
什么是潜在语义索引,它是如何工作的?
已发表: 2020-04-02潜在语义索引 (LSI) 长期以来一直是搜索营销人员争论的焦点。 谷歌“潜在语义索引”一词,你会同时遇到拥护者和怀疑者。 在搜索引擎营销的背景下考虑 LSI 的好处没有明确的共识。 如果您对这个概念不熟悉,本文将总结关于 LSI 的争论,希望您能了解它对您的 SEO 策略意味着什么。
什么是潜在语义索引?
LSI 是自然语言处理 (NLP) 中的一个过程。 NLP 是语言学和信息工程的一个子集,重点关注机器如何解释人类语言。 这项研究的一个关键部分是分布语义。 该模型帮助我们理解和分类大型数据集中具有相似上下文含义的单词。
LSI 开发于 1980 年代,使用一种数学方法,使信息检索更加准确。 该方法通过识别单词之间隐藏的上下文关系来工作。 它可以帮助您像这样分解它:
- 潜在的→隐藏的
- 语义→词之间的关系
- 索引→信息检索
潜在语义索引如何工作?
LSI 使用奇异值分解 (SVD) 的部分应用来工作。 SVD 是一种数学运算,可将矩阵简化为其组成部分,以便进行简单有效的计算。
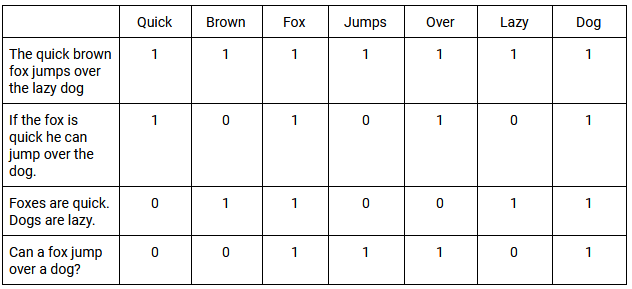
在分析一串单词时,LSI 会删除连词、代词和常用动词,也称为停用词。 这隔离了构成短语主要“内容”的单词。 这是一个简单的示例,说明这可能看起来如何:
![]()
然后将这些词放置在术语文档矩阵(TDM) 中。 TDM 是一个 2D 网格,它列出了每个特定单词(或术语)在数据集中的文档中出现的频率。
然后将加权函数应用于 TDM。 一个简单的例子是对所有包含值为 1 的单词的文档和所有不包含值为 0 的单词的文档进行分类。当单词在这些文档中以相同的一般频率出现时,称为co-occurrence 。 您将在下面找到 TDM 的基本示例,以及它如何评估跨多个短语的共现:
使用 SVD 可以让我们估计所有文档中的单词使用模式。 LSI 生成的 SVD 向量比分析单个术语更准确地预测含义。 最终,LSI 可以使用单词之间的关系来更好地理解它们在特定上下文中的意义或含义。
[案例研究] 通过页面 SEO 推动新市场的增长
 阅读案例研究
阅读案例研究潜在语义索引是如何参与 SEO 的?
在其成长期,谷歌发现搜索引擎会根据特定关键词的出现频率对网站进行排名。 但是,这并不能保证最相关的搜索结果。 相反,谷歌开始对他们认为值得信赖的信息仲裁者的网站进行排名。
随着时间的推移,谷歌的算法会更准确地过滤掉低质量和不相关的网站。 因此,营销人员必须了解搜索背后的含义,而不是依赖于所使用的确切词。 这就是为什么 Roger Montti 在一篇关于过时的 SEO 理念的文章中将 LSI 描述为“搜索引擎的训练轮”,并补充说 LSI“与搜索引擎如何对当今的网站进行排名几乎没有相关性”。
搜索查询的含义与其背后的意图密切相关。 Google 维护着一份名为“搜索质量评估员指南”的文档。 在这些指南中,他们为用户意图引入了四个有用的类别:

- 知道查询- 这代表寻找有关某个主题的信息。 对此的一个变体是“知道简单”查询,当用户在搜索时考虑到特定的答案。
- 做查询——这反映了参与特定活动的愿望,例如在线购买或下载。 所有这些查询都可以通过“交互”的感觉来定义。
- 网站查询- 这是用户正在寻找特定网站或页面的时候。 这些搜索表明对特定网站或品牌的先前认识。
- 亲自访问查询——用户正在搜索物理位置,例如实体店或餐厅。
LSI 背后的理论——在一个短语中定义一个词的上下文含义——为谷歌提供了竞争优势。 然而,“LSI 关键字”突然成为 SEO 成功的黄金门票的想法开始传播开来。
“LSI 关键字”真的存在吗?
