在线对照实验中的元分析:公正地看待这种科学方法的力量和局限性
已发表: 2022-09-28
元分析在 A/B 测试和其他在线实验中有多有用?
它有助于利用过去的学习来改进你的假设生成吗? 或者元分析只是一个懒惰的借口,简单地依赖“经过验证的模式”,而不是基于特定情况的数据通过经验在您的业务中进行创新?
这是一个热议的话题。 有些人赞成,有些人强烈反对。 但是,您如何才能从这两种观点中受益,并为您的实验计划带来切实的价值呢?
这就是这篇文章的内容。 在里面,你会
- 了解什么是元分析
- 查看实际中的元分析示例
- 发现为什么必须谨慎(和尊重)对待元分析作为一个概念,以及
- 了解实验团队如何以正确的方式进行元分析
还有一个好处:您还会看到两位著名的转化率优化专家从相反的角度讨论这个问题。
让我们开始吧。
- 什么是元分析?
- 在线对照实验中的元分析示例
- 有兴趣进行自己的 A/B 测试元分析吗?
- 元分析——是或否
- 元分析——谨慎行事?
- 不妥协测试严谨性和追求创新
- 元分析——给实验飞轮上油?
- 元分析——谨慎行事?
- 如果您选择进行(和使用)元分析——请记住以下几点
- 分析中包含的实验质量差
- 异质性
- 发表偏倚
什么是元分析?
元分析使用统计数据通过分析多个实验结果做出决定。 它来自科学界,研究人员将针对同一问题的医学研究结果汇总在一起,并使用统计分析来判断效果是否真的存在以及它的重要性。
在在线控制实验中,我们有 A/B 测试、多变量测试和拆分测试来制定决策和寻找实现业务目标的最佳方法,我们借用元分析来利用我们已经从之前学到的东西测试以通知未来的测试。
让我们看看不同的例子。
在线对照实验中的元分析示例
以下是 A/B 测试中元分析的 3 个示例,它是如何使用的,以及在每项工作中发现了什么:
- Alex P. Miller 和 Kartik Hosanagar对电子商务 A/B 测试策略的实证元分析
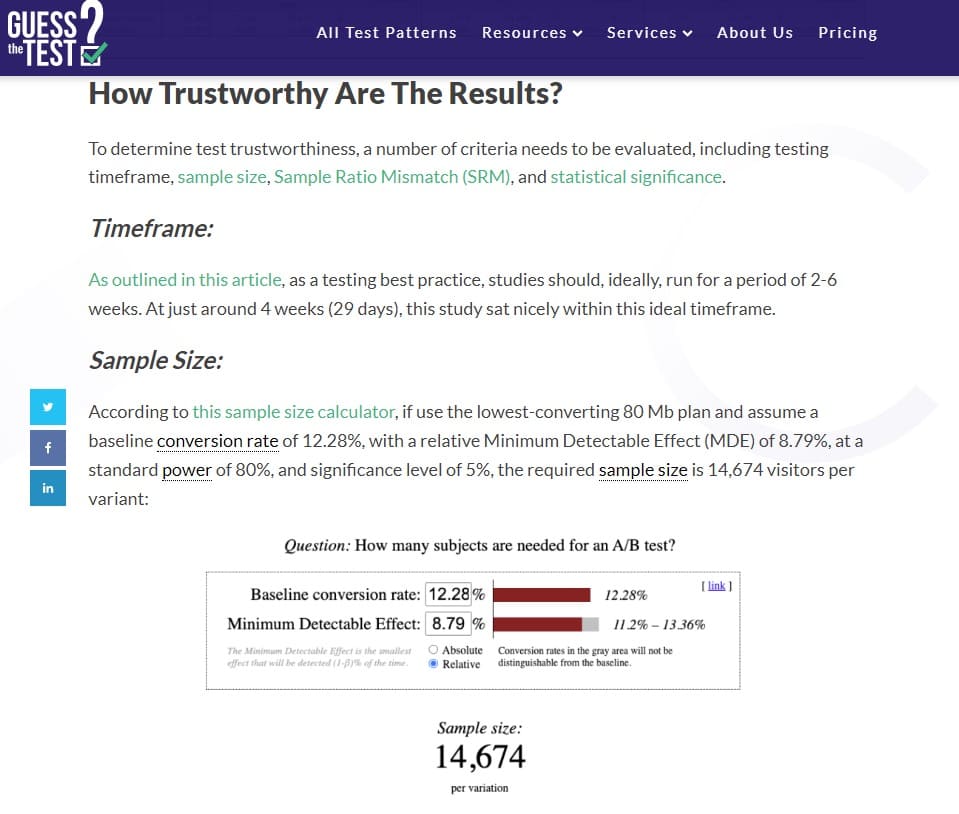
这份 A/B 测试元分析于 2020 年 3 月发布。分析师专门研究了电子商务行业的测试,他们从 SaaS A/B 测试平台收集了数据。 它包括 2,732 次 A/B 测试,由 252 家美国电子商务公司在 3 年内跨 7 个行业进行。
他们分析了这些测试,以提供对测试如何在电子商务转换漏斗的各个阶段进行定位的可靠分析。
他们发现的是:
- 与其他实验类型相比,价格促销测试和类别页面上的测试与最大的影响大小相关联。
- 消费者对不同促销的反应取决于这些促销在电子商务网站中的位置。
- 虽然有关产品价格的促销在转化渠道的早期最有效,但与运输相关的促销在转化渠道的后期(在产品页面和结帐上)最有效。
让我们看另一个例子,以及研究人员发现了什么……
- 什么在电子商务中有效——Will Browne 和 Mike Swarbrick Jones 对 6,700 个实验的荟萃分析
