
Web 开发人员需要了解的技术 SEO 知识
已发表: 2019-06-11如果您正在做技术 SEO,但没有运行您负责的网站,那么 Web 开发团队对您的成功至关重要。 但在增长和营销方面的开发人员和 SEO 并不总是意见一致。
据说,当今 SEO 最需要的技能之一是沟通和联合不同观点的能力。 如果没有高度技术性的 SEO 提及如何与开发人员交谈,就不会发生任何事件。
但除了如何与开发人员交谈之外,您还需要知道该说些什么。 如果您的开发团队从未有过 SEO 方面的经验,这里有一些重要的事情可以确保他们知道——不要屈尊解释什么是 <title> 标签。 毕竟,开发人员远非网络新手。
掌握基础知识
大多数 SEO 期望网站开发人员对在 SEO 中起主要作用的网站元素以及它们如何影响 SEO 性能有基本的了解:
- XML 站点地图
- 机器人.txt
- 模板要求,例如分析跟踪代码的放置、标题的使用(
< h1 >...)、schema.org 标记或语义 HTML - 页面声明如 <link rel=”canonical” >
- 传统上用于构建搜索结果的元素(<title>、<meta description=”lorem ipsum...”>、URLs)
- 301 重定向
- 页面速度
- HTTPS – 和站点迁移,如果您的站点使用 HTTP
- 页面重要性和基于链接的网站结构
- 服务器稳健性和安全性
- 用于 SEO 目的的服务器日志监控
如果您需要为自己或其他人提供进修课程,则 SEO 指南通常比 SEO 为开发人员编写的指南更详细、更完整,从而使它们更有帮助。 一个好的起点总是 Moz 的 SEO 初学者指南,或 Google 的 SEO 入门指南和他们的 Search Console 帮助。
SEO 仅在搜索引擎可以抓取和呈现 URL 时才有效
出现在搜索引擎结果中意味着搜索引擎能够发现、抓取、呈现和解析网站上的关键页面。 当有技术原因导致这种情况没有发生时,整个数字营销链就会崩溃。
机器人需要访问网站
Google 使用不同的用户代理来抓取网站。 这些必须不仅可以访问页面,还可以访问资源(图像和其他媒体)、JavaScript 以及在 URL 上呈现内容所需的其他元素。
同时,URL 的抓取是优先考虑的:我们有时希望通过阻止对后者的抓取而支持对前者的抓取来提升一组页面而不是另一组。 哪些页面属于哪个类别会随着季节而变化,导致重大事件发生,甚至在网站或谷歌算法发生变化之后。
许多 SEO 工具还需要访问爬取或抓取网站的某些部分,以便分析性能或准备批量更正。
如果 SEO 无法访问过滤机器人访问的方法(robots.txt、htaccess、HTTP 标头……),他们会将请求传递给开发团队。
登台网站并上线