许多著名的出版物仍然是 LSI 关键字的坚定拥护者。 然而,一些消息来源,例如谷歌的网站管理员趋势分析师约翰穆勒,表示它们是一个神话。 这些消息来源开始提出以下几点:
- LSI 是在万维网之前开发的,并不打算应用于如此庞大的动态数据集。
- 1989 年授予贝尔通信研究公司的美国潜在语义索引专利将在 2008 年到期。因此,根据 Bill Slawski 的说法,谷歌使用 LSI 类似于“使用智能电报设备连接到移动网络。
- Google 使用 RankBrain,这是一种机器学习方法,可将大量文本转换为“向量”——帮助计算机理解书面语言的数学实体。 与 LSI 不同,RankBrain 将网络作为一个不断扩展的数据集来容纳,使其可供 Google 使用。
最终,LSI 揭示了营销人员应该坚持的一个真理:探索一个词的独特上下文有助于我们更好地理解用户意图,而不是塞进内容中的关键字。 然而,这并不一定证实了谷歌基于 LSI 的排名。 因此,可以肯定地说 LSI 在 SEO 中作为一种哲学而不是一门精确的科学起作用吗?
让我们回到 Roger Montti 关于 LSI 作为“搜索引擎的训练轮”的名言。 一旦你学会骑自行车,你往往会取下辅助轮。 我们可以假设在 2020 年,谷歌不再使用辅助轮吗?
我们可以考虑谷歌最近的算法更新。 2019 年 10 月,搜索副总裁 Pandu Nayak 宣布,谷歌已开始使用名为 BERT(变形金刚的双向编码器表示)的人工智能系统。 影响超过 10% 的搜索查询,这是近年来 Google 最大的更新之一。
在分析搜索查询时,BERT 会考虑与该特定短语中的所有单词相关的单个单词。 这种分析是双向的,因为它考虑了特定单词之前或之后的所有单词。 删除单个单词可能会极大地影响 BERT 如何理解短语的独特上下文。
这与 LSI 形成鲜明对比,后者在分析中省略了任何停用词。 下面的示例显示了删除停用词如何改变我们对短语的理解:
![]()
尽管是停用词,但“查找”是搜索的关键,我们将其定义为“亲自访问”查询。
那么营销人员应该怎么做呢?
最初,LSI 被认为能够帮助 Google 将内容与相关查询进行匹配。 然而,市场上围绕 LSI 使用的争论似乎还没有得出一个单一的结论。 尽管如此,营销人员仍然可以采取许多措施来确保他们的工作保持战略相关性。
首先,应优化文章、网络副本和付费活动以包含同义词和变体。 这解释了意图相似的人使用语言的方式不同。
营销人员必须继续以权威和清晰的方式写作。 如果他们希望他们的内容解决特定问题,这是绝对必须的。 这个问题可能是缺乏信息或需要某种产品或服务。 一旦营销人员这样做,就表明他们真正了解用户意图。
最后,他们还应该经常使用结构化数据。 无论是网站、食谱还是常见问题解答,结构化数据都为 Google 提供了上下文,以了解它正在抓取的内容。