Browne 和 Jones 使用来自零售和旅游行业的 6,700 个大型电子商务实验的数据,研究了 29 种不同类型的变化的影响,并估计了它们对收入的累积影响。 它于 2017 年 6 月发布。
正如论文标题所暗示的那样,目标是通过运行大型元分析来探索电子商务中的有效方法。 这就是他们如何得出这个强有力的总结:与基于行为心理学的变化相比,网站外观的变化对收入的影响可以忽略不计。
每位访问者的收入 (RPV) 指标用于衡量这种影响。 因此,在他们的结果中,实验的 +10% 提升意味着 RPV 在该实验中上升了 10%。
以下是分析中的其他一些发现:
- 表现最好的(按类别)是:
- 稀缺性(股票指标,例如,“仅剩 3 个”):+2.9%
- 社交证明(告知用户他人的行为):+2.3%
- 紧迫性(倒计时):+1.5%
- 放弃恢复(向用户发送消息让他们留在网站上):+1.1%
- 产品推荐(追加销售、交叉销售等):+0.4%
- 但是对 UI 的外观更改(如下所示)无效:
- 颜色(改变网页元素的颜色):+0.0%
- 按钮(修改网站按钮):-0.2%
- 号召性用语(更改文本):-0.3%
- 90% 的实验对收入的影响不到 1.2%,无论是正面的还是负面的
- 几乎没有证据表明 A/B 测试会导致案例研究中常见的两位数收入增长。
现在等待。 在你把这些荟萃分析结果当成福音之前,你需要知道在线实验的荟萃分析是有局限性的。 我们稍后再谈。
- Georgi Georgiev对 GoodUI.org 上 115 个 A/B 测试的元分析
2018 年 6 月,在线实验专家、《在线 A/B 测试中的统计方法》作者 Georgi Georgiev 在 GoodUI.org 上分析了 115 个公开可用的 A/B 测试。
GoodUI.org 发布了一系列实验结果,包括新发现的 UI 模式以及 Amazon、Netflix 和 Google 等实验驱动的公司从他们的测试中学到了什么。
Georgi 的目标是整理和分析这些数据,以揭示测试的平均结果,并在设计和执行 A/B 测试的元分析时提供关于更好的统计实践的想法。
他首先修剪初始数据集并进行一些统计调整。 其中包括删除:
- 被派去体验控制的用户数量与被派去体验挑战者的用户数量之间不平衡的测试,以及
- 妥协的测试(通过他们不切实际的低统计能力发现)。
他分析了剩余的 85 次测试,发现平均提升百分比为 3.77%,中位数提升为 3.92%。 查看下面的分布,您会看到 58% 的测试(这是大多数)在 -3% 和 +10% 之间观察到效果(提升 %)。
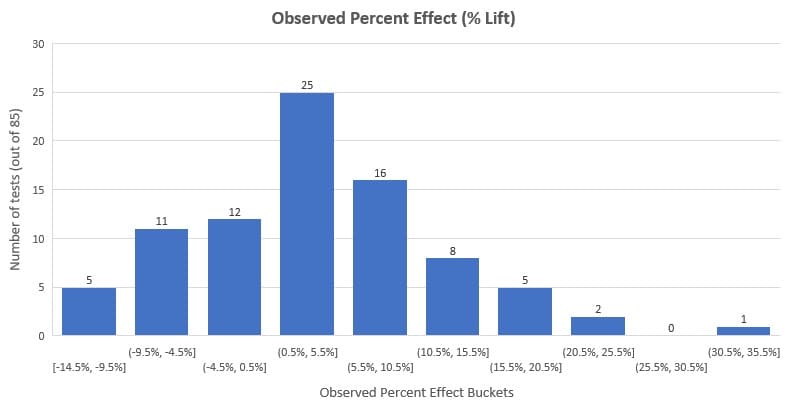
需要注意的是,这代表了这个数据集,而不是所有已经完成的 A/B 测试。 另外,我们必须考虑发表偏倚(我们稍后将讨论的荟萃分析的缺点之一)。
但是,此元分析有助于转化率优化人员和其他优化利益相关者了解 A/B 测试中的外部基准。
有兴趣进行自己的 A/B 测试元分析吗?