登台网站需要考虑到它们需要被批准用于 SEO 的事实——但仍然没有被谷歌和其他搜索引擎索引。 SEO 团队可能需要允许某些机器人访问网站,以便执行验证和检查,从 SEO 的角度来看,这将允许他们为网站提供通过/不通过。 要求 SEO 团队为他们需要授权的机器人提供用户代理和 IP 地址,以及他们所拥有的有关其 SEO 工具可以或不支持的安全协议的任何信息是合理的。
在网站上线时,将 SEO 保留在清单上。 如果机器人已被禁止爬取该站点,则需要在此过程中删除这些规则; 没有 SEO 想看到
用户代理: *
不允许: /
仅作为新站点的 robots.txt 文件中的内容。
技术的选择很重要
技术 SEO 应该熟悉网站的构建方式。 SEO 团队中的某个人应该能够参与有关服务器、CDN、CMS 选择、JavaScript 框架的讨论……
直到过去几个月,谷歌在抓取时都在使用 Chromium M41——是的,这意味着多年来所有普通导航器都支持的功能可能会破坏谷歌的页面。 虽然这已得到纠正,但它表明在涉及网络技术支持的情况下做出假设有时会适得其反。
有时实施方式很重要
技术 SEO 将需要页面模板和标记中的各种花里胡哨。 虽然大多数时候技术 SEO 可以而且应该让开发人员决定如何实施,但在某些情况下 Google 会提供规范或要求。
开发人员应该知道在哪里可以找到这些 - 以及如何询问技术 SEO 请求附带的实施说明是要求,还是只是一厢情愿。
具有推荐或要求的搜索引擎实施策略的一些功能示例包括但不限于以下内容:
- 一般的 JavaScript
- 图像优化
- 延迟加载
- 多语言和地理定位网站
- 首选 Schema.org 标记格式
替代解决方案是可能的
从理论上讲,技术 SEO 和 Web 开发的一个共同点是喜欢基于数据的、创造性的问题解决方案,以使用可用的技术来达到预期的结果。

当技术 SEO 请求不可行时,请寻找替代解决方案。 许多同时也是开发人员的技术 SEO 已经针对不支持某些修改的复杂遗留堆栈提出了解决方法。
- 去年,Dan Taylor 引入了 Edge SEO 一词来指代在页面呈现后但在交付给客户之前实施 SEO 修复的解决方案,例如利用 CDN 上的服务人员。
- 创意技术 SEO 还可以使用 JavaScript、Python、数据库管理和查询,以及搜索引擎和 SEO 工具提供的 API。
在不存在已知解决方案的情况下,运行具有可衡量结果的负责任的测试始终是 SEO 中的一种选择。 由于 Google 不会分享其工作方式的细节,因此技术 SEO 根据 Google 专利、Google 官方声明和在搜索结果中观察到的网站性能做出合理的假设。 在 SEO 中运行自己的测试可能会有风险,但这也是一种受人尊重和接受的做法。
大多数技术性 SEO 问题:迭代与关键更改
最好的 SEO 工作是迭代的,并遵循如下所示的过程:

这意味着要求 SEO 批量请求是合理的,但不阻止定期实施 SEO 更改可能会显着推动 SEO 策略。 这也意味着 SEO 请求可能包括回滚或早期测试的扩展。
SEO 和开发人员应该共同努力,找到一种方法来批量和安排定期的开发请求。
但是,一些 SEO 请求真的等不及了。 这可能包括:
- 修复了从搜索中删除全部或部分网站的错误
- 修复 Google 处罚,称为“手动操作”
- 纠正异常工具或跟踪器行为所需的更改
- 更改以解决直接影响网站搜索性能的主要算法更改
保持最新状态,对新的搜索功能感到兴奋
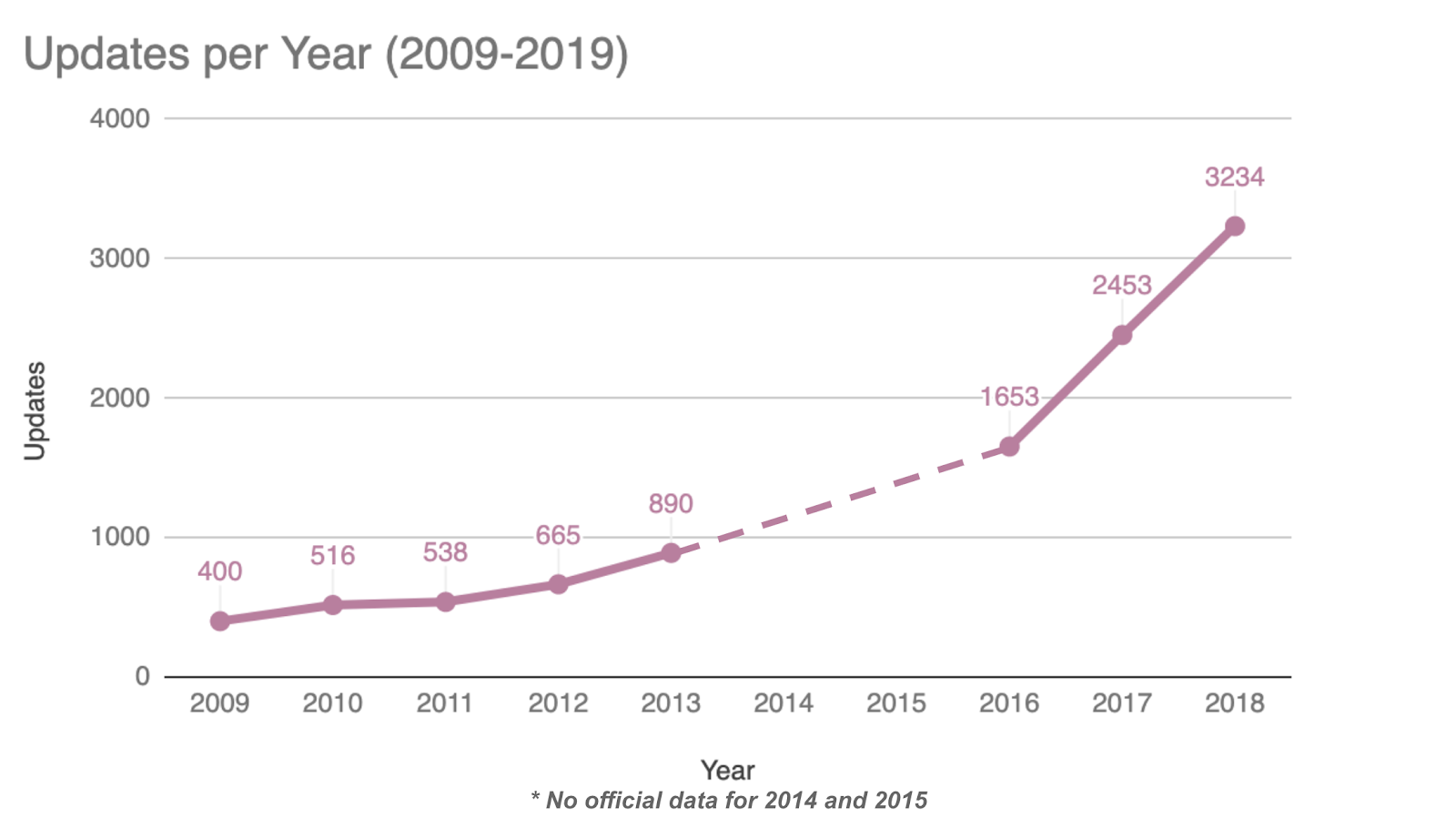
正如我们刚才所建议的,搜索不是一个静态字段。 它随着搜索引擎的新技术、新用途和新版本而发展。 谷歌还对其索引和排名算法进行了近乎不断的修改——他们在 2018 年报告了 3234 处变化,这通常会导致网站优化方式的变化。
这意味着即使是超过 6 到 12 个月的可靠信息也可能不再相关。 例如:
- 排名过去非常依赖于为每个 URL 声明元关键字; 虽然现场搜索引擎仍然使用这些关键字,但 SEO 不再使用。
- Google 曾经建议在分页的一系列 URL 上使用 <link rel=”prev” > 和 <link rel=”next” > 声明,以防止它们将这些页面标记为相同,但不再考虑这一点。
但这也意味着搜索引擎优化经常有新元素。 2019 年宣布的新元素和即将推出的元素包括:
- 谷歌的 Evergreen bot 意味着谷歌可以访问浏览器功能,也许最重要的是更新的 JavaScript。 但是,JavaScript 渲染仍然是单独执行并在稍后执行,因此获取带有 JavaScript 索引的页面的建议仍然有效。
- 常见问题页面标记,对于具有多个问题和答案的页面,现在可以给出
- 日期使用新指南
- 即将在搜索结果中支持高分辨率图像
谷歌还在推特上和通过现场站长环聊回答来自 SEO 的问题,并在谷歌网站站长博客上提供有关变化和主要公告的信息。
共同努力实现相互理解
弥合 Web 开发和 SEO 之间差距的关键之一是相互尊重和沟通。 虽然 SEO 的基础知识很重要,但同样重要的是要认识到开发人员可以使用已经存在的信息轻松地自行获取这些知识。
了解 SEO 在实践中的工作方式会更有成效。 这包括了解机器人访问网站的重要性,技术对搜索的影响,以及如何处理无法按照建议修复的 SEO 问题。 这也意味着了解 SEO 过程是如何工作的,并认识到搜索正在以越来越快的速度发展。
SEO 社区也越来越意识到 Web 开发人员面临的问题。 因此,Detlef Johnson 的 SEO for Developers 等专栏可以在 Search Engine Land 等面向 SEO 的出版物中找到一席之地。 这种意识也让 SEO 寄希望于 Web 开发人员也将努力了解 SEO 的关键要素。