使用 schema.org 词汇创建的代码(以 JSON、Java-Script Object Notation 编写),可帮助搜索引擎抓取、组织和显示您的内容。
如何添加结构化数据
通过在 html 中添加内联脚本,可以轻松地将结构化数据添加到您的网站
下面的示例显示了如何以最简单的格式定义组织的结构化数据。
为了生成模式标记,我使用了这个模式标记生成器 (JSON-LD)。
这是 https://www.telecloudvoip.com/ 的架构标记的实时示例。 检查源代码并搜索 JSON。
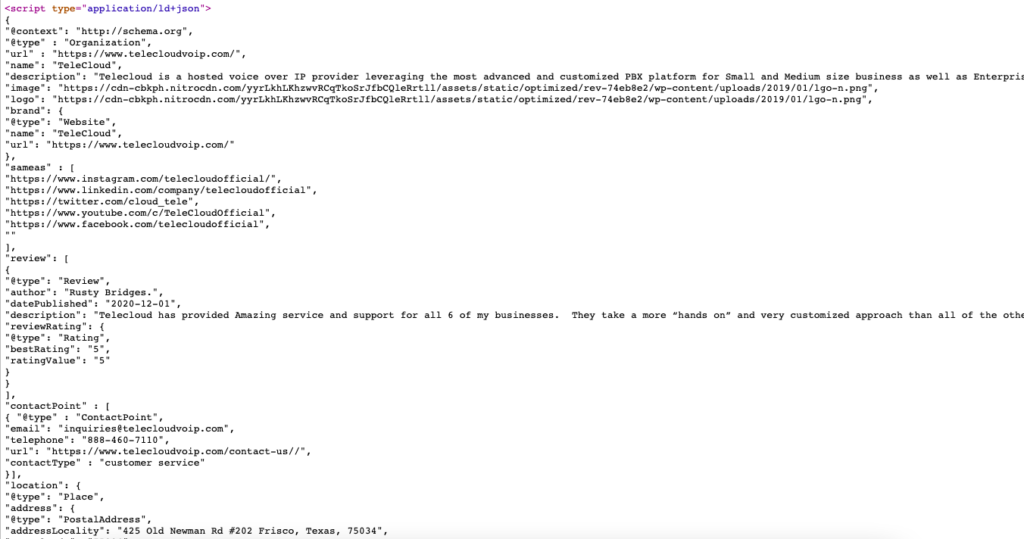
创建架构标记代码后,使用 Google 的富结果测试来查看页面是否支持富结果。
您还可以使用 Semrush Site Audit 工具来探索每个 URL 的结构化数据项,并确定哪些页面有资格出现在 Rich Results 中。 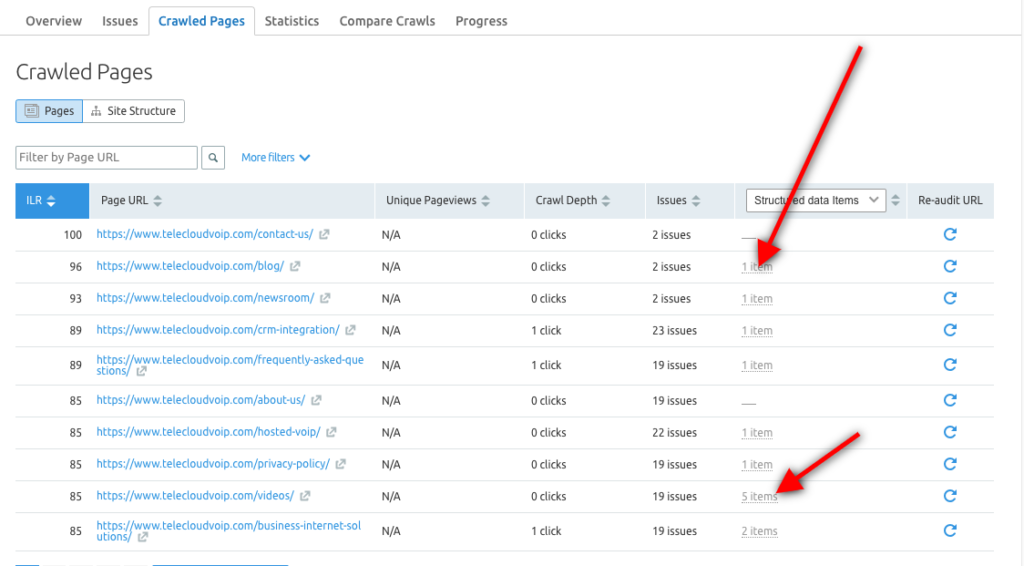
为什么结构化数据对 SEO 很重要?
结构化数据对于 SEO 很重要,因为它可以帮助 Google 了解您的网站和页面的内容,从而对您的内容进行更准确的排名。
结构化数据通过提供更多信息和准确性来改进 SERP(搜索引擎结果页面),从而改善了 Search Bot 的体验和用户体验。
要查看对 Google 搜索的影响,请转到 Search Console 并在性能 > 搜索结果 > 搜索外观下,您可以查看所有富媒体搜索结果类型的细分,例如“视频”和“常见问题解答”,并查看它们带来的自然展示次数和点击次数为您的内容。
以下是结构化数据的一些优点:
- 结构化数据支持语义搜索
- 它还支持您的 E-AT(专业知识、权威性和信任)
- 拥有结构化数据还可以提高转化率,因为更多的人会看到您的列表,这增加了他们向您购买的可能性。
- 使用结构化数据,搜索引擎能够更好地了解您的品牌、网站和内容。
- 搜索引擎将更容易区分联系页面、产品描述、食谱页面、活动页面和客户评论。
- 在结构化数据的帮助下,Google 构建了一个更好、更准确的关于您的品牌的知识图谱和知识面板。
- 这些改进可以带来更多的自然印象和自然点击。
Google 目前使用结构化数据来增强搜索结果。 当人们使用关键字搜索您的网页时,结构化数据可以帮助您获得更好的结果。 如果我们添加 Schema 标记,搜索引擎会更多地注意到您的内容。
您可以在许多不同的项目上实现模式标记。 下面列出了可以应用模式的几个领域:
- 文章
- 博客文章
- 新闻文章
- 活动
- 产品
- 视频
- 服务
- 评论
- 综合评分
- 餐厅
- 本地企业
这是您可以使用模式标记的项目的完整列表。
具有实体嵌入的结构化数据
术语“实体”是指任何类型的对象、概念或主体的表示。 实体可以是人、电影、书籍、想法、地点、公司或事件。
虽然机器无法真正理解单词,但通过实体嵌入,它们能够轻松理解国王 - 王后 = 丈夫 - 妻子之间的关系
实体嵌入比 one-hot 编码表现更好
谷歌使用词向量算法来发现词之间的语义关系,当与结构化数据结合时,我们最终得到了一个语义增强的网络。
通过使用结构化数据,您正在为更加语义化的网络做出贡献。 这是一个增强的网络,我们在其中以机器可读的格式描述数据。
您网站上的结构化语义数据有助于搜索引擎将您的内容与正确的受众相匹配。 NLP、机器学习和深度学习的使用有助于缩小人们搜索的内容与可用标题之间的差距。
最后的想法
当您现在了解词向量的概念及其重要性时,您可以通过利用词向量、实体嵌入和结构化语义数据来使您的有机搜索策略更加有效和高效。
为了获得最高的排名、流量和转化,您必须使用词向量、实体嵌入和结构化语义数据向 Google 证明您网页上的内容是准确、精确和值得信赖的。