您可以访问 Georgi 使用的相同数据集。 它在 GoodUI.org 上公开可用——这是一个针对不同核心问题进行的跨平台、行业和不同核心问题的 A/B 测试的提炼结果存储库。
还有其他类似的 A/B 测试结果集合(您甚至可以通过从众多 A/B 测试示例和案例研究中提取数据来创建自己的结果),但 GoodUI 是独一无二的。 如果您正在浏览和收集案例研究,您将获得有关测试的其他统计信息,否则这些信息很难获得。
还有几件事使 GoodUI 与众不同:
- 它不会根据实验结果进行区分。 它包括获胜、不确定、平坦和否定测试,以对抗 Meta 分析中的发表偏倚,这是一个真正的问题,正如 John Copas 和 Jian Qing Shi 在“Meta 分析、漏斗图和敏感性分析”中所述。
发表偏倚是对发表小型研究的偏好,如果它们的结果比具有负面或不确定结果的研究“显着”。 如果不做出不可测试的假设,您就无法纠正这一点。
- GoodUI 更进一步。 元分析结果通常隐藏在研究论文中。 他们几乎没有进入实际应用的道路,特别是对于不是非常成熟的实验团队。
借助 GoodUI 模式,好奇的优化器可以深入研究观察到的百分比变化、统计显着性计算和置信区间。 他们还可以使用 GoodUI 对结果强弱程度的评估,可能值为“不显着”、“可能”、“显着”和“强”,针对每个转换模式在两个方向上进行。 你可以说它使来自 A/B 测试元分析的见解“民主化”。
- 但是,这里有一个问题。 实验者可能不知道困扰荟萃分析的问题——异质性和发表偏倚——加上荟萃分析结果取决于荟萃分析本身的质量这一事实,可能会转向盲目复制模式的领域。
相反,他们应该进行自己的研究并进行 A/B 测试。 不这样做最近(正确地)引起了 CRO 领域的关注。
GuessTheTest 是另一个 A/B 测试案例研究资源,您可以深入研究类似 GoodUI 等测试的详细信息。
免责声明:我们撰写此博客的目的不是为了批评或赞扬元分析和转换模式。 正如 CRO 领域的专家所讨论的那样,我们只是要介绍利弊。 我们的想法是将荟萃分析作为一种工具呈现,以便您可以自行决定使用它。
元分析——是或否
聪明的头脑会寻找模式。 这就是您下次遇到类似问题时缩短从问题到解决方案的路径的方法。
这些模式会引导您在创纪录的时间内找到答案。 这就是为什么我们倾向于相信我们可以把我们从实验中学到的东西,聚合它们,并推断出一个模式。
但这对实验团队来说是否可取?
在线对照实验中支持和反对荟萃分析的论据是什么? 你能找到一个两全其美的中间立场吗?
我们询问了实验领域中两个最有发言权的声音,他们对元分析的看法(恭敬地)不同。
Jonny Longden 和 Jakub Linowski 是您可以信赖的声音。


元分析——谨慎行事?
在上面的讨论中,Jonny 指出了在在线测试中使用元分析数据的两个潜在问题,这需要 CRO 从业者谨慎行事。

- 问题 #1:使用结果而不进行测试
“如果它适用于那家公司,它也应该适用于我们”。 这可能会被证明是错误的想法,因为围绕测试的细微差别无法体现在您正在审查的结果片段中。
几个测试可能会证明一个简单的解决方案,但这只是它可能比其他解决方案稍微好一点的可能性,而不是它可以在您的网站上运行的明确答案。
- 问题 #2:你不能这么容易地对测试进行分类
正如 #1 中提到的,这些结果并未显示测试背后的完整、细致入微的故事。 您看不到为什么要运行测试,它们来自哪里,网站上存在哪些先前的问题等。
例如,您只看到这是对产品页面上的号召性用语的测试。 但是元分析数据库会将它们分类为特定的模式,即使它们并没有完全落入这些模式中。
这对您、A/B 测试元分析数据库用户或 CRO 研究人员来说意味着什么?
这并不意味着荟萃分析是禁区,但你应该小心使用它。 你应该采取什么样的谨慎态度?
不妥协测试严谨性和追求创新
回想一下,荟萃分析是医学界的一种统计概念,在该概念中,实验受到严格控制,以确保发现的可重复性。
围绕观察的环境和其他因素在多个实验中重复出现,但这与在线实验不同。 无论这些差异如何,在线实验的元分析都会将他们的数据汇总在一起。
一个网站与另一个网站完全不同,因为它有非常不同的受众和非常不同的事情发生。 即使看起来比较相似,即使是同一种产品,但在千千万万种方式中,它仍然是完全不同的,所以你无法控制它。
乔尼·朗登
除其他限制外,这会影响我们所谓的真正荟萃分析的质量。
因此,如果您不确定测试和荟萃分析的统计活力水平,您只能非常谨慎地使用,正如 Shiva Manjunath 建议的那样。
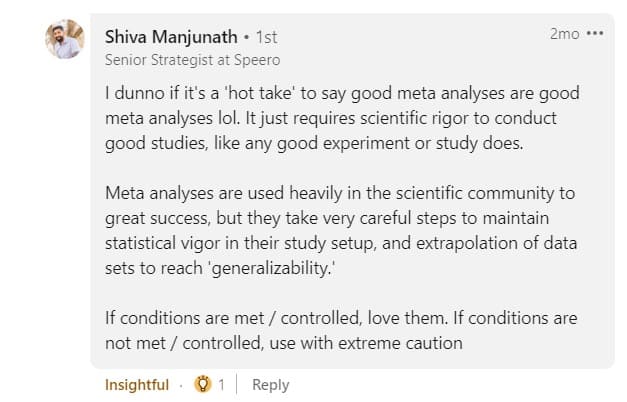
元分析的目标不应该是复制竞争对手。 从利用元分析到直接复制的跳跃推动了可信度的界限。 “复制”背后的意图是有细微差别的,所以这不是一个非黑即白的情况。
上面对黛博拉帖子的评论是多种多样的。 复制到一定程度是可以的,但过度复制是危险的:
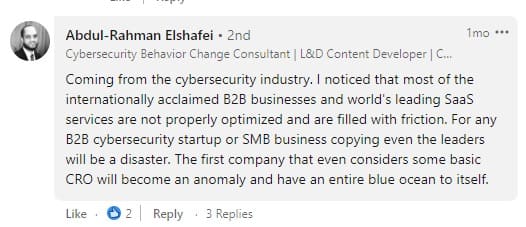
正如 Jakub 所同意的那样,我们必须对复制保持谨慎,尤其是在验证我们通过实验观察到的模式时。
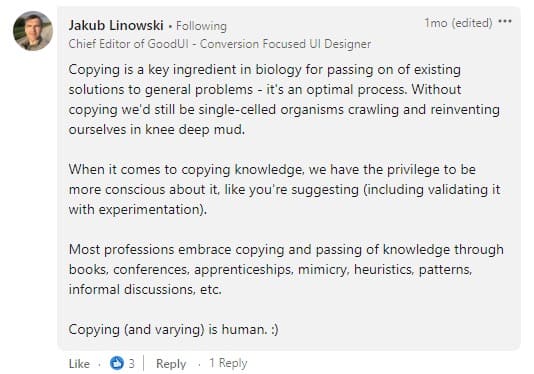
但是,我们应该警惕的是将实验商品化。 也就是说,使用荟萃分析的模式和见解作为最佳实践来代替实验研究,而不是赞美特定情况的数据必须说明的内容。
因此,首先要了解您想要解决的问题,并确定最有可能成功的干预措施。 这就是对遗留实验数据的元分析最能支持独特优化策略的地方。
元分析——给实验飞轮上油?
实验飞轮有一种回收动力的方式。 当你第一次做实验时,你需要很大的惯性才能让事物运转起来。
实验飞轮的想法是利用这种势头来运行更多测试并再次循环,变得越来越好,运行越来越多的测试。
这就是元分析可以提供帮助的地方。 在飞轮中:
- 您运行测试以希望验证您的假设(并可能在此过程中拒绝一些假设)。
- 衡量他们为决策增加的价值。
- 鼓励对 A/B 测试产生更多兴趣和支持。
- 投资于 A/B 测试基础设施并提高数据质量。
- 降低 A/B 测试的人力成本,使下一步比上一轮更轻松。
但作为一个数据驱动的组织,当您认识到 A/B 测试的力量时,您不会止步于此。 相反,您希望在初始实验投资的基础上验证或拒绝更多假设。
如果没有最初的洞察力或知识开始,那么让您的飞轮运转的惯性将太大。 分享这些知识(使 A/B 测试数据大众化)可以通过降低知识壁垒来激发并帮助其他人采用实验方法。
这将我们带到了元分析如何为实验飞轮提供润滑脂的第 1 点:
- 元分析可能会缩短假设想法的时间。
您可以从之前的测试中获取您所学到的知识、见解和所有内容,从而轻松地生成新假设。 这增加了您运行的测试数量,并且是加速 A/B 测试飞轮的绝佳方式。
我们花更少的时间重做已经建立的模式,而花更多的时间根据我们在之前的实验中学到的知识开辟新的路径。
- Meta 分析可以通过过去的数据获得更好的预测率。
过去实验驱动的学习可以让实验飞轮旋转得更快的另一种方法是结合现有数据来提供新的假设。
这可能会改善 A/B 测试中观察到的影响如何溢出到未来。
部署 A/B 测试并不能保证看到您想要的结果,因为 95% 显着性测试的错误发现率 (FDR) 介于 18% 和 25% 之间。 在得出这一结论的测试中,只有 70% 具有足够的功效。
错误发现率是实际无效的显着 A/B 测试结果的一部分。 不要被误认为是误报或 I 类错误。
- 最后,荟萃分析可能是一种建立对本质上不确定的测试结果的信心的方法。
置信水平可帮助您相信您的测试结果并非纯属偶然。 如果您没有足够的信息,您可能倾向于将该测试标记为“不确定”,但不要那么着急。
为什么? 从统计上讲,您可以累积无关紧要的 p 值以获得显着的结果。 请参阅下面的帖子:
荟萃分析有两个主要好处:1)它提高了效果估计的准确性,2)它增加了研究结果的普遍性。
资料来源:好的、坏的和丑陋的:Madelon van Wely 的荟萃分析
鉴于元分析调整和纠正了效应大小和显着性水平,人们可以像使用任何其他实验一样使用这种更高的标准结果,包括:
1)为自己的实验进行功效计算/样本量估计(使用真实数据而不是主观猜测)
2)做出exploit-experiment决定。 如果有人觉得需要额外的信心,他们可能会决定自己进行额外的实验。 如果有人发现荟萃分析的证据足够有力,他们可能会更早地采取行动,而无需进行额外的实验。
雅库布·林诺夫斯基
元分析可以通过各种方式帮助您的实验计划获得更多动力,重要的是要记住它存在一些众所周知的限制。
如果您选择进行(和使用)元分析——请记住以下几点
是的,通过元分析方法结合实验结果可以提高统计精度,但这并不能消除初始数据集的基本问题,例如……
分析中包含的实验质量差
如果元分析中包含的实验设置不当并且包含统计错误,那么无论元分析员多么准确,他们都会得到无效的结果。
也许在 A/B 测试中样本量分配不均,能力或样本量不足,或者有偷窥的证据——不管是什么情况,这些结果都是有缺陷的。
您可以做的绕过此限制的方法是仔细选择您的测试结果。 从您的数据集中消除有问题的结果。 您还可以重新计算您选择包含的测试的统计显着性和置信区间,并在荟萃分析中使用新值。
异质性
这是组合最初不应该放在同一个桶中的测试结果。 例如,当用于进行测试的方法不同时(贝叶斯与频率统计分析、A/B 测试平台特定的差异等)。
这是荟萃分析的一个常见局限性,分析师有意或无意地忽略了研究之间的关键差异。
您可以查看原始定量数据来对抗异质性。 这比仅结合测试结果的摘要要好。 这意味着重新计算每个 A/B 测试的结果,假设您可以访问数据。
发表偏倚
也称为“文件抽屉问题”,这是元分析中最臭名昭著的问题。 在对公开可用的数据进行荟萃分析时,您仅限于汇集那些使其发表的结果。
那些没有成功的呢? 出版物通常偏爱具有统计学意义且具有显着治疗效果的结果。 当荟萃分析中未显示此数据时,结果仅描述已发布的内容。
您可以通过漏斗图和相应的统计数据发现发表偏倚。
那么,您在哪里可以找到没有进入案例研究或 A/B 测试元分析数据库的 A/B 测试? 无论结果如何,A/B 测试平台都处于提供测试数据的最佳位置。 这就是本文中的示例 1 和示例 2 的优势所在。